Retrieval-Augmented Generation (RAG) is an emerging AI technology stack that enhances the capabilities of large language models (LLMs) by providing additional “up-to-date knowledge”.
The basic RAG application includes four key technical components:
-
Embedding Model: Used to convert external documents and user queries into embedding vectors
-
Vector Database: Used to store embedding vectors and perform vector similarity retrieval (retrieving the most relevant Top-K pieces of information)
-
Prompt Engineering (Prompt engineering): Used to combine user questions with the retrieved context as input to the large model
-
Large Language Model (LLM): Used to generate answers
The basic RAG architecture above can effectively address the issues of LLMs generating “hallucinations” and producing unreliable content. However, some enterprise users have higher demands for contextual relevance and Q&A accuracy, requiring a more complex architecture. A popular and effective approach is to integrate a reranker into the RAG application.
01.
What is a Reranker?
A reranker is an important component of the information retrieval (IR) ecosystem, used to evaluate search results and reorder them to enhance query result relevance. In RAG applications, rerankers are mainly used after obtaining the results from vector queries (ANN), allowing for a more effective determination of the semantic relevance between documents and queries, and a finer rearrangement of results, ultimately improving search quality.
Currently, there are two main types of rerankers—statistical-based and deep learning model-based rerankers:
-
Statistical-based rerankers aggregate candidate result lists from multiple sources, using multi-way recall weighted scoring or reciprocal ranking fusion (RRF) algorithms to recalculate scores for all results and uniformly reorder the candidates. The advantage of this type of reranker is that it is computationally simple and efficient, making it widely used in traditional search systems that are sensitive to latency.
-
Deep learning model-based rerankers, often referred to as cross-encoder rerankers. Due to the nature of deep learning, some specially trained neural networks can analyze the relevance between questions and documents very well. This type of reranker can score the semantic similarity between questions and documents. Since the scoring generally depends only on the text content of the question and document, not on the scoring or relative position of the document in the recall results, this reranker is suitable for both single and multi-way recall.
02.
The Role of Rerankers in RAG
Integrating a reranker into RAG applications can significantly improve the accuracy of generated answers, as rerankers can select the documents that are closest to the questions from single or multi-way recall results. Additionally, expanding the richness of retrieval results (e.g., multi-way recall) combined with the refined filtering of the most relevant results (reranker) can further enhance the quality of the final results. Using a reranker can eliminate content that is less relevant to the question from the first layer of recall, narrowing the context provided to the large model down to the most relevant small set of documents. By shortening the context, the LLM can better “focus” on all content within the context, avoiding the neglect of key information, and also saving inference costs.
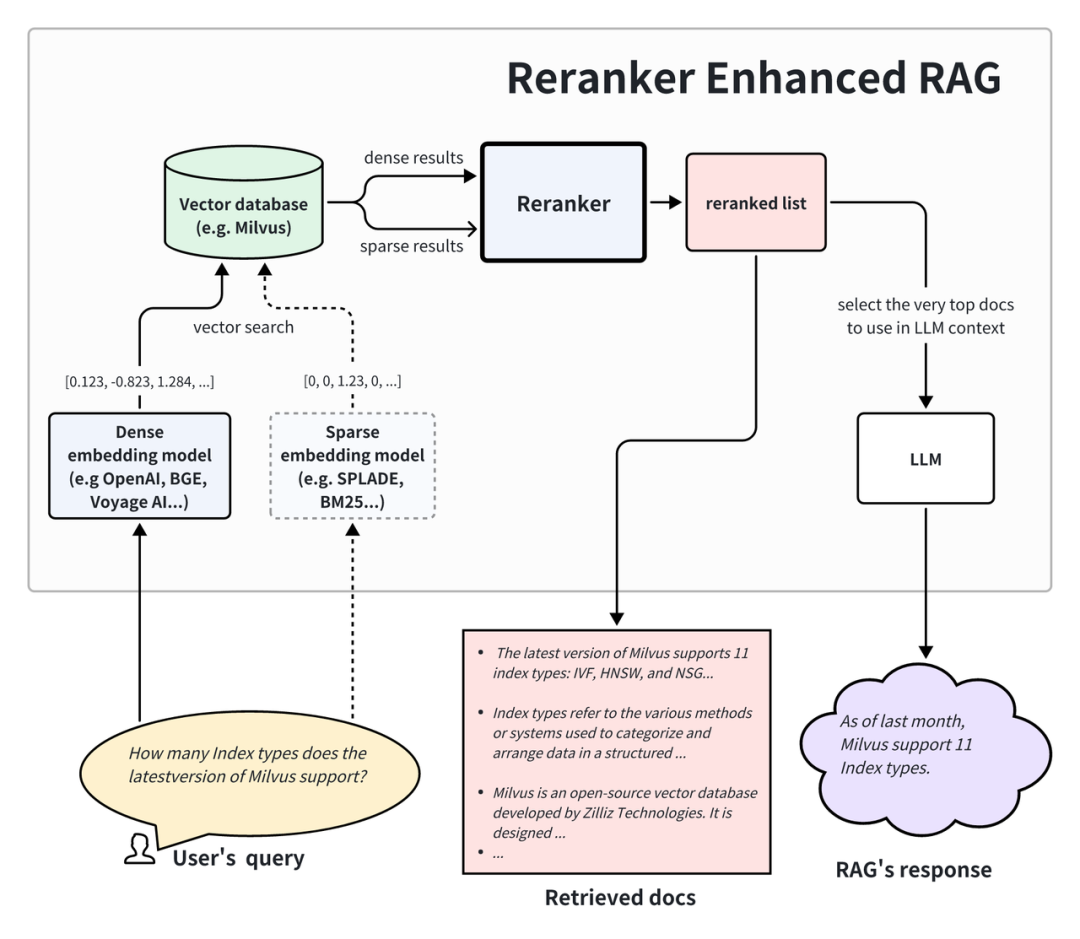
The above image shows the RAG application architecture with the addition of a reranker. It can be seen that this retrieval system contains two stages:
-
Retrieve Top-K relevant documents from the vector database, which can also be combined with sparse embedding to cover full-text retrieval capabilities.
-
The reranker scores and reorders these retrieved documents based on their relevance to the query. After reordering, the top results are selected as the context in the prompt to be passed to the LLM, ultimately generating higher quality and more relevant answers.
However, it should be noted that compared to the basic architecture of RAG that only conducts vector retrieval, adding a reranker also brings some challenges and increases usage costs.
03.
The Cost of Using Rerankers
While using a reranker to enhance retrieval relevance, it is important to focus on its costs. These costs include the increased latency impact on the business and the increased computational load affecting service costs. We recommend balancing retrieval quality, search latency, and usage costs based on your business needs to reasonably assess whether to use a reranker.
-
Rerankers significantly increase search latency
Without using a reranker, RAG applications only need to perform low-latency vector approximate nearest neighbor (ANN) searches to obtain Top-K relevant documents. For example, the Milvus vector database implements efficient vector indexing such as HNSW, achieving millisecond-level search latency. If using Zilliz Cloud, it can further enhance search performance with the more powerful Cardinal index.
However, if a reranker is added, especially a cross-encoder reranker, the RAG application needs to process all documents returned from the vector retrieval through a deep learning model, which can lead to significantly increased latency. Compared to the millisecond-level latency of vector retrieval, depending on model size and hardware performance, latency could increase to hundreds of milliseconds or even seconds!
-
Rerankers greatly increase computational costs
In the basic architecture of RAG, while vector retrieval requires pre-processing documents with deep learning models, this relatively complex computation is cleverly designed to occur offline. Through offline indexing (embedding model inference), each online query process only incurs the extremely low computational cost of vector retrieval. In contrast, using a reranker significantly increases the computational cost of each online query. This is because the reordering process requires high-cost model inference for each candidate document, unlike the former which can reuse offline indexing results for each query, using a reranker requires inference for each online query, leading to repeated overhead. This is very unsuitable for high-traffic information retrieval systems such as web search and e-commerce search.
Let’s do a simple calculation to see the costs of using a reranker.
According to VectorDBBench data, a vector database capable of handling 200 queries per second has a usage cost of only $100 per month, averaging out to a cost of $0.0000002 per query. If using a reranker, assuming the first stage vector retrieval returns the top 100 documents, the cost of reordering these documents can be as high as $0.001. This means that adding a reranker increases costs by 5000 times compared to performing vector searches alone.
Although in many practical situations, only a small number of results may be reordered (e.g., 10 to 20), the costs of using a cross-encoder reranker are still significantly higher than simply performing vector searches.
From another perspective, using a reranker essentially incurs costs equivalent to offline indexing during queries, which means the computational load of model inference. The inference cost is related to input size (number of tokens in the text) and the size of the model itself. Generally, embedding and reranker model sizes range from a few hundred MB to several GB. Assuming the sizes of the two models are similar, because the documents being queried are generally much larger than the question itself, the inference cost for the question can be ignored. If each query requires reordering the top 10 documents, this equates to 10 times the cost of offline computing embeddings for a single document. Under high query loads, the computational and usage costs may become unbearable. For low-load scenarios, such as enterprise internal high-value low-frequency knowledge base Q&A, this cost may be completely acceptable.
04.
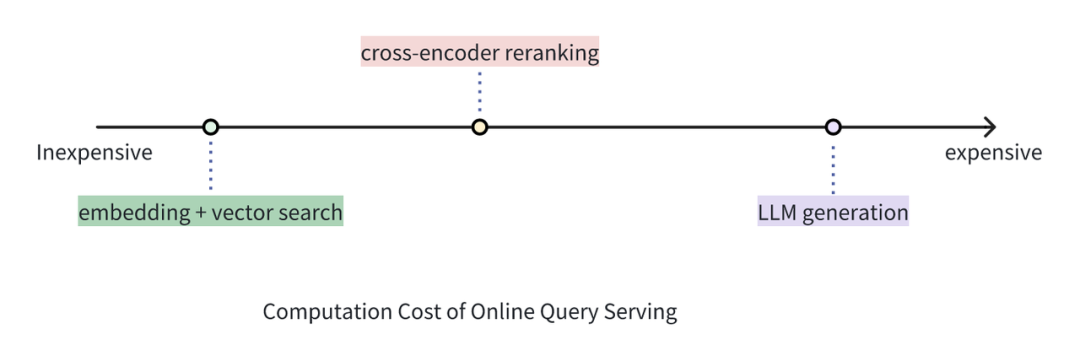
Cost Comparison: Vector Retrieval vs. Cross-encoder Reranker vs. Large Model Generation
Although the cost of using a reranker is significantly higher than simply using vector retrieval, it is still lower than the cost of using an LLM to generate answers for the same number of documents. In the RAG architecture, the reranker can filter the preliminary results of vector searches, discarding documents with low relevance to the query, thereby effectively preventing the LLM from processing irrelevant information. This can greatly reduce the time and cost of the generation part compared to sending all results returned by vector searches into the LLM.
For a practical example: In the first stage of retrieval, the vector search engine can quickly filter out the 20 documents with the highest semantic similarity among millions of vectors, but the relative order of these documents can be further optimized using a reranker. While this incurs some cost, the reranker can further select the best top 5 results from the top 20. Thus, the relatively more expensive LLM only needs to analyze these top 5 results, avoiding the higher costs and attentional “distraction” associated with processing 20 documents. In this way, we can balance latency, answer quality, and usage costs through this composite solution.
05.
In Which Situations is it Suitable to Use Rerankers in RAG Applications?
Scenarios that pursue high precision and high relevance in answers are particularly suitable for using rerankers, such as professional knowledge bases or customer service systems. Because the queries in these applications have high commercial value, the priority of improving answer accuracy far exceeds system performance and cost control. Using a reranker can generate more accurate answers and effectively enhance user experience.
However, in scenarios like web search and e-commerce search, response speed and cost are crucial, so it is less suitable to use the costly cross-encoder reranker. Such applications are more suitable for using vector retrieval combined with lighter score-based rerankers to ensure response speed while improving search quality and reducing overhead.
06.
Conclusion
Compared to using vector retrieval alone, combining with a reranker can improve the accuracy and relevance of answers in retrieval-augmented generation (RAG) and search systems by further refining the ranking of the first layer of retrieval results. However, using a reranker will increase latency and raise usage costs, making it unsuitable for high-frequency and high-concurrency applications. When considering whether to use a reranker, trade-offs must be made between answer accuracy, response speed, and usage costs.
If you need to use a reranker in a RAG application, you can utilize the newly launched pymilvus model library component to call the reranker model in conjunction with Milvus’s vector retrieval. Additionally, Zilliz Cloud not only provides the key component of a vector database but also offers the Pipelines feature, which simplifies the backend architecture of RAG applications and reduces maintenance costs by providing a one-stop API service for text vectorization, retrieval, and reordering. Interested readers can visit the link(https://docs.zilliz.com/reference/python/Model) or browse (https://milvus.io/docs ) to learn more about using rerankers in Zilliz Cloud Pipelines or Milvus.