
Baidu NLP Column
Author: Baidu NLP
1. Introduction
Text matching is an important foundational problem in natural language processing. Many tasks in natural language processing can be abstracted as text matching tasks. For example, web search can be abstracted as a relevance matching problem between web pages and user search queries, automatic question answering can be abstracted as a satisfaction matching problem between candidate answers and questions, and text deduplication can be abstracted as a similarity matching problem between texts.
Traditional text matching techniques, such as the Vector Space Model (VSM) and BM25 algorithms in information retrieval, primarily solve matching problems at the lexical level, or in other words, similarity problems at the lexical level. However, matching algorithms based on lexical overlap have significant limitations due to several reasons:
1) Ambiguity and Synonymy in Language
The same word can express different meanings in different contexts. For example, “apple” refers to both a fruit and a technology company. Similarly, the same meaning can be expressed by different words, such as “taxi” and “cab” both referring to a taxi.
2) Structural Composition Issues in Language
The same words arranged in different sequences can express different meanings, such as “deep learning” and “learning deep.” Furthermore, there are syntactic structure issues, for example, “high-speed train from Beijing to Shanghai” and “high-speed train from Shanghai to Beijing” contain the same words but have completely different meanings. Meanwhile, “Beijing team defeated Guangdong team” and “Guangdong team was defeated by Beijing team” have the same meaning.
3) Asymmetry in Matching
Text matching tasks are not solely about text similarity. On one hand, linguistic similarity is not always required. For instance, in web search tasks, the language used in the query may differ significantly from that on the web page, at least in terms of length. On the other hand, semantic equivalence is not always necessary; in question answering tasks, the two texts to be matched do not need to be synonymous but should determine whether the candidate answer truly addresses the question.
This indicates that for text matching tasks, one cannot only remain at the literal matching level; semantic matching is also needed, which includes not only similarity matching but also broader forms of matching.
In response to these issues, various improvements have been proposed. For example, using statistical machine translation methods to mine synonyms or synonymous phrases to solve mismatch problems; avoiding structural distortion problems by measuring semantic closeness and word spacing; and addressing asymmetric matching issues to some extent through keyword tagging and click-through calculations on web pages. These methods have shown some effectiveness, but overall they lead to very complex strategic logic and have not completely solved the semantic matching problems in specific tasks.
At the semantic matching level, the first challenge is how to represent and compute semantics.
The latent semantic analysis technology that became popular in the 1990s opened up a new avenue by mapping words and phrases to an equal-length low-dimensional continuous space, allowing for similarity calculations in this implicit “latent semantic” space. Subsequently, more advanced probabilistic models such as PLSA (Probabilistic Latent Semantic Analysis) and LDA (Latent Dirichlet Allocation) were designed, gradually forming a very hot topic modeling technology direction. These technologies provide a concise representation of text semantics and are computationally convenient, effectively compensating for the shortcomings of traditional lexical matching methods. However, in terms of effectiveness, these technologies cannot replace literal matching techniques but can only serve as effective supplements.
With the rise of deep learning technology, text matching calculations based on word embeddings trained by neural networks have garnered widespread interest. The training method for word embeddings is simpler, and the semantic computability of the resulting word vectors is further enhanced. However, using word embeddings trained only on unannotated data yields practical results in matching calculations that are not much different from topic modeling techniques; they are essentially both based on co-occurrence information. Moreover, word embeddings themselves do not solve the semantic representation issues of phrases and sentences, nor do they resolve the asymmetry in matching.
In 2013, we developed a supervised neural network semantic matching model called SimNet, which significantly improved the effectiveness of semantic matching calculations. SimNet inherits the implicit continuous vector representation for semantic representation but models the semantic matching problem in an End-to-End manner within a deep learning framework, unifying the embedding representations of words with the semantic representations of sentences, the vector representations of semantics with matching calculations, and the matching calculations of text pairs with pairwise supervised learning, all within a single framework. In practical applications, massive user click behavior data can be transformed into large-scale weakly labeled data, paired with our efficient parallel training algorithm, allowing SimNet, trained on big data, to significantly surpass the effectiveness of topic model algorithms and achieve a complete replacement of strategies based on literal matching, while also directly modeling non-similarity matching problems. Its initial use in web search tasks demonstrated tremendous power, resulting in significant improvements in relevance.
In recent years, related research in academia has gradually increased. For instance, the DSSM model (Deep Structured Semantic Model) proposed by Microsoft Research is very similar to the initial version of SimNet in model framework, differing mainly in training methods. Huawei’s NOAH’S ARK LAB has also proposed several new variants of neural network matching models, such as convolutional matching models based on two-dimensional interactive matching. Research institutions like the Chinese Academy of Sciences have proposed more sophisticated neural network text matching models, such as the Multi-view Recurrent Neural Network Matching Model (MV-LSTM) and the Hierarchical Matching Model MatchPyramid based on matrix matching.
At the same time, we have continuously optimized and improved SimNet, with ongoing enhancements in model effectiveness and expanding applicable scenarios. In addition to web search products, it has also been successfully applied to multiple product lines and application systems, such as advertising, news recommendations, machine translation, and deep question answering, achieving significant results. It is particularly noteworthy that compared to some research efforts in academia, we not only focus on optimizing the model algorithms themselves but also emphasize the integration of deep learning models with foundational natural language processing technologies, especially considering the linguistic characteristics of Chinese, enhancing the practical effectiveness of neural network semantic matching technologies from a usability perspective.
Below, we will first provide an overall introduction to the SimNet framework and model algorithm variants, followed by a focus on improvement strategies that better integrate text characteristics with NLP methods, and finally discuss some factors that need to be considered in practical applications.
2. SimNet Framework
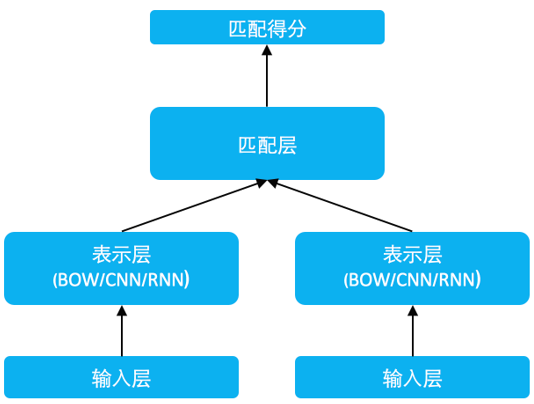
Figure 1: SimNet Framework
The SimNet framework is illustrated in the figure above, mainly divided into input layer, representation layer, and matching layer.
1. Input Layer
This layer converts the text word sequence into a word embedding sequence through a lookup table.
2. Representation Layer
This layer primarily constructs representations from words to sentences, or transforms isolated word embeddings of the sequence into one or more low-dimensional dense semantic vectors with global information. The simplest method is the Bag of Words (BOW) accumulation method, and in addition, we have developed corresponding sequence convolutional networks (CNN), recurrent neural networks (RNN), and various other representation techniques within the SimNet framework. Of course, after obtaining the sentence representation vector, one can also add more layers of fully connected networks to further enhance the representation effect.
3. Matching Layer
This layer utilizes the representation vectors of the texts for interactive calculations. Depending on the application scenario, we have developed two matching algorithms.
1) Representation-based Match
This method focuses more on constructing the representation layer, ensuring that both ends to be matched are converted into equal-length semantic representation vectors. Then, based on the corresponding semantic representation vectors from both ends, matching degree calculations are performed. We designed two calculation methods: one is through a fixed metric function, with the most commonly used being the cosine function, which is simple and efficient with a controllable and meaningful scoring range; the other involves passing the two vectors through a multi-layer perceptron (MLP) to fit a matching score through data training, which is more flexible but requires higher training demands.

2) Interaction-based Match
This method emphasizes more on the sufficient interaction between the two ends to be matched and the matching based on that interaction. Therefore, it does not convert the text into a unique overall representation vector in the representation layer but generally retains a set of representation vectors corresponding to word positions. Below, we introduce a practical application of a SimNet model variant under this approach. First, based on the representation layer, we obtain intermediate position representations of the text using a bidirectional RNN, where each vector corresponding to the word position reflects certain global information centered around that word; then, the two texts interact based on word correspondence, thus constructing a matching matrix between the two texts (of course, multiple matrices can also be constructed to form tensors), which includes more detailed and localized text interaction information; based on this local matching feature matrix, we further use convolution to extract advanced matching features from words to N-Grams, followed by pooling and MLP to obtain the final matching score.
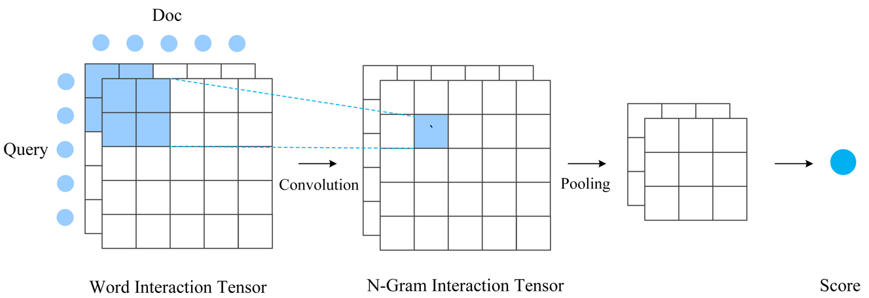
Figure 4: Interaction-based Matching Method
The Interaction-based Match matching method provides a more detailed and sufficient modeling of matching, generally resulting in better performance, but the computational cost increases significantly, making it suitable for applications requiring high accuracy but not high computational performance. In most scenarios, we choose the more concise and efficient Representation-based matching method.
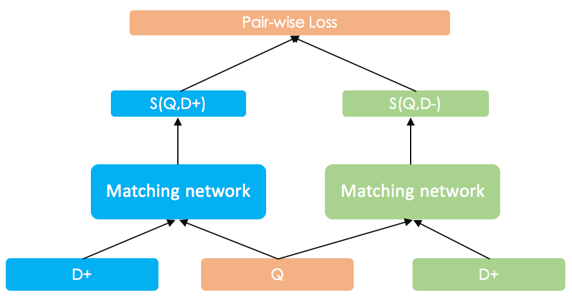
Figure 5: Pair-wise SimNet Training Framework
We adopted pair-wise Ranking Loss for the training of SimNet. Taking web search tasks as an example, suppose the search query text is Q, a relevant document is D+, and an irrelevant document is D-. The matching scores obtained from the SimNet network for Q with D+ and D- are S(Q,D+) and S(Q,D-), respectively, and the optimization objective for training is to ensure that S(Q,D+) > S(Q,D-). In practice, we generally use the Max-Margin Hinge Loss:
max{0, margin – (S(Q,D+) – S(Q,D-))}
This loss is simple and efficient, and the model’s score distinguishability can be adjusted through different margin settings.
3. Feature Improvements in Text Tasks
The matching framework of SimNet is very universal. Especially the Representation-based model has seen similar applications in images for a long time. As early as the 1990s, there were works using Siamese Networks for signature verification matching. However, for text tasks, some unique characteristics of language require us to have more targeted considerations.
Given the one-dimensional sequence characteristics of text, more targeted modeling is needed in the representation layer. For example, we implemented one-dimensional sequence convolutional networks and Long Short-Term Memory networks (LSTM), both of which fully consider the characteristics of text.
Additionally, from the perspective of input signals, we have also fully considered the characteristics of text. SimNet, as an End-to-End semantic matching framework, greatly reduces the cost of feature design, allowing for direct input of text word sequences. However, for Chinese, since the basic language unit is the character, a word segmentation step is still required, but word segmentation itself is a challenging task, and there is no strict definition for the granularity of words. Therefore, the SimNet framework needs to reduce its reliance on precise word segmentation or consider how to enhance matching effectiveness from the perspective of word segmentation. On the other hand, although complex feature design is no longer needed, the production of some basic NLP techniques, such as high-frequency co-occurring segments and syntactic structure information, whether they can be integrated into the SimNet framework as prior knowledge to play a role, is also a direction worth exploring.
1. Character Granularity Matching and Multi-granularity Fusion
We first verified the matching at the character granularity. Since the number of Chinese characters is far less than the number of words (which can reach millions), even with an appropriate increase in the embedding dimension, the overall model size can be significantly reduced. In the SimNet-RNN model, through careful design, character granularity input can achieve matching effects comparable to word granularity. Of course, in most SimNet variants, character granularity has some performance gap compared to word granularity, but the gap is not too large. This allows for the direct use of character granularity models in scenarios with tight memory or without a word segmentation module, achieving good results.
Furthermore, we found that character granularity has good generalization, effectively compensating for the shortcomings of word granularity input, such as segmentation errors and out-of-vocabulary (OOV) issues. This suggests that we can fuse and complement character granularity and word granularity. On the other hand, since there is no unique objective standard for word segmentation, different segmentation methods can also achieve complementarity. For instance, both coarse-grained and fine-grained segmentation can be used simultaneously. This way, the precision requirement for a single word segmentation can be relaxed. This also, in a sense, reduces the high dependence of semantic matching tasks on word segmentation.
From the final results, the fusion of multiple segmentation granularities has led to significant improvements in practical applications. However, there is no unique model for how to fuse multiple segmentation granularities. In the SimNet framework, multi-granularity fusion can be designed and implemented at the input layer, representation layer, and matching layer.
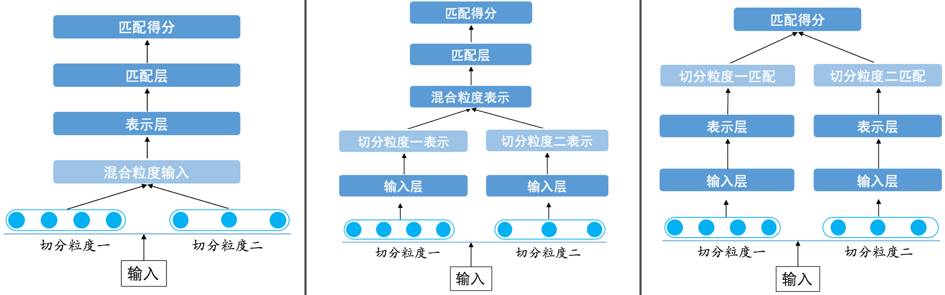
Figure 6: Fusion of Multiple Segmentations in the SimNet Framework
The fusion at the input layer should consider the characteristics of the representation layer network. For BOW, which is an unordered representation structure, we can directly feed multiple segmentation granularities into the model. For ordered representation structures like CNN/RNN, the fusion at the input layer requires some “techniques,” such as considering the alignment of granularity at the character level.
Fusion at the representation layer is more flexible and convenient. Neural networks have many effective ways to merge multiple fixed-length vectors into one, such as simple concatenation or element-wise addition, and more complex methods can also incorporate gate mechanisms. Thus, we can easily fuse multiple representation vectors generated from different segmentation granularities and obtain the final matching similarity through the fused semantic representation layer.
The fusion at the matching layer can be achieved in the simplest and most intuitive way, which is to perform a weighted sum of the matching scores from different representation granularities. This is somewhat similar to an ensemble of matching models with different granularities, but the distinction is that all granularities are trained simultaneously. In this mode, the parameter and computational loads are also the largest.
Experience shows that the earlier the granularity fusion is performed, the better the final effect will be. This is likely because it allows the complementary capabilities of different granularities to be fully utilized as early as possible.
2. Introduction of High-Frequency Bigram and Collocation Segments
Would larger phrase segment granularities than basic word segmentation further enhance effectiveness? Theoretically, the larger the text segment, the more precise the meaning, but it also becomes sparser. The vocabulary at the word granularity level can reach millions, and adding even larger segments puts too much pressure on the model and may also face issues of insufficient training. We designed a clever statistical metric based on big data to select a small amount of high-frequency co-occurring term combinations with significant information value for the matching task, introducing them as bigrams into the dictionary, which further significantly enhances model performance.
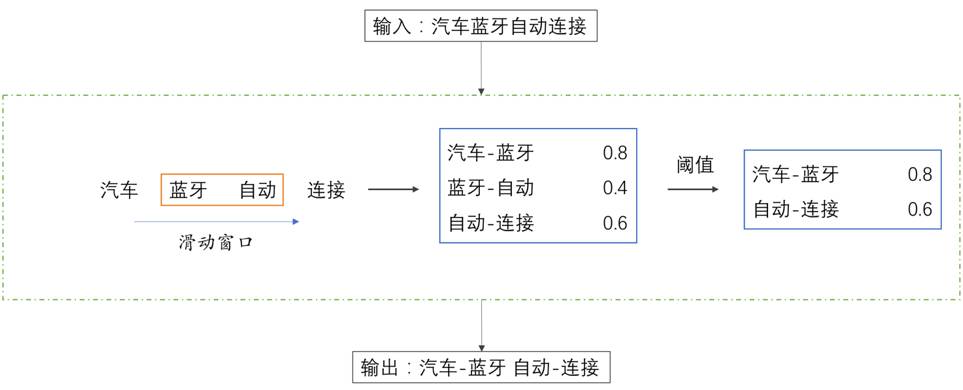
For example, if we input the corpus “Car Bluetooth Automatic Connection,” using basic word segmentation tools, we can segment the sequence into four terms: “Car Bluetooth Automatic Connection.” At this point, through statistical analysis based on big data, we can find that “Car-Bluetooth” has the highest statistical score, followed by “Automatic-Connection,” and “Bluetooth-Automatic” has the lowest. Thus, based on a set statistical threshold, we obtain the output based on bigram granularity.
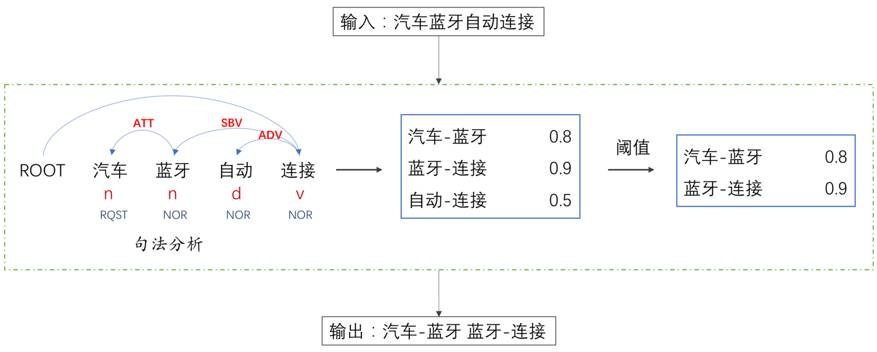
In addition to bigrams, some collocations that span words are also crucial for text semantics. We use dependency syntax analysis tools to obtain the corresponding collocation segments. Using the previous example of “Car Bluetooth Automatic Connection,” we construct a dependency analysis tree for the input corpus and count the co-occurrence frequency of parent and child nodes. Ultimately, we find that “Bluetooth-Connection” is more significant than “Automatic-Connection,” so the final output becomes “Car-Bluetooth Bluetooth-Connection.”
Whether it is bigrams or collocations, they serve to incorporate some prior information into the model using foundational NLP techniques in a straightforward manner, reducing the learning difficulty for the model and significantly improving semantic matching effectiveness in many scenarios.
The above explorations indicate that considering the characteristics of text tasks and the unique features of language, we can not only better design and select neural network models but also effectively integrate some foundational NLP analysis techniques with models to achieve better results more efficiently.
4. Considerations in Practical Applications
In practical applications, in addition to model algorithms, many factors can significantly impact the final effectiveness. The most important of these is data, along with the characteristics of the application scenario.
For deep learning models, the scale of data is crucial. The success of web search applications is largely due to the availability of massive user click data. However, merely having a large quantity is not enough; one must also consider how the data is filtered, how positive and negative examples are set, especially how negative examples are selected. For instance, in web search applications, if frequency issues are not considered, the vast majority of training data may consist of high-frequency query data, but high-frequency queries generally yield better search results. Additionally, some queries have many relevant web pages, while others have very few, leading to significant differences in the number of positive-negative pairs that can be formed. How to handle these issues is crucial, as different data design approaches can greatly affect the final effectiveness.
The application scenario is equally important. For example, is the final matching score the ultimate result, or is it used as feature input for the next layer model? If used as input for the next layer, are there comparability requirements for the scores? What is the final task, classification or ranking? If it is ranking, how can the optimization objectives for ranking be made more consistent with the training optimization objectives? Some of these factors will influence how data is organized, while others may require targeted adjustments to certain model hyperparameters. For example, the specific setting of margin in the aforementioned loss function can affect the trade-off between accuracy metrics and score distinguishability.
Of course, training factors such as learning rate also greatly influence task success, but the ease of setting and adjusting these factors depends on the specific training programs and platforms.
Extended Reading from Baidu NLP Column:
-
Baidu NLP | Intelligent Writing Robot: Not Competing with Humans, We Just Want Human-Machine Collaboration
-
Baidu NLP | Automatic Poetry Writing vs. Ancient Poets: A Deep Dive into Baidu’s “Writing Poems for You” Technology
-
Exclusive Interview with Baidu Vice President Wang Haifeng: The Road of NLP is Still Long
“Baidu NLP” column mainly focuses on the development process of Baidu’s natural language processing technology, reporting cutting-edge information and dynamics, sharing industry insights and deep thoughts from technical experts.

© This article is part of the Machine Heart column, please contact this public account for authorization to reproduce.
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submission or Seeking Coverage: [email protected]
Advertising & Business Cooperation: [email protected]
Click to read the original text and view the Machine Heart official website↓↓↓