
Selected from offconvex
Author:John Miller
Translated by Machine Heart
Contributors: Qianshu, Zhang Qian, Siyuan
In recent years, while Recurrent Neural Networks (RNNs) have been dominant, models like autoregressive Wavenet or Transformers are now replacing RNNs in various sequence modeling tasks. Machine Heart has previously introduced RNNs and CNNs for sequence modeling in a GitHub project, and has also discussed Transformers that do not use either of these networks. This article primarily focuses on the differences between recurrent networks and feedforward networks in sequence modeling, and when it is better to choose convolutional networks over recurrent networks.
-
Machine Heart GitHub project: From Recurrent to Convolutional, Exploring the Secrets of Sequence Modeling
-
Based on attention mechanisms, Machine Heart helps you understand and train neural machine translation systems
In this blog post, we explore the trade-offs between recurrent network models and feedforward models. Feedforward models can improve training stability and speed, while recurrent models have greater expressive power. Interestingly, the additional expressiveness does not seem to improve the performance of recurrent models.
Some research teams have demonstrated that feedforward networks can achieve the same results as the best recurrent models on benchmark sequence tasks. This phenomenon presents an interesting question for theoretical research:
Why can feedforward networks replace recurrent neural networks without sacrificing performance? When can they be replaced?
We discuss several possible answers and emphasize our recent research titled “When Recurrent Models Don’t Need To Be Recurrent,” which provides explanations from the perspective of fundamental stability.
The Story of Two Sequence Models
Recurrent Neural Networks
Many variants of recurrent models have a similar form. The model processes past input sequences using the state h_t. At each time step t, the state is updated according to the following equation:
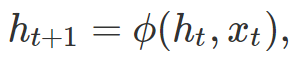
Where x_t is the input at time t, φ is a differentiable mapping, and h_0 is the initial state. In a basic recurrent neural network, the model is parameterized by matrices W and U, and the state is updated according to:
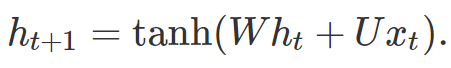
In practice, Long Short-Term Memory networks (LSTMs) are more commonly used. Regardless of the case, when making predictions, the state is passed to function f, and the model predicts y_t = f(h_t). Since state h_t is a function of all past inputs x_0, …, x_t, the prediction y_t also depends on the entire historical input x_0, …, x_t.
The recurrent model can be graphically represented as follows.
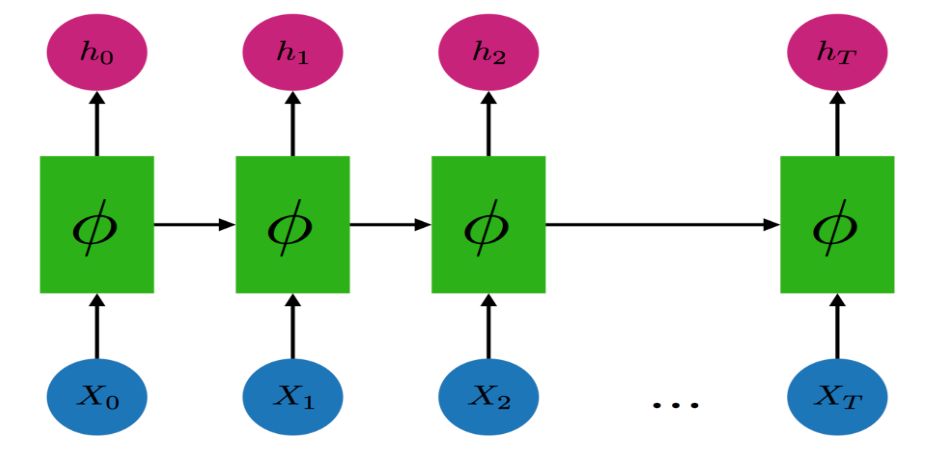
Recurrent models can fit data using backpropagation. However, the gradients backpropagated from time step T to time step 0 often require substantial memory that is difficult to satisfy, so each recurrent model’s implementation typically truncates and only backpropagates the gradients for k time steps.
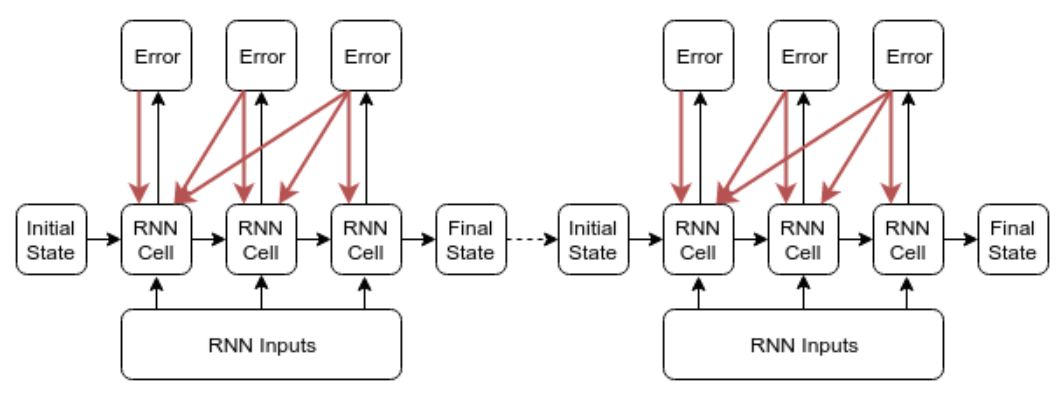
With this configuration, the predictions of the recurrent model still depend on the entire historical input x_0,…,x_T. However, it is currently unclear how this training process affects the model’s ability to learn long-term patterns, especially those requiring more than k steps.
Autoregressive, Feedforward Models
Autoregressive models use only the most recent k inputs, i.e., x_t-k + 1, …, x_t to predict y_t, rather than relying on the entire historical state for predictions. This corresponds to a strong conditional independence assumption. In particular, feedforward models assume that the target depends only on the k most recent inputs. Google’s WaveNet illustrates this general principle well.

Compared to RNNs, the limited context of feedforward models means they cannot capture patterns that exceed k time steps. However, techniques such as dilated convolutions can make k very large.
Why Focus on Feedforward Models?
Initially, recurrent models seem to be more flexible and expressive than feedforward models. After all, feedforward networks impose a strong conditional independence assumption, while recurrent models do not have such restrictions. However, even if feedforward models are less expressive, there are several reasons researchers may prefer to use feedforward networks.
Parallelization: Convolutional feedforward models are easier to parallelize during training, as they do not require updating and maintaining hidden states, thus there is no sequential dependency between outputs. This allows for very efficient training processes on modern hardware.
Trainability: Training deep convolutional neural networks is a fundamental process in deep learning, while recurrent models are often more challenging to train and optimize. Additionally, significant efforts have been made in architecture design and software development to effectively and reliably train deep feedforward networks.
Inference Speed: In some cases, feedforward models can be lighter and execute inference faster than similar recurrent systems. In other cases, particularly for long sequence problems, autoregressive inference can be a significant bottleneck, requiring substantial engineering work or cleverness to overcome.
Feedforward Models Can Outperform Recurrent Models
Although it seems that the trainability and parallelization of feedforward models come at the cost of reduced model accuracy, recent examples indicate that feedforward networks can actually achieve the same accuracy as recurrent networks on benchmark tasks.
Language Modeling: In language modeling, the goal is to predict the next word given all current words. Feedforward models use only the k most recent words for prediction, while recurrent models may use the entire document. Gated convolutional language models are a type of feedforward autoregressive model that competes with large LSTM benchmark models. Despite a truncation length of k = 25, this model outperforms large LSTM models on the Wikitext-103 benchmark, which tests the ability to capture long-term dependencies. On the Billion Word Benchmark, this model is slightly worse than the largest LSTM but trains faster and uses fewer resources.
Machine Translation: The goal of machine translation is to map English sentences to sentences in other languages, such as English to French. Feedforward models use only the k words of the sentence for translation, while recurrent models can leverage the entire sentence. In deep learning, models like Google Neural Machine Translation initially used LSTMs with attention mechanisms for sequence modeling, later transitioning to fully convolutional networks for sequence modeling and using Transformers to build large translation systems.

Speech Synthesis: In the field of speech synthesis, researchers attempt to produce realistic human speech. Feedforward models are limited to the past k samples, while recurrent models can use all historical samples. As of this writing, the autoregressive WaveNet is a significant improvement over LSTM-RNN models.
Further Reading: Recently, Bai et al. proposed a universal feedforward model using dilated convolutions and demonstrated that it outperforms recurrent benchmark models across tasks from synthetic replication to music generation. Machine Heart analyzed this model in the article “From Recurrent to Convolutional, Exploring the Secrets of Sequence Modeling.”
How Can Feedforward Models Surpass Recurrent Models?
In the examples above, feedforward networks achieve results that are the same as or better than recurrent networks. This is puzzling because recurrent models seem more advanced. Dauphin et al. provide one explanation for this phenomenon:
For language modeling, the infinite context information provided by recurrent models is not strictly necessary.
In other words, you may not need a large amount of contextual information to average for prediction tasks. Recent theoretical work provides some evidence supporting this view.
Bai et al. offer another explanation:
The “infinite memory” advantage of RNNs essentially does not exist in practice.
As stated in Bai et al.’s report, even in experiments that explicitly require long-term context, RNNs and their variants cannot learn long sequences. A remarkable Google academic report on the Billion Word Benchmark shows that an LSTM n-gram model that remembers n = 13 character contexts performs no differently than an LSTM that can remember arbitrarily long contexts.
This evidence leads us to speculate that recurrent models trained in practice are essentially feedforward models. This may occur because the truncated backpropagation through time cannot learn patterns longer than k steps, as models trained via gradient descent do not have long-term memory.
In our recent paper, we investigated the gap between recurrent models and feedforward models trained with gradient descent. We indicated that if recurrent models are stable (meaning no gradient explosion), then both the training and inference processes of recurrent models can be well approximated by feedforward networks. In other words, we demonstrated that feedforward and stable recurrent models trained via gradient descent are equivalent in testing. Of course, not all models trained in practice are stable. We also provided empirical evidence that certain stability conditions can be imposed on some recurrent models without sacrificing performance.
Conclusion
Although some preliminary attempts have been made, much work remains to understand why feedforward models can compete with recurrent models and to clarify the trade-offs between sequence models. How much memory is actually needed in general sequence benchmarks? What are the expressive trade-offs between truncated RNNs (which can be seen as feedforward models) and popular convolutional models? Why do feedforward networks perform as well as unstable RNNs in practice?
Answering these questions is an attempt to establish a theory that can explain both the advantages and limitations of our current methods, as well as guide how to choose different models in specific environments.
Original link: http://www.offconvex.org/2018/07/27/approximating-recurrent/
This article is translated by Machine Heart, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time reporter / Intern): [email protected]
Submissions or inquiries: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]