
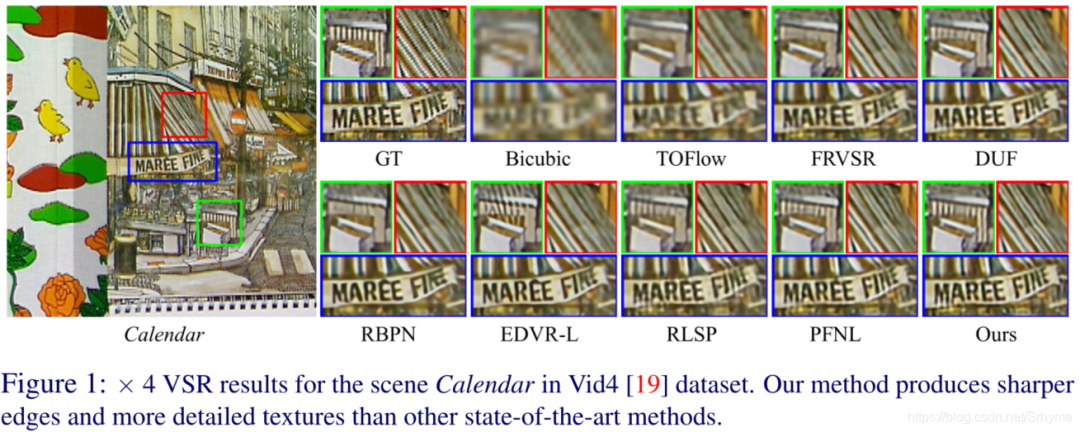
Sharing a paper on video super-resolution titled Revisiting Temporal Modeling for Video Super-resolution, which is a BMVC 2020 paper. The results of this paper currently rank first on several datasets for video super-resolution, and the code has been open-sourced.

Affiliations: Tsinghua University, New York University, Huawei Noah’s Ark Lab
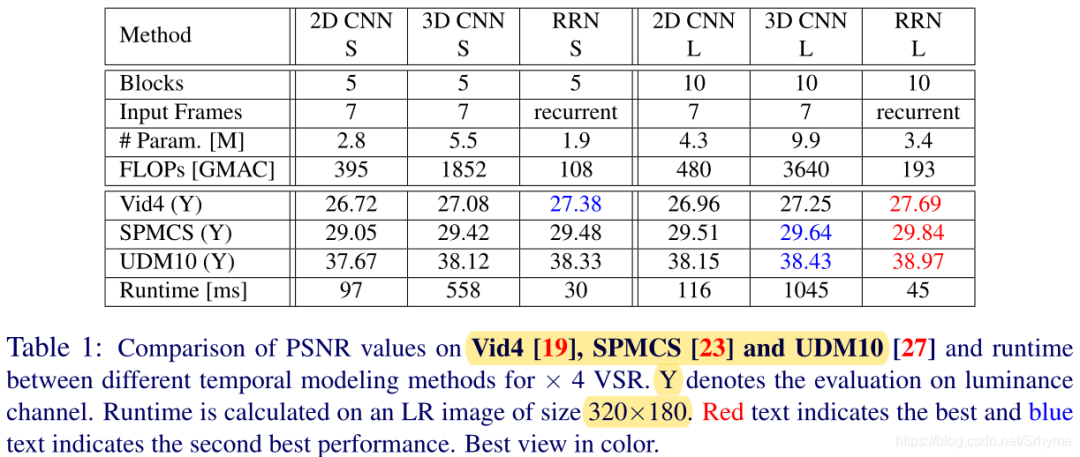
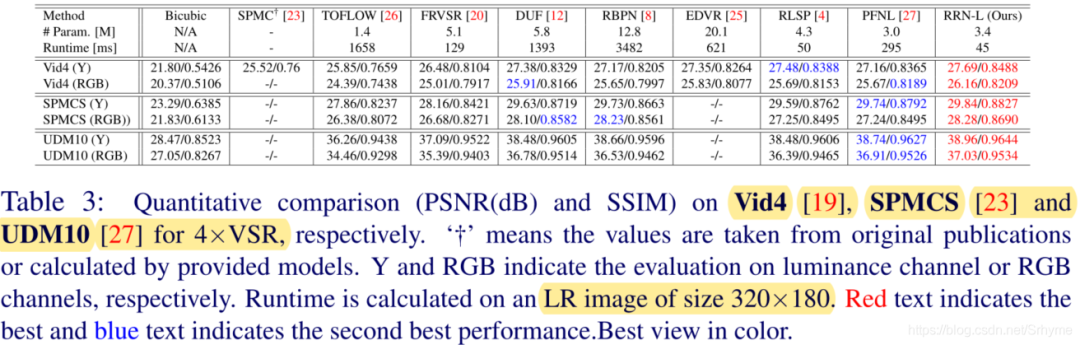
This paper proposes a concise yet efficient super-resolution architecture, achieving a PSNR of 27.69 with only 45ms per frame on the test set, with significant practical value. The highlights are as follows:
-
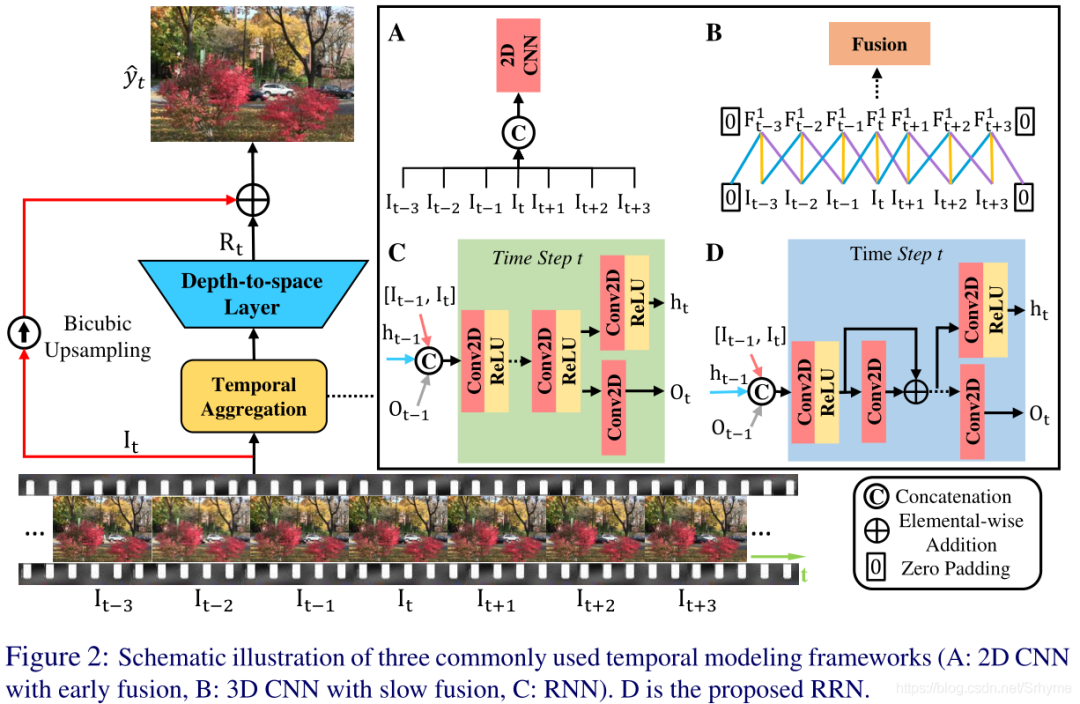
Many video super-resolution (VSR) methods based on deep learning have been proposed in the past, but direct comparisons are difficult due to different loss functions or training sets. This paper unifies the research and compares three temporal modeling methods: early fusion 2D CNN, slow fusion 3D CNN, and RNN.
-
A new Residual Recurrent Network (RRN) is proposed, which stabilizes the training of RNNs using residuals while improving super-resolution performance, achieving SOTA on three benchmark datasets.
2D CNN: Utilizes several improved 2D residual blocks, each consisting of a 3×3 convolution layer and ReLU. The model takes 2T+1 consecutive frames as input, concatenating them along the channel dimension, then passing through a series of residual blocks, outputting a residual feature map of shape H×W×Cr^2^. The residual image R~t~^↑^ is obtained by upsampling the residual feature map four times using depth-to-space, which is then added to the center frame upsampled using bicubic interpolation to produce the HR image.
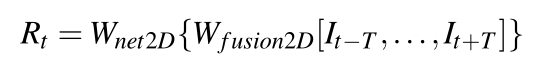
3D CNN: In contrast to 2D CNN, 3D CNN uses 3×3×3 convolution layers to extract spatiotemporal information. Additionally, to prevent frame reduction, we add two zero-pixel value frames along the time axis.
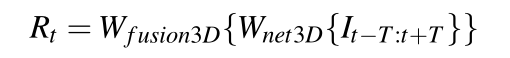
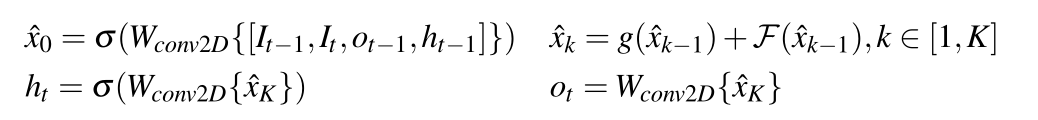

Paper: https://arxiv.org/pdf/2008.05765.pdf
Code: https://github.com/junpan19/RRN
END

Note: Super-resolution

Super-resolution Group Chat
Image and video super-resolution, visible light, infrared, remote sensing super-resolution technologies,
If you are already friends with other accounts of CV Jun, please send a direct message.
WeChat ID: aicvml
QQ Group: 805388940
Weibo Zhihu: @I Love Computer Vision
Submission: [email protected]
Website: www.52cv.net
