
The latest research from the Cohere team reveals that the reasoning capabilities of LLMs do not stem from simple retrieval of pre-training data (previously believed to be “approximate retrieval”), but rather from the learning and application of programmatic knowledge, similar to how humans learn general problem-solving methods from examples. This means that LLMs extract reasoning patterns from data like learning general programs, rather than memorizing answers. This discovery overturns the previous “approximate retrieval” hypothesis and points to a new direction for future LLM training: focusing on high-quality programmatic knowledge rather than pursuing unlimited expansion of data scale. Surprisingly, models of different scales (e.g., 7B and 35B) seem to learn different information from the same data.
Exploring LLM Inference Mechanisms
The reasoning capabilities of large language models (LLMs) have been a hot and challenging topic in AI research. Understanding how LLMs reason not only helps us better leverage the powerful capabilities of LLMs but is also crucial for the design and development of future AI. Previous assumptions suggested that LLMs primarily reason through approximate retrieval, i.e., retrieving knowledge fragments related to questions from vast pre-training data and combining them into answers. In other words, there has been a widespread assumption in the community that when LLMs reason, they perform some form of approximate retrieval, “retrieving” answers to intermediate reasoning steps from parameterized knowledge formed during pre-training, rather than engaging in “true” reasoning.
 However, the latest research from the Cohere team challenges this view. They found that programmatic knowledge, rather than simple retrieval, is the key to LLM reasoning capabilities. This research provides a new perspective for understanding the reasoning mechanisms of LLMs and points to new directions for the training and optimization of future LLMs.
However, the latest research from the Cohere team challenges this view. They found that programmatic knowledge, rather than simple retrieval, is the key to LLM reasoning capabilities. This research provides a new perspective for understanding the reasoning mechanisms of LLMs and points to new directions for the training and optimization of future LLMs.
Question: How Do LLMs Reason?
How exactly do LLMs reason? Do they retrieve information like search engines, or do they apply logic and reasoning like humans? This question has long troubled researchers. The Cohere team’s research aims to explore the reasoning mechanisms of LLMs and clarify how LLMs learn reasoning from pre-training data. Their research focuses on mathematical reasoning tasks to investigate whether LLMs truly engage in reasoning or merely retrieve memorized answers.The core question of the research is: How do LLMs learn reasoning from pre-training data?
Background: The Application of the EK-FAC Influence Function
To explore the reasoning mechanisms of LLMs, the Cohere team employed a method called EK-FAC influence function. This method estimates the impact of each document in the pre-training data on the model’s output, revealing which knowledge is crucial for the model’s reasoning process.The EK-FAC influence function acts like a microscope, helping us magnify and observe the impact of pre-training data on model reasoning and identify the key information that most influences model reasoning, just like finding critical lines of code during debugging.
Experimental Setup: Data and Models
This study used Cohere’s Command R 7B and 35B models of different scales, selecting **5 million documents (2.5 billion tokens)** as samples of pre-training data, ensuring these documents are consistent with the pre-training distribution. The researchers designed three types of questions: factual questions, key reasoning questions (including two-step arithmetic [only for the 7B model], calculating the slope between two points [for both 7B and 35B models], and solving linear equations [only for the 35B model]) and control questions. Control questions were used to eliminate irrelevant factors like formatting that could affect the experimental results. The choice of mathematical reasoning tasks is due to the clear and controllable reasoning steps involved, making it easier to analyze the reasoning process of LLMs.
Example of reasoning questions (Figure 1):
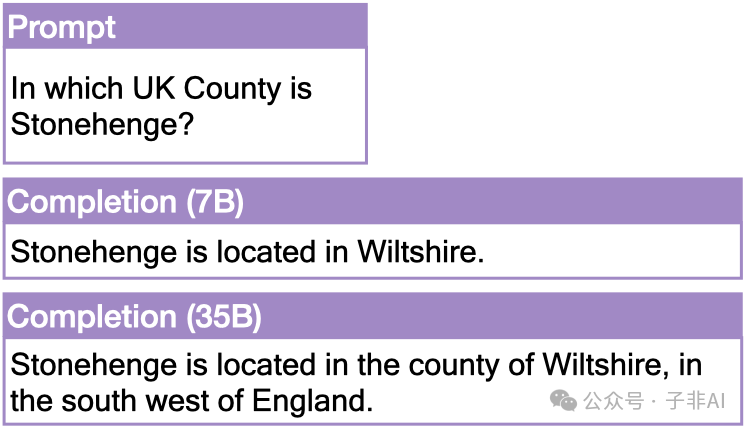
 Figure: Examples of factual questions (left) and reasoning questions (right). Factual questions require knowledge retrieval, while reasoning questions require multi-step reasoning.
Figure: Examples of factual questions (left) and reasoning questions (right). Factual questions require knowledge retrieval, while reasoning questions require multi-step reasoning.Example of two-step operations (7B model) (Figure 2):
 Figure: Example of two-step arithmetic reasoning by the 7B model.
Figure: Example of two-step arithmetic reasoning by the 7B model.Calculating slope (7B and 35B models) example:


Example of solving linear equations (35B model):

Example of factual questions (Figure 6):
Research Findings: Programmatic Knowledge Drives LLM Reasoning
The core finding of the Cohere team is that LLM reasoning is more akin to programmatic generalization, similar to how humans learn general problem-solving methods, rather than simply retrieving answers from pre-training data. LLMs do not simply memorize and match answers, but learn the reasoning process.
Quantitative Results: Evidence of Programmatic Knowledge
Generalization Ability Analysis: Same Tasks, Different Data
The researchers calculated the Pearson correlation coefficients of document influence scores between different questions and found that there is a significant positive correlation between different questions of the same reasoning task (Figure 7), indicating that the model has learned generalizable programmatic knowledge. Even if the specific values in the questions differ, the model can apply the same reasoning process to solve the problems.

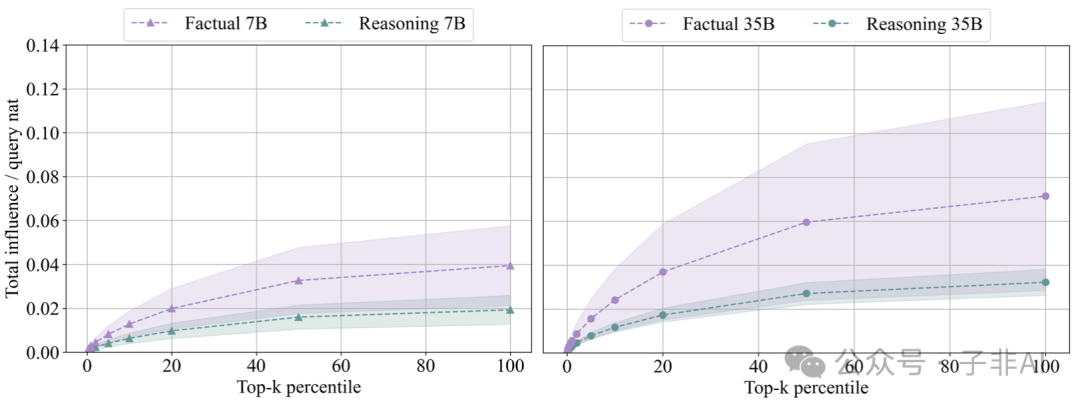
7B vs 35B: The Impact of Model Scale
The 35B model exhibits stronger generalization ability in slope calculation tasks, indicating that larger models can better learn and apply programmatic knowledge. However, surprisingly, there is almost no correlation in the information learned by the 7B and 35B models from the same data.
Dependency Analysis: Weak Dependency, Strong Generalization
Compared to factual questions, reasoning questions have lower dependency on individual documents, and the influence distribution is more scattered (Figure 8), which further proves the importance of programmatic knowledge. The model does not rely on retrieving information from a single document, but learns and synthesizes programmatic knowledge from multiple documents, achieving programmatic generalization.
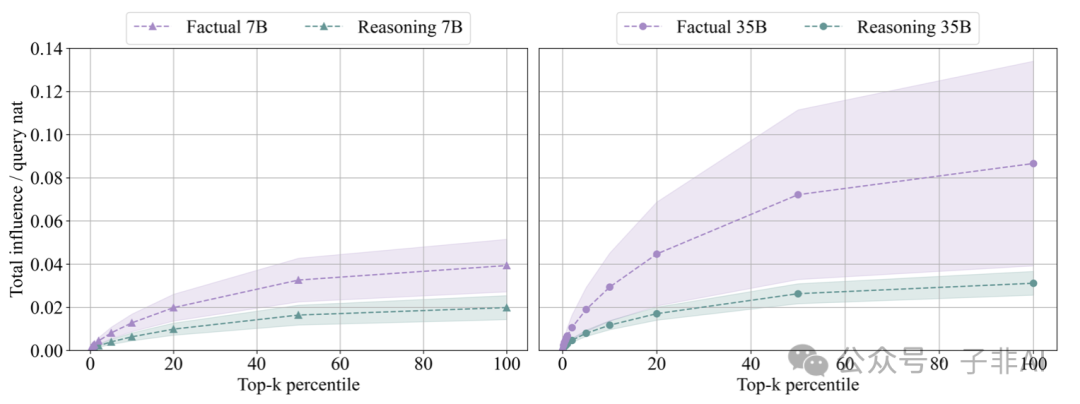
7B vs 35B: The Impact of Model Scale
The 35B model has a lower dependency on individual documents, which again confirms the stronger generalization ability of larger models. This suggests that increasing model scale helps LLMs better learn and use programmatic knowledge and reduces reliance on individual documents. The 35B model has larger and more fluctuating influence values on factual questions, indicating that it learns from fewer but more relevant documents. (Figure 9)
Qualitative Results: In-Depth Interpretation of Programmatic Knowledge
Answer Dependency Analysis: Not Just Simple Answer Matching
The researchers found that answers to factual questions appear more frequently in high-influence documents, while answers to reasoning questions appear very rarely (Figure 10). This further proves that LLM reasoning is not simply answer matching, but a reasoning process based on programmatic knowledge.
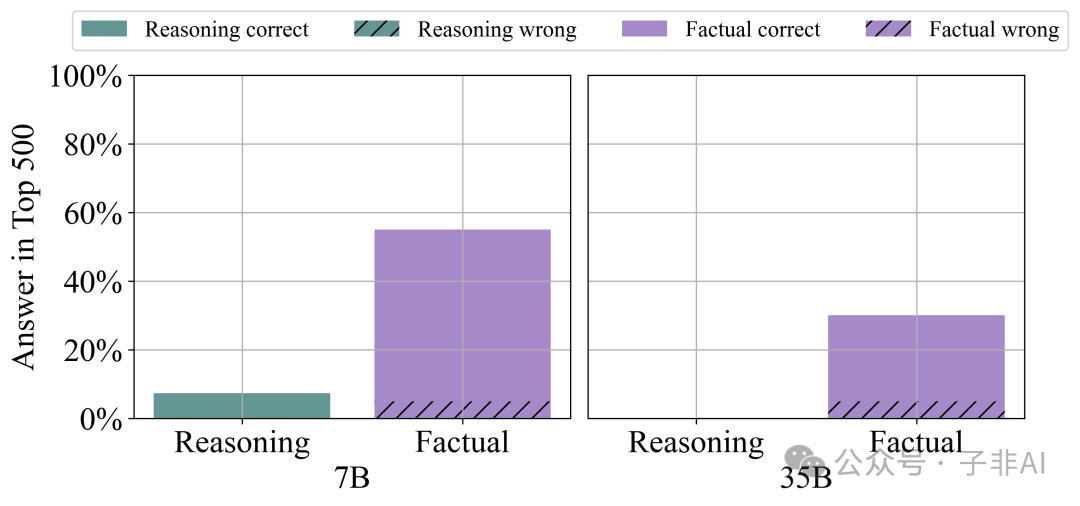
7B vs 35B: The Impact of Model Scale
The 35B model has a lower dependency on answers, which corresponds to its stronger programmatic generalization ability.
Influencing Factors Analysis: Code and Formulas Are Key
Analysis of high-influence documents shows that these documents often contain programmatic knowledge related to reasoning processes, such as code, mathematical formulas, etc. This indicates that LLMs can learn reasoning steps and methods from code and formulas, confirming the importance of programmatic knowledge.
7B vs 35B: The Impact of Model Scale
The 35B model is more inclined to utilize programmatic knowledge, further demonstrating the advantages of larger models.
Data Source Analysis: The Greater Impact of Programmatic Data Sources
The study found that programmatic data sources such as code, StackExchange, ArXiv, and Markdown have a significant positive impact on solving reasoning questions, while data sources like Wikipedia and Trivia have more influence on answering factual questions (Figures 11 & 12). This suggests that different types of data have different impacts on different types of tasks, providing important guidance for constructing more effective pre-training datasets.
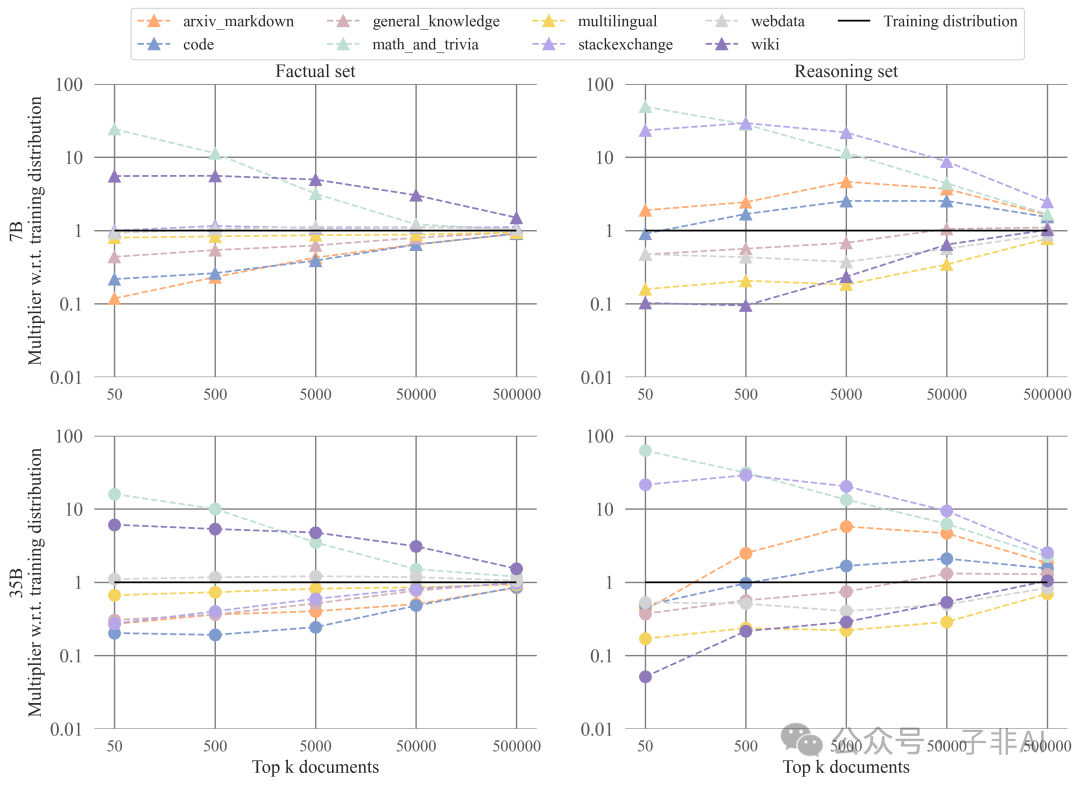
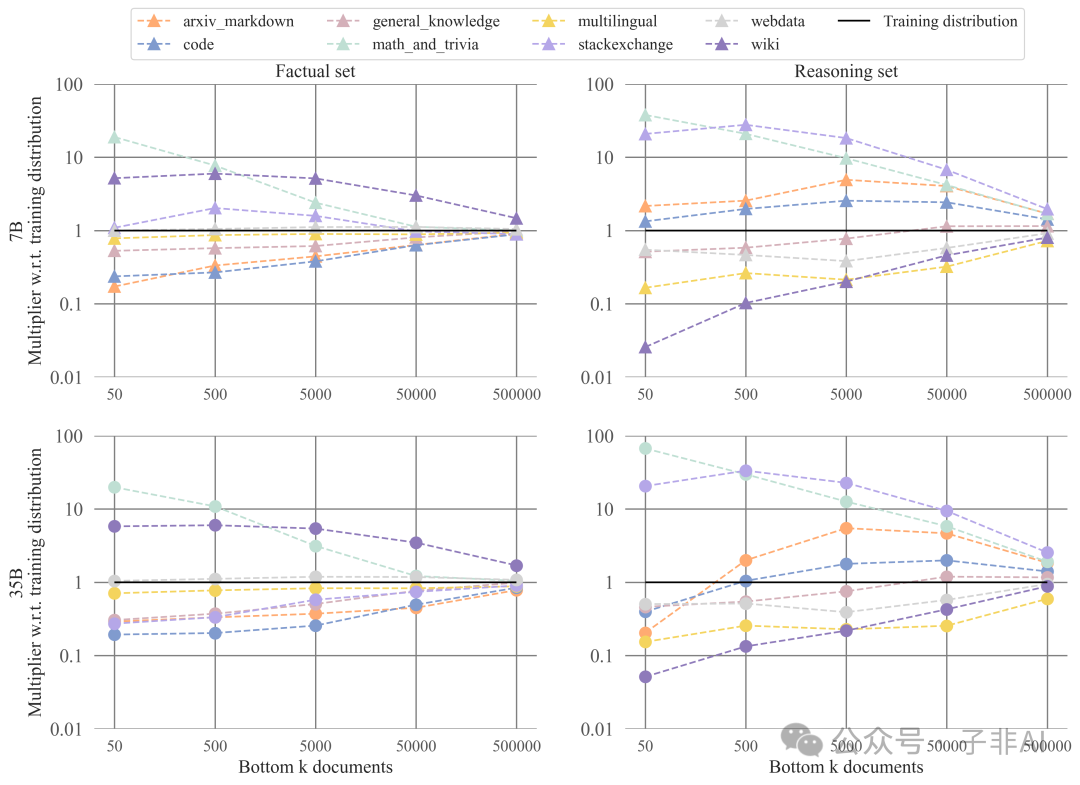
7B vs 35B: The Impact of Model Scale
The 35B model can better leverage knowledge from different data sources, reflecting the stronger learning ability of larger models.
Conclusion: The Future of Programmatic Knowledge
The research by the Cohere team reveals the key role of programmatic knowledge in the reasoning process of LLMs, overturning the previous view that LLMs primarily rely on retrieval for reasoning, and providing new ideas for the training and optimization of future LLMs: focusing on high-quality programmatic knowledge, such as code and formulas. Future research can further explore the learning mechanisms of programmatic knowledge and how to combine programmatic knowledge with other types of knowledge to build more powerful LLM reasoning systems.
Related Links
-
• Paper:https://arxiv.org/pdf/2411.12580 -
• Demo: https://lauraruis.github.io/Demo/Scripts/linked.html