
1. Intuitive Understanding of Attention
Imagine a scenario where you are driving (driving for real! The kind where you hold the steering wheel! Not the other kind of driving!), and it starts to rain, as shown in the image below.

Now, if you want to see the road clearly, what do you need to do? That’s right! You need to turn on the windshield wipers!

The action of the wiper clearing the rain can be seen as the process of finding the Attention area! Give yourself a round of applause; you have understood the Attention mechanism!
2. Revisiting the Attention Mechanism
First, we introduce a concept called Key-Value, key-value pair. The data type in this context is stored as key-value pairs, akin to a one-to-one concept (for example, in marriage law, a legal couple is a one-to-one relationship).
dict = {'name' : 'canshi'} # name is canshi
Recall from middle school that we learned about image formation in the eye! An image appears inverted and scaled in the eye, and the brain corrects it. We start modeling by assuming that the entities existing in nature are Key, also referred to as Value.
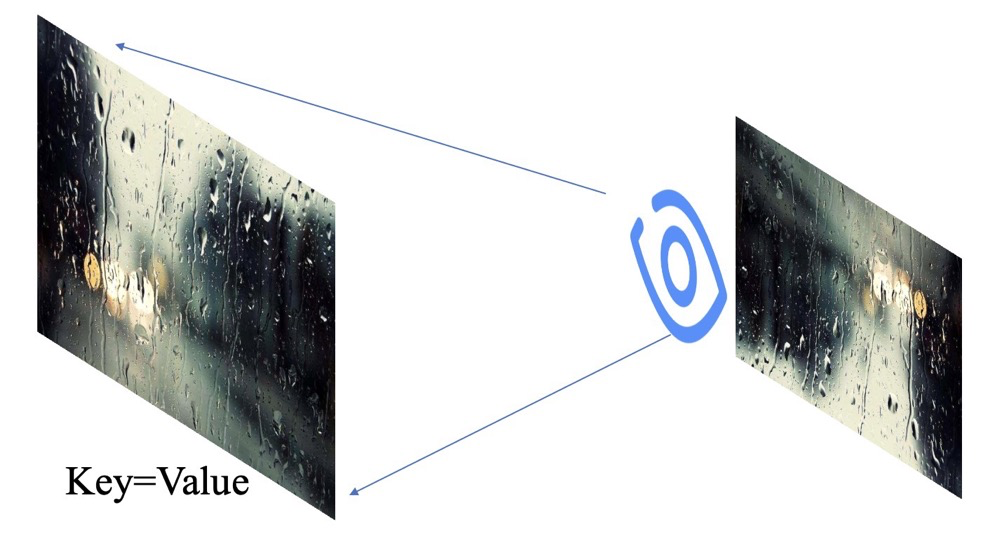
Let’s apply a formula: when it rains, the cold ice rain hits the car window hard! We refer to the entire window being hit as Key, also known as Value. However, we cannot see the road clearly; at this moment, we want to distinguish the main information on the road without focusing on the edges. This is when the wiper comes into play, which we call Query! We can now obtain a clearer image of the main road!
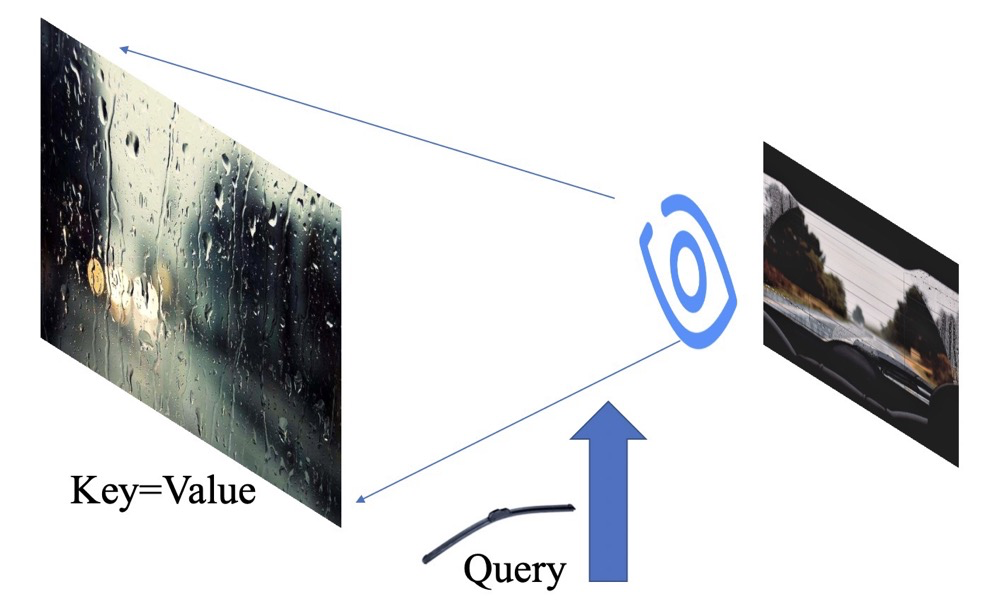
So what actually happens? Let me break it down:
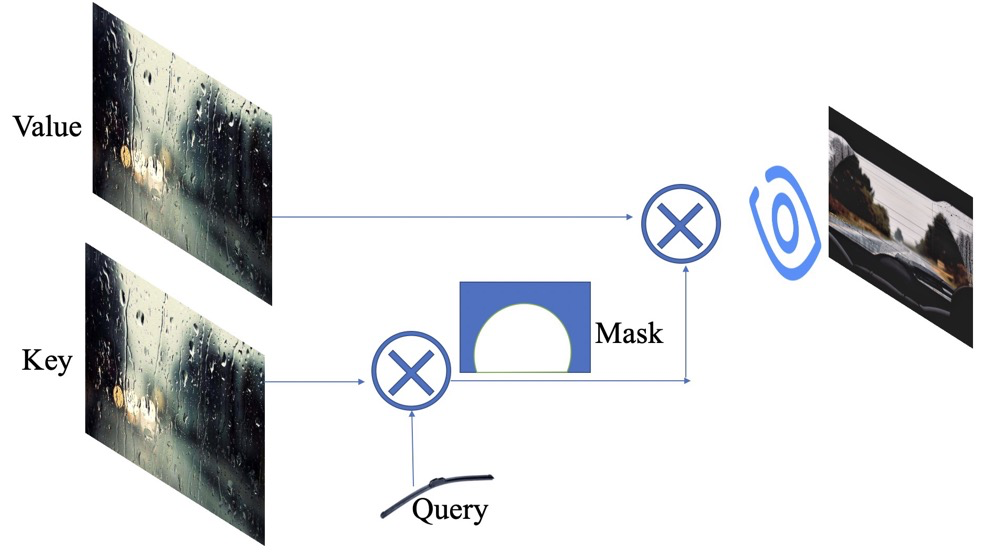
Thus, we apply the wiper function to the window image, resulting in a partially clear image (where values range from 0 to 1); the white area represents the cleared part, while the other areas are not of concern. We then multiply this generated image with the original image to obtain the final image displayed in our brain.
Therefore, you might see some blogs presenting the following image:
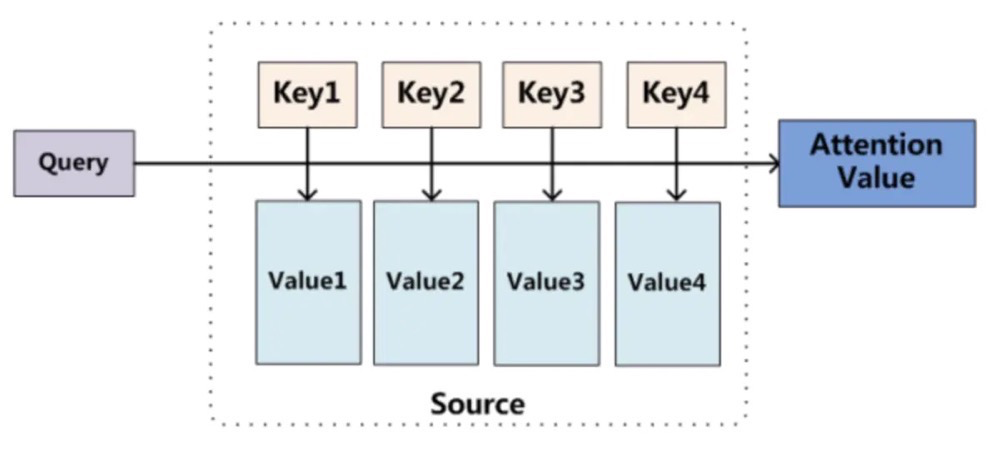
This image is primarily used in machine translation; during translation, each output needs to compute similarity with each input element and perform a weighted sum.
In the field, we generally use matrix operations, unlike tasks in other contexts that need to be performed over time. In this context, it is simply a matrix operation.
For instance, during the wiper’s action of clearing water, we denote the window with rain as original image, and the wiper clearing rain can be represented by similarity, resulting in new image. We then calculate it with the original image to obtain the final image.
Thus, a formula to summarize would be:
Highlighting that different cars have different wipers for clearing rain, similarly, we have various methods to measure similarity. Here we mainly have the following schemes to measure similarity:
Once we have the similarity, we need to normalize it, arranging the original calculated scores into a probability distribution where the sum of all element weights equals 1. The more important parts have larger weights, and the less important ones have smaller weights. We mainly use softmax, though some use other methods, which are also acceptable.
Thus, the weight can be calculated as follows:
Where scale indicates scaling the data to prevent excessively large values.
Finally, we obtain the output:

Thus, wearing glasses is also a form of attention, focusing on areas in the eyes while ignoring other areas, which do not require additional processing.
3. Attention Mechanism in the Brain
As a person grows, every stage may train the brain to quickly obtain desired information from nature. In the current era of big data, with so many images and videos, we need to quickly browse to extract information, as shown in the image below:

At first glance, I might notice this coat is a great style and this red bag is also nice. Of course, everyone’s training dataset is different, and I don’t know what you saw first! After all, this attention matrix requires a massive amount of data for testing.

Oh? You want to challenge me? Then try the challenge below!
The original video is from B station, not P station!
4. Common Attention Mechanisms in CV
1. Non-local Attention
From the above example, we understand that the essence is to compute a weight matrix in one dimension. If this dimension is spatial, it is Spatial Attention, and if it is along the channel dimension, it is Channel Attention. Thus, if you submit in the future and say you lack something, we can build a module from blocks!
Here we will explain the commonly used Attention in the field.
Input features are obtained through convolution, and the three matrices here are different, hence the assumption in the previous text is the same.
The code is as follows:
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
The code looks relatively easy to understand, mainly the function that can multiply the matrices of dimension with the matrix to obtain the resultant matrix. We then use softmax to get the normalized matrix, combining it with the residual to get the final output!
2. CBAM
CBAM is composed of Channel Attention and Spatial Attention.
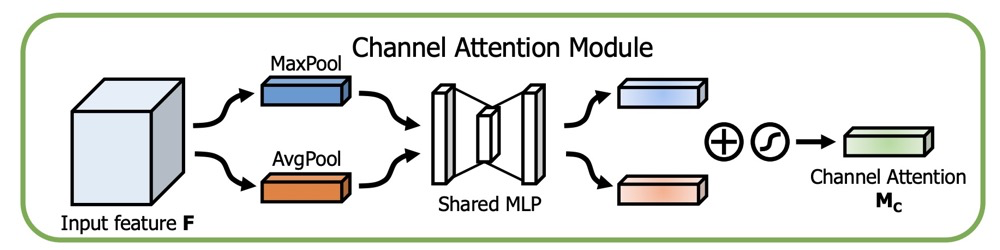
The module learns a weight matrix from the dimension of C x H x W to C x 1 x 1.
The figure from the paper is as follows:
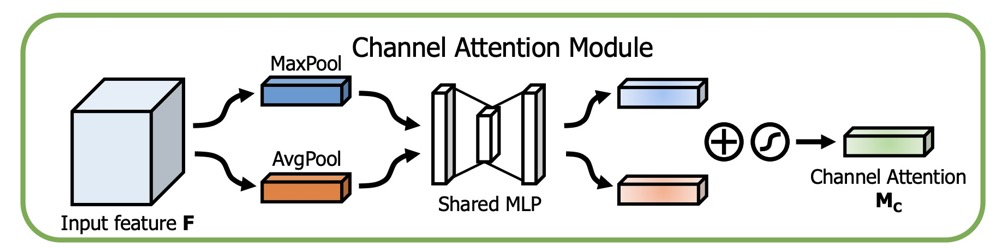
Here is a code example:
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = channel // reduction
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=channel, out_features=mid_channel),
nn.ReLU(inplace=True),
nn.Linear(in_features=mid_channel, out_features=channel)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
return self.sigmoid(avgout + maxout)
Of course, we can use this form to modify it into a unified architecture, as long as we can learn a distribution matrix in the channel dimension.
As shown in the pseudo code below, both are generated through convolution.
# key: (N, C, H, W)
# query: (N, C, H, W)
# value: (N, C, H, W)
key = key_conv(x)
query = query_conv(x)
value = value_conv(x)
mask = nn.softmax(torch.bmm(key.view(N, C, H*W), query.view(N, C, H*W).permute(0,2,1)))
out = (mask * value.view(N, C, H*W)).view(N, C, H, W)
For Spatial Attention, as illustrated:
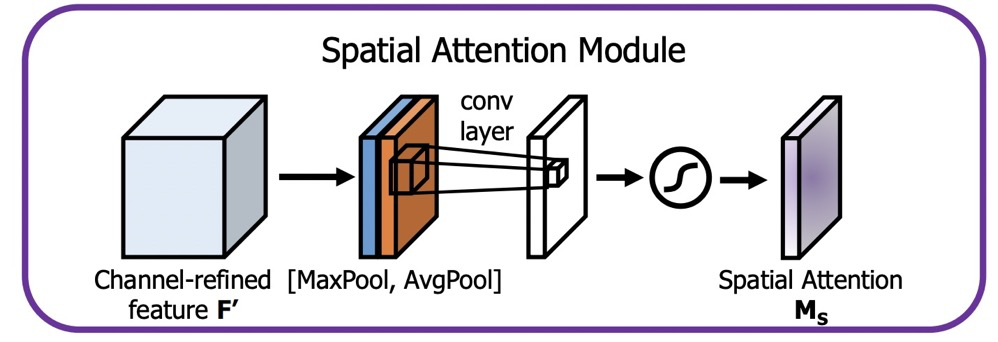
The reference code is as follows:
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
Using the Attention framework, we can rewrite it as follows:
key = key_conv(x)
query = query_conv(x)
value = value_conv(x)
b, c, h, w = t.size()
query = query.view(b, c, -1).permute(0, 2, 1)
key = key.view(b, c, -1)
value = value.view(b, c, -1).permute(0, 2, 1)
att = torch.bmm(query, key)
if self.use_scale:
att = att.div(c**0.5)
att = self.softmax(att)
x = torch.bmm(att, value)
x = x.permute(0, 2, 1)
x = x.contiguous()
x = x.view(b, c, h, w)
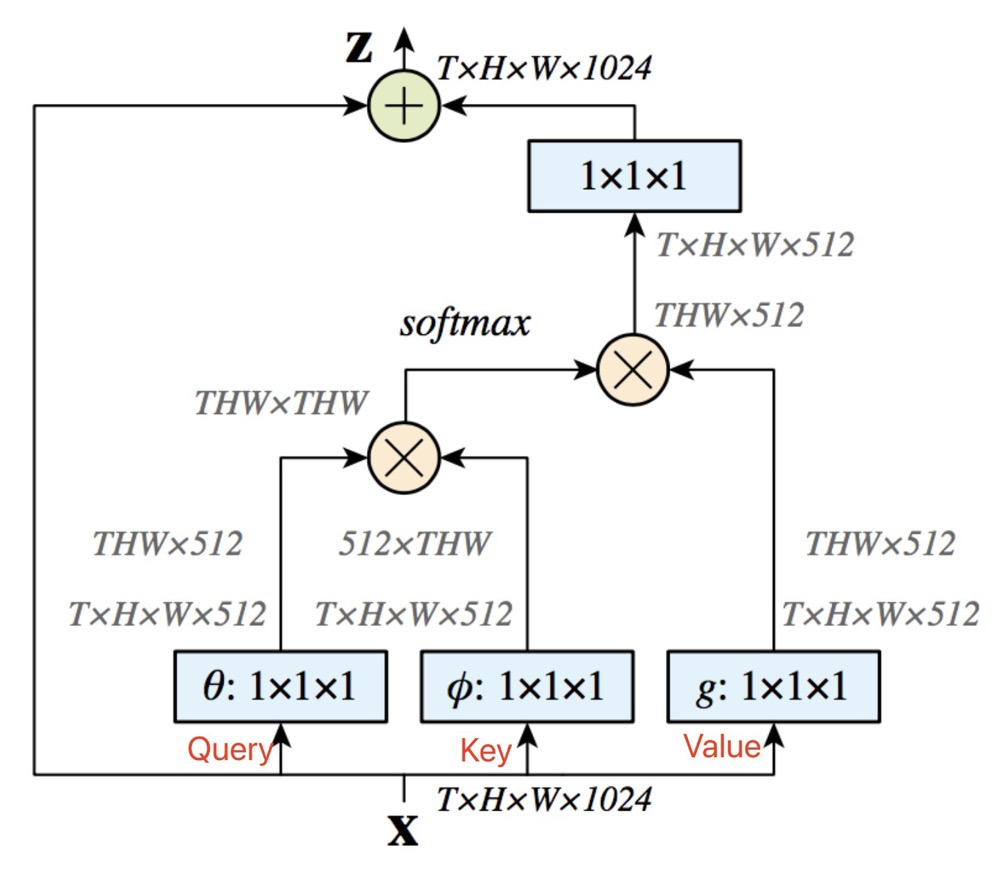
3. CGNL
The paper analyzes that both Channel Attention and Spatial Attention cannot adequately describe the relationships between features, leading to the extreme generation of N x 1 x 1 x 1.
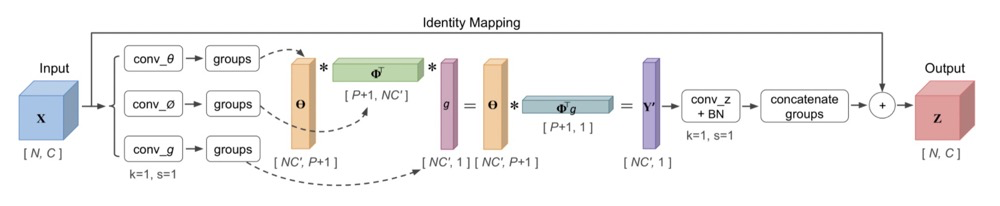
The main code portion regarding computation is:
def kernel(self, t, p, g, b, c, h, w):
"""The linear kernel (dot production).
Args:
t: output of conv theta
p: output of conv phi
g: output of conv g
b: batch size
c: channels number
h: height of featuremaps
w: width of featuremaps
"""
t = t.view(b, 1, c * h * w)
p = p.view(b, 1, c * h * w)
g = g.view(b, c * h * w, 1)
att = torch.bmm(p, g)
if self.use_scale:
att = att.div((c*h*w)**0.5)
x = torch.bmm(att, t)
x = x.view(b, c, h, w)
return x
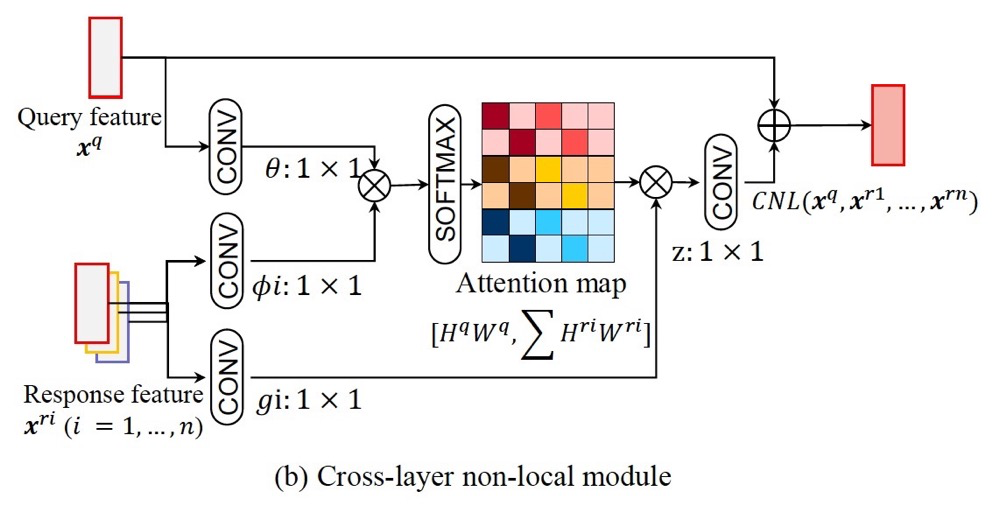
4. Cross-layer Non-local
The paper analyzes that computing within the same layer can lead to redundancy and introduce background noise, as shown on the left side of the image. The right side shows that different layers have different receptive fields, focusing on more reasonable areas globally.
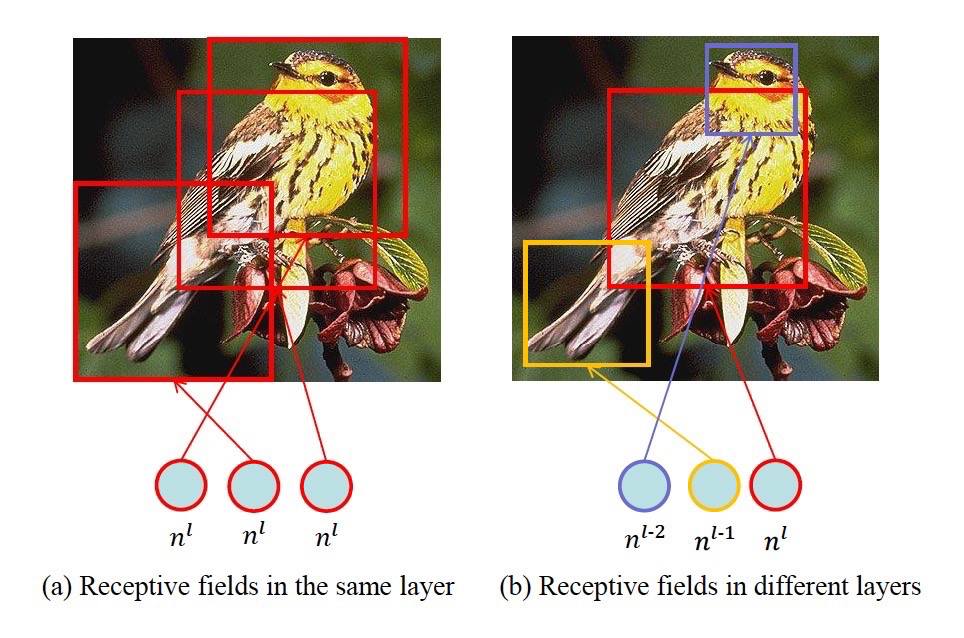
Here, we adopt generation across layers.
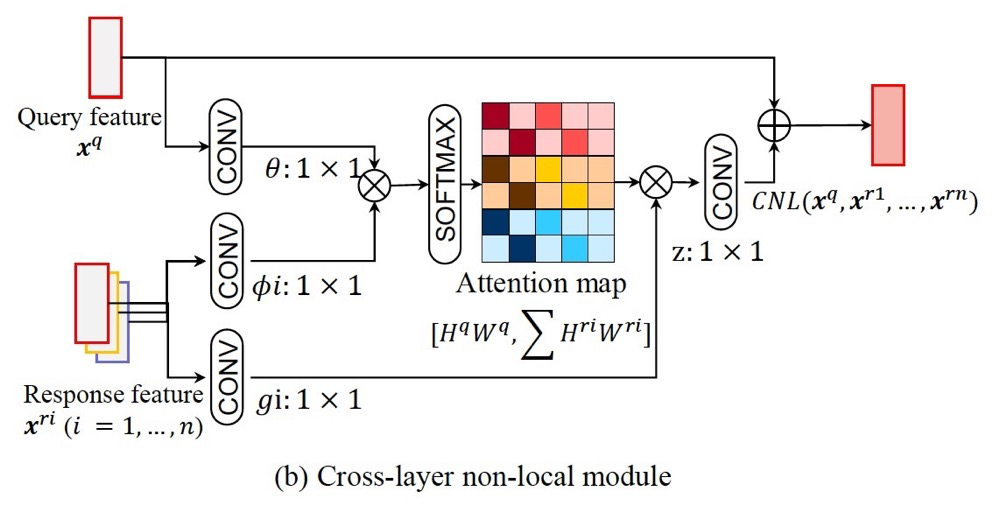
The code portion is quite interesting:
# query : N, C1, H1, W1
# key: N, C2, H2, W2
# value: N, C2, H2, W2
# First, we need a 1 x 1 convolution to make the channel numbers the same
q = query_conv(query) # N, C, H1, W1
k = key_conv(key) # N, C, H2, W2
v = value_conv(value) # N, C, H2, W2
att = nn.softmax(torch.bmm(q.view(N, C, H1*W1).permute(0, 1, 2), k.view(N, C, H2 * W2))) # (N, H1*W1, H2*W2)
out = att * value.view(N, C2, H2*W2).permute(0, 1, 2) #(N, H1 * W1, C)
out = out.view(N, C1, H1, W1)
4. Summary
This is a knowledge point suitable for writing articles, considered a core concept. Currently, this can be summarized for the field, and further updates will follow. Everyone is welcome to stay tuned!
– END –
Past Highlights
Suitable routes and materials for beginners in artificial intelligence
Machine learning and deep learning notes and material downloads
Online manual for machine learning
Deep learning notes collection
Code reproduction collection for "Statistical Learning Methods"
AI basics download
Mathematical foundation collection for machine learning
Video for "Machine Learning Course" from Wenzhou University
Join our QQ group 851320808, scan the code to join WeChat group: