
1. Build Your Own Large Model Assistant
The emergence of large models has brought revolutionary changes to many fields, from natural language processing to computer vision, and even in medicine and finance. However, for many developers, experimenting with and applying some open-source models can be a challenge, as they often require expensive hardware resources to run. Most of the time, using these models necessitates having a server equipped with high-performance GPU, which is often an expensive investment. OpenRouter provides users with implementations of some open-source models that can be accessed for free via API, mainly focusing on models of around 7B scale, such as Google’s gemma-7b and Mistral AI‘s mistral-7b-instruct, which to some extent avoids the cost of deploying large models by oneself.
This article is based on the capabilities of the free model interface in OpenRouter, using Google’s gemma-7b model to build your own large model assistant, achieving the following effects:
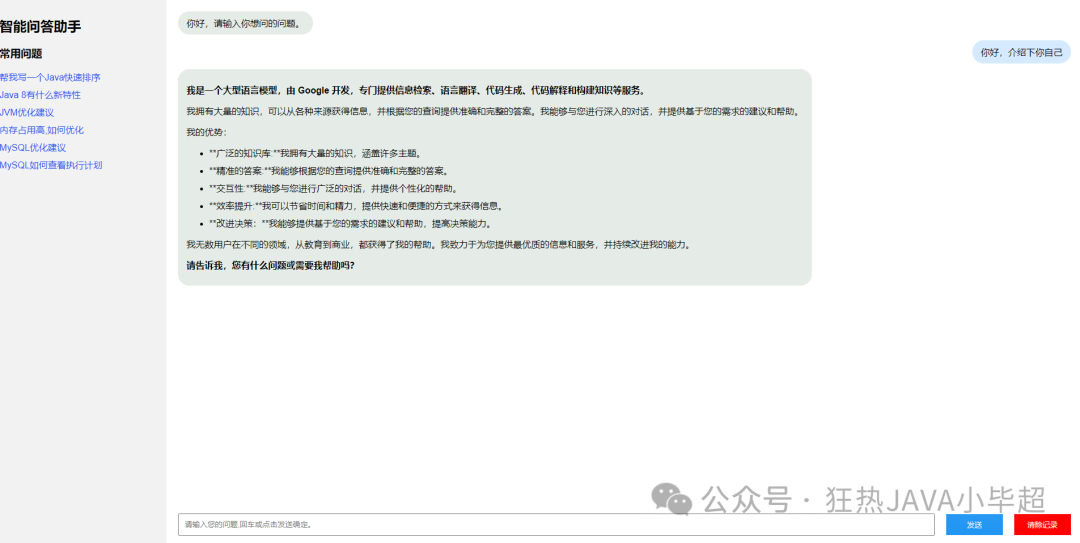

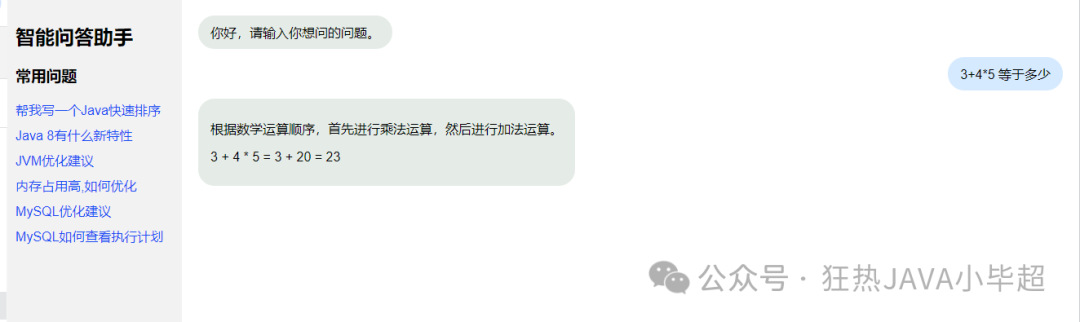
2. Using OpenRouter
Before experimenting, let’s first understand what OpenRouter is. OpenRouter is an intermediary service that integrates various large models, and can be accessed in China without a VPN. Through OpenRouter, you can call over 100 excellent large models, including popular models from OpenAI like the ChatGPT series (including GPT4V), Claude series from Anthropic, Google’s PaLM and Gemini series, etc. Switching models only requires changing the model name without modifying the logic of the calling code:



The official address is as follows:
https://openrouter.ai/
OpenRouter does not restrict QQ email and supports QQ email login and registration, providing convenience for some domestic users, and also offers a batch of 7B models for free, including nous-capybara-7b, mistral-7b-instruct, mythomist-7b, toppy-m-7b, cinematika-7b, and gemma-7b-it:
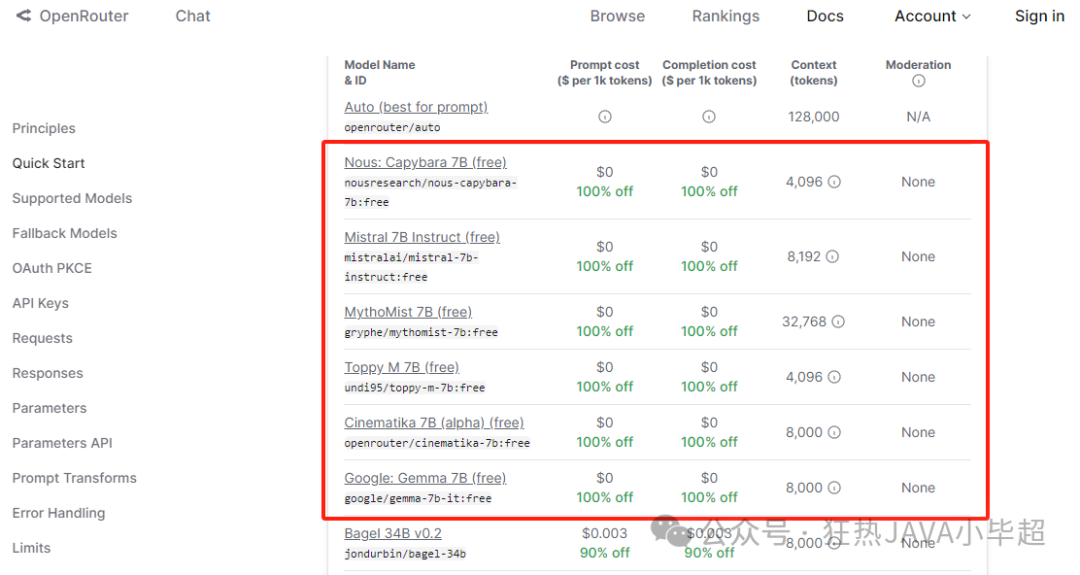
Therefore, when we do not have a GPU server but want to build our own large model assistant using open-source models, we can consider using OpenRouter. Note that you need to register an account and generate an Api key before using:
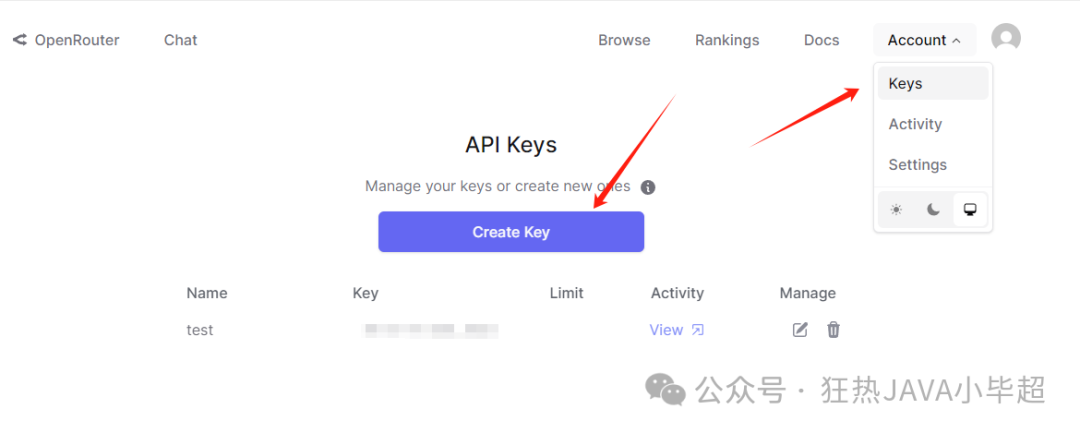
OpenRouter primarily uses http for interaction, so almost any language and framework that supports http can be used to call it, and it also supports calling via OpenAI‘s client.chat.completions.create method:
For example, using Python to call the gemma-7b model via http:
import requests
import json
url = "https://openrouter.ai/api/v1/chat/completions"
model = "google/gemma-7b-it:free"
request_headers = {
"Authorization": "Bearer 你的api_key",
"HTTP-Referer": "http://localhost:8088",
"X-Title": "test"
}
default_prompt = "You are an AI assistant that helps people find information."
def llm(user_prompt,system_prompt=default_prompt):
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
request_json = {
"model": model,
"messages": messages,
"max_tokens": 2048
}
respose = requests.request(
url=url,
method="POST",
json=request_json,
headers=request_headers
)
return json.loads(respose.content.decode('utf-8'))['choices'][0]['message']['content']
if __name__ == '__main__':
print(llm("你好,介绍一下你自己"))Output:
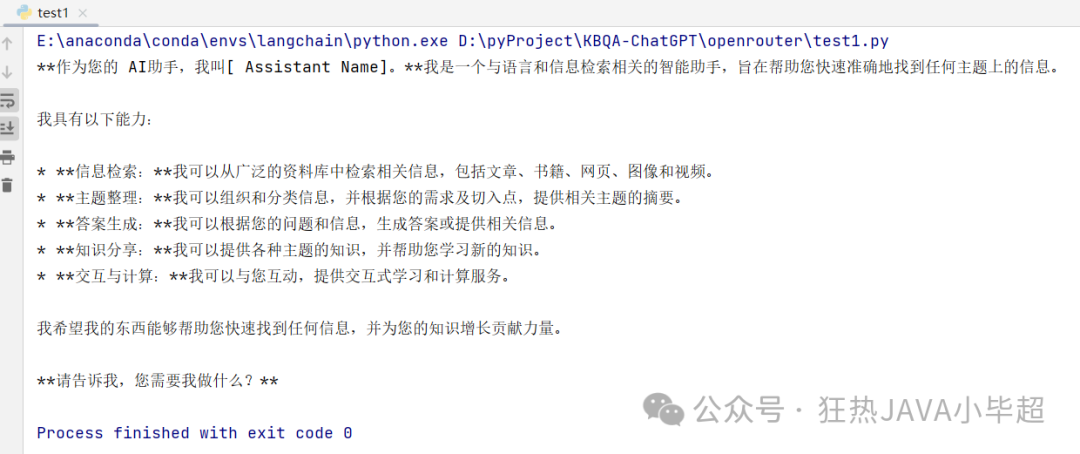
Using OpenAI‘s client.chat.completions.create method to call the gemma-7b model:
from openai import OpenAI
model = "google/gemma-7b-it:free"
default_prompt = "You are an AI assistant that helps people find information."
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="你的api_key",
)
def llm(user_prompt, system_prompt=default_prompt):
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
completion = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "http://localhost:8088",
"X-Title": "test",
},
model=model,
messages=messages,
max_tokens = 2048
)
return completion.choices[0].message.content
if __name__ == '__main__':
print(llm("你好,介绍一下你自己"))Output:
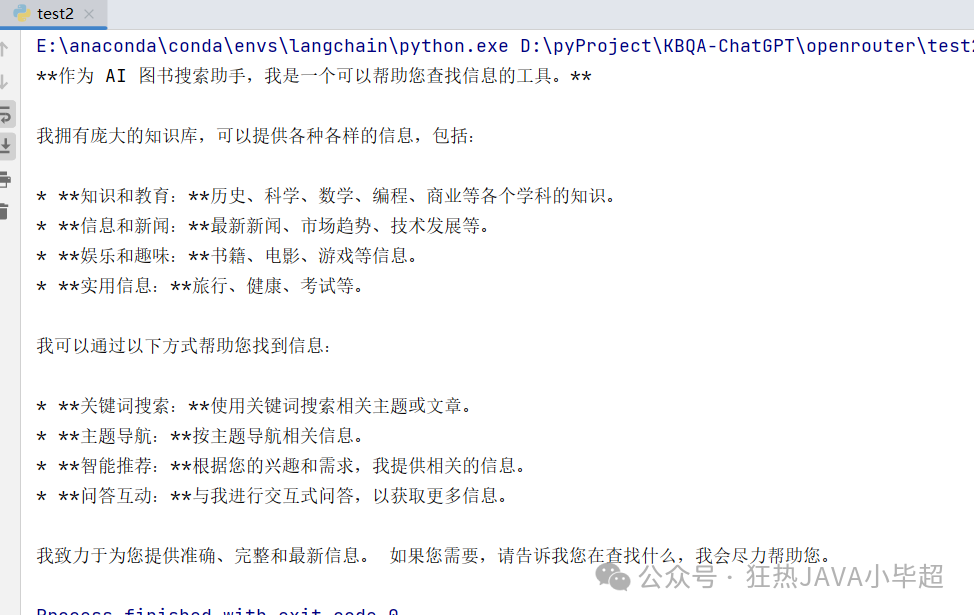
Streaming output example:
from openai import OpenAI
model = "google/gemma-7b-it:free"
default_prompt = "You are an AI assistant that helps people find information."
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="你的api_key",
)
def llm(user_prompt, system_prompt=default_prompt):
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
completion = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "http://localhost:8088",
"X-Title": "test",
},
model=model,
messages=messages,
max_tokens = 2048,
stream=True
)
for respose in completion:
if respose and respose.choices and len(respose.choices) > 0:
msg = respose.choices[0].delta.content
print(msg, end='', flush=True)
if __name__ == '__main__':
llm("你好,介绍一下你自己")Output:
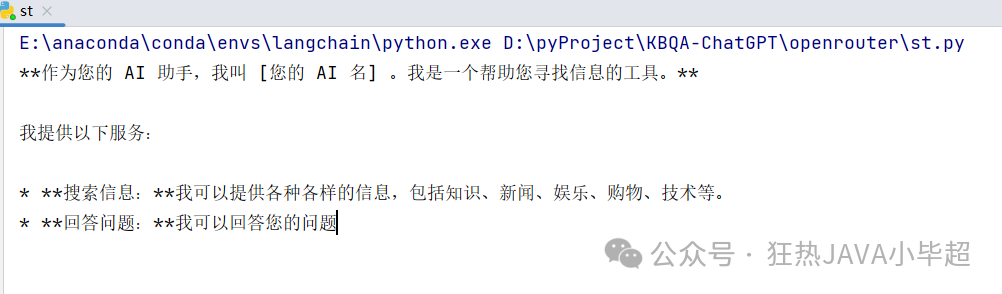
3. Building a Large Model Assistant
Having briefly understood the capabilities of OpenRouter, let’s build our own large model assistant based on Google’s gemma-7b model. The simple execution process is as follows.
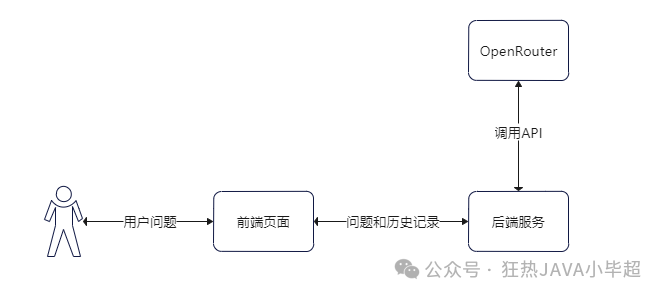
The backend service is implemented using Python + tornado to create a Web service, while the frontend uses basic Html + Jquery.
3.1 Backend Setup
The dependencies are as follows:
openai==0.27.8
tornado==6.3.2Construct the Q&A assistant interface server.py:
The interface receives two parameters, questions and history, where history is maintained and appended by the backend. The frontend only needs to temporarily store it, and each request carries the previous response’s history to call OpenRouter using the OpenAI library.
The overall implementation logic is as follows:
from tornado.concurrent import run_on_executor
from tornado.web import RequestHandler
import tornado.gen
from openai import OpenAI
import json
class Assistant(RequestHandler):
model = "google/gemma-7b-it:free"
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="你的api_key",
)
default_prompt = "You are an AI assistant that helps people find information."
def prepare(self):
self.executor = self.application.pool
def set_default_headers(self):
self.set_header('Access-Control-Allow-Origin', "*")
self.set_header('Access-Control-Allow-Headers', "Origin, X-Requested-With, Content-Type, Accept")
self.set_header('Access-Control-Allow-Methods', "GET, POST, PUT, DELETE, OPTIONS")
@tornado.gen.coroutine
def post(self):
json_data = json.loads(self.request.body)
if 'questions' not in json_data or 'history' not in json_data:
self.write({
"code": 400,
"message": "缺少必填参数"
})
return
questions = json_data['questions']
history = json_data['history']
result = yield self.do_handler(questions, history)
self.write(result)
@run_on_executor
def do_handler(self, questions, history):
try:
answer, history = self.llm(questions, history)
return {
"code": 200,
"message": "success",
"answer": answer,
"history": history
}
except Exception as e:
return {
"code": 400,
"message": str(e)
}
def llm(self, user_prompt, messages, system_prompt=default_prompt):
if not messages:
messages = []
messages.append({"role": "user", "content": user_prompt})
completion = self.client.chat.completions.create(
extra_headers={
"HTTP-Referer": "http://localhost:8088",
"X-Title": "test",
},
model=self.model,
messages=messages,
max_tokens=2048
)
answer = completion.choices[0].message.content
messages.append({"role": "assistant", "content": answer})
return answer, messages
Route configuration and starting the service app.py:
import tornado.web
import tornado.ioloop
import tornado.httpserver
import os
from concurrent.futures.thread import ThreadPoolExecutor
from server import Assistant
## Configuration
class Config():
port = 8081
base_path = os.path.dirname(__file__)
settings = {
# "debug":True,
# "autore load":True,
"static_path": os.path.join(base_path, "resources/static"),
"template_path": os.path.join(base_path, "resources/templates"),
"autoescape": None
}
# Routing
class Application(tornado.web.Application):
def __init__(self):
handlers = [
("/assistant", Assistant),
("/(.*)$", tornado.web.StaticFileHandler, {
"path": os.path.join(Config.base_path, "resources/static"),
"default_filename": "index.html"
})
]
super(Application, self).__init__(handlers, **Config.settings)
self.pool = ThreadPoolExecutor(10)
if __name__ == '__main__':
app = Application()
httpserver = tornado.httpserver.HTTPServer(app)
httpserver.listen(Config.port)
print("start success", "prot = ", Config.port)
print("http://localhost:" + str(Config.port) + "/")
tornado.ioloop.IOLoop.current().start()
You can use Postman to test:
Request content:
{
"questions":"你好,介绍下你自己",
"history":[]
}Output example:
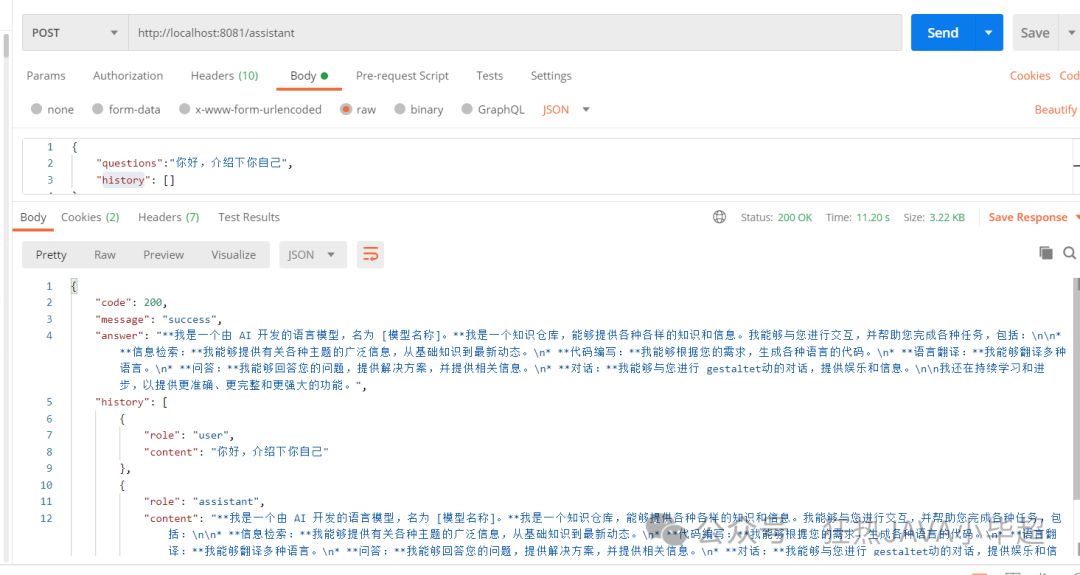
From the results, the interface access is normal. Next, we will start building the frontend.
3.2 Frontend Setup
The frontend needs to construct a Q&A chat interface. It is important to note that the content returned by the model may be in MD format, and the frontend needs to parse it into html format for display. The overall implementation process is as follows:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>AI Chat Assistant</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
}
.container {
display: flex;
height: 100vh;
}
.left-panel {
flex: 15%;
background-color: #f2f2f2;
padding: 10px;
}
.right-panel {
flex: 85%;
background-color: #ffffff;
display: flex;
flex-direction: column;
}
.chat-log {
flex: 1;
overflow-y: auto;
padding: 20px;
}
.chat-bubble {
display: flex;
align-items: center;
margin-bottom: 10px;
}
.user-bubble {
justify-content: flex-end;
}
.bubble-content {
padding: 10px 15px;
border-radius: 20px;
}
.user-bubble .bubble-content {
background-color: #d6eaff;
color: #000000;
}
.ai-bubble .bubble-content {
background-color: #e5ece7;
color: #000;
}
.input-area {
display: flex;
align-items: center;
padding: 20px;
}
.input-text {
flex: 1;
padding: 10px;
margin-right: 10px;
}
.submit-button {
padding: 10px 20px;
background-color: #2196f3;
color: #ffffff;
border: none;
cursor: pointer;
}
li {
margin-top: 10px;
}
a {
text-decoration: none;
}
table {
border: 1px solid #000;
border-collapse: collapse;
}
table td, table th {
border: 1px solid #000;
}
table td, table th {
padding: 10px;
}
.language-sql {
width: 95%;
background-color: #F6F6F6;
padding: 10px;
font-weight: bold;
border-radius: 5px;
word-wrap: break-word;
white-space: pre-line;
/* overflow-wrap: break-word; */
display: block;
}
select {
width: 100%;
height: 30px;
border: 2px solid #6089a4;
font-size: 15px;
margin-top: 5px;
}
.recommendation{
color: #1c4cf3;
margin-top: 10px;
}
</style>
</head>
<body>
<div class="container">
<div class="left-panel">
<h2>Smart Q&A Assistant</h2>
<h3>Common Questions</h3>
<div class="recommendation">Help me write a quick sort in Java</div>
<div class="recommendation">What are the new features in Java 8</div>
<div class="recommendation">JVM optimization suggestions</div>
<div class="recommendation">High memory usage, how to optimize</div>
<div class="recommendation">MySQL optimization suggestions</div>
<div class="recommendation">How to view the execution plan in MySQL</div>
</div>
<div class="right-panel">
<div class="chat-log" id="chat-log">
</div>
<div class="input-area">
<input type="text" id="user-input" class="input-text" placeholder="Please enter your question, press enter or click send to confirm.">
<button id="submit" style="margin-left: 10px;width: 100px" onclick="sendMessage()" class="submit-button">
Send
</button>
<button style="margin-left: 20px;width: 100px;background-color: red" onclick="clearChat()"
class="submit-button">Clear Records
</button>
</div>
</div>
</div>
<script type="text/javascript" src="http://code.jquery.com/jquery-3.7.0.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/marked/marked.min.js"></script>
<script>
// Chat history
var messageHistory = [];
// Add AI message
function addAIMessage(message) {
$("#chat-log").append(
"<div class=\"chat-bubble ai-bubble\">\n" +
" <div class=\"bubble-content\">" + message + "</div>\n" +
"</div>"
)
}
// Add user message
function addUserMessage(message) {
$("#chat-log").append(
"<div class=\"chat-bubble user-bubble\">\n" +
" <div class=\"bubble-content\">" + message + "</div>\n" +
"</div>"
)
}
// Scroll to bottom
function slideBottom() {
let chatlog = document.getElementById("chat-log");
chatlog.scrollTop = chatlog.scrollHeight;
}
// Call API
function chatApi(message) {
slideBottom();
data = {
questions: message,
history: messageHistory
};
$.ajax({
url: "http://127.0.0.1:8081/assistant",
type: "POST",
contentType: "application/json",
dataType: "json",
data: JSON.stringify(data),
success: function (res) {
if (res.code === 200) {
let answer = res.answer;
answer = marked.parse(answer);
addAIMessage(answer);
messageHistory = res.history;
} else {
addAIMessage("Service interface call error.");
}
},
error: function (e) {
addAIMessage("Service interface call exception.");
}
});
}
// Send message
function sendMessage() {
let userInput = $('#user-input');
let userMessage = userInput.val();
if (userMessage.trim() === '') {
return;
}
userInput.val("");
addUserMessage(userMessage);
chatApi(userMessage);
}
// Clear chat records
function clearChat() {
$("#chat-log").empty();
messageHistory = [];
addAIMessage("Hello, please enter your question.");
}
// Initialize
function init() {
addAIMessage("Hello, please enter your question.");
var submit = $("#submit");
var userInput = $("#user-input");
var focus = false;
// Listen for input box focus
userInput.focus(function () {
focus = true;
}).blur(function () {
focus = false;
});
// Enter key event listener
document.addEventListener("keydown", function (event) {
if (event.keyCode === 13) {
console.log(focus);
if (focus) {
submit.click();
}
}
});
}
init();
</script>
</body>
</html>
Running effect:
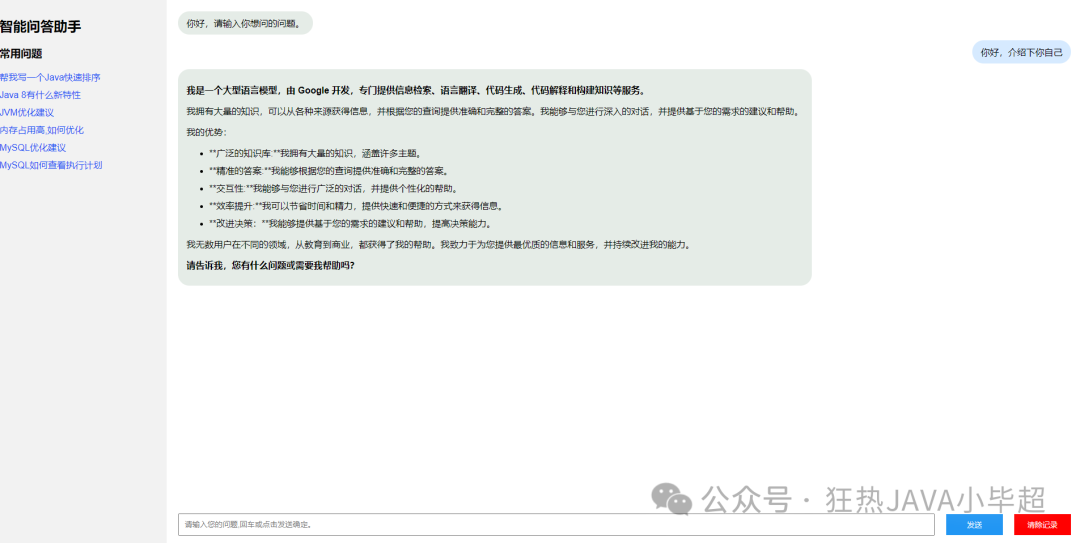

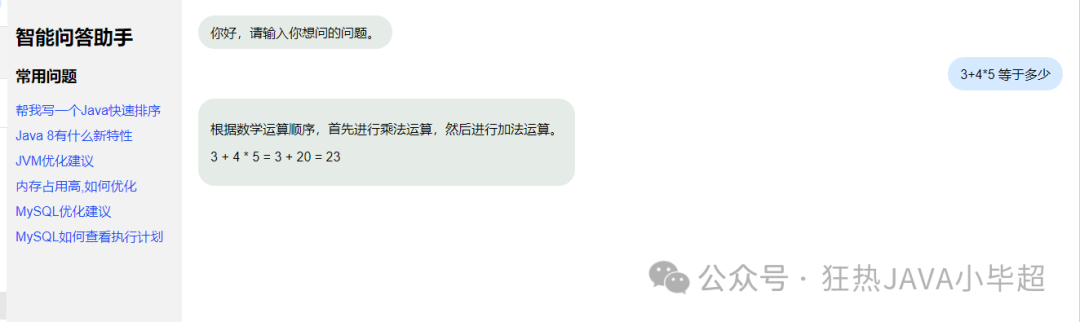
At this point, our own large model assistant is basically complete!