
This article is reproduced with permission from the WeChat public account Paper Weekly (ID: paperweekly). Paper Weekly shares interesting papers in the field of natural language processing every week.
“In-depth Analysis: GAN Models and Their Progress in 2016” [1] provides a detailed introduction to the progress of GANs over the past year, which is highly recommended for newcomers learning about GANs. This article mainly discusses the applications of GANs in NLP (which can be considered as a paper interpretation or notes), and does not cover the basic knowledge of GANs (for those without basic knowledge of GANs, it is recommended to first read [1]; since I am quite lazy, I won’t elaborate on the basic knowledge of GANs here J). As I haven’t written in Chinese for a long time, please bear with and advise me on any inaccuracies in the article.
Although GANs have achieved great success in image generation, they have not produced surprising results in natural language processing (NLP) tasks. The reasons can be summarized as follows:
-
The original GANs primarily operate in real number space (continuous data) and do not work well for generating discrete data (texts). Dr. Ian Goodfellow, the proposer of GAN theory, responded to this issue: “GANs have not yet been applied to natural language processing (NLP); the original GANs were defined only in the real number domain. GANs generate synthetic data through a trained generator, and then run a discriminator on the synthetic data. The output gradient of the discriminator will inform you how to slightly modify the synthetic data to make it more realistic. Generally, you can only slightly modify synthetic data when the data is continuous; if the data is discrete, you cannot simply change the synthetic data. For example, if you output an image with a pixel value of 1.0, you can change this value to 1.0001. However, if you output the word “penguin”, you cannot change it to “penguin + .001” because there is no such word as “penguin + .001”. Since all foundational elements of natural language processing (NLP) are discrete values such as “words”, “letters”, or “syllables”, applying GANs in NLP is very challenging. Generally, reinforcement learning algorithms are used. As far as I know, no one has really started researching the use of reinforcement algorithms to solve NLP problems.”
-
When generating text, GANs model and score the entire text sequence. It is very difficult to assess the score of a partially generated sequence when generating the entire sequence.
-
Another potential challenge relates to the nature of RNNs (most text generation uses RNN models). If we attempt to generate text from latent codes, the error will accumulate exponentially with the length of the sentence. The initial few words may be relatively reasonable, but the quality of the sentence deteriorates as the length increases. Additionally, the length of the sentence is generated from random latent representations, making it difficult to control the sentence length.
Below, I will mainly introduce and analyze some recent papers that apply GANs in NLP:
1. Generating Text via Adversarial Training
-
Paper link: http://people.duke.edu/~yz196/pdf/textgan.pdf
-
This paper was presented at the NIPS GAN Workshop in 2016 and attempts to apply GAN theory to text generation tasks. The methods in this paper are relatively simple and can be summarized as follows:
-
Using recurrent neural networks (LSTM) as the generator of GAN. The approach uses smooth approximations to approximate the output of LSTM. The structure diagram is as follows:
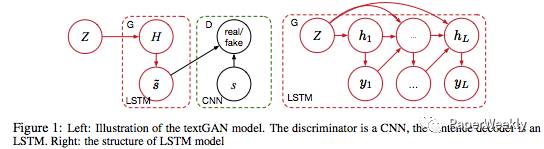
-
The objective function of this paper differs from that of the original GAN, using feature matching methods. The iterative optimization process includes the following two steps:
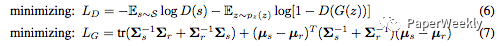
Here, equation (6) is the optimization function of the standard GAN, and equation (7) is the optimization function for feature matching.
-
The initialization process in this paper is quite interesting, especially in the pre-training of the discriminator, where the original sentence and a new sentence obtained by swapping two words in that sentence are used for discrimination training. (During the initialization process, the pointwise classification loss function is used to optimize the discriminator). This is quite interesting because the information input by swapping two words is essentially the same. For example, most convolutional calculations will ultimately yield completely identical values.
-
The update frequency of the generator in this paper is five times that of the discriminator, which is exactly the opposite of the original GAN setting. This is because LSTM has more parameters than CNN, making it more difficult to train.
-
However, the generator model (LSTM) has an exposure bias problem during the decoding phase, which means that during training, it gradually replaces the actual output with the predicted output as the input for the next word.
2. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
-
Paper link: https://arxiv.org/pdf/1609.05473.pdf
-
Paper source code: LantaoYu/SeqGAN
-
This paper treats the text generation process as a sequential decision-making process. As shown in the following diagram:
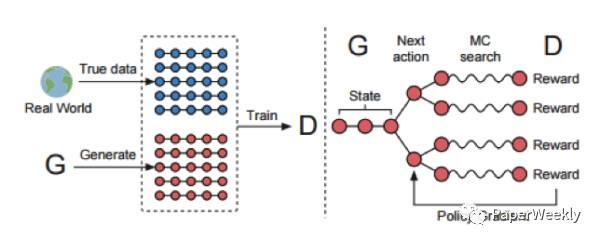
(a) The left diagram shows step 1 of GAN network training, where the discriminator D is mainly used to distinguish between real samples and fake samples, and the discriminator D is implemented using CNN.
(b) The right diagram shows step 2 of GAN network training, where the probability returned by the discriminator D is fed back to the generator G, updating the generator G using reinforcement learning methods, where the generator G is implemented using LSTM.
(c) The update strategy of the G network is reinforcement learning, and the four elements of reinforcement learning: state, action, policy, and reward are defined as follows: state is the tokens that have already been generated (the results from the LSTM decoder before the current timestep), action is the next token to be generated (the current decoding word), policy is the GAN generator G network, and reward is the probability generated by the GAN discriminator D network. The reward is approximated using the following method: 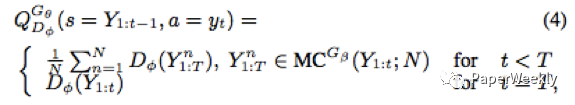
This process features that when decoding at timestep t, Monte Carlo search is used to explore N paths for the remaining T-t timesteps, and these N paths are combined with the already decoded results to form N complete outputs, with the average value of the rewards corresponding to the D network being used as the reward. When t=T, it is no longer possible to explore backward paths, so the reward is directly taken as the reward for the complete decoded result.
(d) For the RL part, this paper uses the policy gradient method. According to the policy gradient theory, the objective function of the generator G can be expressed as follows: 
The derivation result is: (for detailed derivation, please refer to the original paper’s appendix) 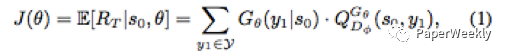
(e) After a period, when more realistic sentences are generated, the discriminator D is retrained, with the objective function of the discriminator represented as follows:
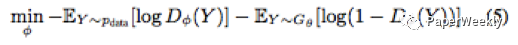
The algorithm structure diagram can be represented as follows: 
-
Experiments
The experimental section is mainly divided into synthetic data experiments and real data experiments.
(a) Synthetic data experiments: Randomly initialize an LSTM generator A, randomly generate a portion of training data to train various generative models.
The evaluation criterion is: negative log likelihood (cross-entropy) NLL. Detailed experimental settings can be found in the original paper.
(b) Real data experiments: Mainly showcase the results of generating Chinese poetry, Obama’s speeches, and music. The experimental datasets include a Chinese poetry dataset (16,394 quatrains), Obama’s speech dataset (11,092 paragraphs), and the Nottingham music dataset (695 songs). The evaluation method is BLEU score, with the experimental results as follows:
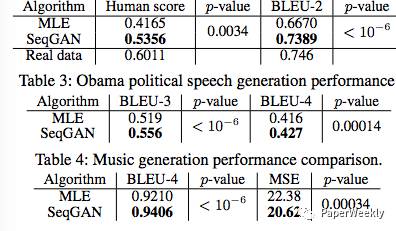
The paper does not showcase the generated poems, so what is the actual effect?
3. Adversarial Learning for Neural Dialogue Generation
-
Paper link: https://arxiv.org/pdf/1701.06547.pdf
-
Paper source code: jiweil/Neural-Dialogue-Generation
-
This paper was uploaded to arxiv on January 26, 2017, and is one of the latest papers on GANs used in NLP. The paper mainly uses adversarial training methods for open-domain dialogue generation. The task is treated as a reinforcement learning (RL) problem, jointly training the generator and discriminator. Similar to SeqGAN, this paper also uses the results from the discriminator D as the reward part for RL, which rewards the generator G, encouraging it to produce dialogues similar to human conversations.
-
Overall, the idea of this paper is similar to SeqGAN, but there are several differences and improvements:
(a) Since this paper is for open-domain dialogue generation, the generator used in the paper employs a seq2seq model (instead of a regular LSTM model). The discriminator uses a hierarchical encoder (instead of CNN).
(b) Two methods are employed to calculate the reward for fully generated or partially generated sequences. In addition to the Monte Carlo search method (similar to SeqGAN), this paper proposes a new method for calculating rewards for partially generated sequences. Training the discriminator with all fully and partially decoded sequences can lead to overfitting. Early generated partial sequences will appear in many training data, for example, the generated first token y_1 will appear in all partially generated sequences. Therefore, this paper suggests randomly selecting one sample from each positive sequence y+ and negative sequence y- to train the discriminator D. This method is faster than Monte Carlo search but may weaken the discriminator and make it less accurate.
(c) In SeqGAN, the generator can only indirectly receive rewards or punishments for the sequences it generates through the rewards generated by the discriminator, and cannot directly obtain information from the gold-standard sequences. This training method is fragile; if the generator deteriorates in a certain training batch, the discriminator can easily judge the generated sentences (for example, reward = 0), and the generator will become lost. The generator only knows that the current generated sentence is poor but does not know how to adjust it to improve the generated sentence. To solve this problem, during the generator’s update process, this paper inputs human-generated responses. For these human-generated responses, the discriminator can set the reward to 1. This way, the generator can still produce good responses under the aforementioned circumstances.
(d) During the training process, there are some settings (tricks) specific to dialogue systems. Readers can refer to Jiwei Li’s previous papers on dialogue systems for more information.
-
Some experimental results:

-
Points to ponder: The paper only attempts to use the results of the discriminator as rewards. Would combining other reward mechanisms proposed by the authors in previous dialogue system papers (e.g., mutual information) improve the results?
4. GANs for Sequence of Discrete Elements with the Gumbel-Softmax Distribution
-
Paper link: https://arxiv.org/pdf/1611.04051.pdf
-
Compared to the previous two papers, this paper handles the problem of discrete data in a rather straightforward manner. Discrete data (represented using one-hot encoding) can generally be obtained through polynomial sampling, such as obtaining p = softmax(h) from the output of the softmax function. The sampling process of y based on the previous probability distribution with probability p is equivalent to: y=one_hot(argmax_i(h_i+g_i)), where g_i follows the Gumbel distribution (with zero location and unit scale). However, one_hot(argmax(.)) is not differentiable. Unlike the original GAN, the authors propose a method to approximate the above expression: y = softmax(1/r(h + g)). This formula is differentiable. The algorithm structure is as follows:

-
The experimental section of this paper is relatively rough, only showcasing the generation of context-free grammar and not conducting experiments on generating other text data.
-
Overall, the methods in this paper are worth improving and can serve as a reference.
5. Connecting Generative Adversarial Network and Actor-Critic Methods
-
Paper link: https://arxiv.org/pdf/1610.01945.pdf
-
Actor-critic methods [2]: Many RL methods (e.g., policy gradient) only apply to either policy or value function. Actor-critic methods combine both policy-only and value function-only methods. The critic is used to approximate or estimate the value function, while the actor, known as the policy structure, is mainly used to select actions. Actor-critic is an on-policy learning process. The results of the critic model are used to help improve the performance of the actor policy.
-
GAN and actor-critic have many similarities. The actor in the actor-critic model functions similarly to the generator in GAN, as they both take an action or generate a sample. The critic in the actor-critic model is similar to the discriminator in GAN, primarily used to evaluate the output of the actor or generator. Interested readers can refer to the original paper for specific similarities and differences.
-
The main contribution of this paper is to illustrate the similarities and differences between GANs and actor-critic models from different perspectives, thereby encouraging researchers studying GANs and those studying actor-critic models to collaborate on developing universal, stable, and scalable algorithms or to draw inspiration from each other’s research.
-
Recently, Bahdanau and others proposed using actor-critic models for sequence prediction [3]. Although [3] did not use GANs, it might provide inspiration for everyone. Perhaps using similar ideas, GANs could also achieve good results in sequence prediction?
[1] In-depth Analysis: GAN Models and Their Progress in 2016
[2] Actor-Critic Algorithms
[3] An Actor-Critic Algorithm for Sequence Prediction
Author
Yang Min, PhD in Computer Science at the University of Hong Kong, engaged in research in natural language and machine learning, recently also focusing on and researching non-goal-oriented dialogue systems and goal-oriented question answering. Please feel free to contact me if you have similar interests.
Homepage: http://minyang.me/
Sina Weibo: Yang Min_HKU
WeChat: yangmin19911129
Read More
▽ Stories
· Rejected by journals repeatedly? Listen to the practical advice from journal editors.
· Turning thirty? Your brain may not have stopped developing (including 7 methods to maintain brain health).
· Cell reports the world’s first human-animal chimeras—medical hope or ethical disaster?
· Will living in space change genes? This pair of twins from NASA tells us—
▽ Paper Recommendations
· A biophysicist from CUHK discovers new collective oscillation patterns in bacteria | Nature paper recommendation
· Yan Ning’s research group reports the first near-atomic resolution structure of a eukaryotic voltage-gated sodium channel | Science paper recommendation
· The brain’s synapses shrink during sleep, which may guarantee learning ability | Science paper recommendation
▽ Paper Digest
· Science and other weekly paper digest (Part 1) | February 2017 Issue 1
· Science and other weekly paper digest (Part 2) | February 2017 Issue 1
For content cooperation, please contact
This is the WeChat official account of the Chinese version of Scientific American, “Global Science”, which serves researchers. We:
· Focus on scientific progress and research ecology
· Recommend important frontier research
· Publish research recruitment
· Push academic lectures and conference announcements.
Welcomelong press the QR code to follow.
