This article first summarizes the development history of large model technology, the iterative path of autonomous driving models, and the role of large models in the autonomous driving industry.
Next, it details the basic definition, fundamental functions, and key technologies of large models, especially the Transformer attention mechanism and the pre-training-fine-tuning paradigm.
The article also discusses the potential of large models in task adaptability, model transformation, and application prospects.
In the section on autonomous driving technology, it reviews in detail the technological iterative path from CNN to RNN, GAN, and then to the combination of BEV and Transformer, as well as the application of occupancy network models.
Finally, the article focuses on how large models empower the perception, prediction, and decision-making layers in autonomous driving, highlighting their importance and influence in this field.
1.1 Development History of Large Model Technology
Large models generally refer to deep learning models with billions or even hundreds of billions of parameters, and large language models are a typical branch of large models (represented by ChatGPT).
The introduction of the Transformer architecture brought in the attention mechanism, breaking through the inherent limitations of RNNs and CNNs in processing long sequences, allowing language models to gain rich linguistic knowledge pre-training on large-scale corpora:
-
On one hand, it opened a new era of rapid development for large language models;
-
On the other hand, it laid the foundation for the realization of large model technology, providing a reference for enhancing model performance in other fields by increasing the number of parameters.
The complexity, high dimensionality, diversity, and personalization requirements make large models more likely to achieve outstanding modeling capabilities in autonomous driving, quantitative trading, medical diagnosis, image analysis, natural language processing, and intelligent dialogue tasks.
1.2 Iterative Path of Autonomous Driving Models
Autonomous driving algorithm modules can be divided into three stages: perception, decision-making, and planning control. Among them, the perception module is a key component that has undergone diverse model iterations:
CNN (2011-2016) — RNN+GAN (2016-2018) — BEV (2018-2020) — Transformer+BEV (2020 to present) — Occupancy Network (2022 to present)
We can take a look at Tesla’s intelligent driving iterative history:
In 2020, the autonomous driving algorithm was restructured, introducing BEV+Transformer to replace the traditional 2D+CNN algorithm, and feature-level fusion replaced post-fusion, with automatic annotation replacing manual annotation.
1.3 Empowerment and Impact of Large Models on the Autonomous Driving Industry
The development of large models in the field of autonomous driving has lagged behind large language models, starting around 2019, drawing on the successful experiences of models like GPT.
The application of large models accelerates the maturity of model endpoints, providing clearer expectations for the landing of L3/L4 level autonomous driving technology.We can look at the prospects for the landing of L3 and above level autonomous driving from four aspects: cost, technology, regulation, and safety, among which:
-
There is still room for cost reduction.
-
The development of technology will continue along two main lines: algorithms and hardware.
-
Regulatory policies are still being gradually improved.
-
Safety has become an essential factor for the commercialization of autonomous vehicles.
Since 2021, major manufacturers have accelerated their layout for L2+ autonomous driving, and it is expected that around 2024, they will achieve L2++ (close to L3) or higher-level autonomous driving functions, with policies expected to become a major catalyst.
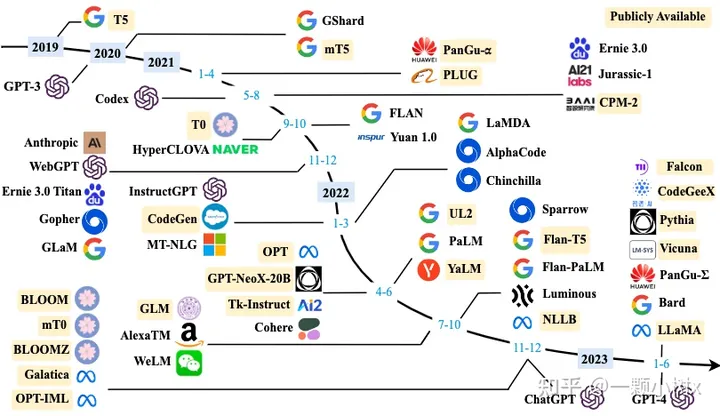
▍Development History of Large Model Technology
2.1 Basic Definition and Fundamental Functions of Large Models
The basic definition of large models: from large language models to ubiquitous large models, large models mainly refer to deep learning models with billions or even hundreds of billions of parameters, with large language models (like the recently popular ChatGPT) being quite representative.
Large language models are a type of deep learning algorithm that can use very large datasets to recognize, summarize, translate, predict, and generate content.
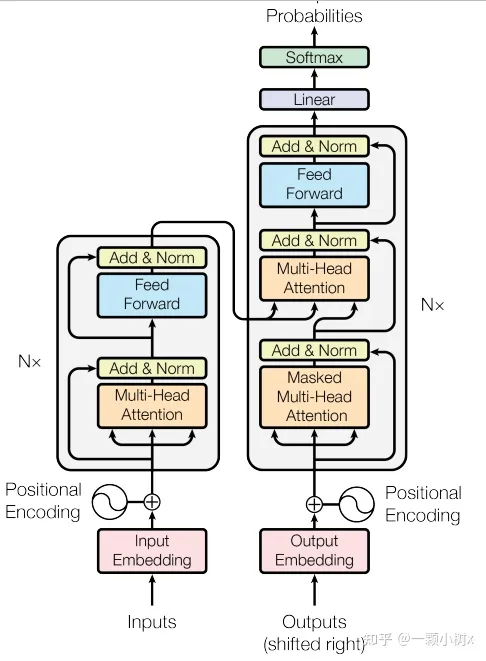
Large language models largely represent a class of deep learning architectures called Transformer networks. The Transformer model is a neural network that learns context and meaning by tracking relationships in sequential data (such as words in this sentence).
The introduction of the Transformer architecture opened a new era of rapid development for large language models:
The following image depicts the development history of large models:
2.2 The Foundation of Large Models — Transformer Attention Mechanism
Attention Mechanism: The Core Innovation of Transformer
Innovation Point 1:The biggest innovation of the Transformer model is the introduction of the attention mechanism, which greatly improves the model’s ability to learn long-distance dependencies, breaking through the limitations of traditional RNNs and CNNs in processing long-sequence data.
Innovation Point 2:Before the emergence of the Transformer, natural language processing generally used RNNs or CNNs to model semantic information. However, both RNNs and CNNs face difficulties in learning long-distance dependencies:
-
The sequential processing structure of RNNs causes information from earlier moments to decay over time;
-
While the local perception of CNNs also limits their ability to capture global semantic information.
-
This makes RNNs and CNNs often struggle to learn long-distance dependencies between words when processing long sequences.
Innovation Point 3:The Transformer attention mechanism breaks through the inherent limitations of RNNs and CNNs in processing long sequences, allowing language models to gain rich linguistic knowledge pre-training on large-scale corpora. This modular and scalable model structure also facilitates expanding the model size and expressive power by increasing the number of modules, providing a feasible path for achieving ultra-large parameter counts.
The Transformer solves the long sequence processing difficulties of traditional models and provides an infinitely expandable structure, laying a dual foundation for the realization of large model technology.
The following is a diagram of the Transformer structure:
2.3 Pre-training-Fine-tuning Paradigm of Large Models
Large models represent a new pre-training-fine-tuning paradigm, where the core is to pre-train a very large parameter model using a large-scale dataset, and then fine-tune it for specific tasks.
This contrasts with traditional single-task training, marking a significant methodological change.
The exponential growth in the number of parameters is the most fundamental characteristic of large models, developing from the millions of parameters in early models to the billions and even hundreds of billions of parameters today, achieving breakthroughs in scale compared to previous generations.
The introduction of the Transformer architecture has opened a new era in NLP model design, introducing self-attention mechanisms and parallel computing concepts, significantly enhancing the model’s ability to handle long-distance dependencies, laying the groundwork for the subsequent development of large models.
It is precisely due to the success of the Transformer architecture that researchers have realized the crucial role of model architecture design in handling complex tasks and large-scale data. This awareness has sparked further interest among researchers in increasing the number of model parameters. Although there have been attempts to increase the parameter count before, they were limited by the memory and other capabilities of the models at the time, resulting in minimal improvements in model performance after increasing the parameter count.
The success of GPT-3 fully validates that a moderate increase in parameter count can significantly enhance the model’s generalization ability and adaptability, thus igniting a research boom in large models.
With over a hundred billion parameters and powerful language generation capabilities, GPT-3 has become a paradigm of parameterized models. It performs remarkably well on many NLP tasks, even achieving impressive results in few-shot or zero-shot learning.
The advantages of increasing parameter count include:
-
Better representation ability: Increasing the parameter count allows the model to learn complex relationships and patterns in the data better, thus improving its representation ability and performance on different tasks.
-
Generalization ability and transfer learning: Large models can transfer knowledge learned from one domain to another, achieving better transfer learning results, which is especially valuable for tasks with scarce data.
-
Zero-shot learning: Increasing the parameter count allows the model to better utilize existing knowledge and patterns, thus achieving better results in zero-shot learning, even with very few examples.
-
Innovation and exploration: The powerful capabilities of large models can help conduct more innovative experiments and explorations, uncovering more hidden information in the data.
2.4 Exploring Large Models: Task Adaptability, Model Transformation, and Application Prospects
Compared to early artificial intelligence models, large models have achieved a qualitative leap in parameter count, leading to an overall improvement in modeling capabilities for complex tasks:
1) Enhanced learning ability: to tackle more complex tasks;
2) Strengthened generalization ability: to achieve broader applicability;
3) Improved robustness;
4) Higher-level cognitive interaction ability: capable of simulating certain human abilities, etc.
The complexity, high dimensionality, diversity, and personalization requirements make large models more likely to achieve outstanding modeling capabilities in certain tasks:
-
Multi-modal sensor data fusion analysis, especially involving the processing of temporal data, such as in autonomous driving;
-
Complex and dynamic targets require models to learn from large-scale diverse data patterns, such as optimizing quantitative trading strategies in the financial sector;
-
High-dimensional input spaces involving heterogeneous data sources, such as medical images and reports;
-
Customization needs for personalized modeling for different users or scenarios, such as intelligent assistants;
▍Iterative Path of Autonomous Driving Technology
3.1 Overview of Core Modules in Autonomous Driving Algorithms
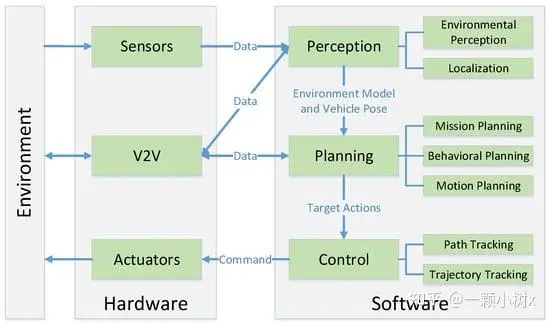
Autonomous driving algorithm modules can be divided into three stages: perception, decision-making, and planning control, where the perception module is a key component.
Perception Module:The perception module is responsible for analyzing and understanding the traffic environment around the autonomous driving vehicle, which is the foundation and prerequisite for achieving autonomous driving. The accuracy of the perception module directly affects and restricts the overall safety and reliability of the autonomous driving system.
The perception module mainly obtains input data through various sensors such as cameras, LiDAR, and millimeter-wave radar, and then accurately analyzes road markings, other vehicles, pedestrians, traffic lights, road signs, and other scene elements using deep learning and other algorithms for subsequent processes.
Decision-making and Planning Control:Compared to the perception module, the roles of decision-making and planning control modules are more singular and passive.
These modules primarily generate driving strategies based on the environmental understanding results outputted by the perception module, planning the vehicle’s motion trajectory and speed in real time, and ultimately converting these into control commands to achieve autonomous driving.
However, large models mainly empower the perception and prediction stages at the vehicle end, gradually penetrating into the decision-making layer.
3.2 CNN
2011-2016: CNN Triggered the First Wave of Innovation in the Autonomous Driving Field
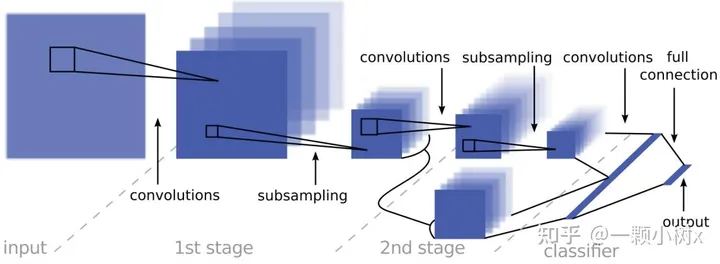
With the enhancement of deep learning and computing capabilities, Convolutional Neural Networks (CNNs) have triggered the first wave of innovation in the autonomous driving field through their outstanding performance in image recognition tasks.
This is a two-stage convolutional neural network architecture, where the input is processed through two convolutional and subsampling stages, ultimately classified by a linear classifier.
CNN Greatly Enhanced the Environmental Perception Ability of Autonomous Driving Vehicles
-
On one hand, CNN’s excellent performance in image recognition and processing enables vehicles to accurately analyze roads, traffic signs, pedestrians, and other vehicles;
-
On the other hand, the ability of CNNs to effectively process data from various sensors achieves the fusion of image, LiDAR, and other data, providing comprehensive environmental cognition. Coupled with improved computational efficiency, CNN models further gained the ability to perform complex perception and decision-making in real time.
However, CNN-based autonomous driving also has certain limitations:
-
1) Requires a large amount of labeled driving data for training, which is challenging to obtain sufficiently diverse data;
-
2) Generalization performance needs improvement;
-
3) Robustness also needs to withstand more complex environments;
-
4) Temporal task processing capability: RNNs and other models may have an advantage in this regard.
3.3 RNN, GAN
2016-2018: RNNs and GANs Were Widely Applied to Autonomous Driving Related Research, Driving Rapid Development During This Period
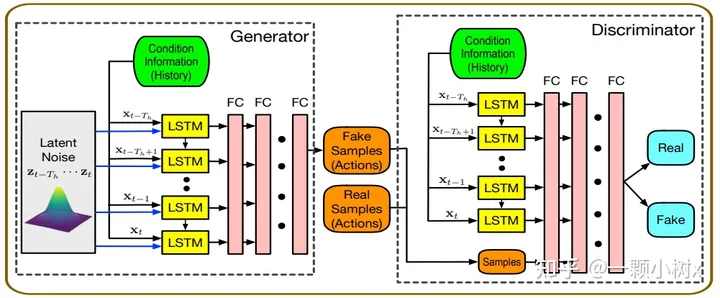
RNNs are more suitable than CNNs for processing time series data: the recurrent structure of RNNs can model dynamic changes over time, which is very useful for handling temporal tasks such as trajectory prediction and behavior analysis in autonomous driving. For instance, in fields like target tracking and multi-agent interaction modeling, RNNs and LSTMs (improved versions of RNNs) have brought about significant breakthroughs, predicting the future motion trajectories of vehicles and providing support for decision-making and planning.
GANs’ generative capabilities alleviate the issue of insufficient training data for autonomous driving systems: GANs can learn complex distributions and generate high-quality synthetic data, bringing new ideas to the autonomous driving field to alleviate the problem of insufficient training data for autonomous driving systems. For example, GANs can generate simulated sensor data and scene information, test the robustness of autonomous driving algorithms, and can also be used for interactive scene generation.
RNN+GAN can achieve end-to-end behavior prediction and motion planning: RNNs are responsible for temporal modeling, while GANs handle data generation, and the two work together to provide more comprehensive and reliable environmental perception, state prediction, and decision support for autonomous driving systems.
This is an example of a model architecture that integrates LSTM and GAN.
Unresolved issues with RNNs and GANs:
-
RNN-type models: Long-term temporal modeling capability is still relatively weak, especially when dealing with longer time series data, which may encounter issues like gradient vanishing or explosion, limiting their application effectiveness in certain autonomous driving tasks.
-
GAN models: The quality of generated data is difficult to control and often fails to reach a sufficiently realistic level. Furthermore, although GANs can generate synthetic data, their specific applications in the field of autonomous driving remain relatively limited.
-
Low sample efficiency: RNNs and GANs still have low sample efficiency, often requiring a large amount of real scene data for training and optimization. Additionally, these models are difficult to interpret, lacking a clear explanation of their internal decision-making processes, and issues of model stability and reliability also need to be addressed further.
The reasons for the cooling application of RNNs and GANs in the autonomous driving field include:
-
Efficiency and real-time requirements: Autonomous driving systems need to make decisions and control under high real-time demands. Traditional RNNs face issues with low computational efficiency when processing sequential data, limiting their ability to handle real-time perception and decision-making tasks.
-
Complexity and generalization ability: Autonomous driving involves complex and variable traffic scenarios and environments, requiring strong generalization abilities. However, traditional RNNs may encounter difficulties when handling complex temporal data, making it hard to adapt to various traffic situations.
-
Emergence of new technologies: With the development of deep learning, new model architectures and algorithms are continuously emerging, such as the Transformer architecture and reinforcement learning, which may be more efficient and applicable in handling perception, decision-making, and planning tasks.
3.4 BEV
2018-2020: Models Based on Bird’s Eye View (BEV) Gained Extensive Research and Application in the Autonomous Driving Field
The core idea of the BEV model is to project the three-dimensional environmental data around the vehicle (such as point clouds and images from LiDAR and cameras) onto a top-down plane to generate a two-dimensional bird’s eye view. This method of “flattening” three-dimensional information into a two-dimensional representation brings significant advantages for the environmental perception and understanding of autonomous driving systems:
-
The bird’s eye view provides a more intuitive and information-rich environmental representation than direct raw sensor data, allowing for clearer observation of the positions and relationships of road, vehicles, pedestrians, signs, and other elements, enhancing the autonomous driving system’s perception of complex environments.
-
The global top-down perspective is more conducive to path planning and obstacle avoidance systems for decision-making, allowing for more reasonable and stable path planning based on road and traffic conditions.
-
BEV models can unify the input data from different sensors into a shared representation, providing the system with more consistent and comprehensive environmental information.
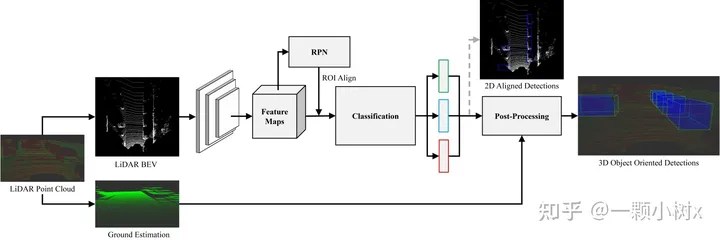
This is the BirdNet 3D object detection framework, where the three outputs of the network are: category (green), 2D bounding box (blue), and yaw angle (red).
However, the BEV model also faces several urgent issues that need to be resolved:
-
Generating BEV representations from original three-dimensional data requires significant coordinate transformations and data processing, increasing computational load and hardware requirements.
-
Information loss is an issue; projecting three-dimensional information onto two dimensions inevitably loses some details, such as occlusion relationships.
-
The conversion from different sensors to the BEV coordinate system also requires complex calibration.
-
Research is needed on how to effectively fuse various heterogeneous data sources to generate more accurate and complete BEV representations.
3.5 Transformer+BEV
Since 2020, the combination of Transformer+BEV has become an important consensus in the field of autonomous driving, pushing the technology into a new development stage.
The method of combining the Transformer model with BEV (bird’s eye view) representation is becoming an important consensus in the field of autonomous driving, driving the realization of fully autonomous driving.
-
On one hand, BEV can efficiently express the rich spatial information around the autonomous driving system;
-
On the other hand, Transformers exhibit unique advantages in processing sequential data and complex contextual relationships, having been successfully applied in fields like natural language processing. The combination of both can fully utilize the environmental spatial information provided by BEV and the capabilities of Transformers in modeling multi-source heterogeneous data, achieving more precise environmental perception, longer-term motion planning, and more globalized decision-making.
Tesla was the first to introduce the BEV+Transformer large model. Compared to traditional 2D+CNN small models, the advantages of large models mainly include:
-
1) Enhanced perception capability: BEV integrates multi-modal data from LiDAR, radar, and cameras on the same plane, providing a global perspective and eliminating occlusion and overlap issues between data, improving object detection and tracking accuracy;
-
2) Improved generalization ability: The Transformer model extracts feature functions and uses the attention mechanism to find the intrinsic relationships of things, enabling intelligent driving to learn to summarize and generalize rather than mechanically learning. Mainstream automakers and autonomous driving companies have already laid out BEV+Transformer, making large models the mainstream trend in autonomous driving algorithms.
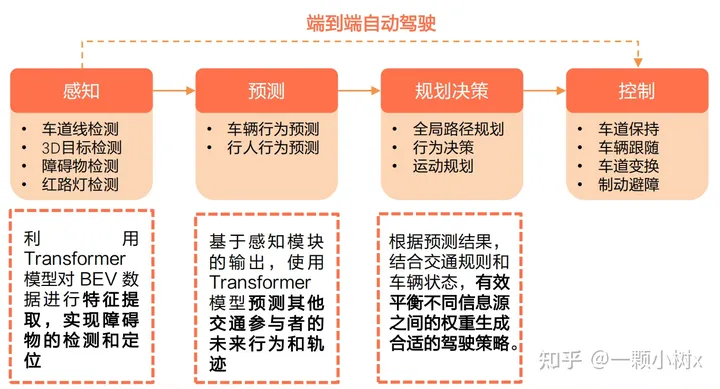
The following is a sample framework diagram of Transformer+BEV:
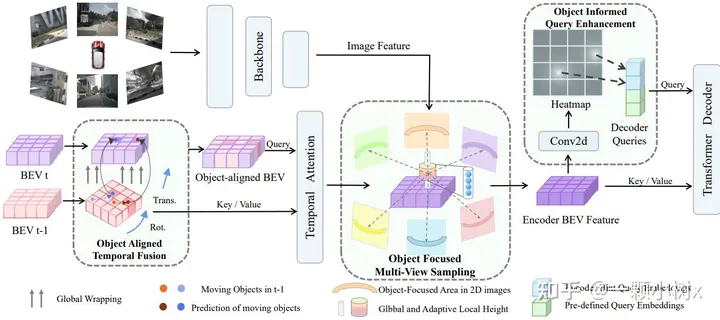
(a) Object Alignment Temporal Fusion: First, based on the vehicle’s own movement, the current bird’s eye view map at time t is deformed and adjusted to resemble the previous moment (t-1). This allows for predicting the current position of objects based on their previous positions combined with speed, thus achieving fusion of objects on the map at different times.
(b) Object-Focused Multi-View Sampling: First, some points are pre-set in three-dimensional space, and these points are then projected onto the features of the image. This allows for sampling across the entire height range and adaptively focusing on certain major objects, sampling more points in their local spatial areas.
(c) Object Notification Query Enhancement: After the encoder processes image features, supervision information from heat maps is added. At the same time, points corresponding to the detected high-confidence positions of objects are used to replace some of the originally preset query points.
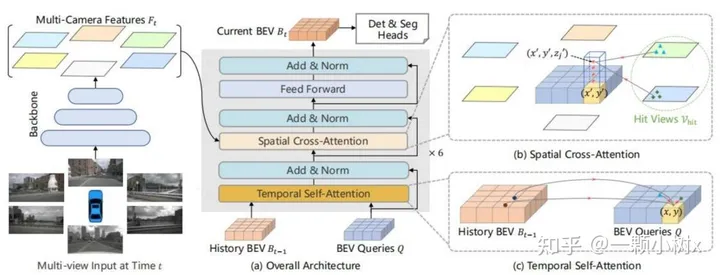
The following is another example framework diagram of Transformer+BEV:
The emergence of GPT has had a significant impact on the development of the Transformer+BEV model.
-
The success of GPT demonstrates the potential of Transformer models, prompting more researchers to apply Transformers in computer vision and autonomous driving, leading to innovative practices of Transformer+BEV.
-
The pre-training ideas of GPT provide references for pre-training and transfer learning in Transformer+BEV, capturing semantic information through pre-training and then applying it.
-
OpenAI’s public code and models have also accelerated the research progress of Transformer-like models in various fields.
The current attention on the Transformer+BEV model is mainly based on its integration of the advantages of both Transformers and BEV:
-
Transformers excel at processing sequential data and capturing semantic information, while BEV provides an overall view of the scene, facilitating the analysis of spatial relationships. The combination of both achieves complementarity, enhancing the understanding and expression of complex scenes.
-
The accumulation of autonomous driving data lays the foundation for training large models. Big data supports the learning of more complex features, improving environmental perception accuracy and making end-to-end learning possible.
-
Enhancing safety and generalization ability remains a core challenge in autonomous driving. At the current stage, Transformer+BEV effectively combines semantic understanding and multi-view modeling, capable of handling relatively uncommon, complex, or challenging traffic scenes or environments, showing great potential.
3.6 Occupancy Network Model
In 2022, the occupancy network model was used in autonomous driving systems, achieving efficient modeling of road scenes.
-
The occupancy network is a technology applied by Tesla in autonomous driving perception in 2022. Compared to BEV, it can more accurately restore the 3D environment around the autonomous driving vehicle, enhancing the vehicle’s environmental perception capabilities.
-
The occupancy network consists of two parts: an encoder that learns rich semantic features and a decoder that can generate three-dimensional scene expressions.
-
Tesla uses a large amount of driving data collected by onboard cameras to train the occupancy network model. The decoder can restore and imagine various scenes, enhancing robustness in abnormal situations.
-
The occupancy network technology allows Tesla to fully utilize unlabeled data, effectively supplementing the lack of labeled datasets. This is significant for improving the safety of autonomous driving and reducing traffic accidents. Tesla is continuously improving the integration of this technology in its autonomous driving system.
Tesla publicly unveiled the occupancy network model at the 2023 AI Day, based on learning for 3D reconstruction, aiming to restore the 3D environment around autonomous driving vehicles more accurately, representing an elevation of the BEV view:
-
BEV+Transformer’s limitations: The bird’s eye view is a 2D image, which inevitably loses some spatial height information, failing to accurately reflect the actual occupied volume of objects in 3D space. Therefore, BEV focuses more on stationary objects (such as curbs, lane markings, etc.), while recognizing spatial targets (such as the 3D structure of objects) is challenging.
-
Occupancy networks: Existing three-dimensional representation methods (voxel, mesh, point cloud) are not ideal in terms of storage, structure, and suitability for learning, while occupancy networks represent three-dimensional surfaces as continuous decision boundaries of deep neural network classifiers based on learning, enabling 3D environment reconstruction without point cloud data from LiDAR, and better integrating perceived 3D geometric information with semantic information compared to LiDAR, resulting in more accurate three-dimensional scene information.
 Huawei’s ADS 2.0 further upgrades the GOD network, enhancing road topology reasoning networks, similar to Tesla’s occupancy network.
Huawei’s ADS 2.0 further upgrades the GOD network, enhancing road topology reasoning networks, similar to Tesla’s occupancy network.
-
GOD 2.0 (General Obstacle Detection) has no upper limit for obstacle recognition, achieving a recognition rate of 99.9%;
-
RCR2.0 can recognize more roads, with a perception area reaching 2.5 football fields, and real-time generation of road topology.
-
In December 2023, the AITO New M7 equipped with ADS 2.0 will achieve high-level intelligent driving without high-precision maps nationwide.
Comparing the effects of BEV, the following is the BEV bird’s eye view:
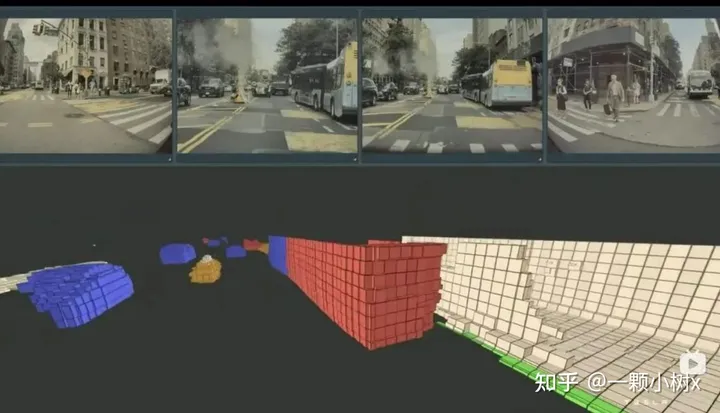
The following is the 3D view of the occupancy network:
▍Empowerment of Large Models in the Autonomous Driving Industry
4.1 Large Models in Autonomous Driving
Large models, represented by GPT, typically contain hundreds of millions or even billions of parameters, employing Transformer structures for distributed training to enhance model capabilities.
The success of GPT has inspired autonomous driving researchers to utilize similar architectures for end-to-end learning, even leading to the emergence of pre-trained models specifically designed for autonomous driving. These efforts bring new ideas to the autonomous driving industry, enhancing the safety, efficiency, and user experience of autonomous driving systems through powerful data analysis and pattern recognition capabilities, achieving more accurate environmental perception and intelligent decision-making.
The application of large models accelerates the maturity of model endpoints, providing clearer expectations for the landing of L3/L4 level autonomous driving technology.
The maturity of models makes autonomous driving systems more stable and reliable, laying the foundation for commercial applications. With the rapid development of deep learning and neural network technologies, models have made significant progress in perception, decision-making, and control, progressing towards efficiently processing large amounts of sensor data, accurately recognizing traffic signs, pedestrians, vehicles, etc., and achieving environmental perception. Furthermore, models can assist in real-time path planning and decision-making, allowing vehicles to safely navigate complex traffic environments.
The application of large models provides clearer expectations for the landing of L3/L4 level autonomous driving technology, especially Tesla’s explorations in cutting-edge technology, which are becoming a barometer for achieving L3/L4 level autonomous driving. The algorithm of Transformer+BEV+occupancy network proposed by Tesla enables vehicles to understand complex traffic environments more accurately, providing stronger environmental perception capabilities for L3/L4 level autonomous driving systems, thus enabling more confident navigation in specific scenarios like urban roads and highways.
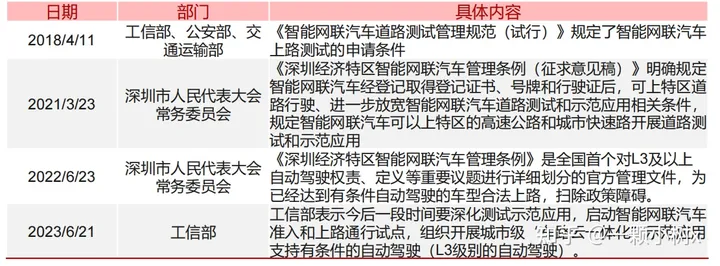
Excerpt from important autonomous driving policies in China
Safety is an essential factor for the commercialization of autonomous vehicles.
To ensure the safety and reliability of autonomous driving systems, according to national regulatory requirements, autonomous vehicles must undergo training and evaluation on closed courses for over 5000 kilometers, and test drivers must undergo no less than 50 hours of training and pass vehicle safety technical inspections before applying for road testing qualifications. Currently, the total mileage of intelligent connected vehicles in road testing in China has exceeded 70 million kilometers. We expect that it will still take some time for L3 and above autonomous vehicles to open personal use road trial areas.
Automotive communication safety and data security must also meet national standards or relevant regulations. We expect that in the future, China will refer to the practices of European and American countries to further refine safety requirements and strengthen the construction of related regulatory systems, such as formulating safety assessment standards for autonomous vehicles, clarifying safety assurance requirements at each stage of the autonomous vehicle development lifecycle, and establishing mechanisms for determining responsibility in autonomous vehicle accidents.
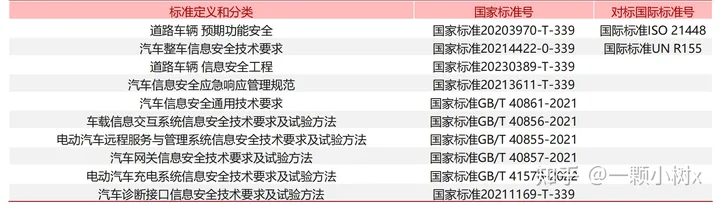
Some safety standards for autonomous vehicles
4.2 Vehicle-End Empowerment Mainly Acts on Perception and Prediction Stages, Gradually Penetrating into Decision-Making Layer
The application of large models in autonomous driving can be simply described as transmitting the data collected by the entire vehicle back to the cloud, where the large model deployed in the cloud trains the data accordingly.
The primary role of large models in autonomous driving is in the perception and prediction stages.
In the future, the generation of driving strategies will gradually shift from rule-driven to data-driven. There are two ways to generate driving strategies in the planning decision layer:
1) Based on data-driven deep learning algorithms;
2) Based on rule-driven (for safety reasons, rule-based generation of driving strategies is currently commonly adopted, but as the level of autonomous driving increases and application scenarios continue to expand, rule-based algorithms have many limitations in handling corner cases).
Combining vehicle dynamics, the Transformer model can generate suitable driving strategies:
By integrating data from dynamic environments, road conditions, vehicle status, etc., the multi-head attention mechanism of the Transformer effectively balances the weights between different information sources to make reasonable decisions quickly in complex environments.
Author | Zhihu @ A Small Tree x