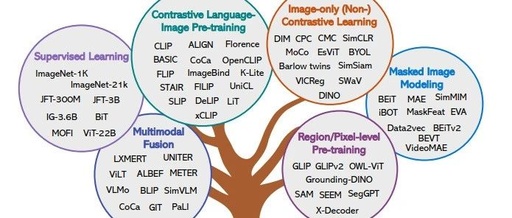
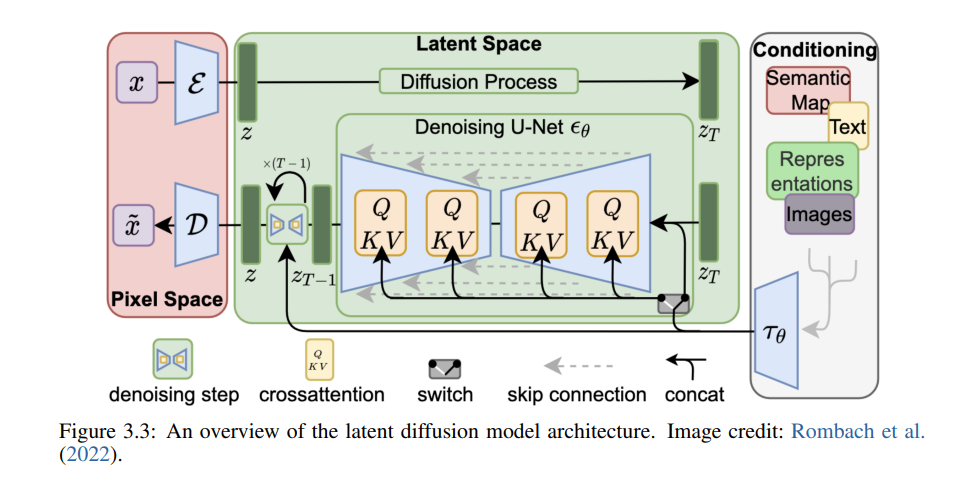
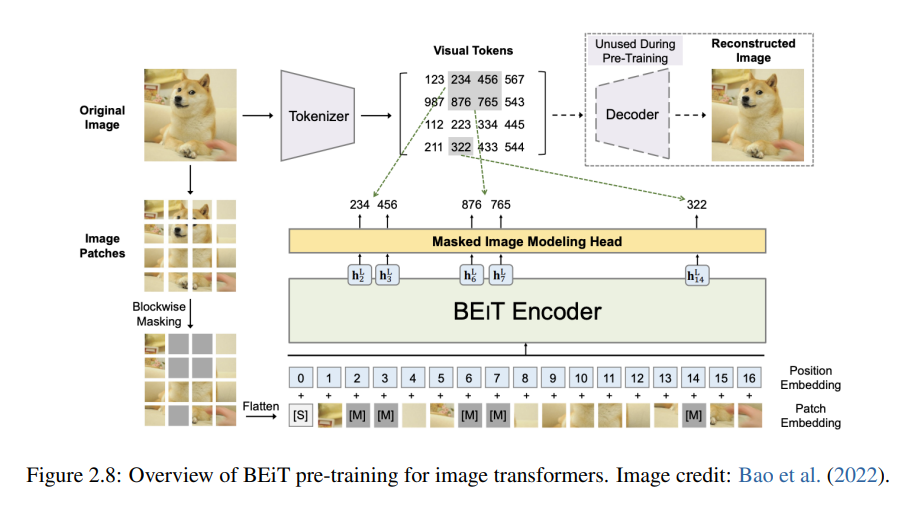
Previously, we introduced the Large Language Models (LLMs) technology principles and applications. LLMs are a type of Foundation model, and besides LLMs, Foundation models also include Large Vision Models and Large Multimodal Models.
Currently popular text-to-image models like Stable Diffusion, DALL-E, text-to-video model Sora, image-text retrieval, and visual content generation all fall under the category of multimodal large models. Today, I would like to recommend an overview paper on multimodal large models, and we will also release papers on visual large models in the future, so please stay tuned.
Reply ‘mfm’ in the backend to obtain the PDF
Below is a mind map summarizing the document’s content:
– Multimodal Foundation Models
– Definitions and Background
– The Importance of Multimodal Foundation Models
– Transition from Expert Models to General Assistants
– Supervised Pre-training
– Self-supervised Learning
– Text-to-Image Generation
– Spatially Controlled Generation
– From Closed-set to Open-set Models
– Task-specific Models to General Models
– From Static to Promptable Models
– Large Multimodal Models
– Case Studies of Large Multimodal Models
– Advanced Topics in Multimodal Agents
– Overview of Multimodal Agents
– Case Study of Multimodal Agents: MM-REACT
– Advanced Topics in Multimodal Agents
– Evaluation of Multimodal Agents
– Summary and Research Trends
– Building General AI Agents

The above diagram illustrates three representative problems that multimodal large models attempt to solve: visual understanding tasks, visual generation tasks, and a general interface with language understanding and generation capabilities.
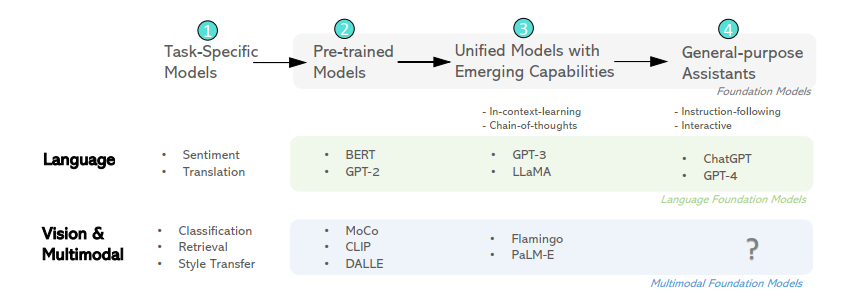
The above diagram describes the development trends of foundation models in the language and visual/multimodal domains, highlighting the trend of evolution from specialized models to general assistants and emphasizing the need for further research to determine how to best achieve this transition.
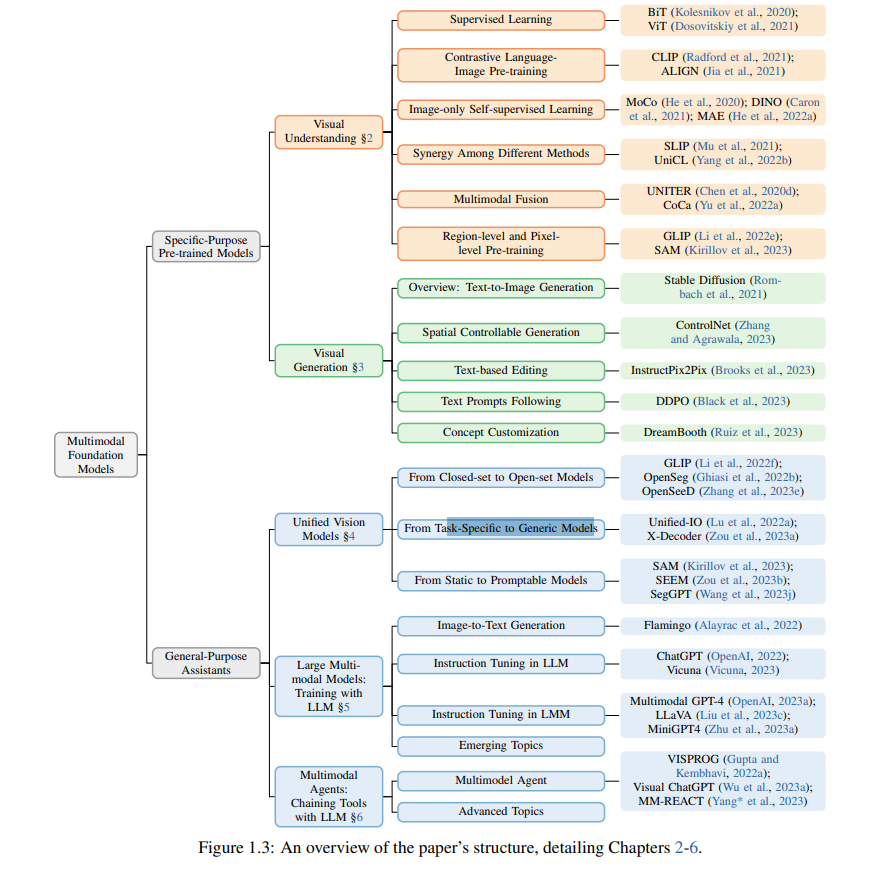
The structure of the entire paper’s sections
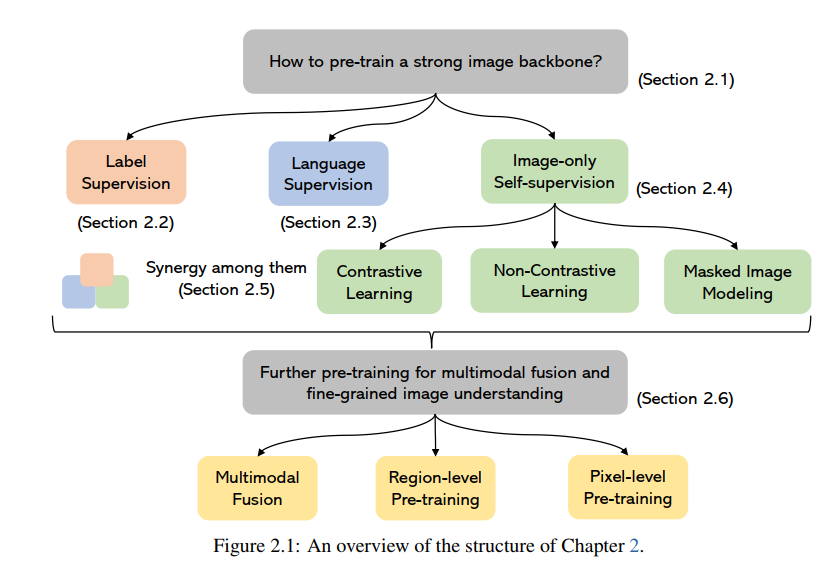
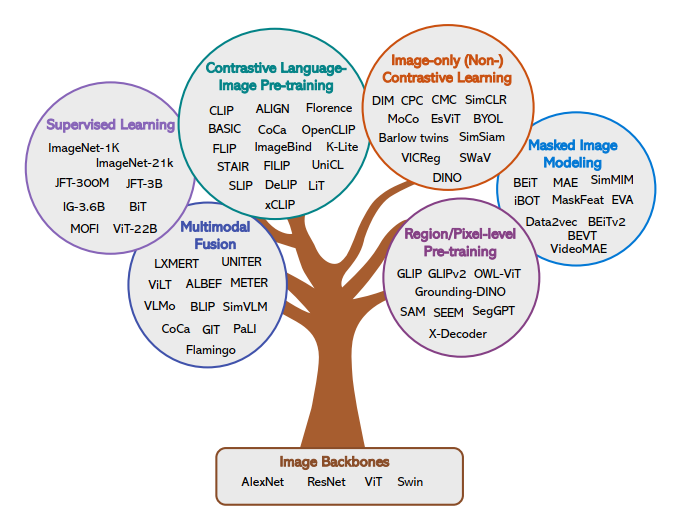
Summary of Visual Understanding
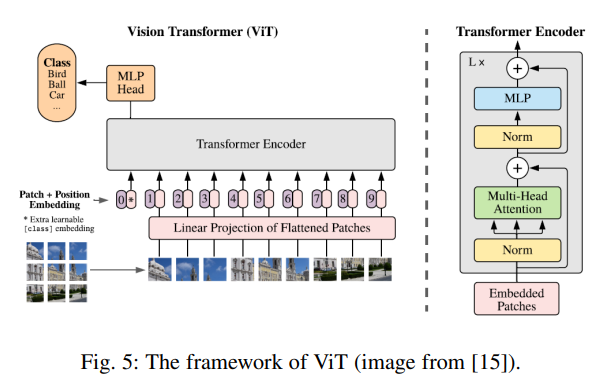
The development of large language models relies not only on computational power and data factors but also on the advancement of model architectures. Transformer is the foundation of language large models, while ViT is the foundation of visual large models.

Summary of Visual Content Generation
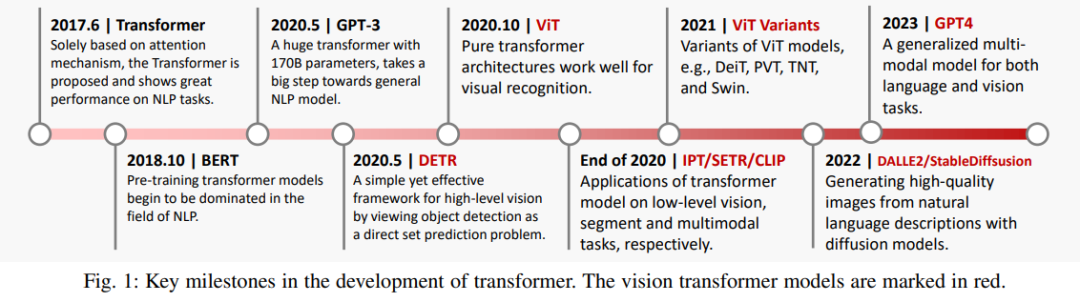
Timeline of Major Events in Image Generation
GANs are adept at generating realistic images that closely resemble those in the training set, while VAEs excel at creating a variety of images. Existing models have not successfully combined these two functionalities until the emergence of Stable Diffusion, which integrates the advantages of GAN and VAE, capable of generating realistic and diverse images.
CLIP is a pioneering work that maps language and images into a unified embedding space, serving as the foundation of multimodal large models.
BeiT, MAE, and IGPT have opened the era of image pre-training, BERT in CV.