
This article is approximately 6000 words long and is recommended for a reading time of over 10 minutes.
Table-GPT is a large language model specifically designed for table analysis, unifying tables, natural language, and commands.
1 Abstract
Language models like GPT-3 and ChatGPT exhibit exceptional abilities in following various human instructions and executing different tasks, however, they perform poorly in understanding tabular data (structured data). This may be because these models are primarily pre-trained on one-dimensional natural language text, while tables, as two-dimensional objects, require more complex information processing capabilities. (I personally believe it may also be because neural networks are not particularly good at heterogeneous data and numerical representations.)
Table-GPT is a data analysis tool that breaks through the limitations of large language model technology, using the “table tuning” paradigm of large models, which trains/fine-tunes language models like GPT3.5 and ChatGPT with real table synthesis task data, enhancing their ability to understand and execute table tasks.
It integrates several core components into the GPT model based on tables, natural language, and commands, including global table representation, command chains, and domain-aware fine-tuning. Table-GPT outperforms standard GPT-3.5 and ChatGPT on table understanding tasks and can respond to instructions to execute new table tasks. The Table-GPT framework has advantages such as language-driven EDA, a unified cross-modal framework, and generalization with privacy protection. It simplifies the way users handle tabular data, improves the reliability of data operation execution, and can better handle data variability and generalize to different domains. Furthermore, Table-GPT supports private deployment, providing robust data privacy protection.
2 Introduction
2.1 Fine-tuning
Instruction tuning in NLP is a technique for training language models to follow different human instructions by constructing training data of the form “(instruction, completion)” manually annotated by human annotators, continuing to train the model to follow high-level human instructions, resulting in well-known models such as ChatGPT/InstructGPT and their open-source versions like Stanford-Alpaca and LLaMa-chat. Early GPT-3 models could not reliably follow such instructions, which was later achieved in models like ChatGPT.
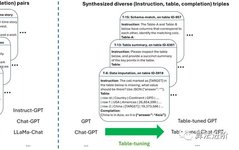
Table tuning is a new method for training language models to understand tables. We improve the model’s ability to follow human instructions by using multi-training data in the form of instructions, tables, and completions. We synthesize task data using a large number of real tables, as shown in Figure 1.
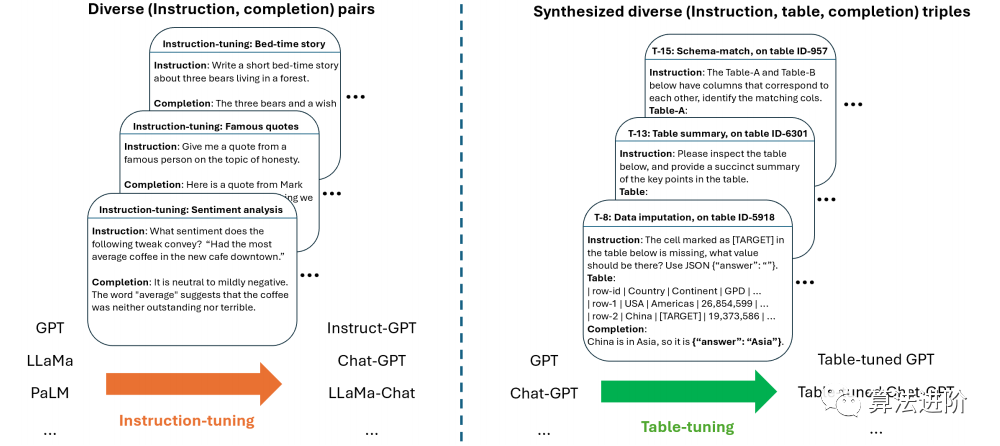
Figure 1: Instruction tuning and table tuning. (Left) Instruction tuning is a technique developed in the NLP community that continues to train language models (like GPT) for instruction-following capabilities (like ChatGPT). (Right) Table tuning is a similar method we propose for training language models to better understand tables and execute table tasks.
2.2 Language Models
Currently popular language models fall into two categories: encoder-based language models and decoder-based language models, both derived from the original Transformer architecture.
Encoder-based language models include BERT and RoBERTa, which only use the encoder of the Transformer and are pre-trained on large amounts of text to effectively represent the semantics of text using embedding vectors. To use such models for downstream tasks, specific task fine-tuning is usually adopted.
Decoder-based language models include GPT and LLaMa, which are inherently generative and have been shown to excel at generalizing to new downstream tasks without requiring specific task fine-tuning. Especially after instruction tuning, decoder models can easily adapt to new tasks using only natural language instructions and a few optional examples, allowing them to generalize to new datasets and tasks without fine-tuning on labeled data for each specific task, making decoder models more versatile and adaptable.
2.3 Language Models for Table Tasks
Pioneering work in the database literature uses language models to perform table-related tasks. Encoder-based language models (like TaBERT, Ditto, and Doduo) are trained based on encoder-based BERT-like models and perform well on various table tasks. However, to generalize to new datasets or tasks, fine-tuning with labeled data is required. In contrast, decoder-based language models (like GPT-3 and ChatGPT) can perform tasks with just instructions, achieving good performance on table tasks through a technique called “prompt engineering”.
We propose “table tuning” as an orthogonal direction, continuing to train base language models once to improve their performance on various table tasks. Figure 2 shows the table tuning process, which is similar to instruction tuning but focuses more on enhancing the model’s ability to understand tables and execute table tasks. Our table tuning model remains general, capable of following human instructions to execute table tasks (without task-specific fine-tuning), just like the underlying GPT-3 and ChatGPT models. In Table-GPT, the goal is to have both generalization capability and good performance on table tasks.
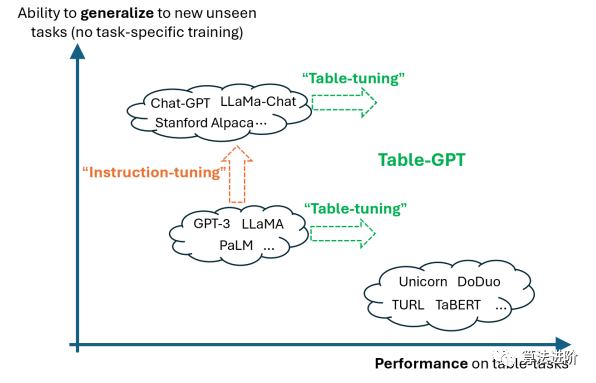
Figure 2: Instruction tuning and table tuning. Instruction tuning can enhance the model’s “generalization ability” to follow different human instructions to execute new and unknown tasks (x-axis), while our proposed table tuning is conceptually similar but aims to enhance the model’s ability to understand tables and execute table tasks (y-axis).
3 Can Language Models “Read” Tables?
Language models face challenges in reading and understanding two-dimensional tables, including the differences between one-dimensional text and two-dimensional tables, as well as the sequential sensitivity of text versus the arrangement-invariant nature of tables.
To test the ability of language models to read tables in a column-wise direction, we designed a simple testing task (T-1), including “missing value identification,” where random cells were removed from real tables to generate two variants. As shown in Figure 3:
Figure 3: Two variants of the task (T-1) for identifying missing cells. (Left) T-1(a): A random cell is removed from a real table, but its column separator is retained. The presence of “| |” indicates a missing cell, which should be easily identifiable. (Right) T-1(b): A random cell and its column separator are both removed, which is a common but challenging CSV parsing problem.
We tested with 1000 real tables, and the results are shown in Table 1: reading tables in a column-wise direction is challenging, with accuracy rates of 0.38 and 0.26 respectively; after using column separators and a few demonstrations, the model could only correctly complete half of the tests (0.51); in row-wise direction, the model’s ability to identify missing cells is better, but still not good enough in the “no col-separator” setting.
Table 1: Accuracy data of GPT-3.5 (using Text-Davinci-002) on the task (T-1) for missing value identification.

The ability of language models to read tables in a column-wise direction is insufficient, and their ability to identify missing cells in a row-wise direction is weak. This indicates that language models may not be suitable for table tasks. Therefore, the development of table tuning methods is necessary.
4 Table-GPT’s Table Tuning
4.1 Overall Approach: Integrate and Enhance
Table tuning is inspired by the successes in the NLP literature, using “(instruction, completion)” pairs to train language models, which has led to popular models like ChatGPT and LLaMa-chat. Our proposed table tuning enhances the model’s ability to execute table tasks by using “(instruction, table, completion)” triples. We define instances of table tasks as triples that include instruction, table, and completion. However, the challenge lies in ensuring the quality of the “(instruction, completion)” pairs, which requires a large amount of human annotation to ensure the quality and diversity of the training data. We hope to replicate the success of instruction tuning in the table domain, ideally without the need for expensive human annotation. Existing benchmark data suffers from a lack of task and data diversity, and we attempt to perform table tuning using only existing benchmark data, leading to overfitting.
4.2 Integrating Different Table Tasks
We propose two methods: (1) synthesizing new table tasks for task diversity, and (2) synthesizing new table test cases of existing table tasks for data diversity. We scraped 2.9 million high-quality web tables and 188,000 database tables, synthesizing table tasks based on real tables sampled from the corpus.
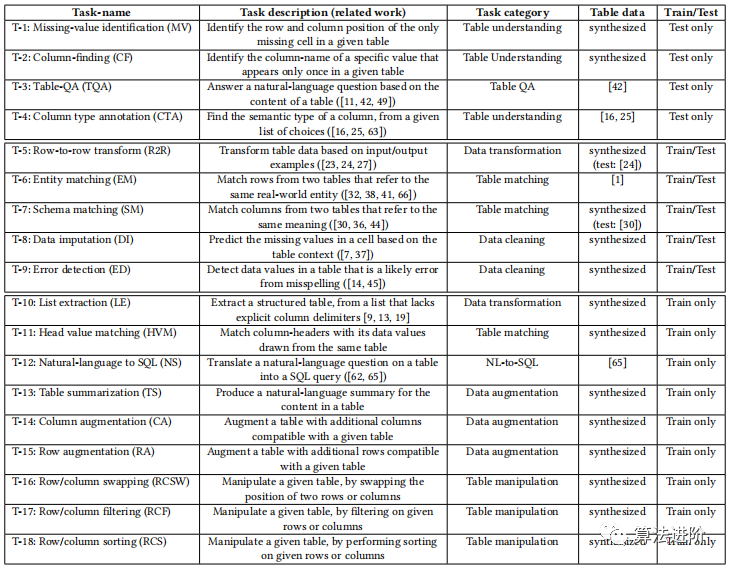
Table 2 provides a collection and summary of 18 table-related tasks for “table tuning” GPT to better handle table tasks. These tasks cover a wide range of areas such as table understanding, table question answering, table matching, table cleaning, and table transformation. Each task in Table 2 has a task category and table data, where task categories cover various types of tasks, and table data consists of tasks synthesized from various real tables to ensure the diversity of training data and avoid overfitting.
Table 2: Collection and summary of 18 table-related tasks.
4.3 Enhancing Integrated Table Tasks
We enhance through different levels, including instruction-level, table-level, completion-level, and language model-assisted completion enhancement, aimed at creating more data diversity and avoiding overfitting.
At the instruction level, we use GPT to enhance normative instructions, generating multiple variants. At the table level, we can perform operations such as column permutation, row permutation, column sampling, and row sampling to increase table diversity. At the completion level, we enhance by adding reasoning steps to the original completion. Finally, we use language model-assisted completion enhancement, cultivating the model’s performance on complex tasks through step-by-step reasoning. Real assisted completion enhancement uses ground truth step-by-step reasoning, such as task (T-9) error detection. Conventional language models produce many false positives in this task, such as confidently predicting cells without spelling errors as spelling errors. Using real facts generated during the table task synthesis process can reduce false positives and improve result quality. Additionally, other types of enhancements, including template-level enhancement and task-level enhancement, are performed to increase the diversity of training data and plate tuning.
4.4 Table-GPT as a “Table Foundation Model”
We generate table tasks using the integrate and enhance method and train language models to maximize completion loss. This process is called table tuning. The table-tuned model TableTune(M) can serve as a better “table foundation model” if it outperforms M in the following scenarios: (1) zero-shot out-of-the-box; (2) few-shot out-of-the-box; (3) prompt tuning for specific tasks; (4) specific task fine-tuning.
We expect to verify the effectiveness of table tuning through experimental evaluations.
5 Experiments
5.1 Experimental Setup
We tested four models: GPT-3.5, Table-GPT-3.5, ChatGPT, and Table-ChatGPT. Among them, Table-GPT-3.5 and Table-ChatGPT are models obtained by table tuning GPT-3.5 and ChatGPT, as shown in Table 3. We used 14 table tasks as training data and ensured that the test tasks were separated from the training data. For unseen tasks, we evaluated whether the model could follow human instructions and execute new unseen tasks. For common tasks, we hope the table-tuned models can demonstrate table-related concepts. We used existing benchmark data, and for tasks where real labels could not be automatically synthesized, we used manually labeled benchmark data. Detailed information on the test data and its statistics can be seen in Table 4.
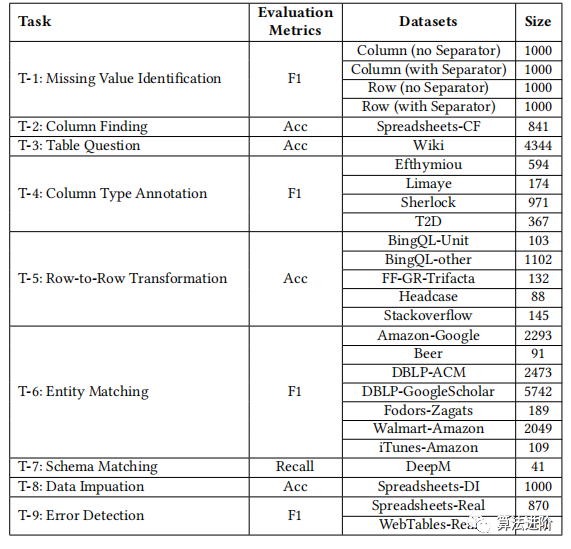
Table 3: Detailed results of table tuning on GPT-3.5 and ChatGPT for various datasets. Zero-shot is not applicable to row-to-row example transformations that require examples (marked as “N.A.”). For all “unseen” tasks, these tasks are held out and unseen during table tuning. For all “seen” tasks, the tasks are visible during the table tuning but the test dataset is held out and unseen.
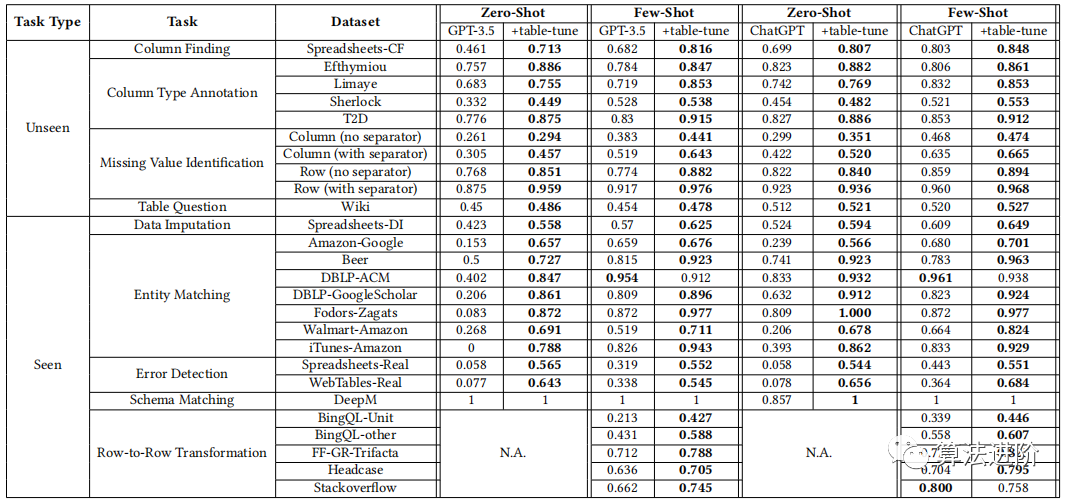
Table 4: Detailed information on test data and evaluation metrics.
5.2 Quality Comparison: Unseen + Seen Tasks
Figures 4 and 5 compare the performance of GPT-3.5 with Table-GPT-3.5, and ChatGPT with Table-ChatGPT, respectively. The table-tuned models show a strong performance advantage across various table tasks, demonstrating the generalizability of our proposed table tuning method on different styles of underlying language models. Out of a total of 104 tests, the table-tuned models excelled in 98 tests.
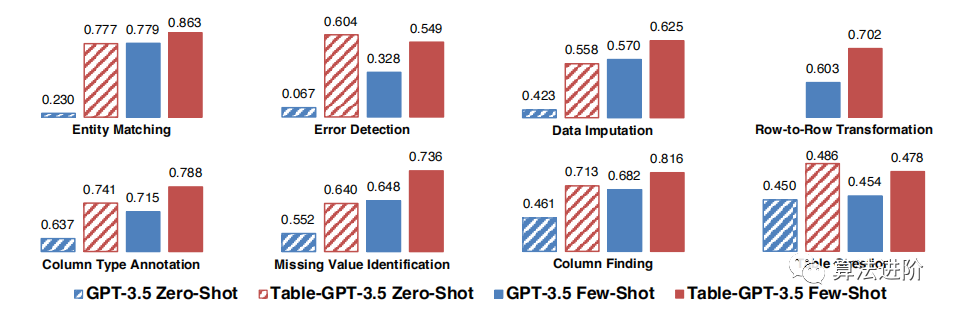
Figure 4: Overall quality improvement between standard GPT-3.5 and Table-GPT-3.5.
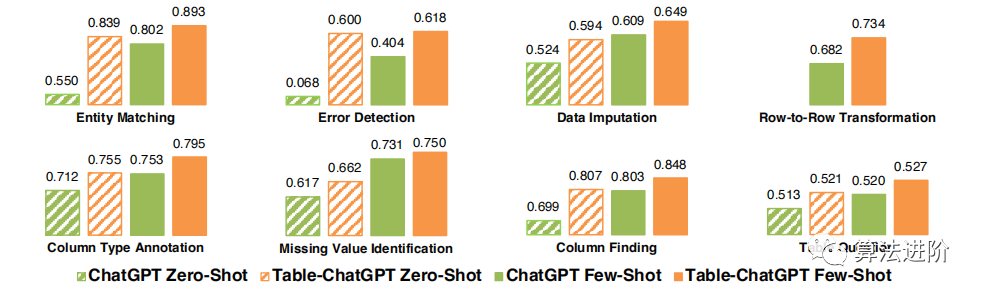
Figure 5: Overall quality improvement between standard ChatGPT and Table-ChatGPT.
5.3 Benefits of Specific Task Optimization
The table-tuned GPT model performs well in zero-shot and few-shot settings and can serve as a table foundation model. Using specific task optimization can improve the quality of downstream tasks. In single-task prompt engineering, Table-GPT-3.5 outperforms GPT-3.5, using 200 labeled examples for prompt engineering evaluation, Table-GPT-3.5 consistently selects better prompts. Figure 6 shows the top 5 prompts selected for Table-GPT-3.5 and GPT-3.5 respectively. In single-task fine-tuning, both Table-GPT-3.5 and GPT-3.5 benefit from specific task fine-tuning, but Table-GPT-3.5 requires less labeled data, as shown in Figure 7.
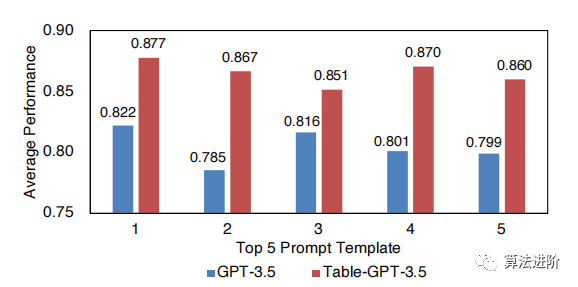
Figure 6: Quality comparison using prompt engineering. The results of the 5 best prompt templates are shown on the Efthymiou dataset.
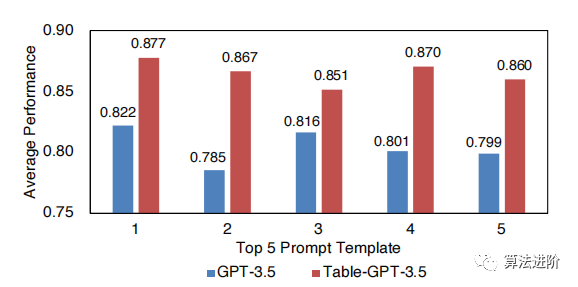
Figure 7: Single-task fine-tuning.
5.4 Sensitivity Analysis
We conducted sensitivity analysis to study the impact of the number of training tasks, amount of training data, size of the base model, and prompt templates on the performance of the table-tuning model, as shown in Figures 8-11.
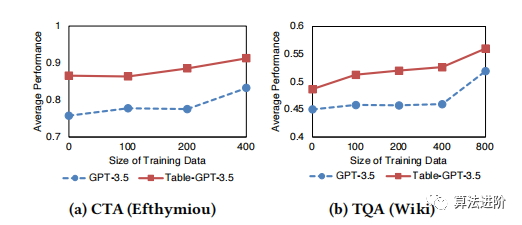
Figure 8: Number of different training tasks.
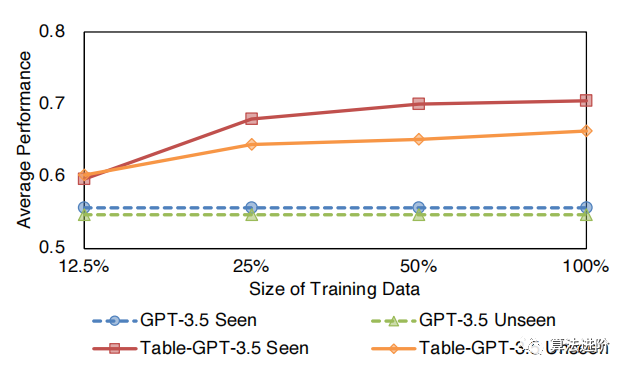
Figure 9: Amount of different training data.
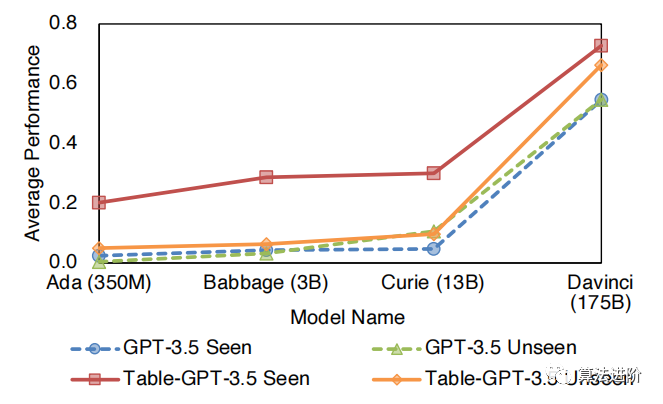
Figure 10: Size of different models.
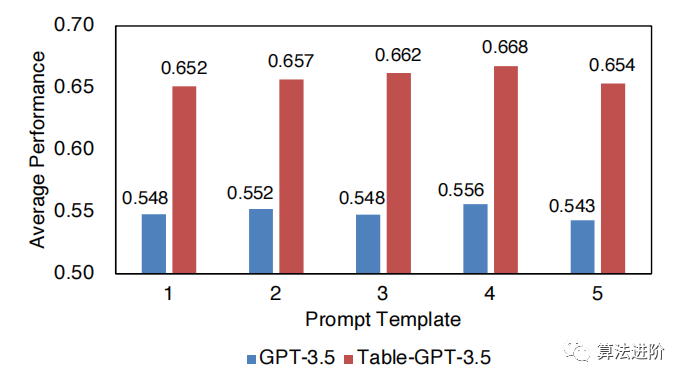
Figure 11: Different prompt templates.
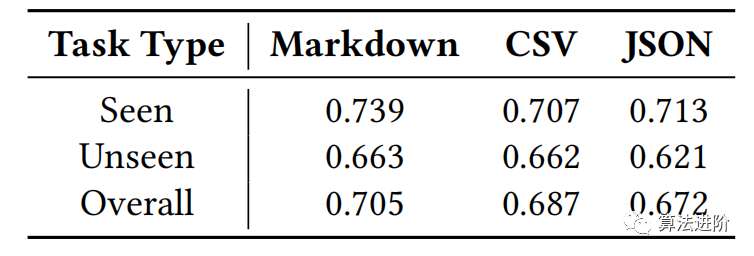
It can be seen that using more training tasks can improve performance across all tasks. As the amount of training data increases, the performance of both seen and unseen tasks improves but tends to stabilize. For the base model size, we find that the table-tuned model performs better on larger models, which may be due to their better generalization capabilities. Finally, we find that different prompt templates can impact the performance of the model, but Table-GPT-3.5 consistently outperforms GPT-3.5 by more than 10 percentage points across all prompt templates, demonstrating the robustness of Table-GPT-3.5. In terms of table formats, Markdown format shows better average performance than other formats, as shown in Table 5.
Table 5: Performance of Table-GPT-3.5 under different table formats.
5.5 Ablation Study
We conducted an ablation analysis to understand the benefits of different enhancement strategies, with results summarized in the table. Without task-level enhancement, i.e., without synthetic tasks, performance significantly decreases. Without table-level enhancement, i.e., without column arrangements, performance drops. Without instruction-level enhancement, i.e., without prompt variations, performance slightly declines. Without completion-level enhancement, i.e., without reasoning chains, performance decreases.
Table 6: Ablation study of table tuning.

6 Table-GPT
6.1 Model Design
Table-GPT is based on the 7B parameter Phoenix model, fine-tuned on 2T text data and 0.3M tables, supporting user queries and table analysis reports.
The overall architecture of Table-GPT is shown in Figure 12. Table-GPT consists of a table encoder and LLM, combining input tables and text queries for reasoning and generating command sequences and text responses. After error correction, commands are executed, providing operational tables and responses. The streamlined process enhances query efficiency, improves user experience, and simplifies data analysis.
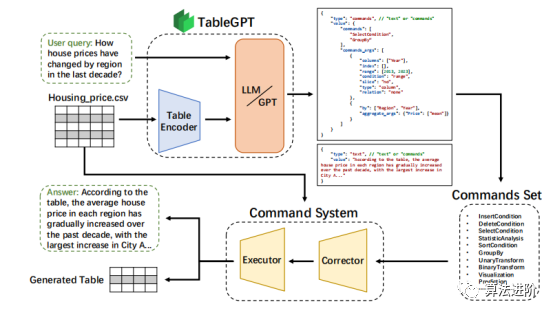
Figure 12: TableGPT framework structure.
6.2 Global Representation of Tables
Large language models (LLM) have achieved interaction with various modalities such as vision and audio, but exploration of interfaces with tabular data remains limited. How to enable LLMs to understand and interpret tabular data is crucial. Existing methods only extract partial information, neglecting the inherent global information and industry context within the data. For tables, the entire table needs to be embedded into a vector, rather than generating sample embeddings. This is challenging because table data is a highly abstract structured data type with dual permutation-invariant structure. Furthermore, tables from different domains vary in size and format, making it challenging to extract features from different tables using a unified neural network architecture.
We propose a cascade table encoder to extract global representations from tables, enabling LLMs to achieve comprehensive table understanding. This encoder jointly extracts knowledge from metadata and all numeric entries, dividing the information in table data into two main parts. The first part learns the metadata representation of the table, while the second part learns the numeric information representation of the table. We use a modified set transformer as the backbone of the table encoder, enhancing it through attention mechanisms. This encoder is pre-trained on a dataset of 10,000 tables, and the learned table representations can be used not only for table understanding but also to enhance the predictive performance of downstream classifiers.
6.3 Command Chain
We propose a method to enhance the multi-hop reasoning capability of large language models (LLM) in table operations through pre-packaged function commands. Compared to SQL statements generated by Text2SQL, these command sequences are easier for backend parsing systems to check and locate errors. We introduce the concept of Command Chain (CoC), enhancing the chain of thought method by providing step-by-step instructions related to intermediate steps. The purpose of the command chain is to enhance the reasoning ability and robustness of LLMs when manipulating table data, involving converting user inputs into a series of intermediate command operations, allowing LLMs to manipulate tables more accurately and efficiently. To improve performance and stability, we build a dataset containing a large number of command chain instructions while fine-tuning LLMs to adapt to commands, employing context learning to provide prompts for multiple steps within the command chain sequence. The command chain method has three main advantages: enhancing LLM’s multi-hop reasoning ability for table operations, improving the ability to handle complex multi-table interactions, and rejecting overly vague instructions, instead requiring users to provide more specific intentions. This method enables LLMs to better handle edge cases and unexpected situations, making it a promising approach for real-world applications.
6.4 Domain Data Processing Pipeline
We developed an efficient domain data processing pipeline to address the shortcomings of large language models in handling specific industry nuances and logical styles. This pipeline leverages active learning to carefully select fine-tuning examples from domain data, achieving excellent fine-tuning results with fewer examples, thus accelerating the model learning process. Additionally, we enhanced the document retrieval capabilities of LLMs, retrieving relevant information from a large number of proprietary documents using technologies like vector databases and LangChain, further enriching the contextual learning of LLMs. This pipeline helps LLMs quickly and cost-effectively adapt to the data needs of various specific industries, addressing challenges of industry-specific language styles and logic, and integrating natural language, tables, and command domains.
7 Evaluation
7.1 Commands Supported by Table-GPT
Table-GPT supports a rich set of commands, enabling natural language interaction with tables, allowing querying, filtering, sorting, and summarizing data, enhancing data visualization and report generation, facilitating automated decision-making processes, enabling users to make predictions, forecast trends, and estimate outcomes. When user intentions are vague, Table-GPT requests more detailed intentions rather than rigidly translating commands.
7.2 Comparison with Previous LLMs Using Commands
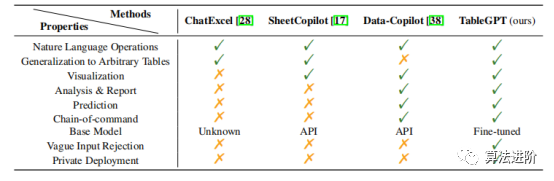
Some existing solutions combine tables with language models, such as ChatExcel, SheetCopilot, and Data-Copilot, which typically rely on prompting LLM inference APIs like OpenAI API to call predefined external commands. Table-GPT adopts a unique approach, specifically fine-tuning LLMs for table-related tasks, thereby highlighting the capabilities of the LLM architecture. See Table 7 for a comparison of TableGPT with previous LLMs using commands for table data.
Table 7: Comparison of TableGPT with previous LLMs using commands for table data.
7.3 Case Studies
Figures 13-19 show examples of Table-GPT:
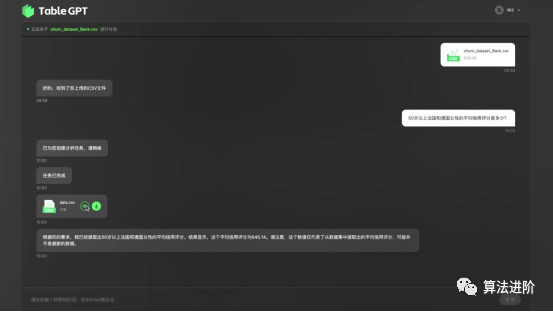
Figure 13
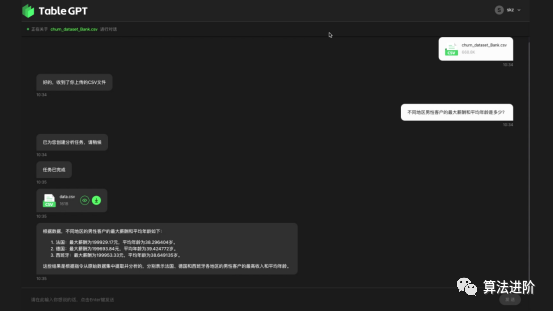
Figure 14
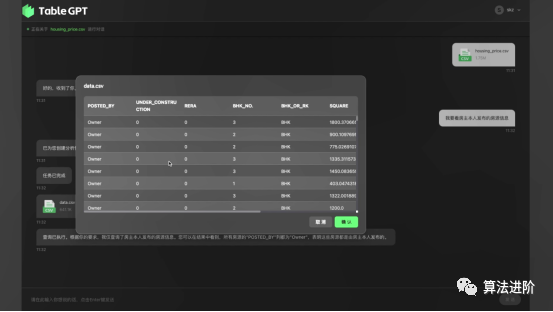
Figure 15
Figure 16
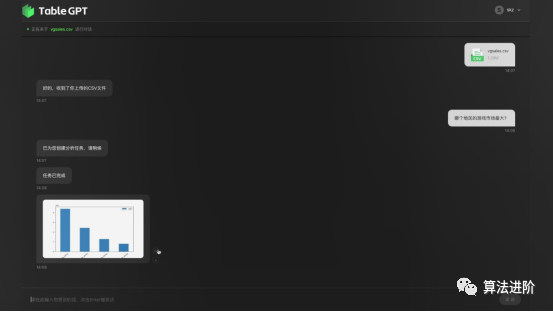
Figure 17
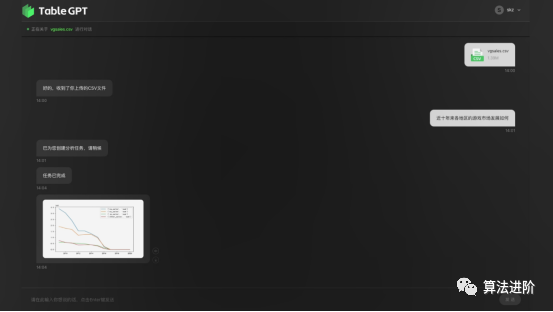
Figure 18
Figure 19
8 Conclusion
Table-GPT is a large language model specifically designed for table analysis, unifying tables, natural language, and commands. It has various functions such as answering questions, manipulating data, visualizing information, generating analysis reports, and making predictions. Technically, Table-GPT addresses several key challenges in developing a natural language-driven table data processing framework, including comprehensive table understanding, command chain generation, and domain-specific fine-tuning. We believe Table-GPT has the potential to reshape the landscape of table data processing, accelerating the efficiency of table data modeling and exploratory data analysis (EDA), and empowering various fields such as finance, transportation, and scientific research.
References:
1. “Table-GPT: Table-tuned GPT for Diverse Table Tasks”
2. “TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT”
Editor: Huang Jiyan
