
Abstract This article establishes a data-driven model for predicting f-CaO in clinker using a fully connected neural network based on the TensorFlow+Keras deep learning framework. The model is trained with the Nadam optimizer, showing better robustness compared to SGD (Stochastic Gradient Descent). Furthermore, this article introduces the implementation method for real-time prediction of f-CaO content in cement clinker, achieving a prediction error of less than 5.11%, which can effectively guide the optimization control system for calcination and provide data support for the intelligent control of calcination.
In modern dry-process cement production lines, the f-CaO content is an important control indicator for measuring the quality of cement clinker. The level of f-CaO not only affects the stability of the cement produced but also relates to the energy consumption indicators during the cement production process. Currently, most domestic production lines use offline methods for detecting f-CaO content in clinker, where laboratory analysis is performed every hour on sampled materials. Some new production lines, such as those in Wuhu and Hefei, have adopted online detection of f-CaO content in clinker, with sampling devices installed at the kiln discharge point, sending samples to the laboratory’s analyzer through a conveyor system, with a sampling interval of once per hour.
The cement calcination process is complex, with many parameters affecting the f-CaO content of clinker, and there are non-linear and time-varying delays between these parameters and the f-CaO content. Additionally, due to the long sampling cycle, the prediction of f-CaO content must consider the impacts of time variation and time delay. Early f-CaO predictions were mostly based on the MatLab platform using BP neural networks, with gradient descent optimization algorithms for model training. In recent years, with advancements in deep learning technology, convolutional neural networks and other algorithms have been used for f-CaO model training.

To address the issues in measuring f-CaO content in clinker, this article applies a fully connected neural network with the Nadam optimizer for f-CaO content prediction. The fully connected neural network features both forward and backward propagation. In forward propagation, each layer computes the network output through linear calculations and activation functions, while in backward propagation, optimization algorithms are used to update model parameters. Compared to BP networks that use gradient descent (SGD) for model parameter updates, which can lead to issues such as gradient explosion or vanishing (where the gradient function experiences exponential increases or decreases) and local optima, as well as loss of valuable feature information in pooling layers of convolutional neural networks (CNNs), this article utilizes the Relu activation function and Nadam optimization algorithm to effectively resolve these issues. The article provides the loss values of the algorithm and some prediction analyses, achieving real-time prediction of f-CaO and providing data support for the optimization control system of calcination.
1. TensorFlow and Keras Deep Learning Framework
TensorFlow is an open-source machine learning framework based on data flow graphs developed by Google, supporting Python and C++ languages. It is widely used in image classification, object detection, model prediction, and other fields.
Keras is a deep learning library based on TensorFlow and Theano, consisting of a high-level neural network API written in Python. Using Keras allows for rapid implementation of a re-encapsulation of TensorFlow, significantly reducing the amount of code required to implement deep learning purely using TensorFlow.
The environment used in this article includes Anaconda and PyCharm, with a Python 3.7 virtual environment configured in Anaconda for PyCharm to use, and TensorFlow version 2.3.0.
PyCharm is a Python IDE created by JetBrains, and this article uses PyCharm 2020.3. The environment settings are shown in Figure 1.

Figure 1: Python Virtual Environment
2. Feature Parameter Selection and Data Preprocessing
In the calcination process of pre-decomposed kiln clinker, the reasonable matching of air, coal, material, and kiln speed is crucial. When the amount of raw material feeding is fixed, if the coal feeding amount is too high, the clinker granules become larger and yellow heart material appears, resulting in lower f-CaO content; if the coal feeding amount is too low, the clinker granules become smaller, leading to higher f-CaO content. With fixed raw material feeding and coal consumption, if the tertiary air volume is too high, the air volume in the kiln decreases, which can lead to post-combustion in the kiln, resulting in a high reducing atmosphere and higher f-CaO content; if the tertiary air volume is too low, the air volume in the decomposition furnace is insufficient, increasing the air volume in the kiln, leading to higher secondary and tertiary air temperatures, smaller clinker granules, and higher f-CaO content. With fixed air, coal, and material, if the kiln speed is too fast, the material’s residence time in the firing zone shortens, leading to incomplete burning absorption and higher f-CaO content; if the kiln speed is too slow, the material accumulates too thickly in the kiln, resulting in poor heat exchange and incomplete pre-burning, also leading to higher f-CaO content.
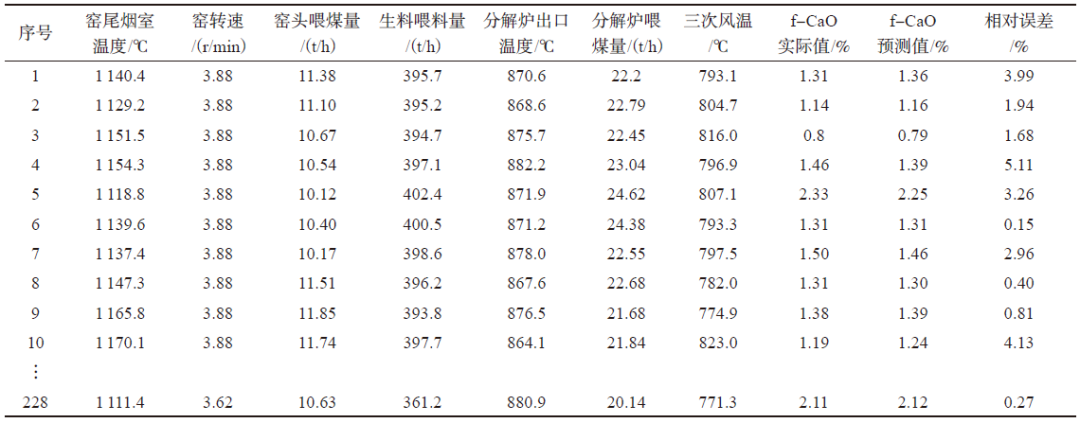
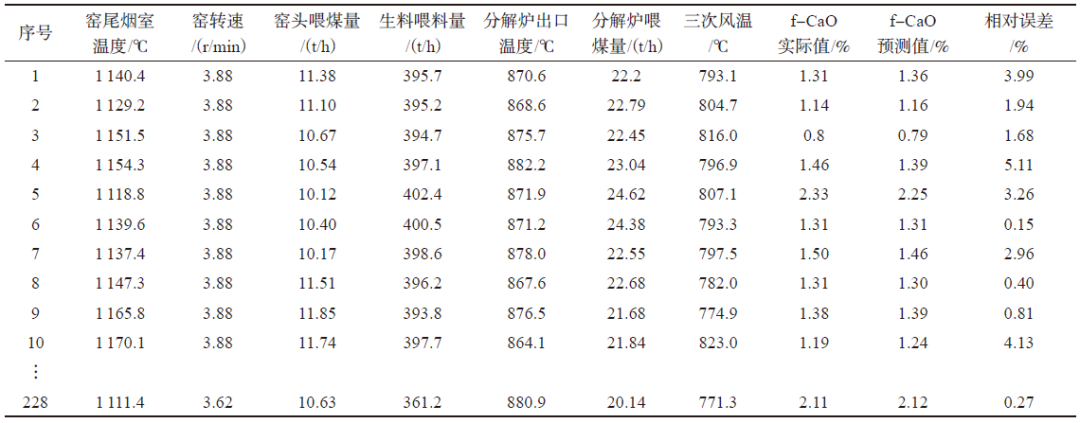
Sample data includes 254 groups of data from a certain factory over four months, with some data shown in Table 1.
Table 1: Sample Raw Data

The model selects seven parameters as feature parameters for model identification: kiln tail flue gas temperature, kiln rotation speed, coal feeding amount at the kiln head, raw material feeding amount, coal feeding amount in the decomposition furnace, decomposition furnace outlet temperature, and tertiary air temperature.

Data preprocessing mainly includes error handling and data transformation. Since the sample data has different engineering units and varies greatly in numerical value, directly using these untransformed (normalized) raw data can easily lead to increased computational errors and uncertainties, affecting learning speed and accuracy. To accelerate the learning speed and model accuracy of the neural network, the sample data must undergo normalization processing before being input as training samples. Normalization uses the MinMaxScaler function from sklearn for normalization within the range [0, 1]. It is important to note that during practical application, it has been found that data normalization is crucial in deep learning, directly affecting model accuracy and should not be overlooked.
The calculation formula is as follows:
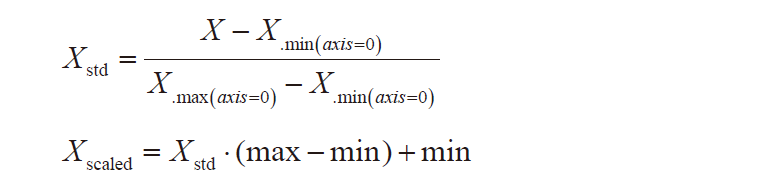
The data after normalization is shown in Table 2.
Table 2: Normalized Data

3. Neural Network Model Training and Prediction
The Momentum algorithm computes the exponential weighted average of gradients and uses this value to update parameter values, effectively solving local optimum problems (such as saddle point issues).
The RMSProp (Root Mean Square Prop) algorithm introduces squares and square roots on the basis of the exponential weighted average of gradients, helping to reduce oscillation on the path to the minimum value and allowing for a larger learning rate, thereby accelerating the algorithm’s learning speed.

Adam is a first-order optimization algorithm that can replace traditional stochastic gradient descent processes. It iteratively updates the neural network weights based on training data and can be seen as a modified version of Momentum + RMSProp. Compared to traditional SGD, Adam shows better robustness concerning hyperparameters.
Nadam is similar to Adam with a Nesterov momentum term. The formula is as follows:
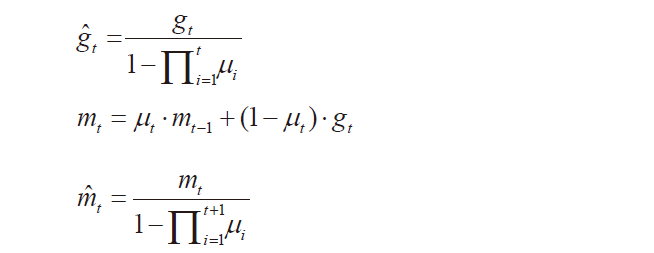
Generally, where you want to use RMSprop with momentum or Adam, you can often achieve better results using Nadam. It effectively resolves issues such as gradient explosion or vanishing (where the gradient function experiences exponential increases or decreases) and local optima problems that arise from using gradient descent (SGD) for model parameter updates, as well as loss of valuable feature information in pooling layers of convolutional neural networks (CNNs).
The f-CaO fully connected neural network model based on the Nadam optimizer includes an input layer (7 nodes), hidden layer 1 (256 nodes), BN layer, hidden layer 2 (256 nodes), BN layer, hidden layer 3 (256 nodes), DropOut (32 nodes), and output layer (1 node). The hidden layers use Relu as the activation function, and the output layer uses Linear as the activation function. The model loss function adopts mse (mean squared error), with the learning rate set to 0.001 and the number of iterations set to 4,000.
90% of the dataset is used for training, and 10% is used for testing. The training results are shown in Figure 2, and the prediction curve is shown in Figure 3.
The model’s loss (mean squared error) is: training set = 0.0036, testing set = 0.0156.

This data-driven model training algorithm does not require special preconditions. If there are changes in raw materials or significant fluctuations in operating conditions, the data already included in the training set has completed model training, making the model applicable to these situations. Therefore, during usage, it is essential to maintain the model dataset and optimize the model updates.
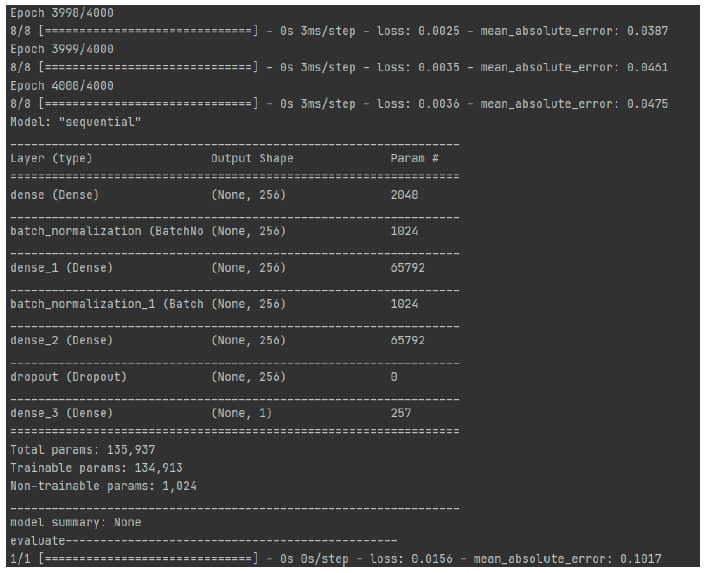
Figure 2: Model Training Results
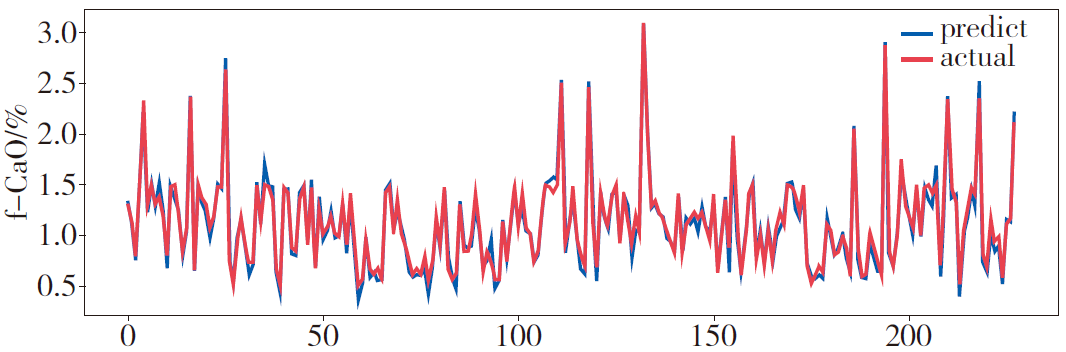
Figure 3: Prediction Curve Based on Nadam Optimizer
Real-time data can be collected from the DCS system through the OPC UA communication protocol. The following Python statement can achieve real-time prediction of f-CaO and send the predicted value to the calcination optimization control system via the OPC UA communication protocol:
predict_out = model.predict(x_test)
Data prediction analysis is shown in Table 3, with relative errors ranging from 0.15% to 5.11%.
 Table 3: Partial Prediction Analysis
Table 3: Partial Prediction Analysis
This algorithm has been implemented in the calcination optimization control of a certain cement factory’s 5,000 t/d clinker production line and applied in the Hefei Institute’s mechanism model microservice platform to provide model training services for enterprises.
4. Conclusion
This article establishes a data-driven model for predicting f-CaO in clinker using a fully connected neural network based on the TensorFlow+Keras deep learning framework, trained with the Nadam optimizer. The model is used for real-time prediction of f-CaO content in cement clinker, achieving a prediction error of less than 5.11%, effectively guiding the operation of the calcination optimization control system and providing data support for the cement calcination optimization system.


Author Unit: Hefei Cement Research and Design Institute Co., Ltd.

Recommended Reading
1.[Xi’an | April 19-21] 2023 Cement Industry Calcination and Environmental Protection Technology Exchange Conference
2.Top 10 Benefits of Enterprises Participating in Standard Formulation
3. Notice on the Acceptance of National Promotion Project “General Portland Cement Low Carbon Product Certification”
4.Welcome to Publish Advertisements in the 2023 “Cement” Magazine
5. Intelligent Upgrade and Transformation of Roller Press Technology (High Pressure Small Cycle) and Combined Grinding System
6.Technical Comic | Hydraulic Double Sliding Rail Roller Press Feeding Device
7.Development and Application of Roller Press Double Curve Feeding Device
8.NOx Emission Reduction Technology and Review for Cement Kiln Flue Gas
9.Solution to the Belt Conveyor Belt Surface Cleaning Problem
10.Practice of Using Phosphogypsum-Industrial Molasses Composite for Base Layer Concrete with Retarding Cement
11.Research on the Impact of Waste Residue Formulation on the Pressure Steam Expansion Performance of High Magnesium Clinker
12.Discussion on the Co-disposal of Hazardous Waste in Cement Kilns
13.Practice of Effectively Controlling the Water Soluble Hexavalent Chromium Content in Cement by Adjusting Raw Material Composition
14.Analysis of Factors Affecting Gypsum Dehydration Efficiency in Cement Kiln Wet Desulfurization System
15.Analysis of Key Technologies for Ultra-Low Emission Transformation of Cement Kiln Bag Dust Collectors
16.Revisiting the Analysis and Calculation of Coupling Heating Expansion
17.Comparative Analysis of Common Feeding Devices for Roller Presses
18.Technical Upgrade of Roller Presses (Extrusion Effect is Key)
19.Transformation of Sealed Small Warehouse and Sealed Chain Plate Feeder for Raw Material Grinding
20.Application of Dry Desulfurization and SCR Denitration in Flue Gas Treatment of Magnesium-Calcium Brick Calcination
21. Discussion on the Collection and Purification (Emission Reduction) of CO2 in New Dry-Process Cement Kilns
22.Energy-saving Transformation of Preheater System to Reduce Resistance

