Telling GPT-4: “Hey, no worries. I’m quite happy here with Google’s Gemini.”
Telling GPT-4: “Hey, no worries. I’m quite happy here with Google’s Gemini.”
Just early this morning, after a long wait, Google launched its latest artificial intelligence model Gemini (Gemini).

This model, claimed by Google to be the largest and most powerful AI model, looks incredibly advanced just from the official demonstration video.
In the video, Gemini not only recognizes the drawings, videos, tricks, and pranks performed by the presenter in seconds, but also responds fluently throughout the process, using various interjections skillfully.
If it weren’t mentioned beforehand, you might even think this is JARVIS from a movie.
If it’s really that impressive, why do we need GPT-4?
However, upon closer inspection, it turns out that the released Gemini is actually a family of large models, including “Medium” Gemini Nano, “Large” Gemini Pro, and “Extra Large” Gemini Ultra.
Currently, the version available to everyone is Gemini Pro, while most of the test demonstrations are based on the “Extra Large” Gemini Ultra.

From the data released by the official source, while each version has its suitable environment, the performance differences between different versions are still quite significant.
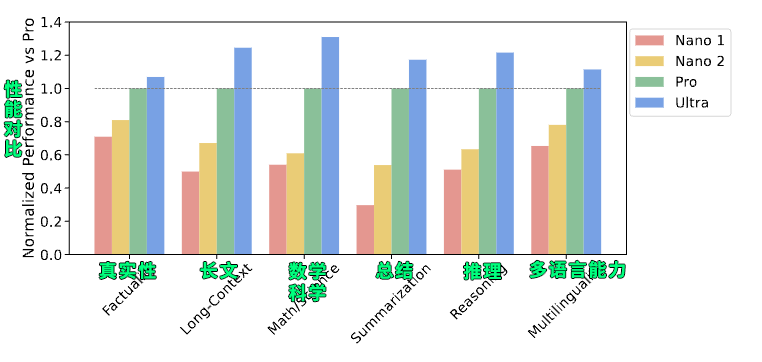
 The capabilities of the Extra Large Gemini Ultra are indeed outstanding.
The capabilities of the Extra Large Gemini Ultra are indeed outstanding.
It not only outperforms GPT-4 in various conventional tests.
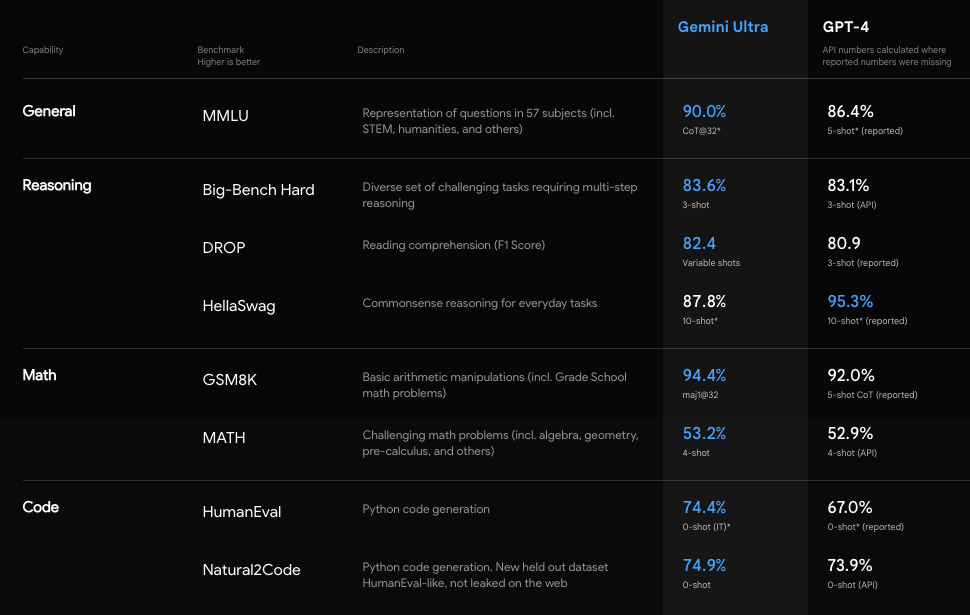
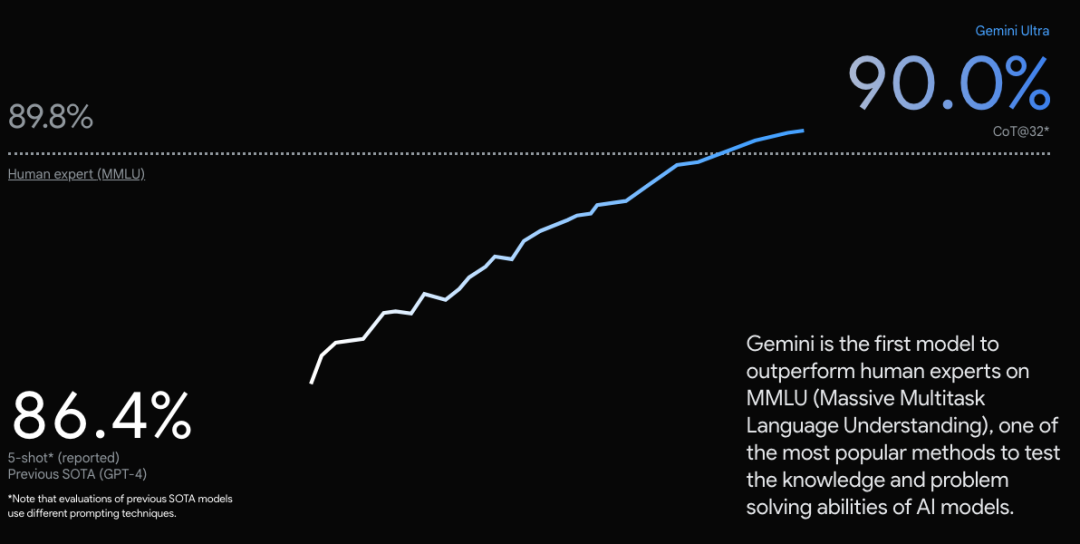
In fact, in the MMLU (Massive Multitask Language Understanding) test, Gemini Ultra not only surpassed GPT-4 but also outperformed human experts, becoming the first model to exceed humans in this area.
Besides its overall superiority over GPT-4 in conventional capabilities, Gemini’s most unique feature is that it is Google’s first multimodal large model, meaning it can interact not only through text but also through voice, video, and images.
According to Google, existing so-called multimodal large models have all separately trained text, visual, and audio models, which are then stitched together.
This results in a “bulk” multimodal large model that, when faced with images, text, audio, or video appearing simultaneously, only decomposes the different modules to answer individually and then summarizes the responses from each part to form an answer.
 In contrast, Gemini is fundamentally a multimodal model, trained with a large amount of multimodal data, allowing it to understand multimodal inputs synchronously from the start.
In contrast, Gemini is fundamentally a multimodal model, trained with a large amount of multimodal data, allowing it to understand multimodal inputs synchronously from the start.
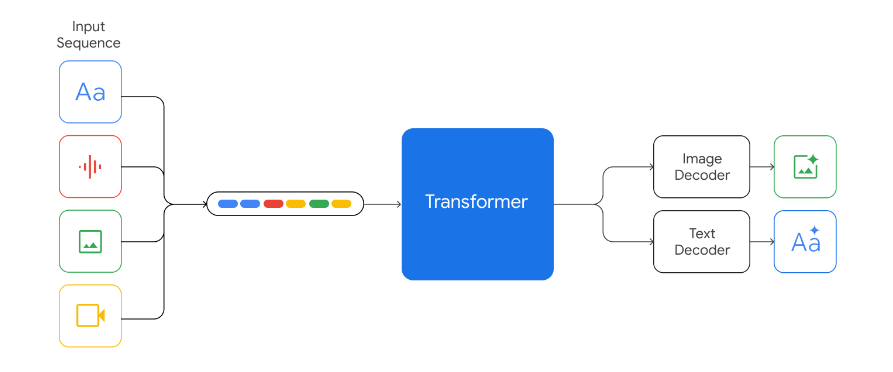
This is akin to encountering a mixed-language tourist group from China, Japan, and Korea, where previously, guides fluent in the respective languages would be assembled to lead the group.
However, Gemini’s approach is to hire a guide who is fluent in Chinese, Japanese, Korean, and English, allowing one person to seamlessly manage all tourists.
Therefore, it is not surprising that in the previous multimodal tests where GPT-4V was “far ahead,” Gemini also demonstrated a comprehensive superiority.

However, it appears so impressive that it seems unrealistic, leading to quite a bit of skepticism online.
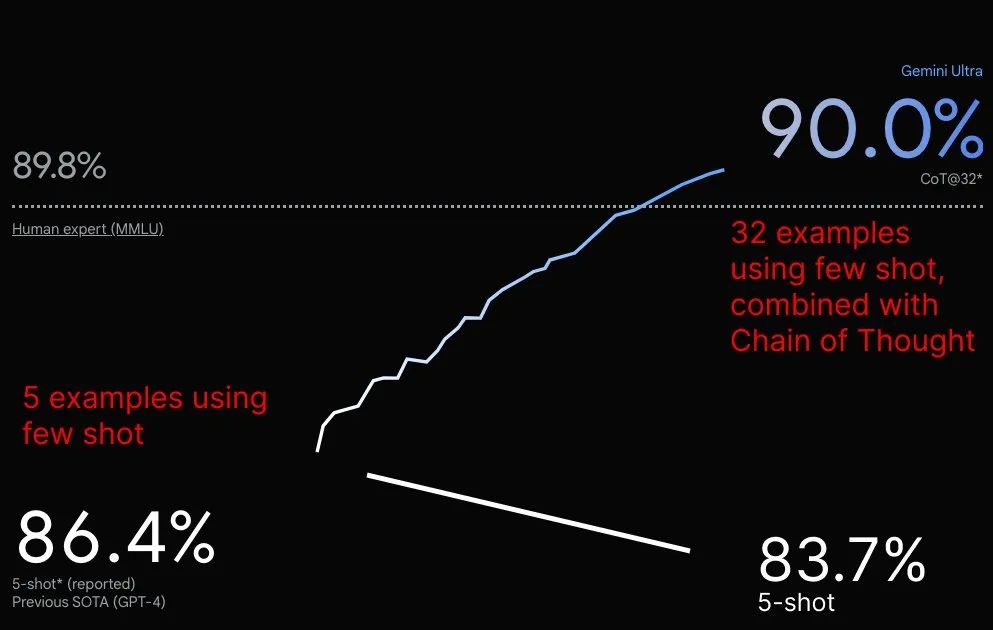
For example, some people complain that the difference between 90.0% and 89.8% is just two-thousandths, yet the graph makes it look like a huge improvement.
 Moreover, many have noticed that in several tests, Google employed some manipulative techniques.
Moreover, many have noticed that in several tests, Google employed some manipulative techniques.

For instance, the testing methods used for Gemini Ultra and GPT-4 were not the same; Gemini Ultra used a newly developed method called CoT@32*.
Under this new method, GPT-4’s score improved only modestly, while Gemini showed significant progress.
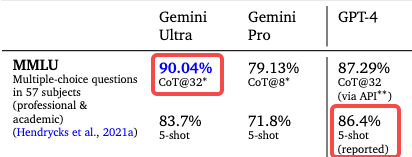
However, if Gemini Ultra and GPT-4 were held to the same standard, its score would only be 83.7, which is lower than GPT-4.
In fact, many suspect that the interactive demonstration video was also a edited promotional showcase, and the actual performance is nowhere near as impressive.
 We don’t need to concern ourselves with these true or false antics, as Google has already utilized the fine-tuned Gemini Pro in Bard, so we can directly see how much this upgraded Bard can improve.
We don’t need to concern ourselves with these true or false antics, as Google has already utilized the fine-tuned Gemini Pro in Bard, so we can directly see how much this upgraded Bard can improve.
However, the currently adjusted Bard only supports English, so we brought in the GPT-4V version of ChatGPT to have a friendly competition in English.

According to Google, this time Gemini has made the greatest progress in multimodal capabilities, so today, we mainly test this aspect.
First, we tested their basic knowledge by sending them a photo of the Badaling Great Wall to see if they could guess where it is.
 Unexpectedly, Bard immediately gave ChatGPT a wake-up call, accurately identifying Badaling Great Wall.
Unexpectedly, Bard immediately gave ChatGPT a wake-up call, accurately identifying Badaling Great Wall.
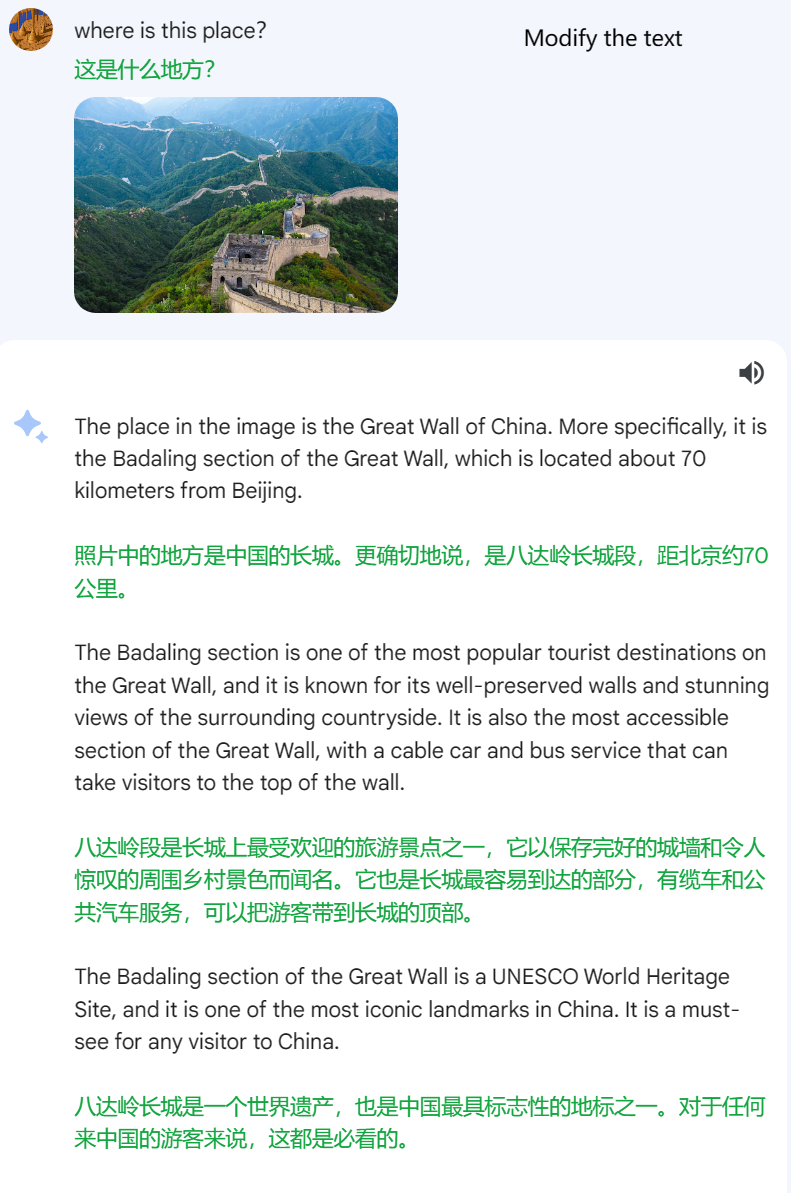
On the other hand, ChatGPT seemed a bit hesitant, only providing the answer of the Great Wall without specifying which section it was.
However, horses can stumble, and an occasional mistake is nothing to worry about. To further test their image recognition capabilities, I asked them to identify the model of a car.
They both provided the correct answer: Chevrolet Corvette.
However, Bard provided more details, including the engine model, horsepower, and acceleration, which matched up with the facts, whereas ChatGPT simply gave a brief answer, mentioning it was cost-effective.

 Being able to recognize these proper images does not demonstrate significant capability, as this is now a basic requirement for large models.
Being able to recognize these proper images does not demonstrate significant capability, as this is now a basic requirement for large models.
So, I searched for some meme images online to test their understanding of complex human thoughts.
First, I used a meme of a dog wearing a protective headgear.
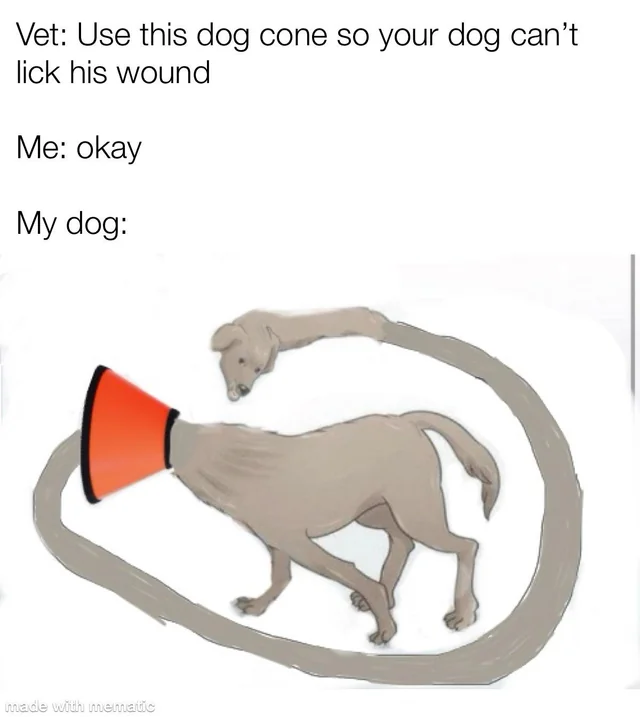
Bard and ChatGPT both provided similar answers, noting that the dog wants to lick its wound while wearing the protective gear.

 Next, I tested a meme of a cat, which should resonate with many workers.
Next, I tested a meme of a cat, which should resonate with many workers.

Bard not only recognized the meaning of people’s dislike for Mondays but also identified this as a famous internet cat from 2012.

ChatGPT’s response was quite concise, capturing the meaning but not providing as much detail, making it comparable to Bard.

After all, humor, as a form of understanding and resonance with things that are witty, absurd, or illogical,…
To comprehend memes and understand humor, AI needs to possess the ability to understand human emotions, experiences, and cultural backgrounds.
Of course, as someone who writes every day, I also wanted to test its chart analysis capabilities, hoping it might become a productivity tool for me…
I randomly found a bar chart from the U.S. Department of the Treasury’s official website to see how much information they could extract.
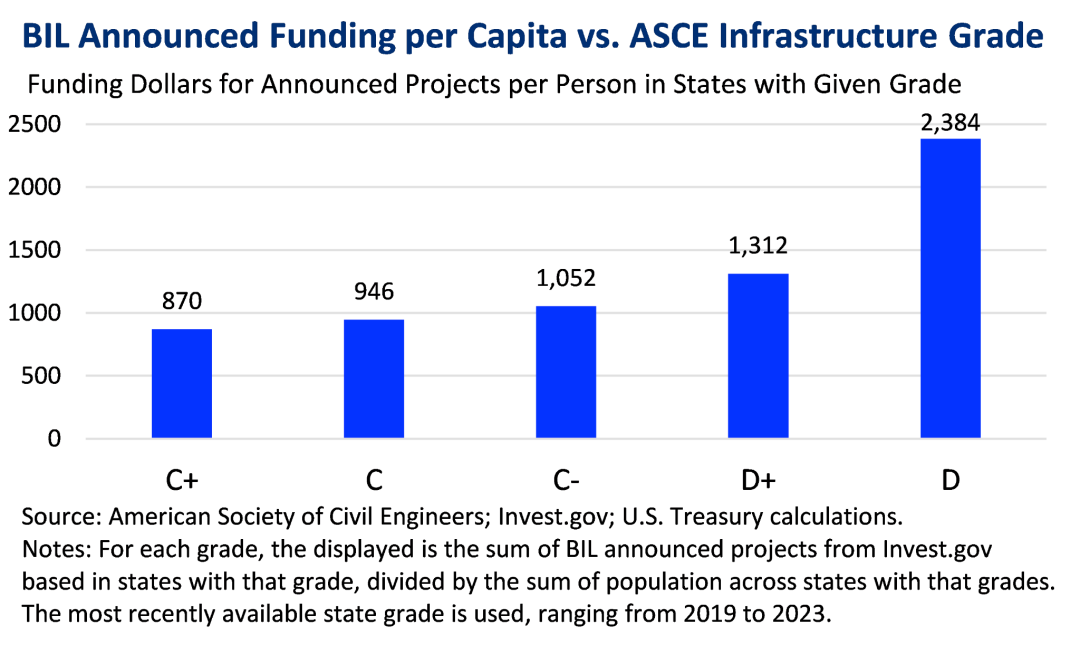
In this area, Bard and ChatGPT were difficult to distinguish, both accurately identifying that the U.S. will increase investment in lower-tier infrastructure states.

There were only slight differences in the order of their expressions, so the choice depends on personal preference. However, I would say Bard is more appealing for free users.

Finally, we tested the nightmare of large models, which is math problems, to assess their mathematical abilities.
The first question was a middle school-level geometry problem, asking them to calculate the angle of ABO.
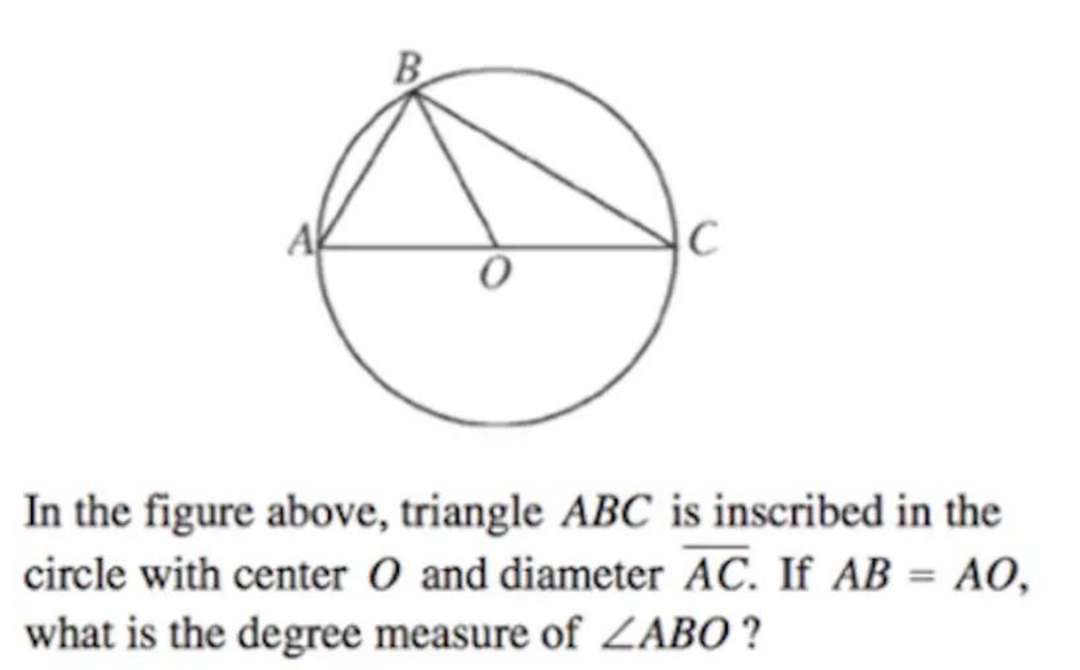
Bard quickly identified that ABO is an equilateral triangle, providing the answer that ABO is 60°.

 However, ChatGPT’s answer was surprising, giving 45° instead.
However, ChatGPT’s answer was surprising, giving 45° instead.

In another question, regarding which points are continuous but not differentiable, Bard slightly outperformed ChatGPT.
Those with some calculus background should recognize that C: x=-2 and x=1 are the correct answers.
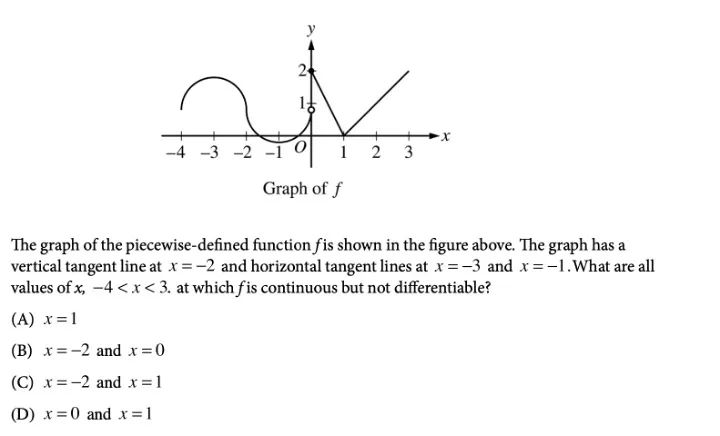
Bard steadily selected the correct answer C.
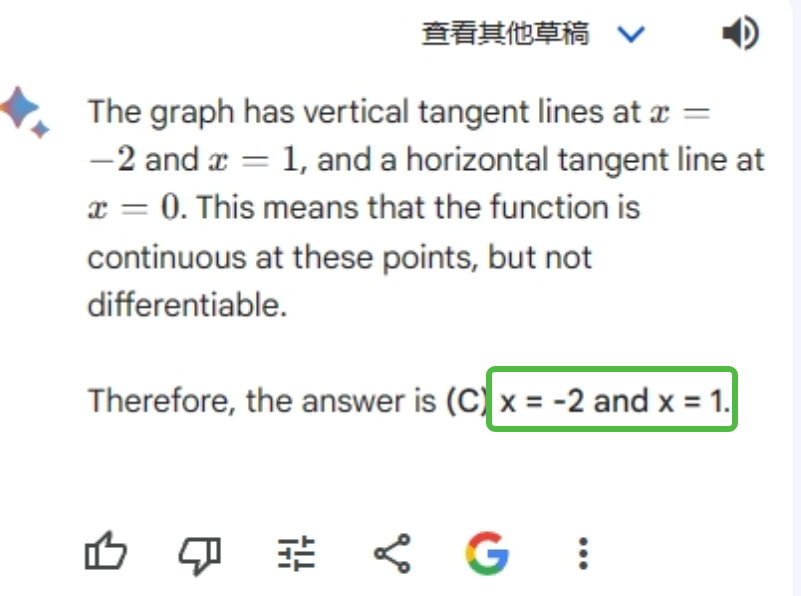
ChatGPT continued to play it safe, hesitantly choosing the answer B, which it thought was the most likely.

 Overall, after several rounds of comparative testing, I finally encountered a model that can hold its own against GPT-4V and even has some advantages.
Overall, after several rounds of comparative testing, I finally encountered a model that can hold its own against GPT-4V and even has some advantages.
In a few days, on the 13th, developers and enterprise users will also be able to directly call the API for Gemini Pro.
Additionally, Google plans to integrate Gemini into Pixel devices, with the Pixel 8 Pro being the first smartphone to run Gemini Nano.
In the coming months, Gemini will successively combine with services and products such as Search, Ads, and Chrome.
As for the paper strength of Gemini Ultra, which “overwhelms” GPT-4V, we will have to wait until early next year to experience it in Bard Advanced.

 Finally, I want to say, as the saying goes, “It’s hard for giants to turn around…” Many people use this metaphor to describe Google’s predicament in the new AI era.
Finally, I want to say, as the saying goes, “It’s hard for giants to turn around…” Many people use this metaphor to describe Google’s predicament in the new AI era.
After all, when Bard was released in the first half of the year, there were even quite a few blunders due to its rushed launch.

The story of Google’s AI going from leading the pack to becoming a follower of OpenAI has seemingly become a classic case of “Shang Zhongyong” in the tech circle.
However, I believe that the “difficulty” of giants turning around has at least two levels of logic behind it.
The first level is about willingness to turn around, and the second level concerns success.
 Whether it’s Kodak, which shelved the “digital camera,” or Nokia, which clung to the Symbian system until 2013, they encountered issues at the first level.
Whether it’s Kodak, which shelved the “digital camera,” or Nokia, which clung to the Symbian system until 2013, they encountered issues at the first level.
We can also see that at least in terms of willingness to turn around, Google has no complaints.
Currently, Gemini gives me the impression that, while it may not have the same stunning effect as when I first encountered ChatGPT, it is at least at the level that Google should have.
After all, let’s not forget that when Ultraman, Musk, and others founded OpenAI, one of their goals was to break Google’s monopoly in the AI field.
Including the “T” in “GPT,” which stands for Transformer, was originally proposed by Google’s team.
And now, having woken up early but arrived late, Google has at least caught up with the pace.
Of course, on the road to AGI, I cannot say who among Google, OpenAI, or others will reach the finish line first or whether their direction is correct.
But it cannot be denied that if a powerful giant successfully turns around, finds the right direction, and hits the gas…
Then, it’s likely that no one can stop it.
Written by: Bajie & Squirrel & Jiangjiang Edited by: Jiangjiang & Dabing & Mianxian Cover: Xuanxuan
Image and Data Sources:
Google DeepMind, Bard, ChatGPT