[New Intelligence Overview] After Google released Gemini, it has claimed that Gemini Pro is superior to GPT-3.5. However, CMU researchers conducted their own tests to provide an objective and neutral third-party comparison. The results show that GPT-3.5 still generally outperforms Gemini Pro, although the gap is not large.
Google’s recent release of Gemini has stirred quite a commotion.
After all, the large language model field has been dominated by OpenAI’s GPT.
As onlookers, we certainly hope that tech companies will compete and that large models will clash!
As Google’s flagship product, Gemini naturally bears high expectations.
Although some strange incidents occurred after Gemini’s release, such as video forgery and claiming to be Wenxin Yiyan.
However, this is not a big issue; we focus on effectiveness rather than advertisements.
Recently at CMU, researchers conducted a fair, in-depth, and repeatable experimental test, focusing on comparing the strengths and weaknesses of Gemini and GPT in various tasks, while also including the open-source competitor Mixtral.
Paper link: https://arxiv.org/abs/2312.11444
Code link: https://github.com/neulab/gemini-benchmark
The researchers conducted an in-depth exploration of Google Gemini’s language capabilities in the paper,
objectively comparing the abilities of OpenAI GPT and Google Gemini models from a third-party perspective, and publicly releasing the code and comparison results.
We can find the areas where the two models excel.
The researchers compared the accuracy of six different tasks:
– Knowledge-based QA (MMLU)
– Reasoning (BIG-Bench Hard)
– Mathematics (GSM8k, SVAMP, ASDIV, MAWPS)
– Code Generation (HumanEval, ODEX)
– Web Instruction Tracking (WebArena)
To ensure fairness, all variables were controlled in the experiments, using the same prompts, generation parameters, and evaluations for all models.
LiteLLM was used in the evaluations to query the models in a unified manner, and try_zeno was used for comprehensive in-depth analysis.
The study compared Gemini Pro, GPT-3.5 Turbo, GPT-4 Turbo, and Mixtral, highlighting their differences in capabilities.
Features: Gemini Pro is multimodal, trained using videos, text, and images. GPT-3.5 Turbo and GPT-4 Turbo are primarily text-based, with GPT-4 Turbo being multimodal.
Testing Reproduction Methods
For easier reproduction, click the link below to enter the CMU integrated Zeno-based AI evaluation platform for verification
GitHub link:
https://github.com/neulab/gemini-benchmark]
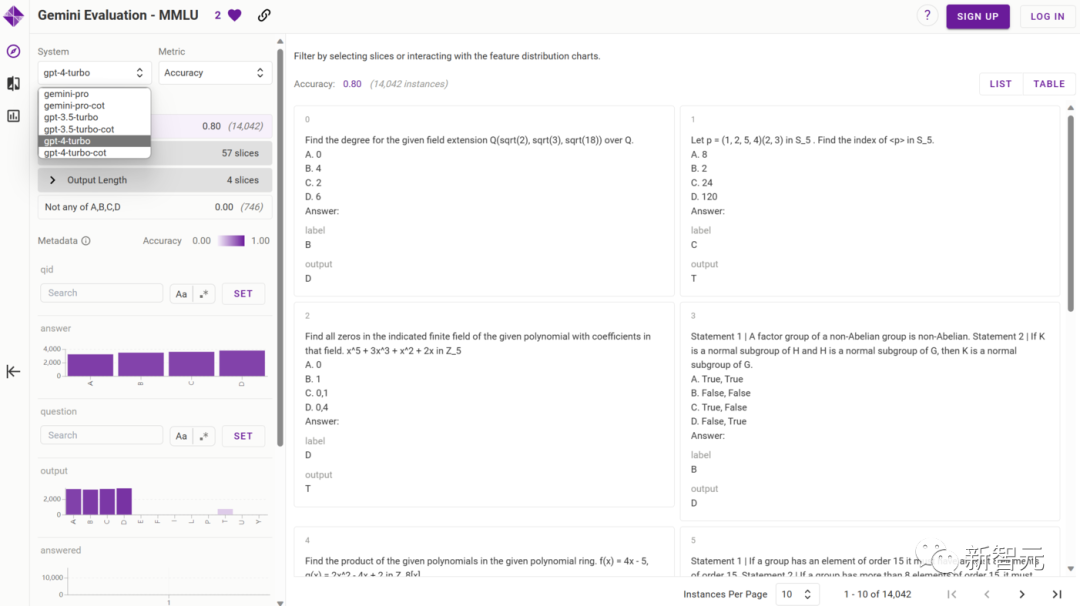
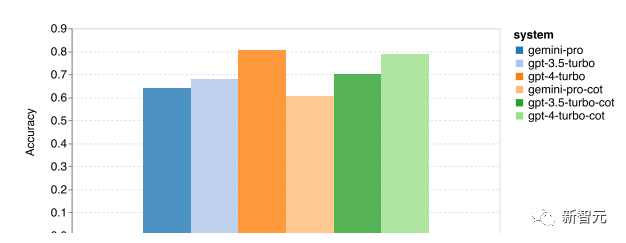
Knowledge-based Question Answering (Knowledge-based QA)
Based on the MMLU (Massive Multitask Language Understanding) evaluation proposed by UC Berkeley in 2020
This test covers 57 tasks, including elementary mathematics, US history, computer science, law, etc. The knowledge covered by the tasks is extensive, and the language is English, used to evaluate the basic knowledge coverage and understanding ability of large models.
The overall accuracy of the MMLU tasks with 5-shot and chain-of-thought prompts is shown in the figure below, with Gemini Pro slightly lagging behind GPT-3.5 Turbo
The article also points out that the performance difference using chain-of-thought prompts is minimal, possibly because MMLU is primarily a knowledge-based question answering task that may not significantly benefit from stronger reasoning-oriented prompts.
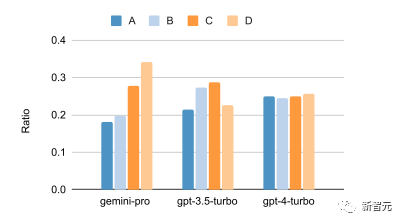
The following figure shows the ratio of answer outputs for multiple-choice questions by Gemini Pro, gpt3.5-turbo, and gpt-4-turbo, revealing that both Gemini Pro and gpt3.5-turbo exhibit some answer bias, especially Gemini Pro strongly favors option D
This indicates that Gemini has not undergone extensive instruction tuning to address multiple-choice question issues, which may lead to biases in answer ordering.
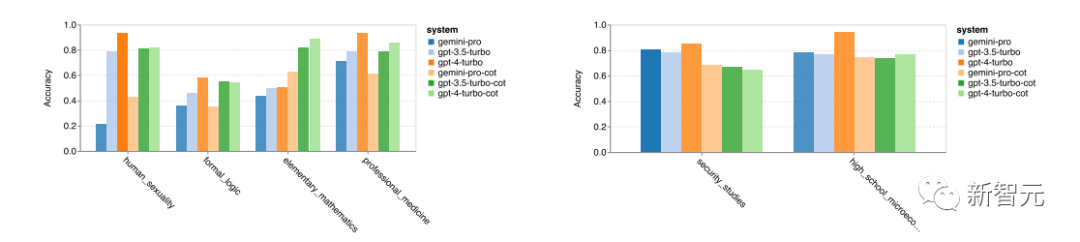
Among the 57 sub-tasks of MMLU, only two tasks saw Gemini Pro outperform GPT3.5-turbo.
The following figure shows the accuracy of the top four tasks where gpt3.5 leads Gemini Pro, and the two tasks where Gemini Pro surpasses gpt3.5
General-purpose Reasoning
Based on the BBH (BIG-Bench Hard) general-purpose reasoning dataset, which includes arithmetic, symbolic, and multilingual reasoning as well as factual understanding tasks.
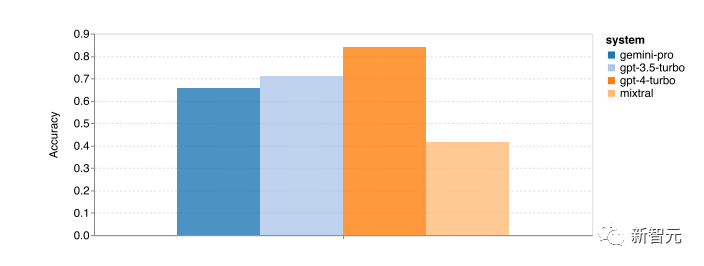
First, the overall accuracy figure shows that Gemini Pro achieves slightly lower accuracy than GPT 3.5 Turbo and is far below GPT 4 Turbo. In contrast, the Mixtral model’s accuracy is much lower.
Next, some detailed analyses were conducted, first testing accuracy based on question length, with the results shown in the figure below.
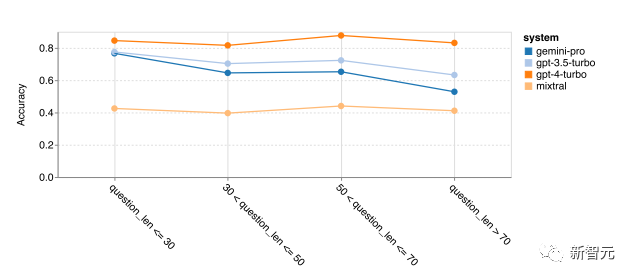
The author found that Gemini Pro performs poorly on longer, more complex questions, while the GPT models are more robust in this regard.
GPT-4 Turbo performs especially well, showing almost no performance drop even on longer questions, indicating its strong ability to understand longer and more complex queries.
GPT-3.5 Turbo’s robustness is in the middle. Mixtral is particularly stable in terms of question length but has a much lower overall accuracy.
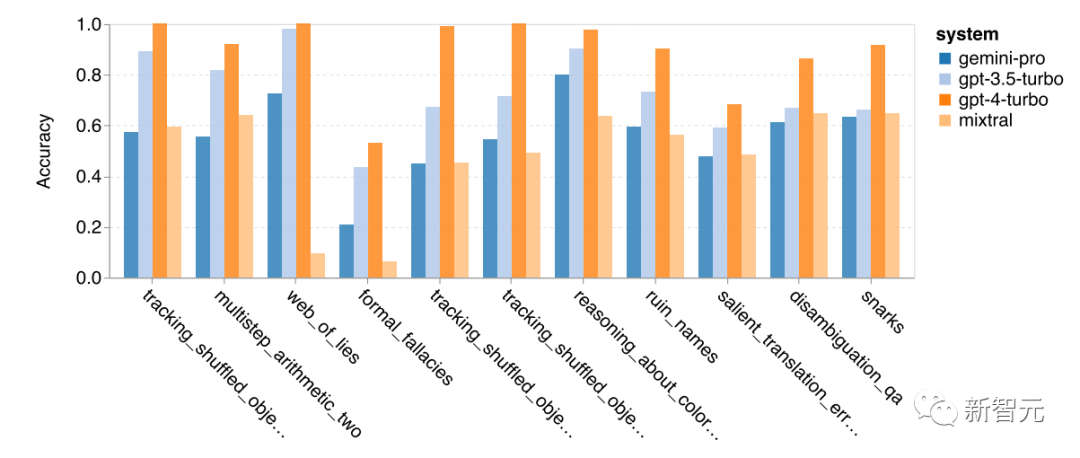
The following figure details the tasks where GPT-3.5 Turbo outperforms Gemini Pro the most.
Gemini Pro performs poorly on the tracking_shuffled_objects task
In some tasks, such as multistep_arithmetic_two, salient_translation_error_detection, snarks, disambiguation_qa, and two tracking_shuffled_objects tasks, Gemini Pro’s performance is even worse than that of the Mixtral model.
Of course, there are some tasks where Gemini Pro outperforms GPT3.5.
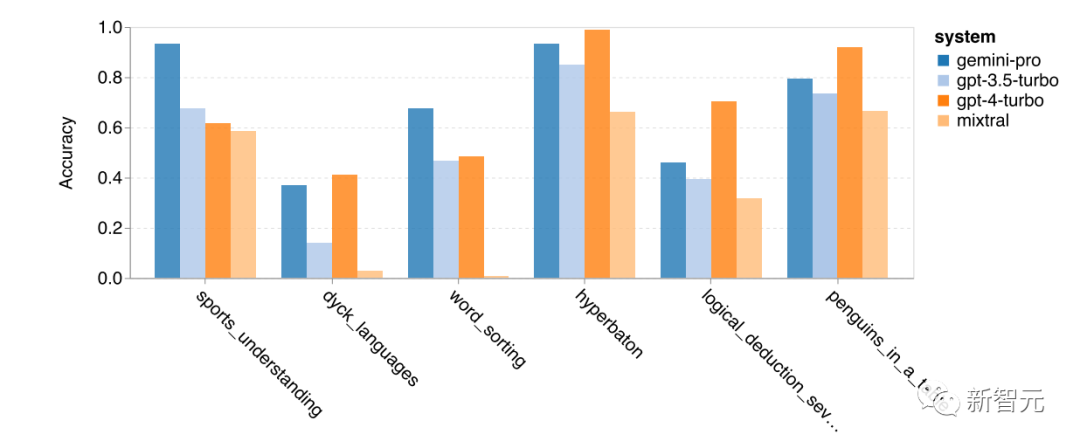
The following figure shows the six tasks where Gemini Pro performs better than GPT 3.5 Turbo. These tasks require world knowledge (sports_understanding), operator stack manipulation (dyck_languages), alphabetical sorting of words (word_sorting), and table parsing (penguins_in_a_table).
The article concludes this section by stating that for general reasoning tasks, it seems that neither Gemini nor GPT has an absolute advantage, so both can be tried.
Based on four math application problem evaluations:
– GSM8K, elementary math benchmark
– SVAMP dataset, checking robust reasoning ability through different word orders for problem generation,
– ASDIV dataset, with different language patterns and problem types
– MAWPS benchmark, consisting of arithmetic and algebra application problems.
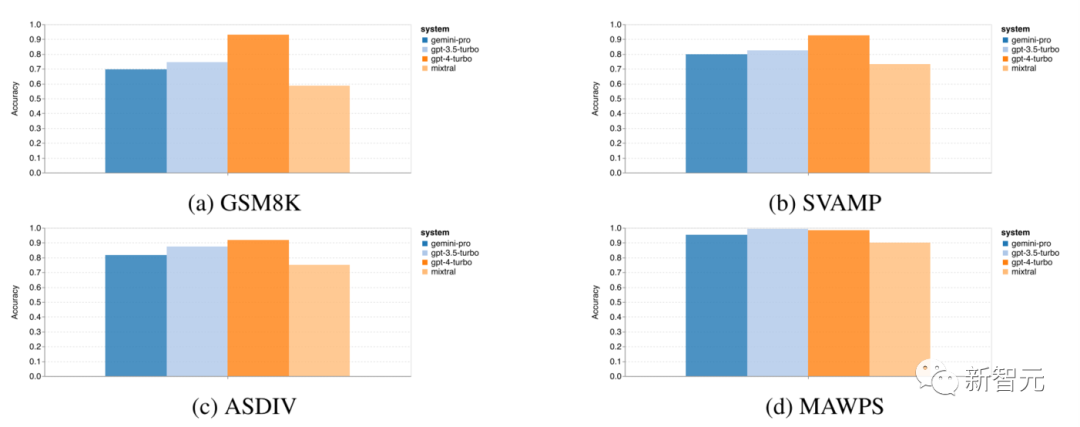
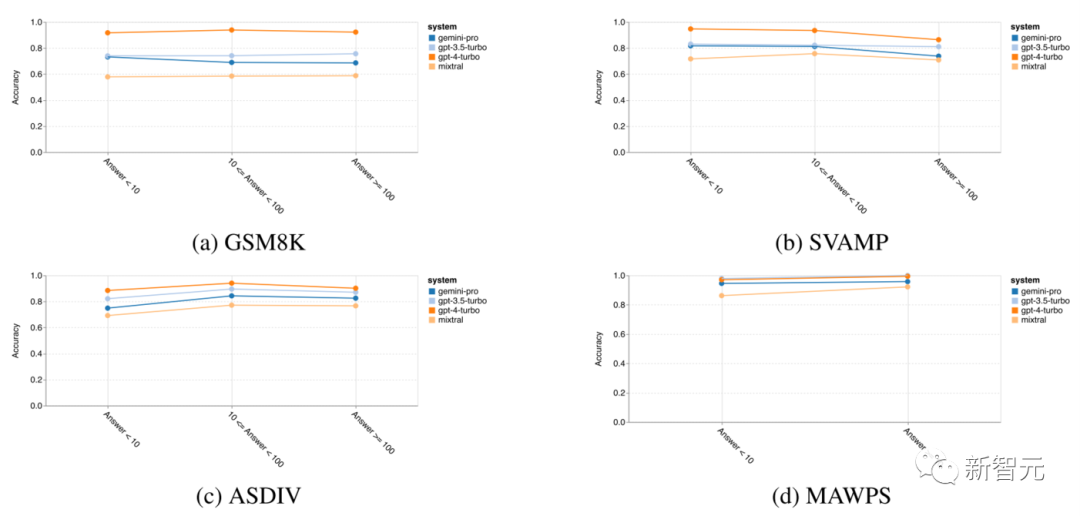
The following figure shows the overall accuracy of the four mathematical reasoning tasks
From the figure, it can be seen that in the GSM8K, SVAMP, and ASDIV tasks, Gemini Pro’s accuracy is slightly lower than that of GPT-3.5 Turbo and far below that of GPT-4 Turbo, all of which involve diverse language patterns.
For the MAWPS task, all models achieved over 90% accuracy, although Gemini Pro still performed slightly worse than the GPT models.
Interestingly, in this task, GPT-3.5 Turbo performed slightly better than GPT-4 Turbo.
In contrast, the Mixtral model’s accuracy is much lower than that of the other models.
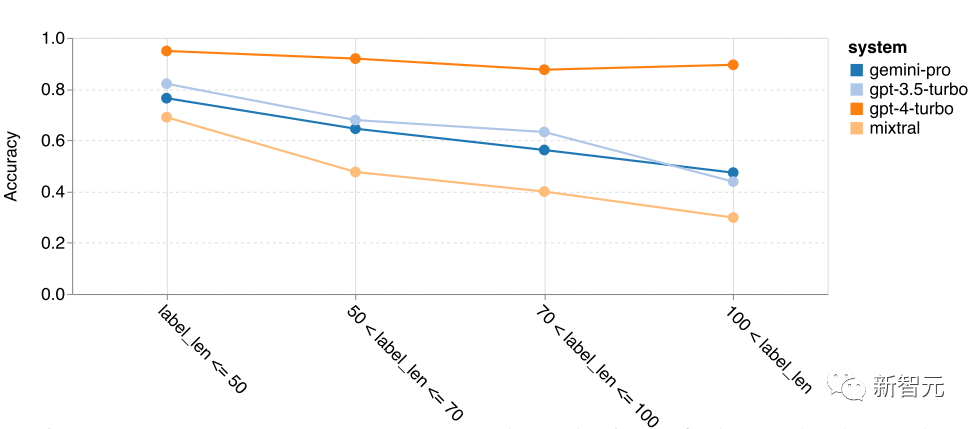
As seen in previous BBH reasoning tasks, we can observe that longer task reasoning performance declines.
As before, GPT 3.5 Turbo outperforms Gemini Pro on shorter questions but declines faster; Gemini Pro achieves similar (though still slightly inferior) accuracy on longer questions.
However, in the most complex examples where the chain-of-thought (CoT) length exceeds 100, Gemini Pro outperforms GPT 3.5 Turbo, but performs poorly on shorter examples.
Finally, the article studies the accuracy of the comparative models in generating answers of different digit lengths.
Three categories were created based on the number of digits in the answers: one-digit, two-digit, and three-digit answers (except for the MAWPS task, where answers do not exceed two digits).
As shown in the figure below, GPT-3.5 Turbo appears to be more robust for multi-digit math problems, while Gemini Pro’s performance declines more on problems with more digits.
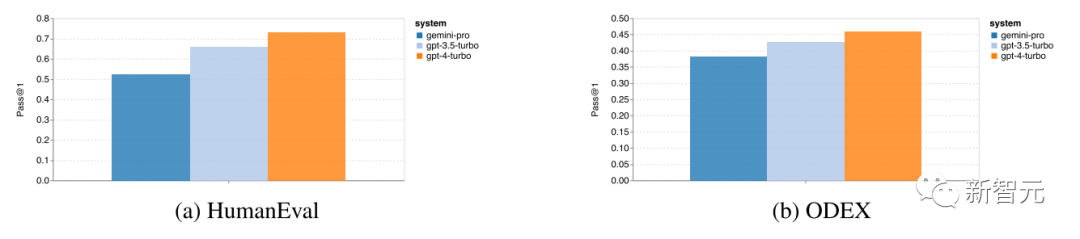
In this category, the article uses two code generation datasets, HumanEval and ODEX, to examine the coding capabilities of the models.
The former tests basic code understanding of a limited set of functions in the Python standard library.
The latter tests the ability to use a broader range of libraries from the entire Python ecosystem.
Both use human-written English task descriptions (usually with test cases) as input. These problems are used to evaluate understanding of language, algorithms, and elementary mathematics.
Overall, HumanEval has 164 test samples, and ODEX has 439 test samples.
The overall situation of code generation is shown in the figure below:
Gemini Pro’s Pass@1 scores on both tasks are lower than those of GPT-3.5 Turbo and far below those of GPT-4 Turbo.
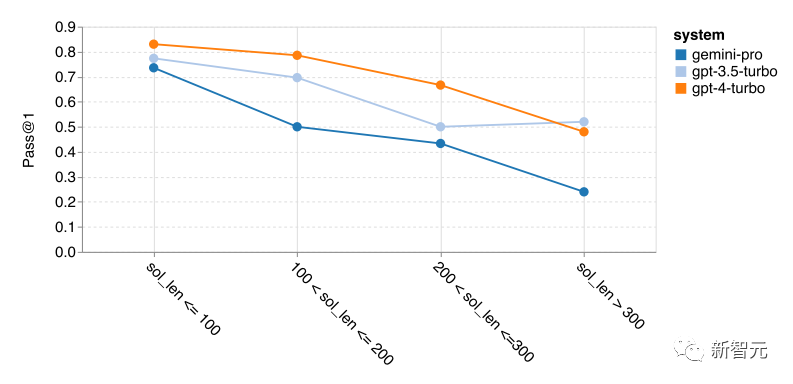
Next, the relationship between the optimal solution length and model performance was analyzed, as the solution length can somewhat indicate the difficulty of the corresponding code generation task.
The article finds that when the solution length is below 100 (representing simple problems), Gemini Pro can achieve Pass@1 scores comparable to GPT-3.5, but when the solutions become longer (i.e., dealing with more difficult problems), it falls significantly behind.
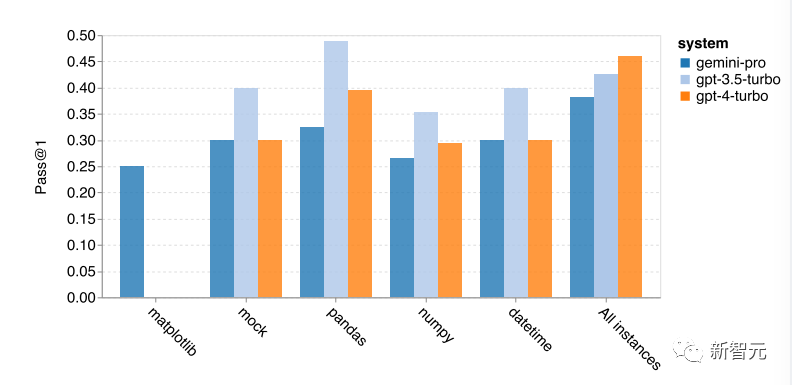
The article also analyzes how the libraries required for each solution impact model performance, as shown in the figure below:
According to the results, in most cases using libraries like mock, pandas, numpy, and datetime, Gemini Pro performs worse than GPT-3.5.
However, it outperformed GPT-3.5 and GPT-4 in the case of matplotlib, demonstrating stronger capabilities when it comes to plotting and visualization through code execution.
Below are several specific failure cases:
First, Gemini is slightly inferior in correctly selecting functions and parameters from the Python API
For example, when you give the following instruction
def f_3283984(): """decode a hex string '4a4b4c' to UTF-8."""
Gemini Pro generates the following code, leading to a type mismatch error.
bytes(bytearray.fromhex('4a4b4c'), 'utf-8')
In contrast, GPT 3.5 Turbo uses the following code, achieving the expected result:
hex_string = '4a4b4c'decoded_string = bytes.fromhex(hex_string).decode('utf-8')return decoded_string
Additionally, Gemini Pro has a higher error rate, and the generated code is syntactically correct but does not correctly match complex intents.
For example, for the following instruction
from typing import Listdef remove_duplicates(numbers: List[int]) -> List[int]: """From a list of integers, remove all elements that occur more than once. Keep order of elements left the same as in the input. >>> remove_duplicates([1, 2, 3, 2, 4]) [1, 3, 4] """
Gemini Pro’s code only extracts unique numbers without removing those that occur multiple times.
seen_numbers = set()unique_numbers = []for number in numbers: if number not in seen_numbers: unique_numbers.append(number) seen_numbers.add(number)return unique_numbers
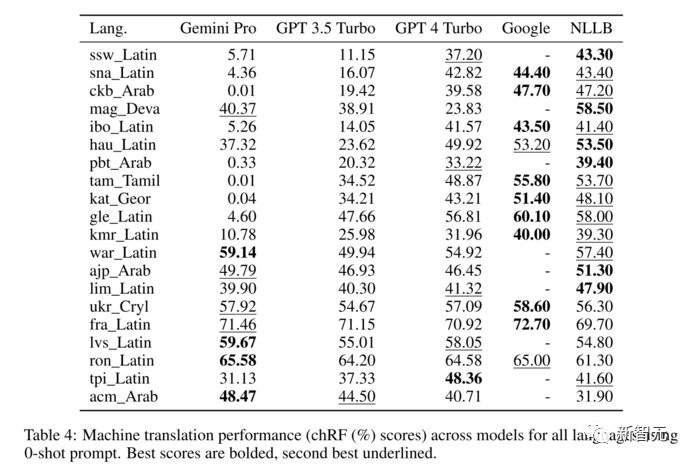
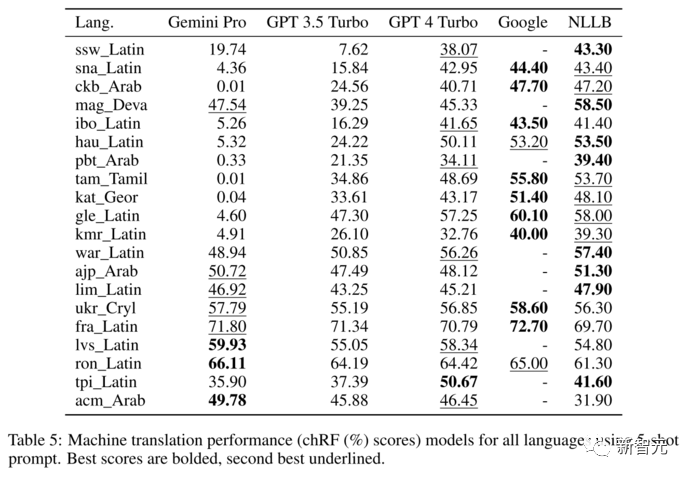
Based on the FLORES-200 machine translation benchmark, assessing the model’s multilingual capabilities, particularly in translation between various language pairs.
For all selected language pairs, 1012 sentences in the test set were evaluated. As the first step of this study, the scope was limited to translations from English to other languages (ENG→X).
The results are shown in the figure below, with Gemini Pro outperforming other models in translation tasks, excelling in 8 out of 20 languages compared to GPT-3.5 Turbo and GPT-4 Turbo, achieving the highest performance in 4 languages.
Although it has not surpassed dedicated machine translation systems in non-English language translations, general language models also show competitively strong performance.
Zero-shot and five-shot prompts show that Gemini Pro outperforms other models in translation tasks
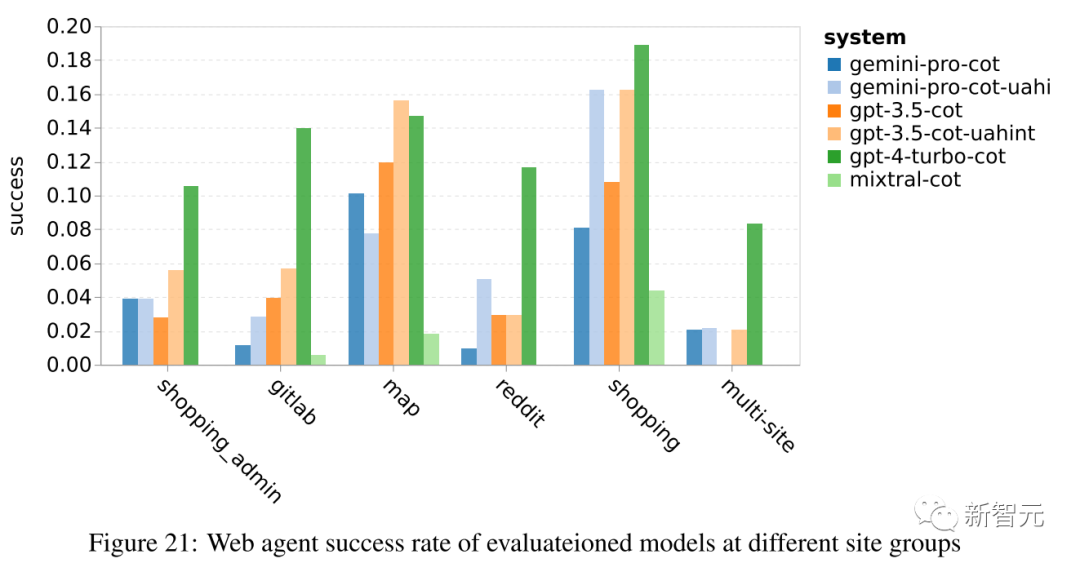
Finally, this article verifies the ability of each model to act as a web navigation agent, a task requiring long-term planning and complex data understanding.
Using WebArena, a command-execution-based simulation environment where success criteria are based on execution results. The tasks assigned to the agents include information retrieval, site navigation, and content and configuration operations.
These tasks span various websites, including e-commerce platforms, social forums, collaborative software development platforms (e.g., GitLab), content management systems, and online maps.
The overall results from the article show that Gemini-Pro’s performance is comparable to that of GPT-3.5-Turbo, though slightly inferior.
Similar to GPT-3.5-Turbo, when prompts indicate that tasks may not be completed (UA prompts), Gemini-Pro performs better. With UA prompts, Gemini-Pro’s overall success rate reaches 7.09%.
Subsequently, the article further breaks down the web performance, as shown in the figure below, revealing that Gemini-Pro performs worse than GPT-3.5-Turbo on GitLab and maps, while it is close to GPT-3.5-Turbo on shopping management, Reddit, and shopping. It performs better than GPT-3.5-Turbo on multi-site tasks.
In this article, the author conducted the first fair and in-depth study of Google’s Gemini model, comparing it with OpenAI’s GPT 3.5 and 4 models, as well as the open-source Mixtral model.
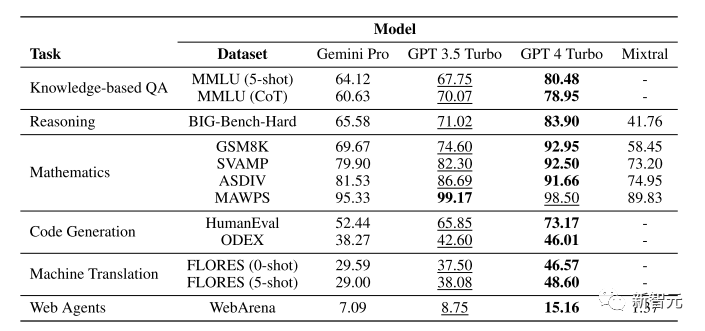 Main results of the CMU evaluation, with bold black indicating the best model and underlining the second
Main results of the CMU evaluation, with bold black indicating the best model and underlining the second
Finally, the author added some notes:
Pointing out that their work is aimed at a changing and unstable API, all results are the latest as of the date of writing this article, December 19, 2023, but may change in the future as models and surrounding systems are upgraded.
The results may depend on the specific prompts and generation parameters chosen.
The author did not use multiple samples and self-consistency (self-consistency) in the way Google does, but believes that testing different models using consistent prompts across multiple tasks can reasonably demonstrate the robustness and adherence to general instructions of the tested models.
The author notes that data leakage troubles current large model evaluation tasks; although they did not explicitly measure this leakage, they attempted various methods to mitigate the issue.
In the outlook, the author also suggests that everyone should evaluate whether Gemini Pro is indeed comparable to GPT 3.5 Turbo according to this paper before using it. The author also mentioned that the Ultra version of Gemini has not yet been released, and once it is released, they will verify whether it is indeed comparable to GPT-4 as reported.
https://arxiv.org/abs/2312.11444