
Selected from MachineLearningMastery
Author: Jason Brownlee
Translated by Machine Heart
Contributors: Nurhachu Null, Lu Xue
The encoder-decoder structure has shown advanced levels in several fields, but this structure encodes the input sequence into a fixed-length internal representation. This limits the length of the input sequence and results in poorer performance of the model on particularly long input sequences. Introducing the attention mechanism into recurrent neural networks helps to address this limitation. This method can be applied to sequence prediction in multiple fields, including text translation, speech recognition, and more.

The popularity of the encoder-decoder structure is due to its demonstration of the current highest levels in many fields. The limitation of this structure is that it encodes the input sequence into a fixed-length internal representation. This limits the length of the input sequence and leads to poorer performance of the model on particularly long input sequences.
In this blog, we will discover how the attention mechanism can be adopted in recurrent neural networks to overcome this limitation.
After reading this blog, you will know:
-
The limitations of the encoder-decoder structure and fixed-length internal representations
-
How to let the network learn to pay attention to the corresponding positions in the input sequence for each item in the output sequence using the attention mechanism
-
The applications of recurrent neural networks with attention mechanisms in five areas, including text translation and speech recognition.
The Problem of Long Sequences
In encoder-decoder recurrent neural networks, a series of long short-term memory networks (LSTMs) learn to encode the input sequence into a fixed-length internal representation, while another set of LSTMs reads the internal representation and decodes it into the output sequence. This structure has demonstrated state-of-the-art performance in challenging sequence prediction problems (e.g., text translation) and has quickly become the dominant method. For example, the following two papers:
-
Sequence to Sequence Learning with Neural Networks (2014)
-
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation (2014)
The encoder-decoder structure can still achieve excellent results on many problems. However, it is constrained by the requirement that all input sequences are forced to be encoded into fixed-length internal vectors. This limitation restricts the performance of these networks, especially considering longer input sequences, such as long sentences in text translation.
“One potential problem with this encoder-decoder approach is that the neural network needs to compress all the necessary information from the source sentence into a fixed-length vector. This makes it difficult for the neural network to handle long sentences, especially those longer than the training corpus.”
——Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
Attention Mechanism in Sequences
The attention mechanism is a method that frees the encoder-decoder structure from fixed-length internal representations. It does this by retaining the intermediate output results of the LSTM encoder for each step of the input sequence, and then training the model to learn how to selectively focus on the input and link them to items in the output sequence. In other words, each item in the output sequence depends on the selected items in the input sequence.
“The model proposed in the paper searches for the most relevant information in a series of locations in the source sentence each time it generates a word during translation. It then predicts the next target word based on the context vector, the positions in the source text, and the previously generated target words.”
——Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate (https://arxiv.org/abs/1409.0473), 2015
While this approach increases the computational burden on the model, it results in a more focused and better-performing model. Furthermore, the model can demonstrate how it pays attention to the input sequence when predicting the output sequence. This helps us understand and analyze what the model is focusing on and to what extent it is paying attention to specific input-output pairs.
“The method proposed in the paper allows for an intuitive observation of the (soft) alignment relationships between each word in the generated sequence and some words in the input sequence, which can be achieved through the visualization of the annotated weights… Each row in the matrix of each figure represents the weights associated with the annotations. Thus, we can see which position in the source sentence was emphasized when generating the target word.”
——Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate (https://arxiv.org/abs/1409.0473), 2015
Issues with Using Large Images
Convolutional neural networks applied to computer vision problems also face similar issues; training models with particularly large images can be challenging. The resulting effect is that the image is observed extensively before making predictions, obtaining its approximate representation.
“An important characteristic of human perception is that it does not tend to process the entirety of a scene at once but selectively focuses attention on certain parts of the visual space to acquire the necessary information, combining local information from different time points to construct an internal representation of the entire scene, guiding subsequent eye movements and decisions.”
——Recurrent Models of Visual Attention (https://arxiv.org/abs/1406.6247), 2014
These glimpse-based corrections can also be considered as attention mechanisms, but they are not the attention mechanisms that this article aims to discuss.
Related papers:
-
Recurrent Models of Visual Attention, 2014
-
DRAW: A Recurrent Neural Network For Image Generation, 2014
-
Multiple Object Recognition with Visual Attention, 2014
Five Examples of Using Attention Mechanism for Sequence Prediction
This section provides specific examples of combining attention mechanisms with recurrent neural networks for sequence prediction.
1. Attention Mechanism in Text Translation
The example of text translation has been mentioned earlier. Given an input sequence of a French sentence, it translates and outputs an English sentence. The attention mechanism is used to observe the specific words in the input sequence that correspond to each word in the output sequence.
“When generating each target word, we let the model search for some input words or word annotations computed by the encoder, thereby extending the basic encoder-decoder structure. This allows the model to no longer be required to encode the entire source sentence into a fixed-length vector and enables it to focus only on information relevant to the next target word.”
——Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate (https://arxiv.org/abs/1409.0473), 2015
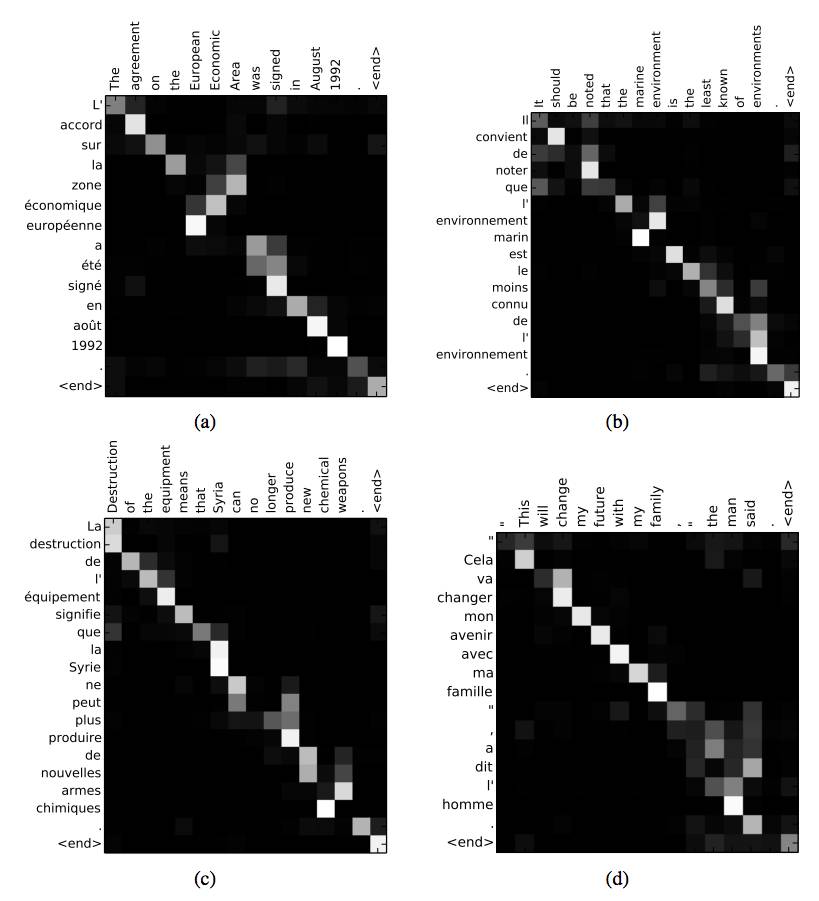
Attention compilation in French-English translation
Figure caption: Columns represent the input sequence, rows represent the output sequence, highlighted blocks represent the association between the two, with lighter colors indicating stronger associations.
Image from the paper: Dzmitry Bahdanau, et al., Neural machine translation by jointly learning to align and translate, 2015
2. Attention Mechanism in Image Captioning
Unlike the glimpse method, sequence-based attention mechanisms can be applied to computer vision problems to help find ways to better utilize convolutional neural networks to focus on the input image, for example, in a typical image captioning task. Given an input image, the output is an English description of that image. The attention mechanism is used to focus on local images relevant to each word in the output sequence.
“We proposed an attention-based method that achieved state-of-the-art performance on three benchmark datasets… We also demonstrated how to use the learned attention mechanism to provide more interpretability to the model generation process, showing that the learned alignment is highly consistent with human intuition.”
—— Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2016

Attention compilation of output words with specific regions of the input image
Similar to the above image, the underlined words in the output text correspond to the glowing areas in the image on the right.Image from the paper: Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, 2016
3. Attention Mechanism in Semantic Entailment
Given a premise scene and an assumption about that scene in English, the output is whether the premise and assumption contradict, relate to each other, or whether the premise entails the assumption.
For example:
-
Premise: “Photo from the wedding”
-
Assumption: “Someone is getting married”
The attention mechanism is used to associate each word in the assumption with words in the premise, and vice versa.
We proposed an LSTM-based neural model that can read the two sentences as a single sentence for semantic entailment analysis, rather than encoding each sentence independently into a semantic vector. We then expanded the model with a word-by-word attention mechanism to encourage reasoning about whether there is an entailment relationship between paired words and phrases… The benchmark score of the expanded model was 2.6% higher than that of LSTM, setting a new accuracy record…
——Reasoning about Entailment with Neural Attention (https://arxiv.org/abs/1509.06664), 2016
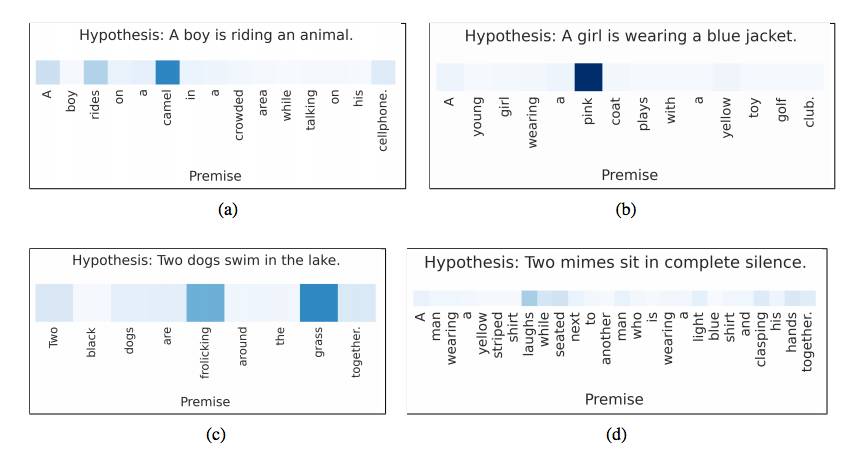
Attention compilation from words in the premise to words in the assumption.Image from the paper: Reasoning about Entailment with Neural Attention, 2016
4. Attention Mechanism in Speech Recognition
Given an English audio segment as input, the output is a sequence of phonemes. The attention mechanism is used to associate each phoneme in the output sequence with specific speech frames in the input sequence.
“… We proposed a novel end-to-end trainable speech recognition structure based on a hybrid attention mechanism, which combines content information and positional information to select the next position in the input sequence during decoding. A satisfying aspect of the model is its ability to recognize speech longer than the training corpus.”
——Attention-Based Models for Speech Recognition (https://arxiv.org/abs/1506.07503), 2015.
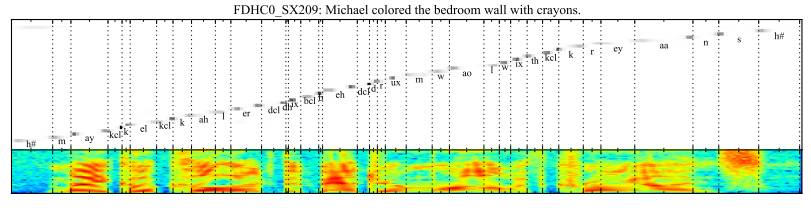
Attention compilation from output phonemes to input speech frames. Image from the paper: Attention-Based Models for Speech Recognition, 2015.
5. Attention Mechanism in Text Summarization
Given an English article as an input sequence, the output is a segment of English text summarizing the input sequence. The attention mechanism is used to associate each word in the summary text with the corresponding word in the source text.
“… We proposed a model based on the neutral attention mechanism for abstractive summarization, which evolved from recent advancements in neural machine translation. We combined this probabilistic model with a generative algorithm capable of producing accurate abstractive summaries.”
——A Neural Attention Model for Abstractive Sentence Summarization (https://arxiv.org/abs/1509.00685), 2015
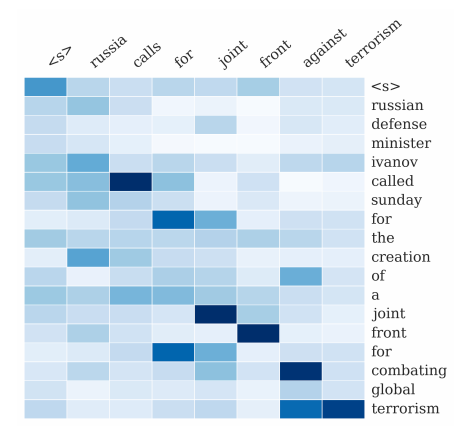
Attention compilation from words in the input text to the summary output. Image from the paper: A Neural Attention Model for Abstractive Sentence Summarization, 2015.
Further Reading
If you are interested in adding attention mechanisms in LSTMs, you can read the following:
-
Attention and memory in deep learning and NLP (http://www.wildml.com/2016/01/attention-and-memory-in-deep-learning-and-nlp/)
-
Attention Mechanism (https://blog.heuritech.com/2016/01/20/attention-mechanism/)
-
Survey on Attention-based Models Applied in NLP (http://yanran.li/peppypapers/2015/10/07/survey-attention-model-1.html)
-
[Quora Q&A] What is exactly the attention mechanism introduced to RNN? (https://www.quora.com/What-is-exactly-the-attention-mechanism-introduced-to-RNN-recurrent-neural-network-It-would-be-nice-if-you-could-make-it-easy-to-understand)
-
What is Attention Mechanism in Neural Networks? (https://www.quora.com/What-is-Attention-Mechanism-in-Neural-Networks)
Conclusion
This blog post introduced the use of attention mechanisms in LSTM recurrent neural networks for sequence prediction.
Specifically:
-
The encoder-decoder structure in recurrent neural networks uses fixed-length internal representations, which impose limitations on learning long sequences.
-
The attention mechanism overcomes this limitation of the encoder-decoder structure by allowing the network to learn to associate each item in the output sequence with relevant items in the input sequence.
-
This method has been applied in various sequence prediction problems, including text translation, speech recognition, and more.

Original link: http://machinelearningmastery.com/attention-long-short-term-memory-recurrent-neural-networks/
This article is translated by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (full-time reporters/interns): [email protected]
Submissions or inquiries: [email protected]
Advertising & business cooperation: [email protected]