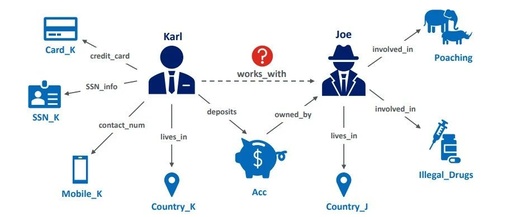

Knowledge graphs represent factual knowledge about the world through relationships between concepts, which are crucial for intelligent decision-making in enterprise applications. By encoding concepts and relationships as low-dimensional feature vectors, new knowledge can be inferred from existing facts in the knowledge graph. The most effective representation method for this task is called Knowledge Graph Embedding (KGE), which is learned through neural network architectures. Due to their impressive predictive performance, they are increasingly used in high-impact fields such as healthcare, finance, and education. However, is the use of black-box KGE models robust against adversarial attacks in high-risk domains? This paper argues that state-of-the-art KGE models are vulnerable to data poisoning attacks, where systematically perturbing the training knowledge graph reduces their predictive performance. To support this argument, two novel data poisoning attacks are proposed, which create input deletions or additions during training to degrade the performance of the learning model during inference. The goal of these attacks is to use knowledge graph embeddings to predict missing facts in the knowledge graph.
To address the issue of adversarial missing data leading to decreased model performance, model-agnostic instance attribution methods are proposed. These methods are used to identify the training instances that have the greatest impact on the KGE model’s predictions for the target instance. Influential triples are used for adversarial deletion. To poison the KGE model through adversarial addition, their inductive capacity is leveraged. The inductive capacity of KGE models is obtained through relational patterns such as symmetry, inversion, and composition in the knowledge graph. Specifically, to lower the model’s predictive confidence for the target fact, this paper proposes increasing the model’s predictive confidence for a set of bait facts. Therefore, adversarial additions are constructed that can enhance the model’s predictive confidence for bait facts through different relational reasoning patterns. Evaluation of the proposed adversarial attacks shows that they outperform state-of-the-art baselines on four KGE models across two publicly available datasets. Among the proposed methods, simpler attacks compete with or outperform those with high computational costs. The contribution of the paper not only highlights and provides an opportunity to fix the security vulnerabilities of KGE models but also aids in understanding the black-box predictive behavior of these models.
https://www.zhuanzhi.ai/paper/363a0ab471d644889cdf52f172e86fb2



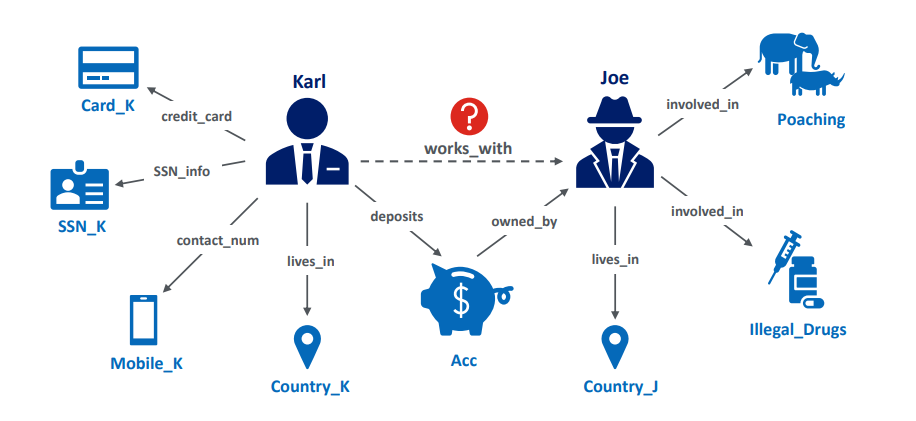
Similar to anti-money laundering applications in the financial sector, knowledge graphs are a universal representation of factual knowledge about interconnected entities and their relationships (Hogan et al., 2021). In recent years, multiple large-scale knowledge graphs have been developed to support intelligent decision-making across fields such as search engines, e-commerce, social networks, biomedicine, and finance. Commercial enterprises like Google and Microsoft have built web-scale knowledge graphs from textual resources on the internet to support Google Search and Bing. Similarly, Facebook and LinkedIn rely on graph representations of user knowledge to understand user preferences and recommend potential connections or job opportunities. Online vendors like Amazon and eBay also use enterprise knowledge graphs to encode user shopping behaviors and product information to improve product recommendations. Other companies such as Accenture, Deloitte, and Bloomberg have also deployed knowledge graphs in the financial services sector. These financial graphs provide robust support for applications such as enterprise search, financial data analysis, risk assessment, and fraud detection (Hogan et al., 2021; Noy et al., 2019).
More generally, in the field of natural language processing (NLP), injecting background knowledge represented by factual knowledge graphs supports knowledge-aware applications, such as knowledge-based question answering or explainable fact-checking in knowledge bases (Ji et al., 2022; Kotonya and Toni, 2020). Research on methods that combine structured knowledge representation with unstructured textual language representation is an emerging direction in this field. These methods seek to leverage factual and common-sense knowledge to enhance the contextual reasoning and understanding capabilities of NLP models (Malaviya et al., 2020; He et al., 2020; Zhang et al., 2022). Similarly, in the field of computer vision (CV), machine learning for tasks such as image classification, visual question answering, and skeleton-based action recognition is enhanced by representing relationships between objects in a scene or image as knowledge graphs (see Ma and Tang, 2021, Chapter 11). On the other hand, knowledge graphs have also emerged in new applications in healthcare and biomedical research. Here, biological networks are used to simulate connections and interactions among different protein structures, drugs, and diseases. Furthermore, integrating biomedical knowledge with patients’ electronic health records can facilitate comprehensive analysis of disease comorbidities, enabling personalized precision medicine (Rotmensch et al., 2017; Mohamed et al., 2020; Li et al., 2021; Bonner et al., 2022). Thus, knowledge graphs are the pillars of learning and reasoning in modern intelligent systems.
To integrate graph data into standard ML pipelines, symbolic graph structures need to be represented as differentiable feature vectors. The characteristics of traditional algorithm heuristics and domain engineering crafts are based on statistical graphs or the topological structure of nodes, or kernel methods (see Hamilton, 2020, Chapter 2). The inflexibility of feature engineering renders graphical representation learning algorithms, which learn to represent graph structures as low-dimensional continuous feature vectors, also known as embeddings. To learn the embeddings of entities, these algorithms aim to preserve the structural information of entities’ neighborhoods in the graph domain as similarity measures in the embedding domain. In this way, algebraic operations on entity embeddings reflect the graph structural interactions between these entities, allowing topological information from the graph to be utilized for various ML tasks. Deep learning-based neural network architectures are used to optimize the representations of entities and relationships in knowledge graphs so that the learned representations best support downstream ML tasks to be performed on the graph (Hamilton et al., 2017b; due to their effectiveness across different downstream tasks, graph representation learning algorithms have become the state-of-the-art methods for learning and reasoning with knowledge graphs (Chen et al., 2020; Nickel et al., 2016a).
The success of deep learning-based methods is attributed to their ability to extract rich statistical patterns from large amounts of input data. However, since they are data-driven, the learned models are opaque, and the reasons behind predictions are unknown. Due to this black-box predictive behavior, the failure modes of the models are also unknown. Existing research has shown that the predictions of deep learning models can be manipulated by altering their input data (Biggio and Roli, 2018; Joseph et al., 2019). This is particularly concerning in high-risk fields such as healthcare, finance, education, or law enforcement, where knowledge graph representation learning algorithms are increasingly used (Mohamed et al., 2020; Bonner et al., 2022). In these fields, decision outcomes can affect human lives, and the risk of model failure is very high. On the other hand, due to the high stakes, there are likely to be motivated adversarial participants who wish to manipulate model predictions. Moreover, knowledge graphs are often automatically extracted from textual sources on the internet or curated from user-generated content (Nickel et al., 2016a; Ji et al., 2022). This makes it easy for adversaries to inject carefully crafted false data into the graph. Therefore, deploying graph representation learning models in high-risk user-facing domains, good predictive performance of the models is not sufficient. Ensuring the safety and robustness of model usage is critical. However, establishing adversarially robust models requires methods to measure the adversarial robustness of the models. In other words, a necessary prerequisite for adversarially robust graph representation learning models is methods to identify the failure modes or security vulnerabilities of existing models.
The research in this paper is driven by the need to identify the adversarial vulnerabilities of black-box graph representation learning algorithms, which is a key step towards their responsible integration into high-risk user-facing applications.
Convenient access to knowledge
Convenient download, please followZhuanzhi WeChat account (click the blue button above to follow)
Reply “KGAR” in the background to getthe download link for Adversarial Robustness in Knowledge Graph Representation Learning from Zhuanzhi