Click on the above “Beginner Learning Vision” to select “Star Mark” or “Top“
Important content delivered immediately
Paper Title: “How much Position Information Do Convolutional Neural Networks Encode? “
Paper Link: https://openreview.net/forum?id=rJeB36NKvB
This article explains how CNNs learn the absolute position information within images. The article comes from Canadian scholars and is included in ICLR2020. It mainly describes two things:
-
Convolutional neural networks can incorporate absolute position information, and the degree varies among different networks.
-
Absolute position information is introduced through zero-padding, and the representation effect is better in deeper layers.
02
Previously, the concepts of CNN and absolute position were rarely discussed together.
I believe there are two reasons for this: first, it is generally believed that CNNs are translation invariant (for classification tasks), or translation equivariant (for segmentation and detection tasks); second, there is no specific task demand. For example, in the three major object perception tasks in computer vision: classification, segmentation, and detection, object classification is unrelated to position; semantic segmentation, as pixel-level semantic classification, also does not rely on position; the object detection task, which is most likely related to absolute position, has been decoupled from absolute position by mainstream methods, turning into a regression of local relative positions relative to anchor boxes or anchor points. Thus, the network itself does not need to know the absolute position of objects, and position information is used as a prior in preprocessing and postprocessing for coordinate conversion. However, absolute position information is valuable in many tasks, such as instance segmentation, where object + absolute position can uniquely determine an instance.
A very obvious observation is that the human visual system can easily know absolute positions, for example: “There is a bird in the upper left corner, and it has flown to the right.” Moreover, for objects in images, they are essentially distinguished by position and shape.
This article first makes an assumption:
First, we know that the original features learned by convolutional networks can be visualized using CAM for salient regions. The article conducted a simple experiment by cropping an image to test the change in salient regions before and after cropping.
Theoretically, since the features are the same before and after cropping, the salient regions of common objects should remain unchanged, but it was found that the salient regions shifted after cropping, which is difficult to explain with the translation invariance of convolutional neural networks, leading to suspicion that it is due to position information.
Thus, the author analyzed through experiments whether convolutional neural networks can learn position information.
Specific network design for the experiments:
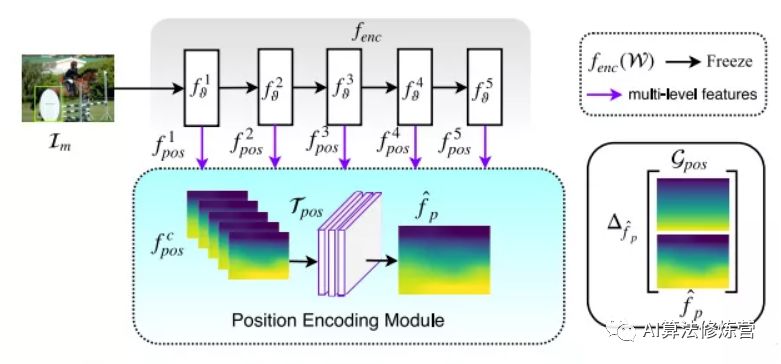
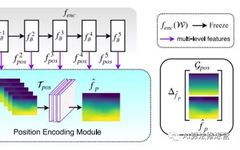
The network consists of two parts:
-
Encoder: A pre-trained backbone like ResNet or VGG, whose parameters do not participate in training, serving only as a feedforward network to extract features;
-
Position Encoding Module: Composed of convolutions, with trainable parameters, and only one convolution was used in the experiment.
Any image (the image contains content) is input, and the network is trained to output position-related images. For example, inputting a noise image, the network is expected to output a horizontal coordinate map (position information). Meanwhile, the normalized gradient results of the image are set to 5 target masks:
H: Horizontal direction V: Vertical direction G: Gaussian distribution
HS: Horizontal repetition VS: Vertical repetition
The above labels can be considered random labels, as they are unrelated to the content of the image, only related to some pixels’ positions in the image.
Evaluation Metrics:SPC: Spearman correlation coefficient, a non-parametric measure of the dependence between two variables, used to evaluate the correlation between two statistical variables.MAE: Mean pixel difference between the predicted position map and the real gradient position map.
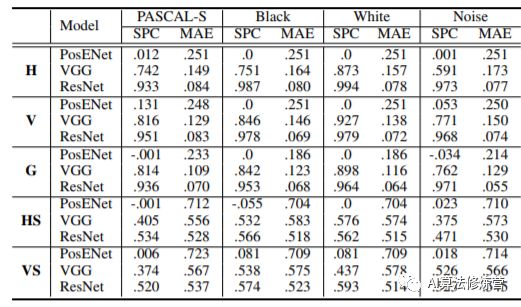
Here, VGG/ResNet indicates that pre-trained weights are used to extract feature maps as input to the Position Encoding Module, while PosENet’s input is the original image directly.
From the experimental results table, the comparison shows that extracting position information from the original image is quite difficult.However, after encoding through the neural network, consistent position information was extracted. The high performance of the test set results indicates that the model did not blindly fit the noise but rather extracted real position information.
Specifically, under zero-padding, models based on VGG and ResNet can predict reasonably related position outputs, such as horizontal or vertical coordinates.
Without padding, the output only directly responds to the input content and cannot predict position information unrelated to the content.
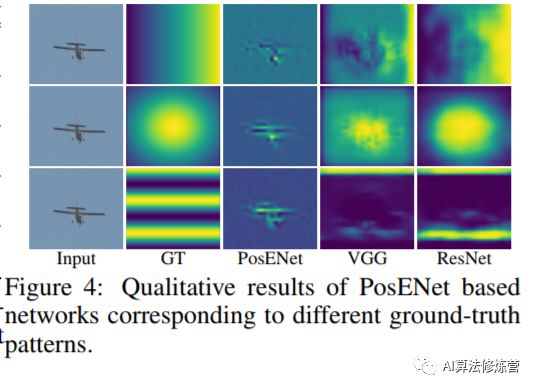
As shown in the figure, the results are visualized, corresponding to the ground truth, and it can be seen that the predicted position map has a correlation with the real position map, further revealing the presence of position information in these networks. Position information is implicitly encoded in the classification structure of convolutional neural networks without requiring any explicit supervision.
The previous experiments confirmed that the pre-trained weights of convolutional neural networks in classification tasks can encode absolute position information, but what factors influence this encoding?
Since absolute position information is obtained from the feature maps produced by the Encoder module and extracted by the Position Encoding Module, and the extraction process only involves convolution operations, we consider the convolution operations and feature maps.
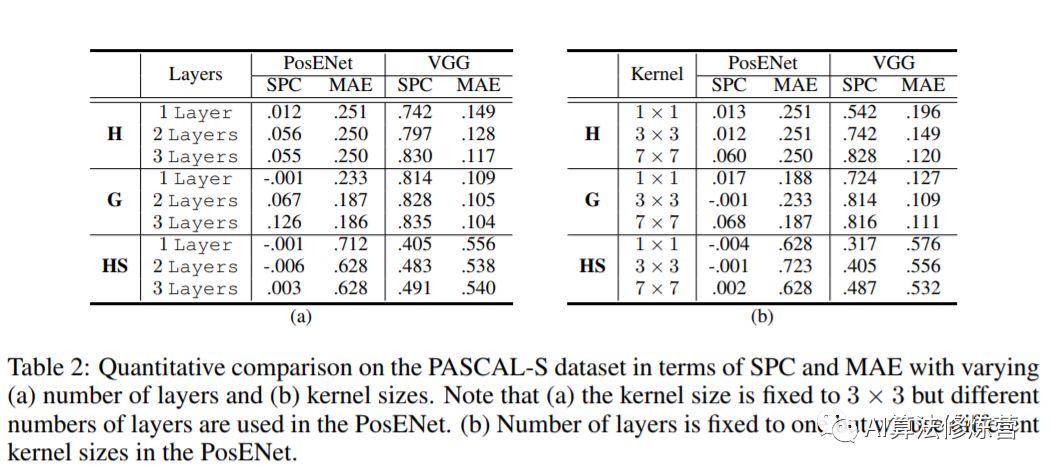
-
Number of Convolutional Layers: As shown in the above (a) results,stacking multiple convolutional layers can improve the network’s ability to read position information.The reason may be that stacking multiple convolutional layers increases the receptive field.
-
Increasing Convolution Kernel Size: From result (b),larger kernel sizes may capture more position information, which is also related to the stacking of convolutional layers, as both increase the receptive field.
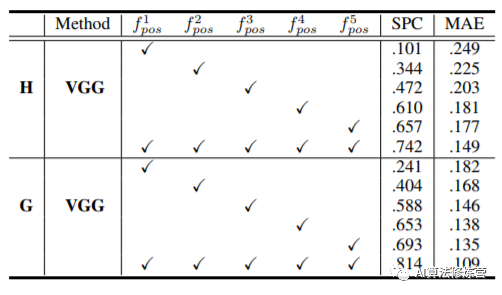
-
Impact of Feature Layers: Compared to shallow features,deep features achieve better performance.However, there is another variable: the number of spatial channels in each layer differs, so controlling variables to ensure the same features are compared clarifies that position information is encoded more strongly in the deeper layers of the network.
From the previous two experiments, we learned that convolutional neural networks have the ability to encode position information, and the original image does not introduce position information. So if this position information does not come from the original image, where does it come from?The answer isZero-Padding.
The author conducted controlled variable tests on the number of paddings in the Position Encoding Module network, finding that as padding increases, the position information becomes more significant. Additionally, experiments using the VGG network further confirmed that padding introduces position information.
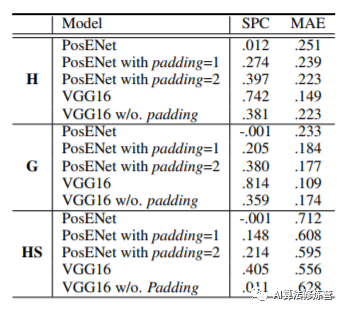

From the visualizations in the figures, it can also be seen that padding significantly affects the introduction of position information, especially in the final VGG, where the presence or absence of padding has a large impact.
Similarly, for object detection and semantic segmentation tasks, experiments found that removing padding operations led to a significant drop in performance.
The article demonstrates the effect of zero-padding through experiments, but how zero-padding specifically introduces position information and its mechanism may still require further research to explain.
Although current CNN models can implicitly learn a certain degree of position information, it is clearly insufficient. How to better utilize absolute position information is worth further exploration; CoordConv and semi-conv are good explorations.
The most straightforward approach is to concatenate the coordinates of each pixel to the input or intermediate features. This simple and direct method can bring a 3.6 AP improvement in SOLO’s instance segmentation results.
Overall, understanding position information, or understanding zero-padding, can lead to better designs for networks and tasks in the future. For instance, instance segmentation and object detection tasks that require position information should incorporate more zero-padding, while in tasks like image stylization where position information is not needed, reducing its use may yield some benefits.
Good news!
The "Beginner Learning Vision" knowledge group is now open to the public👇👇👇
Download 1: Chinese Tutorial for OpenCV-Contrib Extension Modules
Reply "Chinese Tutorial for Extension Modules" in the "Beginner Learning Vision" WeChat public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: 52 Lectures on Python Vision Practical Projects
Reply "Python Vision Practical Projects" in the "Beginner Learning Vision" WeChat public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, helping you quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply "OpenCV Practical Projects 20 Lectures" in the "Beginner Learning Vision" WeChat public account to download 20 practical projects based on OpenCV, enhancing OpenCV learning.
Group Chat
You are welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, you will not be approved. After successful addition, you will be invited into relevant WeChat groups based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed. Thank you for your understanding~