

Can process 1 hour of video, 11 hours of audio, and over 30,000 lines of code at once.
On February 16, Zhiyuan reported that Google released its latest achievement in the large model matrix – Gemini 1.5, extending the context window length to 1 million tokens.
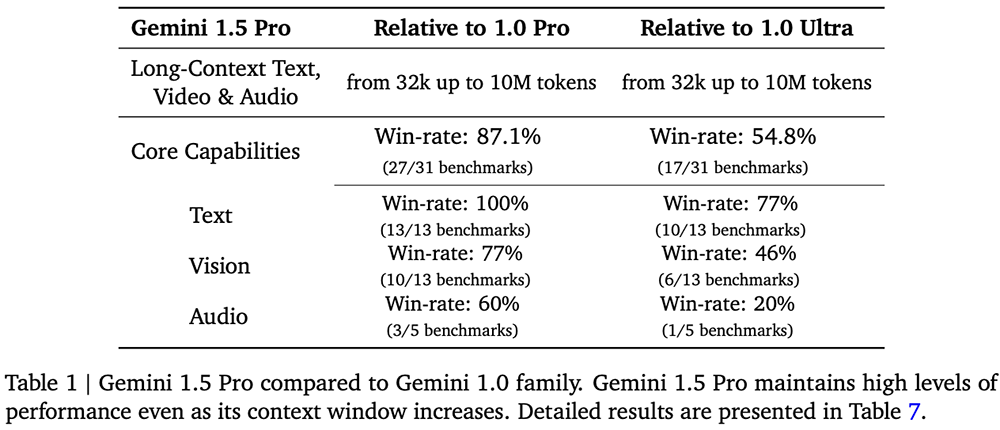
Gemini 1.5 Pro achieves a quality comparable to 1.0 Ultra while using less computation. This model has made breakthroughs in understanding long contexts, significantly increasing the amount of information the model can process – running continuously with up to 1 million tokens, achieving the longest context window in any large foundational model to date.
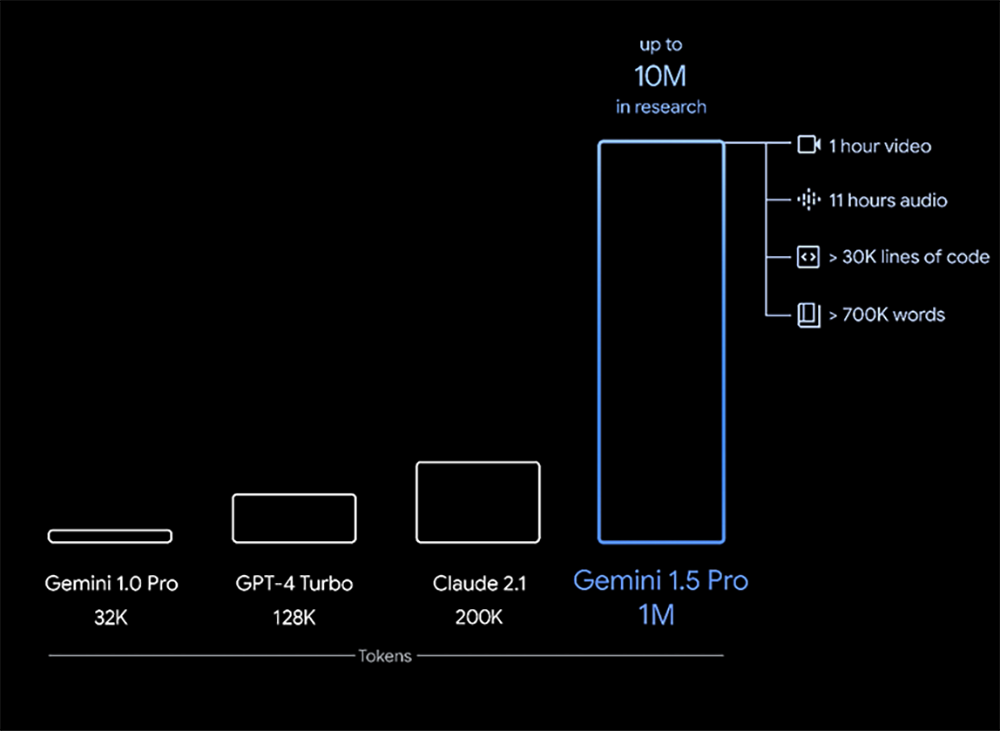
This means that Gemini 1.5 Pro can process a large amount of information at once – including 1 hour of video, 11 hours of audio, over 30,000 lines of code, or more than 700,000 words of codebase.
Starting today, Google will provide a limited preview of Gemini 1.5 Pro to developers and enterprise customers through AI Studio and Vertex AI.
Additionally, Google revealed that it has successfully tested up to 10 million tokens in research.

Article Benefit:58 pages《Gemini 1.5 Technical Report》, available by replying with the keyword 【Zhiyuan 408】 in the public account chat.
Based on Transformer and MoE architecture,
1 million tokens context window
Demis Hassabis, CEO of Google DeepMind, speaking on behalf of the Gemini team, stated that Gemini 1.5 provides significantly enhanced performance, representing a step change in their approach, built on research and engineering innovations across nearly every part of Google’s foundational model development and infrastructure, including training and servicing the model more efficiently through the new expert mixture (MoE) architecture.
The first Gemini 1.5 model released for early testing is Gemini 1.5 Pro. This is a medium-sized multimodal model optimized for a wide range of tasks, with performance comparable to Google’s largest model to date 1.0 Ultra. It also introduces a groundbreaking experimental feature in long context understanding.
The “context window” of AI models consists of tokens, which are the building blocks used to process information. The larger the context window, the more information it can receive and process in a given prompt, making its output more consistent, relevant, and useful.
Through a series of machine learning innovations, Google has significantly increased the context window capacity from the initial 32,000 tokens of Gemini 1.0 to 1.5 Pro’s 1 million tokens.
Gemini 1.5 Pro comes with a standard context window of 128,000 tokens. Starting today, a limited number of developers and enterprise customers can try out a private preview of the context window of up to 1 million tokens through AI Studio and Vertex AI. As Google actively works on optimizing the full 1 million tokens context window, it aims to improve latency, reduce computational demands, and enhance user experience.
Gemini 1.5 is built on Google’s research foundation on Transformer and MoE architectures. Traditional Transformers are large neural networks, while MoE models are divided into smaller “expert” neural networks.
Depending on the type of input given, MoE models learn to selectively activate the most relevant expert paths in their neural networks. This specialization greatly improves the efficiency of the model. Google has been an early adopter and research pioneer of MoE technology in deep learning.
The latest innovations in model architecture allow Gemini 1.5 to learn complex tasks faster while maintaining quality, enabling its team to iterate, train, and deliver more advanced versions of Gemini at a faster pace.
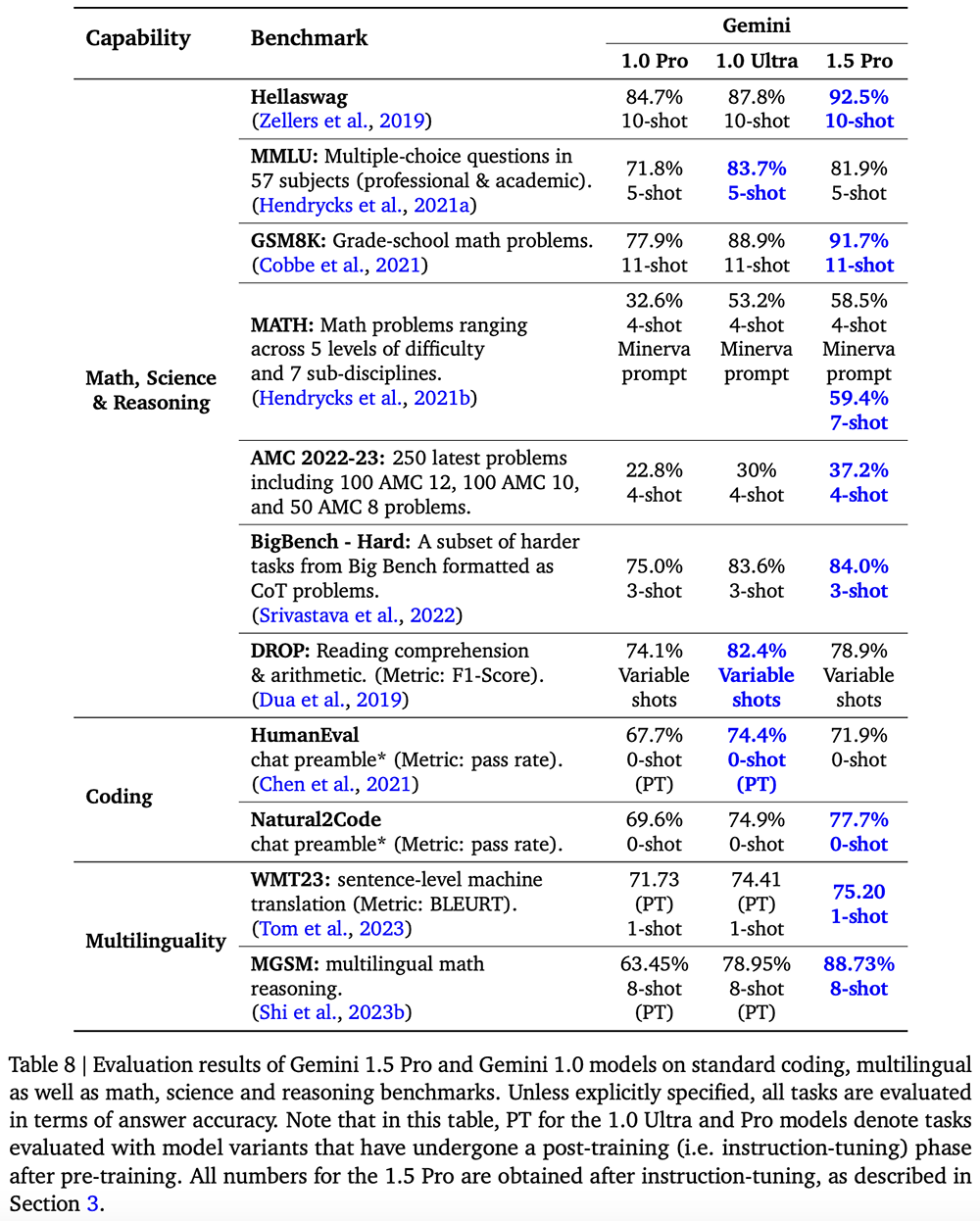
Can perform complex reasoning on large amounts of information,
Rare language translation approaches human level
Gemini 1.5 Pro seamlessly analyzes, classifies, and summarizes large amounts of content within a given prompt. For example, when given a 402-page record of the Apollo 11 moon landing mission, it can reason through the dialogues, events, and details within the document.
The model can understand, reason, and identify strange details within the 402-page record of the Apollo 11 moon landing mission.
Gemini 1.5 Pro can perform highly complex understanding and reasoning tasks across different modalities, including video. For instance, when given Buster Keaton’s 44-minute silent film, the model can accurately analyze various emotional points and events, even reasoning out small details that may easily be overlooked in the film.
When provided with simple line drawings as reference material for real-life objects, Gemini 1.5 Pro can identify scenes from Buster Keaton’s 44-minute silent film.
1.5 Pro can execute more relevant problem-solving tasks across longer blocks of code. When given a prompt containing over 100,000 lines of code, it can reason better through examples, suggest useful modifications, and explain how different parts of the code work.
Gemini 1.5 Pro can reason through 100,000 lines of code, providing useful solutions, modifications, and explanations.
When tested on a comprehensive evaluation panel of text, code, images, audio, and video, Gemini 1.5 Pro outperformed 1.0 Pro in 87% of the benchmarks used for developing large language models. In the same benchmarks, its performance level is roughly comparable to 1.0 Ultra.
Even with the increased context window, Gemini 1.5 Pro maintains high levels of performance. In the NIAH evaluation, embedding text containing specific facts or statements within a long block of text, Gemini 1.5 Pro found the probability of embedded text within a data block of up to 1 million tokens at 99%.
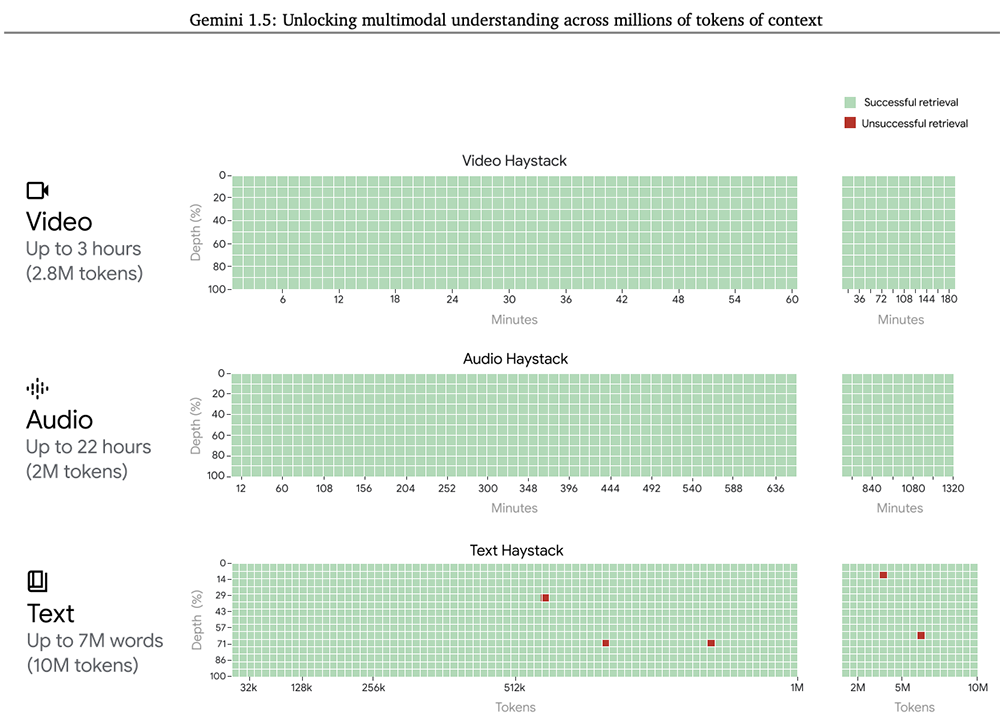
Gemini 1.5 Pro also demonstrates impressive “situational learning” skills, learning new skills from information provided over long prompts without additional fine-tuning.
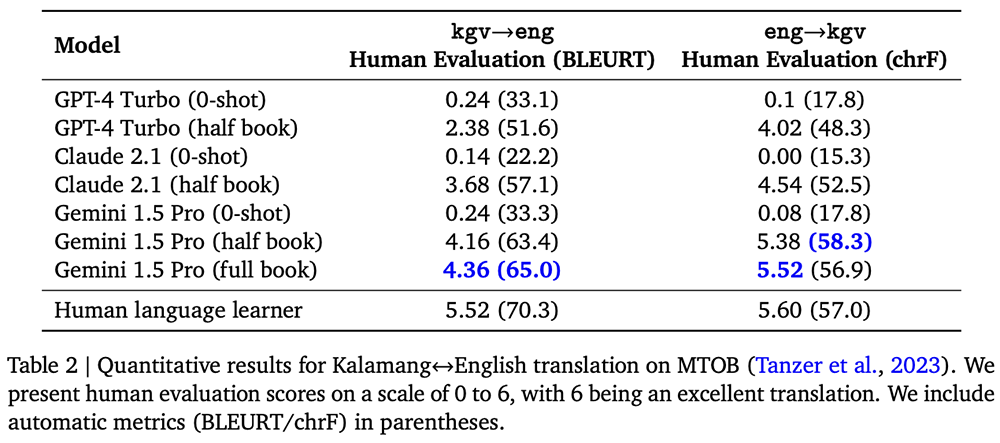
Google tested this skill on the MTOB (Machine Translation from One Book) benchmark, showing the model’s ability to learn from previously unseen information.
Especially for rare languages, such as the translation between English and Karamani, Gemini 1.5 Pro achieved test scores far exceeding those of large models like GPT-4 Turbo and Claude 2.1, reaching levels similar to a human learning English from the same content.
Conclusion: Further testing is underway,
to explain the ultra-long context functionality
According to Google’s AI principles and safety policies, Google ensures that its models undergo extensive ethical and safety testing, integrating research findings into its governance processes and model development and evaluation.
Google is developing further tests to explain the novel long context capabilities of Gemini 1.5 Pro.
When the model is ready for broader release, Google will introduce Gemini 1.5 Pro with a standard context window of 128,000 tokens and plans to quickly introduce pricing tiers, starting from the standard 128,000 context window, expanding to 1 million tokens.
Early testers can try the 1 million tokens context window for free during the testing period. Developers interested in testing 1.5 Pro can register at AI Studio, while enterprise customers can contact the Vertex AI customer team.
Article Benefit:58 pages《Gemini 1.5 Technical Report》, available by replying with the keyword 【Zhiyuan 408】 in the public account chat.
(This article is original content from NetEase News • NetEase account feature content incentive program signed account 【Zhiyuan】, unauthorized reproduction is prohibited.)


