Source | Asynchronous | Book Giveaway at the End
How to Build the Simplest GPT
What is the Learning Method for GPT?
Borrowing the famous quote from Linus, “talk is cheap, show me the code”, there is nothing more suitable than building a GPT from scratch.
Some students may be intimidated, thinking that something achieved with hundreds of billions of dollars can’t just be created. However, our goal is to write the simplest GPT to fundamentally understand GPT technology. Just like the earliest released Linux kernel, which was only 20,000 lines of code, but the core architecture of Linux continues to this day.
In fact, by implementing just 8 core components, we can create a “small but complete” GPT in only 400 lines of code.
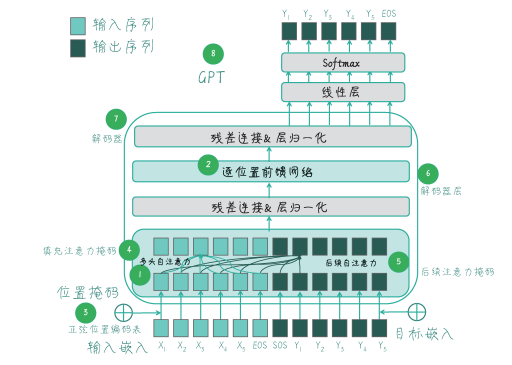
Before we start, let’s understand some basic concepts. GPT is a natural language processing model based on the Transformer architecture, and the core of the Transformer is the self-attention mechanism, which assigns different weights to each element in the input sequence, thereby better capturing the dependencies within the sequence.
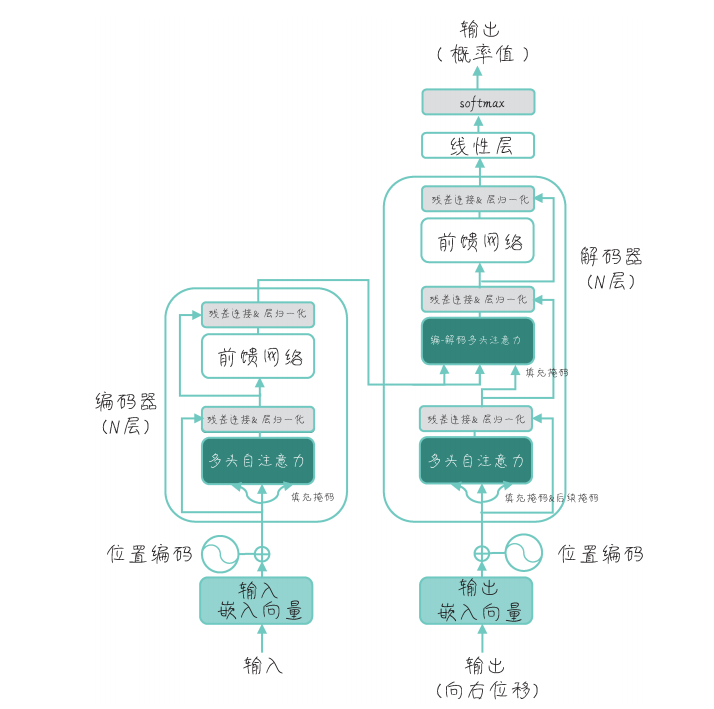
GPT is a unidirectional model trained from left to right, using only the decoder architecture of the Transformer, featuring autoregressive characteristics. During training, the GPT model uses subsequent attention masks to ensure that each position can only see the information before its current position, making GPT particularly suitable for generative tasks such as text classification and question-answering systems.
Now that we know the principles of GPT, let’s set up the GPT development environment.
Setting Up the GPT Development Environment
The experimental environment for this project is Debian Linux, and the programming language is Python 3.x. Students can choose suitable tools according to their environment, such as Windows, MacOS, or other Linux distributions. Development tools can include PyCharm, VSCode, etc.
In this simplest GPT project, we need to rely on the numpy and PyTorch libraries, which we can install using pip. Pip will automatically install the relevant dependencies in sequence.
pip install numpy
NumPy (Numerical Python) is the most fundamental and important scientific computing library in Python, providing powerful support for handling large-scale data and efficient numerical computation. Some mathematical functions of NumPy will be used in this project.
PyTorch is a scientific computing library based on Python, primarily designed to solve deep learning tasks. PyTorch uses dynamic computation graphs, allowing for flexible construction of complex computation graphs, while supporting both dynamic and static graphs. It also allows users to freely combine various neural network layers to achieve customized model structures.
In the simplest GPT project, the torch.nn module is used to build the neural network model, providing a rich set of classes and functions that facilitate users in defining, training, and evaluating neural network models. By using torch.nn, users can quickly build various complex neural network structures to accomplish deep learning tasks.
Additionally, we use the torch.optim module for optimization algorithms, which provides various common optimizers and encapsulates parameter updates and learning rate adjustments, making it convenient for users to train and optimize deep learning models.
Now that the development environment is ready, let’s start building the simplest GPT.
The Simplest GPT Development Process
The structure of the simplest GPT project can be divided into three parts: the GPT model, building the corpus and training the model, and generating text.
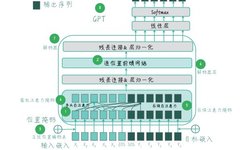
The 8 components that constitute the GPT model include multi-head self-attention, position-wise feedforward networks, sinusoidal position encoding table, padding mask, subsequent mask, decoder layer, decoder, and GPT. The first five components make up the Transformer decoder, and we will focus on interpreting the code for the decoder layer.
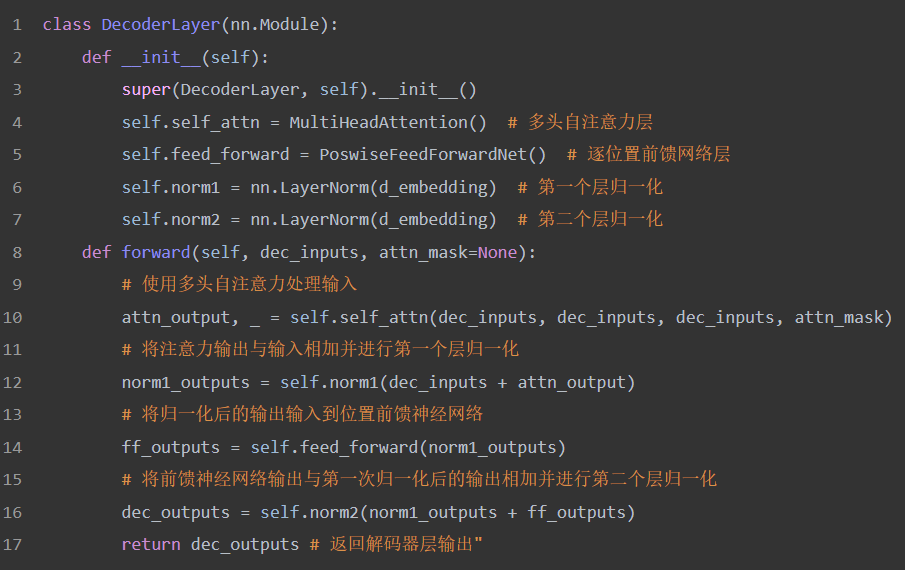
The GPT decoder layer includes a multi-head self-attention layer (MultiHeadAttention) and a position-wise feedforward network layer (PosFeedForwardNet), followed by two layer normalization (nn.LayerNorm).
The first layer normalization (norm1): After the multi-head self-attention (self_attn) processes, the attention output (attn_output) is added to the original input (dec_inputs). This addition operation implements a residual connection, which can accelerate gradient backpropagation and help train deep networks.
The second layer normalization (norm2): After the position-wise feedforward network (feed_forward) processes, the feedforward neural network output (ff_outputs) is added to the first layer normalization output (norm1_outputs). This can standardize the input data and improve training stability.
Building the Corpus and Training the Model
Prepare a piece of raw text for training the model, as shown in the figure below. Although it is not long, it is sufficient to demonstrate the core functionality of the simplest GPT.
The analysis results of this text are shown in the figure below.
Next, we will train the model on the raw text, with the code as follows:
The training data consists of given input sentences, which have been encoded into numerical representations. In each training batch, the model’s input is the current sequence of words, and the target output is the next word for each word in that sequence.
To calculate the loss, the model predicts the probability distribution of the next word and then uses the cross-entropy loss function to compare these predicted probabilities with the actual target words. The code will autonomously choose between GPU or CPU for computation based on the host configuration, and the training time is around a few minutes:
The following code uses the trained model to generate text, and after running, you can see the results of a greedy search for each generated word:
First, the code converts the input string into a list of word indices (input_tokens), and then these input tokens are used as the initial generated text (output_tokens). Next, the function enters a loop to generate new tokens one by one until reaching the maximum length (max_len) or encountering a sentence end marker.
Thus, the construction of GPT is complete. Students can also adjust the above code, for example, by saving the model to disk for repeated loading, or using richer corpora to train the model, etc.
The complete 400 lines of code for the simplest GPT project are all in “GPT Illustrated: How Large Models are Built”, which provides very detailed explanations of the 8 components of GPT.
This is a particularly interesting book that teaches you GPT through stories, so let’s take a closer look.
Understanding Large Models
“GPT Illustrated: How Large Models are Built” traces the development context of NLP technology, discussing N-Gram, Bag of Words (BoW), Word2Vec (W2V), Neural Probabilistic Language Models (NPLM), Recurrent Neural Networks (RNN), Seq2Seq (S2S), Attention Mechanisms, Transformers, and the birth and evolution of a series of breakthrough technologies from the original GPT to ChatGPT and then GPT-4.
The biggest feature of this book is that it unfolds technical discussions through dialogues between two virtual characters, “Brother Coffee” and “Xiao Bing”, turning tedious technical details into light-hearted humorous stories and colorful illustrations, guiding readers through different times and spaces to witness the inheritance, evolution, and transformation of natural language processing technology.
The author of this book, Huang Jia, whose pen name is “Brother Coffee”, is currently an AI researcher at the Singapore Agency for Science, Technology and Research, focusing on the development and application of NLP large models. Brother Coffee has many years of experience in the AI field, with rich practical experience in various industries such as government, banking, and healthcare.
Brother Coffee is also the author of bestselling books such as “Machine Learning for Beginners” and “Ten Talks on Data Analysis by Brother Coffee”. In his writing, technology sheds its mysterious veil, and readers naturally learn to apply technology through a relaxed reading experience.
Rich Accompanying Resources are another major feature of this book, as Brother Coffee meticulously writes example codes for each chapter and compiles them into Python notebook files. Readers can easily run and debug the code in the interactive environment of the notebook and observe the output results.
Code Directory for Each Chapter
Running and debugging Python notebook projects in VSCode
This work by Brother Coffee has also received widespread recognition in the industry, with several big names jointly recommending this book.
Understanding “GPT Illustrated: How Large Models are Built” to deeply grasp the principles of large models. Don’t say you can build GPT; in any field of large models, students can navigate with ease. This is the core competitiveness that should be possessed in the AI era!
▼ Click below to purchase the book, limited-time discount
Share Your Thoughts on GPT
Participate in the interaction in the comment area, and click to view and share the event to your friends. We will select 1 reader to receive an e-book version of the book, deadline January 15.