
Trends in AIGC
The future LLM foundation models will become increasingly powerful, and many small models (huggingface models) are also thriving. When integrated with current enterprise applications or privatized data, new AI applications will emerge.
In autonomous agent systems driven by LLM technology, LLM plays the role of the intelligent brain and includes three components that enhance its key performance: Planning, Memory, and Tool.
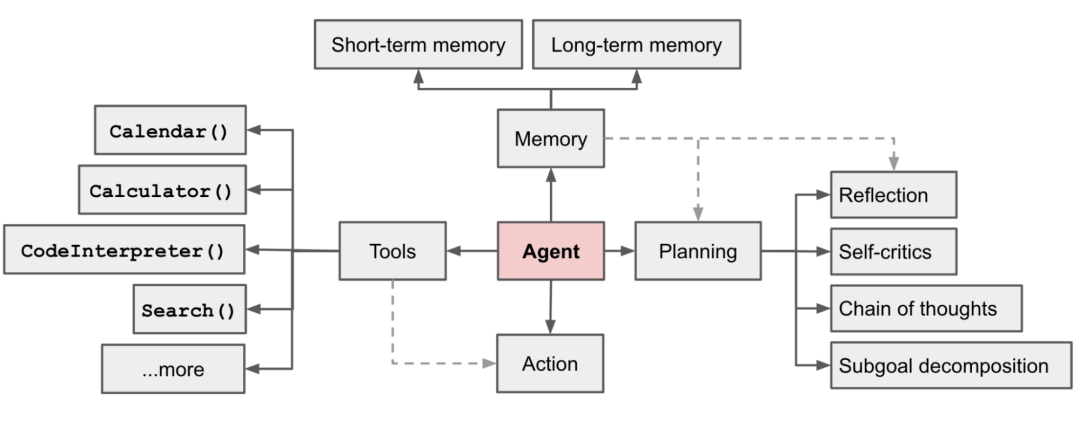
For more specific information about Agents, refer to: LLM Powered Autonomous Agents | Lil’Log
Next, we will build our own domain-specific data and AI Agent step by step.
Environment Preparation
-
Python 3.11 -
pip 24.0 -
IntelliJ IDEA / Pycharm -
OpenAI API Key -
Kubernetes 1.26.5 -
Helm v3.12.1
Technology Stack
-
LangChain: as the foundational framework -
LangChain Smith: for call tracing -
Jupyter Notebook: for writing and running code -
Milvus: vector database -
Gradio: frontend UI framework
Choosing a Vector Database
There are currently many vector databases available, which can be overwhelming. Here are some that I have used:
-
Faiss: Faiss is a library developed by Facebook AI Research, focusing on efficient similarity search for dense vectors. It supports various indexing and distance metrics and is suitable for large-scale datasets, running on both CPU and GPU. Welcome to Faiss Documentation
-
Chroma: Chroma is a GPU-based vector search library that provides fast approximate and exact searches. It is designed to optimize GPU performance, suitable for applications that require real-time search. 🧪 Usage Guide | Chroma
-
Pinecone: Pinecone is a cloud service that provides vector database as a service. It is easy to use, supports real-time data updates, and auto-scaling, suitable for developers who do not want to manage hardware. After registration, you will receive $100 in credits to try it out. Quickstart | Pinecone
-
Milvus: Milvus is an open-source vector database that supports various indexing structures and similarity search algorithms. It is suitable for multiple languages and provides rich APIs and SDKs for various AI application scenarios. Milvus documentation
Why Choose Milvus
From the official documentation and some blogs, I found several considerations:
-
Data Persistence and Low-Cost Storage
Data loss is the minimum baseline. Many standalone and lightweight vector databases do not focus on data reliability; most ANN indexes are purely loaded in memory, requiring large memory consumption to perform retrieval. Milvus is the world’s first vector database to support disk indexing, providing more than ten times the storage cost-effectiveness compared to disk indexing.
-
Data Distribution
Traditional database sharding is often based on primary keys or partition keys. For vector databases, queries often need to find vectors similar to the global target vector, which requires executing across all partitions, increasing computational demands as the data volume grows. Setting reasonable partition strategies based on vector data distribution and fully utilizing distribution information to enhance query performance and accuracy is essential.
-
Stability and Reliability
In the usage scenarios of vector databases, many require single-machine failures to recover within minutes, and there are increasing demands for master-slave disaster recovery and even cross-data center disaster recovery. Milvus achieves data availability based on distributed storage and message queues, and implementing stateless fault recovery based on K8s undoubtedly saves resources and shortens recovery time. Another significant challenge for the stability of vector databases is resource management. Traditional databases focus more on scheduling management of IO resources like disk and network, while the core bottleneck of vector databases is computation and memory.
-
Operability and Observability
Milvus supports multiple deployment modes, such as K8s Operator and Helm chart, docker compose, pip install, etc., and provides a monitoring and alerting system based on Grafana, Prometheus, and Loki. Zilliz has also open-sourced the vector database visualization management component Attu and the visualization tool Feder, significantly reducing the management difficulty of vector databases and improving the interpretability of vector retrieval. Thanks to Milvus 2.0’s distributed cloud-native architecture, Milvus is also the first vector database in the industry to support multi-tenant isolation, RBAC, Quota throttling, and rolling upgrades.
Enterprise privatized data is a very, very important resource. Currently, many RAG applications can maximize the utilization of AI + DATA by reasonably using these data resources for retrieval enhancement, resulting in a more intelligent application to serve enterprises.
Using K8S to Deploy Milvus Vector Database
Installation Introduction
For a quick and easy installation, refer to the official documentation: Install Milvus Standalone with Kubernetes
### 1. Add helm repo
helm repo add milvus https://zilliztech.github.io/milvus-helm/
helm repo update
### 2. View values file and mainly adjust storage parameters
helm show values milvus/milvus > milvus-values.yaml
helm template milvus-release milvus/milvus -f milvus-values.yaml -n milvus --set cluster.enabled=false --set etcd.replicaCount=1 --set minio.mode=standalone --set pulsar.enabled=false > local-deployment.yaml
### 3. Install the standalone version of milvus
kubectl create namespace milvus
helm upgrade --install milvus-release milvus/milvus -f milvus-values.yaml -n milvus --set cluster.enabled=false --set etcd.replicaCount=1 --set minio.mode=standalone --set pulsar.enabled=false
### 4. Local access
kubectl port-forward service/milvus-release 19530:19530
The above is a simple installation on the local machine. Of course, you can also combine various cloud vendors and Storage Class for high-availability storage to deploy distributed clusters, providing better performance and availability.
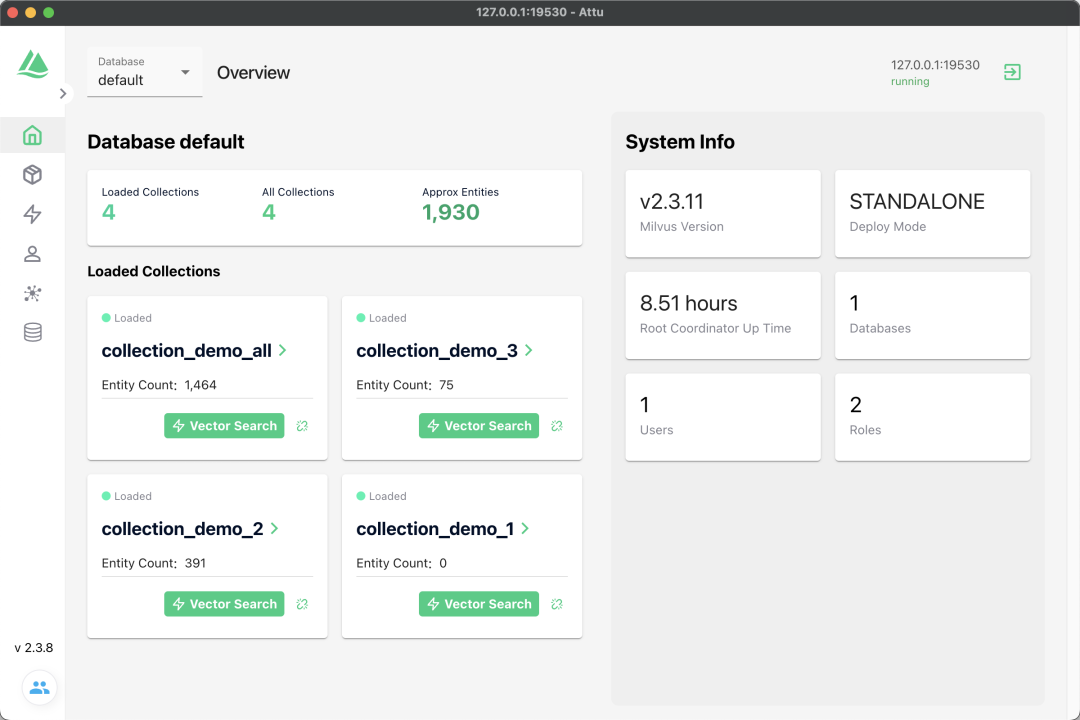
Installation Result

UI Interface Display
Installation address: zilliztech/attu: The GUI for Milvus
RAG
Retrieval Augmented Generation (RAG) refers to optimizing the output of large language models by allowing them to reference authoritative knowledge bases beyond their training data before generating responses. Large language models (LLMs) are trained on vast amounts of data, using billions of parameters to generate raw outputs for tasks such as answering questions, translating languages, and completing sentences. Building on the already powerful capabilities of LLMs, RAG extends their functionality to access internal knowledge bases specific to domains or organizations, all without requiring retraining of the models. This is an economical way to enhance LLM outputs, keeping them relevant, accurate, and useful across various contexts.
Known challenges faced by LLMs include:
-
Providing false information when there is no answer. -
Providing outdated or generic information when users need specific current responses. -
Creating responses from non-authoritative sources. -
Generating inaccurate responses due to term confusion, where different training sources use the same terms to discuss different things.
A typical RAG architecture diagram:
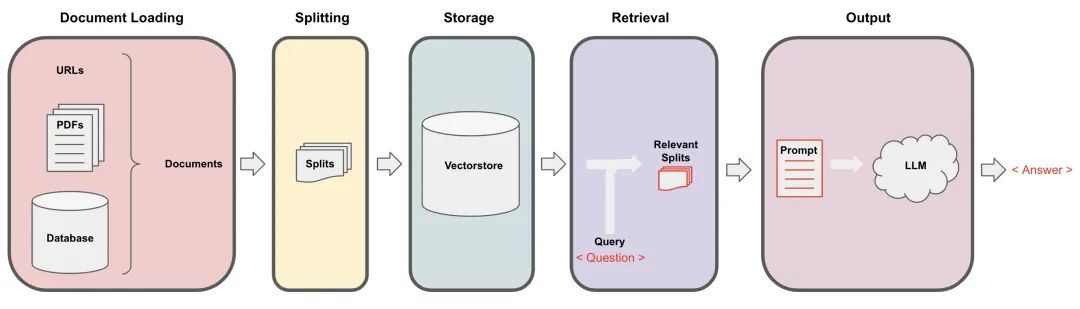
Typical RAG applications consist of two main components:
Indexing
A pipeline used to introduce data from sources and index it. This usually occurs offline. The indexing process consists of several parts:
1 Load
Loading: First, we need to load data. This is done using DocumentLoaders.
2 Split
Splitting: Text splitters break down large Documents into smaller chunks. This is useful for indexing data and passing it to the model, as large chunks are harder to search and do not fit well into the model’s limited context window.
3 Store
Storage: We need a place to store and index our splits so they can be searched later. This is usually accomplished using VectorStore and Embeddings models.
Retrieval And Generation
The actual RAG chain accepts user queries at runtime, retrieves relevant data from the index, and then passes it to the model.
1 Retrieval
Retrieval: Given user input, use Retriever to fetch relevant splits from storage.
2 Generation
Generation: The ChatModel / LLM generates answers using prompts that include the question and the retrieved data.
Example🌰
Once you have your OpenAI ApiKey and vector database ready, you will build a RAG application based on an agent step by step. Note: If you encounter messages indicating that a Python package is not installed, you can install it using the pip command.
1 Load Configuration
import os
from dotenv import load_dotenv, find_dotenv
# Read local .env file
_ = load_dotenv(find_dotenv())
api_key = os.getenv('OPENAI_API_KEY')
api_base = os.getenv('OPENAI_API_BASE')
2 Load Data
Load data from websites, PDFs, and videos using WebBaseLoader, PyPDFLoader, etc.
For more DataLoaders, refer to: Document loaders | Langchain
Script:
from langchain_community.document_loaders import WebBaseLoader
# from website
website_urls = [
"http://193.112.246.235:8090/archives/alibaba-cola-4.0-practices",
]
html_docs = []
for url in website_urls:
html_docs.extend(WebBaseLoader(web_path=url, encoding="UTF-8").load())
print(len(html_docs))
print(html_docs[0].metadata)
# from pdf
#! pip install pypdf
from langchain.document_loaders import PyPDFLoader
pdf_urls = [
"data/MachineLearning-Lecture01.pdf",
]
pdf_docs = []
for url in pdf_urls:
pdf_docs.extend(PyPDFLoader(url).load())
print(len(pdf_docs))
print(pdf_docs[0].metadata)
# from video
# fix ssl issue: pip install pyopenssl ndg-httpsclient pyasn1 urllib3
from langchain_community.document_loaders import YoutubeLoader
urls = [
"https://www.youtube.com/watch?v=HAn9vnJy6S4",
"https://www.youtube.com/watch?v=dA1cHGACXCo",
"https://www.youtube.com/watch?v=ZcEMLz27sL4",
"https://www.youtube.com/watch?v=hvAPnpSfSGo",
"https://www.youtube.com/watch?v=EhlPDL4QrWY",
"https://www.youtube.com/watch?v=mmBo8nlu2j0",
"https://www.youtube.com/watch?v=rQdibOsL1ps",
"https://www.youtube.com/watch?v=28lC4fqukoc",
"https://www.youtube.com/watch?v=es-9MgxB-uc",
"https://www.youtube.com/watch?v=wLRHwKuKvOE",
"https://www.youtube.com/watch?v=ObIltMaRJvY",
"https://www.youtube.com/watch?v=DjuXACWYkkU",
"https://www.youtube.com/watch?v=o7C9ld6Ln-M",
]
video_docs = []
for url in urls:
video_docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load())
print(len(video_docs))
print(video_docs[0].metadata)
outputs:
1
{'source': 'http://193.112.246.235:8090/archives/alibaba-cola-4.0-practices', 'title': "Alibaba COLA 4.0 架构实践 - Eric's Blog", 'description': 'Alibaba COLA架构 4.0 COLA 是 Clean Object-Oriented and Layered Architecture的缩写,代表“整洁面向对象分层架构”。 目前COLA已经发展到COLA v4。 互联网业务项目一般会遇到如下一些普遍问题: 虽然整体架构规划', 'language': 'en'}
22
{'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}
13
{'source': 'HAn9vnJy6S4', 'title': 'OpenGPTs', 'description': 'Unknown', 'view_count': 7603, 'thumbnail_url': 'https://i.ytimg.com/vi/HAn9vnJy6S4/hq720.jpg', 'publish_date': '2024-01-31 00:00:00', 'length': 1530, 'author': 'LangChain'}
3 Generate Index for Documents and Store in Vector Database
Script:
from langchain_openai import OpenAIEmbeddings
#from langchain_community.vectorstores import FAISS
#from langchain_community.vectorstores import Chroma
from langchain_community.vectorstores import Milvus
from langchain_text_splitters import RecursiveCharacterTextSplitter
import itertools
total_docs = list(itertools.chain(html_docs, pdf_docs, video_docs))
# Set the same schema for different documents or set dynamic scheme for Milvus
for doc in total_docs:
source_metadata = {"source": doc.metadata["source"]}
doc.metadata = source_metadata
# Split documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100)
chunked_docs = text_splitter.split_documents(total_docs)
# Better than text-embedding-ada-002
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
connection_args = {"host": "127.0.0.1", "port": "19530"}
collection_name = "collection_demo_all"
vectorstore = Milvus(
embedding_function=embeddings,
connection_args=connection_args,
drop_old =True
).from_documents(
documents=chunked_docs,
embedding=embeddings,
collection_name=collection_name,
connection_args = connection_args,
)
# vectorstore = FAISS.from_documents(
# chunked_docs,
# embeddings,
# )
# vectorstore = Chroma.from_documents(
# chunked_docs,
# embeddings,
# )
View data:
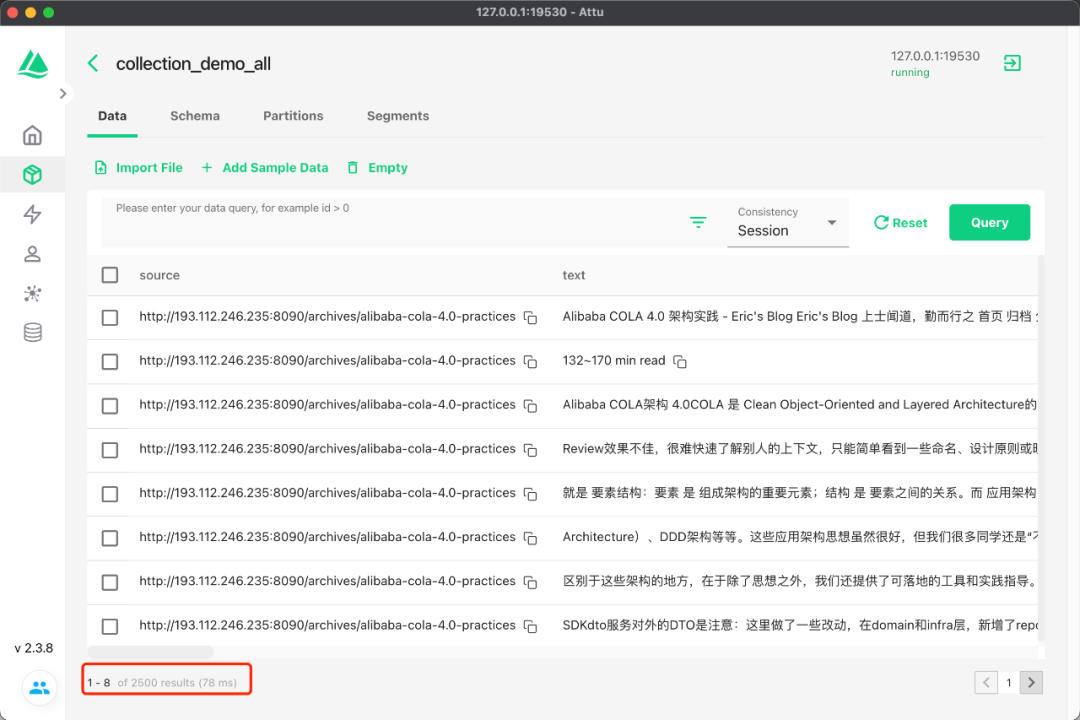 image-20240315212540396
image-20240315212540396
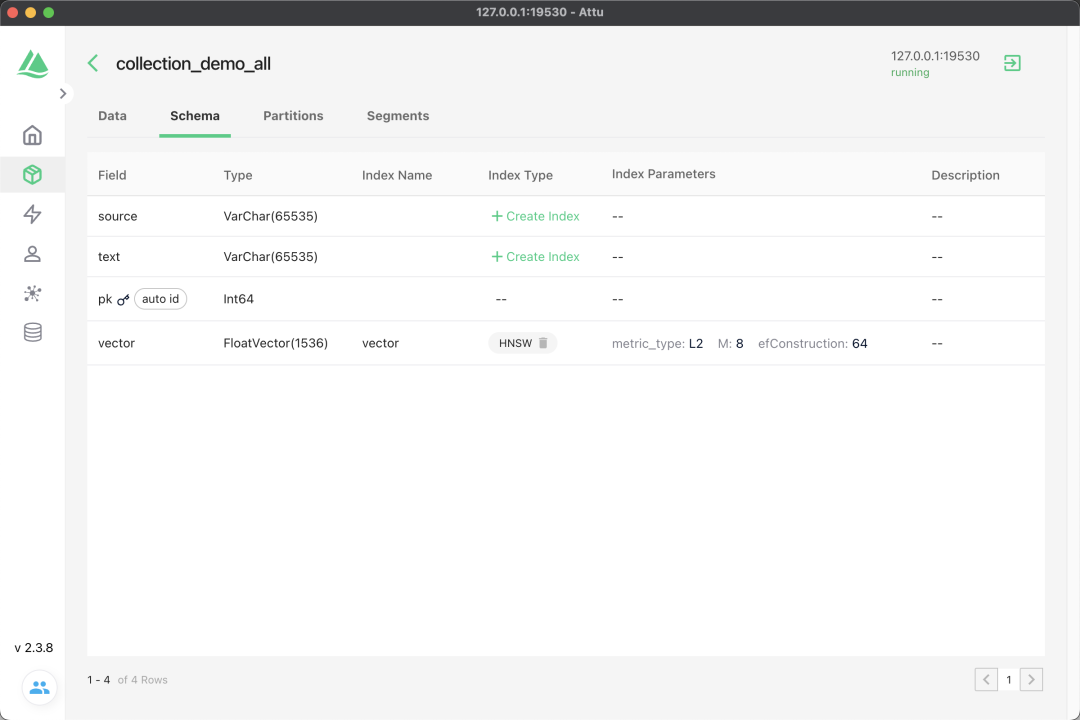
You can also perform similarity document retrieval through db
# Perform similarity search
## Will query website data
result1 = vectorstore.similarity_search("What is the COLA architecture?", k=3)
print("=======result1=======\n" + str(result1))
## Will query PDF data
result2 = vectorstore.similarity_search("what did they say about matlab?", k=3)
print("=======result2=======\n" + str(result2))
## Will query Video data
result3 = vectorstore.similarity_search("how do I build a RAG agent?", k=3)
print("=======result3=======\n" + str(result3))
outputs:
=======result1=======
[Document(page_content='The significance of architecture overview is the element structure: elements are the important components of the architecture; structure is the relationship between elements. The significance of application architecture lies in defining a good structure; governing application complexity and reducing system entropy; moving from a chaotic state to an orderly state. The COLA architecture is born for this purpose, and its core responsibility is to define a good application structure, providing best practices for optimal application architecture. Through continuous exploration, we find that a good layered structure and good package structure definition can help us govern the chaotic business application system. After multiple iterations, we have defined a relatively stable and reliable application architecture: COLA v4. COLA architecture is introduced in the official blog of COLA: Because business problems have certain commonalities. For example, typical business systems need to: receive requests, respond to responses; perform business logic processing, such as parameter validation, state transition, business calculation, etc.; interact with external systems, such as databases, microservices, search engines, etc.; it is precisely because of such commonalities that many universal architectural ideas emerge, such as layered architecture, hexagonal architecture, onion architecture, clean architecture (Clean Architecture), DDD architecture, etc. Although these application architectural ideas are good, many of our colleagues still say, “I understand many principles, but I still can’t live a good life.” The problem lies in the lack of practice and guidance. The significance of COLA is that it not only represents an idea but also provides implementable practices. It should be one of the few open-source software at the application architecture level. The COLA architecture differs from these architectures in that, in addition to the idea, we also provide implementable tools and practical guidance. The official layered diagram of COLA architecture: and the official introduction of the naming and meaning of each layer: Layer package name function required Adapter layer web handles page request Controller no Adapter layer wireless handles wireless adaptation no Adapter layer wap handles wap adaptation no App layer executor handles requests, including command and query is App layer consumer handles external messages no App layer scheduler handles scheduled tasks no Domain layer model domain model no Domain layer service domain capabilities, including DomainService no Domain layer gateway domain gateway, decoupling tool is Domain layer repository domain data access is Infra layer gatewayimpl gateway implementation is Infra layer repositoryimpl database access implementation is Infra layer mapperibatis database mapping no Infra layer config configuration information no Client SDK api service exposed to the outside API is Client', metadata={'source': 'http://193.112.246.235:8090/archives/alibaba-cola-4.0-practices', 'pk': 448376587072256902}), Document(page_content='Alibaba COLA architecture 4.0 COLA stands for Clean Object-Oriented and Layered Architecture, representing “clean object-oriented layered architecture.” Currently, COLA has developed into COLA v4. Internet business projects generally encounter some common problems: although the overall architectural planning is good, implementation deviates significantly, lacking sufficient abstraction and flexible design, and is process-oriented programming. The tight deadlines and rapid iterations of business lead to chaotic code structure, with almost no code comments and documentation, even if there are project code specifications. Frequent personnel changes result in taking over old projects, and newcomers have no time to digest the code structure and find it difficult to quickly understand the context. The urgent deadlines only allow the mess to pile up. Collaborative development involves different coding habits, with utility class codes each used differently, and business naming often conflicts, which further affects efficiency as the team grows. Similar functionalities are difficult to modify, and often hear: to write this card, first change the previous one. Code Review is ineffective, making it difficult to quickly understand the context of others, only able to see some naming, design principles, or obvious implementation issues. Most teams hardly have time for code refactoring, allowing code to rot. Or there is no motivation or KPI for code refactoring. No unit tests are written, or the large number of unit tests written are not very useful, requiring significant modifications when new features are added or refactoring occurs. Whenever a new code repository is started, it is full of confidence and structured. However, as time goes on, the code becomes increasingly rotten, and technical debt becomes larger. Is there a good solution? There is: design a well-structured application architecture and code implementation specifications, regularly conduct reviews to slow down code rot (of course, it is difficult to completely avoid it). Regularly refactor code to address technical debt, keeping designs as simple as possible so that developers at different levels can quickly understand and start developing, rather than piling more mess on a pile of complex, unreadable code. Designs should adhere to SOLID principles, as developers often violate the single responsibility principle and open-closed principle, making code and test adjustments difficult. Adhere to Code Review, first review model design, then understand implementation details. Persist in writing tests, writing effective tests, rather than just looking at test coverage and quantity, recommending using TDD. The Alibaba COLA architecture aims to provide a practical business code structure specification to slow down code rot as much as possible and speed up team development efficiency as much as possible. COLA overviews the significance of architecture as element structure: elements are the important components of the architecture; structure is the relationship between elements. The significance of application architecture lies in defining a good structure; governing application complexity and reducing system entropy; moving from a chaotic state to an orderly state. COLA architecture is born for this purpose, and its core responsibility is to define a good application structure, providing best practices for optimal application architecture. Through continuous exploration, we find that a good layered structure and good package structure definition can help us govern the chaotic business application system. After multiple iterations, we have defined a relatively stable and reliable application architecture: COLA v4. COLA architecture is introduced in the official blog of COLA: Because business problems have certain commonalities. For example, typical business systems need to: receive requests, respond to responses; perform business logic processing, such as parameter validation, state transition, business calculation, etc.; interact with external systems, such as databases, microservices, search engines, etc.; it is precisely because of such commonalities that many universal architectural ideas emerge, such as layered architecture, hexagonal architecture, onion architecture, clean architecture (Clean Architecture), DDD architecture, etc. Although these application architectural ideas are good, many of our colleagues still say, “I understand many principles, but I still can’t live a good life.” The problem lies in the lack of practice and guidance. The significance of COLA is that it not only represents an idea but also provides implementable practices. It should be one of the few open-source software at the application architecture level. COLA architecture differs from these architectures in that, in addition to the idea, we also provide implementable tools and practical guidance. The official layered diagram of COLA architecture: and the official introduction of the naming and meaning of each layer: Layer package name function required Adapter layer web handles page request Controller no Adapter layer wireless handles wireless adaptation no Adapter layer wap handles wap adaptation no App layer executor handles requests, including command and query is App layer consumer handles external messages no App layer scheduler handles scheduled tasks no Domain layer model domain model no Domain layer service domain capabilities, including DomainService no Domain layer gateway domain gateway, decoupling tool is Domain layer repository domain data access is Infra layer gatewayimpl gateway implementation is Infra layer repositoryimpl database access implementation is Infra layer mapperibatis database mapping no Infra layer config configuration information no Client SDK api service exposed to the outside API is Client', metadata={'source': 'http://193.112.246.235:8090/archives/alibaba-cola-4.0-practices', 'pk': 448376587072256901}), Document(page_content='Alibaba COLA architecture 4.0 COLA stands for Clean Object-Oriented and Layered Architecture, representing “clean object-oriented layered architecture.” Currently, COLA has developed into COLA v4. Internet business projects generally encounter some common problems: although the overall architectural planning is good, implementation deviates significantly, lacking sufficient abstraction and flexible design, and is process-oriented programming. The tight deadlines and rapid iterations of business lead to chaotic code structure, with almost no code comments and documentation, even if there are project code specifications. Frequent personnel changes result in taking over old projects, and newcomers have no time to digest the code structure and find it difficult to quickly understand the context. The urgent deadlines only allow the mess to pile up. Collaborative development involves different coding habits, with utility class codes each used differently, and business naming often conflicts, which further affects efficiency as the team grows. Similar functionalities are difficult to modify, and often hear: to write this card, first change the previous one. Code Review is ineffective, making it difficult to quickly understand the context of others, only able to see some naming, design principles, or obvious implementation issues. Most teams hardly have time for code refactoring, allowing code to rot. Or there is no motivation or KPI for code refactoring. No unit tests are written, or the large number of unit tests written are not very useful, requiring significant modifications when new features are added or refactoring occurs. Whenever a new code repository is started, it is full of confidence and structured. However, as time goes on, the code becomes increasingly rotten, and technical debt becomes larger. Is there a good solution? There is: design a well-structured application architecture and code implementation specifications, regularly conduct reviews to slow down code rot (of course, it is difficult to completely avoid it). Regularly refactor code to address technical debt, keeping designs as simple as possible so that developers at different levels can quickly understand and start developing, rather than piling more mess on a pile of complex, unreadable code. Designs should adhere to SOLID principles, as developers often violate the single responsibility principle and open-closed principle, making code and test adjustments difficult. Adhere to Code Review, first review model design, then understand implementation details. Persist in writing tests, writing effective tests, rather than just looking at test coverage and quantity, recommending using TDD. The Alibaba COLA architecture aims to provide a practical business code structure specification to slow down code rot as much as possible and speed up team development efficiency as much as possible. COLA overviews the significance of architecture as element structure: elements are the important components of the architecture; structure is the relationship between elements. The significance of application architecture lies in defining a good structure; governing application complexity and reducing system entropy; moving from a chaotic state to an orderly state. COLA architecture is born for this purpose, and its core responsibility is to define a good application structure, providing best practices for optimal application architecture. Through continuous exploration, we find that a good layered structure and good package structure definition can help us govern the chaotic business application system. After multiple iterations, we have defined a relatively stable and reliable application architecture: COLA v4. COLA architecture is introduced in the official blog of COLA: Because business problems have certain commonalities. For example, typical business systems need to: receive requests, respond to responses; perform business logic processing, such as parameter validation, state transition, business calculation, etc.; interact with external systems, such as databases, microservices, search engines, etc.; it is precisely because of such commonalities that many universal architectural ideas emerge, such as layered architecture, hexagonal architecture, onion architecture, clean architecture (Clean Architecture), DDD architecture, etc. Although these application architectural ideas are good, many of our colleagues still say, “I understand many principles, but I still can’t live a good life.” The problem lies in the lack of practice and guidance. The significance of COLA is that it not only represents an idea but also provides implementable practices. It should be one of the few open-source software at the application architecture level. COLA architecture differs from these architectures in that, in addition to the idea, we also provide implementable tools and practical guidance. The official layered diagram of COLA architecture: and the official introduction of the naming and meaning of each layer: Layer package name function required Adapter layer web handles page request Controller no Adapter layer wireless handles wireless adaptation no Adapter layer wap handles wap adaptation no App layer executor handles requests, including command and query is App layer consumer handles external messages no App layer scheduler handles scheduled tasks no Domain layer model domain model no Domain layer service domain capabilities, including DomainService no Domain layer gateway domain gateway, decoupling tool is Domain layer repository domain data access is Infra layer gatewayimpl gateway implementation is Infra layer repositoryimpl database access implementation is Infra layer mapperibatis database mapping no Infra layer config configuration information no Client SDK api service exposed to the outside API is Client', metadata={'source': 'http://193.112.246.235:8090/archives/alibaba-cola-4.0-practices', 'pk': 448376587072255954})]
=======result2=======
[Document(page_content="those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn't. \nSo I guess for those of you that haven't s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to", metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'pk': 448376587072256033}), Document(page_content='machine learning stuff was actually useful. So what was it that you learned? Was it \nlogistic regression? Was it the PCA? Was it the data ne tworks? What was it that you \nlearned that was so helpful?' And the student said, 'Oh, it was the MATLAB.' \nSo for those of you that don\'t know MATLAB yet, I hope you do learn it. It\'s not hard, \nand we\'ll actually have a short MATLAB tutori al in one of the discussion sections for \nthose of you that don\'t know it.', metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'pk': 448376587072256037}), Document(page_content='those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn't. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon't have a MATLAB license, for the purposes of this class, there's also — [inaudible] \nwrite that down [inaudible] MATLAB — there' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it's free, and for the purposes of this class, it will work for just about \neverything.', metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'pk': 448376587072256942})]
=======result3=======
[Document(page_content="this is a blog post we wrote kind of a while back talking about Rag and the various approaches to improve rag um and I'll of course share this link but if we look at this diagram here there's a few different places that we can think about kind of improving our rag chain so initially we can think about like if we have a raw user question we can transform it in some way um we can query you can use routing to query different databases we can use Query construction if you want to go from like natur language to", metadata={'source': 'EhlPDL4QrWY', 'pk': 448376587072256321}), Document(page_content="hi this is Lance from the Lang chain team and today we're going to be building and deploying a rag app using pine con serval list from scratch so we're going to kind of walk through all the code required to do this and I'll use these slides as kind of a guide to kind of lay the the ground work um so first what is rag so under capoy has this pretty nice visualization that shows LMS as a kernel of a new kind of operating system and of course one of the core components of our operating system is the ability to", metadata={'source': 'EhlPDL4QrWY', 'pk': 448376587072256302}), Document(page_content="hi this is Lance from the Lang chain team and today we're going to be building and deploying a rag app using pine con serval list from scratch so we're going to kind of walk through all the code required to do this and I'll use these slides as kind of a guide to kind of lay the the ground work um so first what is rag so under capoy has this pretty nice visualization that shows LMS as a kernel of a new kind of operating system and of course one of the core components of our operating system is the ability to connect like your CPU or in this case an LM uh to dis or in this case say a vector store some kind of data storage that contains information that you want to pass into the llm and llms have this notion of a context window which typically pass in like say prompts but of course we can also pass in information retrieved from external sources now one of the most popular external sources are vector stores and these have really nice properties like the ability to perform semantic similarity search so you can", metadata={'source': 'EhlPDL4QrWY', 'pk': 448376587072257089})]
Next, combine with LLM for QnA.
4 Build Appropriate Prompts and Choose Base Large Model
There are many articles on prompt engineering, so I won’t elaborate here. There are many websites to obtain prompts, such as LangChain Hub, Hugging Face Datasets, etc.
Script:
#from langchain import hub
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
# Build prompt and llm base model
## From standard library to build prompt
## prompt = hub.pull("rlm/rag-prompt")
## prompt = hub.pull("hwchase17/openai-functions-agent")
## prompt = hub.pull("hwchase17/openai-tools-agent")
## print(prompt.messages)
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are an assistant for Q&A tasks. Use the retrieved context below to answer questions. If you don't know the answer, say you don't know."),
MessagesPlaceholder(variable_name="chat_history", optional=True),
("human", "{question}"),
MessagesPlaceholder(variable_name='agent_scratchpad'),
]
)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
5 Build Tool
When creating a create_retriever_tool, be sure to carefully write the description field, as this will affect which tool LangChain uses later. If the wrong tool is selected during natural language processing, unreasonable results may occur.
Script:
from langchain.tools.retriever import create_retriever_tool
## Build retriever
retriever = vectorstore.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
"db_content_retriever_tool",
"a retriever tool for COLA architecture, Machine Learning, RAG, Langchain",
)
tools = [retriever_tool]
6 Build Agent
from langchain.agents import AgentExecutor, create_openai_tools_agent
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
7 Validation
Validation 1:
agent_executor.invoke({"question": "What is the theme of this COLA blog?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `db_content_retriever_tool` with `{'query': 'COLA blog theme'}`
...
{'question': 'What is the theme of this COLA blog?',
'output': 'The theme of this COLA blog is "Alibaba COLA 4.0 Architecture Practice".'}
Validation 2:
agent_executor.invoke({"question": "How many layers does the COLA architecture have?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `db_content_retriever_tool` with `{'query': 'COLA architecture layers'}`
...
{'question': 'How many layers does the COLA architecture have?',
'output': 'The COLA architecture consists of the following layers:
1. Adapter layer: includes the Controller that handles page requests, handles wireless adaptation, handles wap adaptation
2. App layer: includes the executor that handles requests, the consumer that handles external messages, the scheduler that handles scheduled tasks
3. Domain layer: includes the domain model, the service of domain capabilities, the gateway of domain, the repository of domain data access
4. Infra layer: includes the gateway implementation, the database access implementation, the database mapping, the configuration information
5. Client SDK: includes the API service exposed to the outside and the methods of domain objects that provide business entities and business logic calculation to the App layer
These layers each have different responsibilities and functions to achieve a good structure of the overall architecture and govern application complexity.'}
Validation 3:
agent_executor.invoke({"question": "What are the benefits of using the COLA architecture? What is the difference between COLA architecture, DDD architecture, and hexagonal architecture? Please summarize in 100 words or less."})
outputs:
> Entering new AgentExecutor chain...
Invoking: `db_content_retriever_tool` with `{'query': 'Advantages of COLA architecture'}`
...
{'question': 'What are the benefits of using the COLA architecture? What is the difference between COLA architecture, DDD architecture, and hexagonal architecture? Please summarize in 100 words or less.',
'output': 'The benefits of the COLA architecture include providing business entities and methods for business domain, offering business entities and business logic calculations for the application layer. The domain is the core of the application, independent of any other layers; the infrastructure layer is responsible for handling technical details such as CRUD operations on databases, search engines, file systems, and distributed service RPCs. The advantages of COLA architecture lie in the layered and functional packaging strategy, which can control chaos within the business domain. The difference between COLA and DDD and hexagonal architecture is that COLA focuses more on the layering of business entities and the packaging of business logic, providing clear architectural specifications and code quality, enhancing team development efficiency.'}
Validation 4:
agent_executor.invoke({"question": "What is the difference between the domain layer and the app layer?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `db_content_retriever_tool` with `{'query': 'the difference between domain layer and app layer'}`
...
{'question': 'What is the difference between the domain layer and the app layer?',
'output': 'In the architecture of applications, the Domain layer and App layer have the following differences:
1. App layer (Application Layer): The App layer is the implementation layer of services, containing the implementation classes of various businesses and strictly following business packaging. In the App layer, it is packaged according to business domains and then packaged according to functional implementations. The App layer includes the following three functions:
- Executor: handles requests, including commands (command) and queries (query).
- Consumer: handles external messages.
- Scheduler: handles scheduled tasks.
- Converter: handles data object conversions.
2. Domain layer (Domain Layer): The Domain layer is the core layer of the application, independent of any other layers. In the Domain layer, it is packaged according to different domains (such as customer and order). The Domain layer includes the following main file types:
- Domain Entity: The entity model can be a rich model, for example, Customer.java defines the attributes and methods of the Customer entity.
- Domain Service: provides business logic calculations.
- Domain Gateway: used for decoupling and accessing external resources.
In summary, the App layer mainly handles functions related to external interaction, such as handling requests, messages, and scheduled tasks, while the Domain layer is the core of the application, containing business entities, business logic calculations, and domain services. Both play different roles in the architecture with clear divisions of labor.'}
8 Custom Tool
Enhance our AI Agent by creating custom tools.
from langchain_core.tools import tool
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
import wikipedia
from pydantic import BaseModel, Field
@tool
def search_wikipedia(query: str) -> str:
"""Run Wikipedia search and get page summaries."""
page_titles = wikipedia.search(query)
summaries = []
for page_title in page_titles[: 3]:
try:
wiki_page = wikipedia.page(title=page_title, auto_suggest=False)
summaries.append(f"Page: {page_title}\nSummary: {wiki_page.summary}")
except (
self.wiki_client.exceptions.PageError,
self.wiki_client.exceptions.DisambiguationError,
):
pass
if not summaries:
return "No good Wikipedia Search Result was found"
return "\n\n".join(summaries)
Rebuild the Agent:
# Use all tools
tools = [retriever_tool, multiply, add, exponentiate, search_wikipedia]
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
9 Validate Again
The output includes the selected tool name and the result.
Validation 1:
agent_executor.invoke({"question": "1 + 1 = ?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `add` with `{'first_int': 1, 'second_int': 1}`
...
{'question': '1 + 1 = ?', 'output': '1 + 1 equals 2.'}
Validation 2:
agent_executor.invoke({"question": "6 * 8 = ?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `multiply` with `{'first_int': 6, 'second_int': 8}`
...
{'question': '6 * 8 = ?', 'output': '6 multiplied by 8 is equal to 48.'}
Validation 3:
This demonstrates an error❌ example; theoretically, the question here should select the context from the PDF materials in db_content_retriever_tool, but it chose the search_wikipedia Tool instead because of the insufficiently accurate description provided when creating the tool, leading to issues in tool selection during LangChain processing.
agent_executor.invoke({"question": "What did they say about MATLAB?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `search_wikipedia` with `{'query': 'Matlab'}`
...
{'question': 'What did they say about MATLAB?', 'output': 'MATLAB is a proprietary multi-paradigm programming language and numeric computing environment developed by MathWorks. It allows matrix manipulations, plotting of functions and data, implementation of algorithms, creation of user interfaces, and interfacing with programs written in other languages. MATLAB has more than four million users worldwide, coming from various backgrounds of engineering, science, and economics. Additionally, MATLAB has an optional toolbox that uses the MuPAD symbolic engine for symbolic computing abilities, and Simulink, a graphical multi-domain simulation and model-based design tool for dynamic and embedded systems. Simulink is a MATLAB-based graphical programming environment for modeling, simulating, and analyzing multidomain dynamical systems.'}
Validation 4:
After adjustments, we no longer selected the wiki tool for answering questions.
agent_executor.invoke({"question": "How do I build a RAG agent?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `db_content_retriever_tool` with `{'query': 'RAG agent'}`
...
{'question': 'How do I build a RAG agent?', 'output': 'Building a RAG (Retrieval-Augmented Generation) agent involves several steps. Here are some key points from the retrieved content:
1. **Understanding RAG**: RAG is like a kernel of a new operating system that connects language models (LMs) to external data sources for information retrieval.
2. **Components of RAG**: RAG consists of the ability to connect LMs to external data sources, such as vector stores, which allow semantic similarity searches.
3. **RAG Architecture**: The RAG bot typically starts with a retrieval step before responding. This architecture is simpler and more streamlined, focusing on a single retrieval step rather than iterative searches.
4. **Implementation**: To build a RAG agent, you would need to set up the necessary code and infrastructure to enable retrieval and generation processes within the agent.
If you need more detailed information or specific steps on building a RAG agent, further resources or guidance may be required.'}
Validation 5:
Here, we choose a new term, and this time we will choose Wikipedia for the answer.
agent_executor.invoke({"question": "What is Domain-Driven Design?"})
outputs:
> Entering new AgentExecutor chain...
Invoking: `search_wikipedia` with `{'query': 'Domain-Driven Design'}`
...
{'question': 'What is Domain-Driven Design?', 'output': 'Domain-Driven Design (DDD) is a software development methodology aimed at solving design problems in complex business domains by modeling software systems as domain models. Domain-Driven Design emphasizes a deep understanding of the business domain and directly maps this domain knowledge into software design. By using domain models to describe the concepts and relationships of the business domain, development teams can better communicate, understand, and implement business requirements, thus improving the quality and maintainability of software systems.'}
10 Add Memory for Message History
from langchain.memory import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# Use memory storage, can also use external systems like redis, etc.
chat_history_for_chain = ChatMessageHistory()
conversational_agent_executor = RunnableWithMessageHistory(
agent_executor,
lambda session_id: chat_history_for_chain,
input_messages_key="question",
output_messages_key="output",
history_messages_key="chat_history",
)
Validation:
conversational_agent_executor.invoke(
{
"question": "I'm Eric!",
},
{"configurable": {"session_id": "session_id_001"}},
)
> Entering new AgentExecutor chain...
Hello Eric! How can I assist you today?
> Finished chain.
{'question': "I'm Eric!",
'chat_history': [],
'output': 'Hello Eric! How can I assist you today?'}
conversational_agent_executor.invoke(
{
"question": "What is my name?",
},
{"configurable": {"session_id": "session_id_001"}},
)
> Entering new AgentExecutor chain...
Your name is Eric!
> Finished chain.
{'question': 'What is my name?',
'chat_history': [HumanMessage(content="I'm Eric!"),
AIMessage(content='Hello Eric! How can I assist you today?')],
'output': 'Your name is Eric!'}
There are many ways to add memory; here, we use an unlimited memory method. Increasingly more historical context will lead to a significant increase in token consumption. A new chain can be added between the current chains to summarize the history using LLM.
11 Use Gradio to Build a Simple UI to Access Your Agent
def generate(question):
response = agent_executor.invoke({"question": question})
return response.get("output")
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# Gradio Demo UI 🖍️")
input_text = gr.Text(label="Your Input")
btn = gr.Button("Submit")
result = gr.Textbox(label="Generated Result")
btn.click(fn=generate, inputs=[input_text], outputs=[result])
gr.close_all()
demo.launch()
Validation:
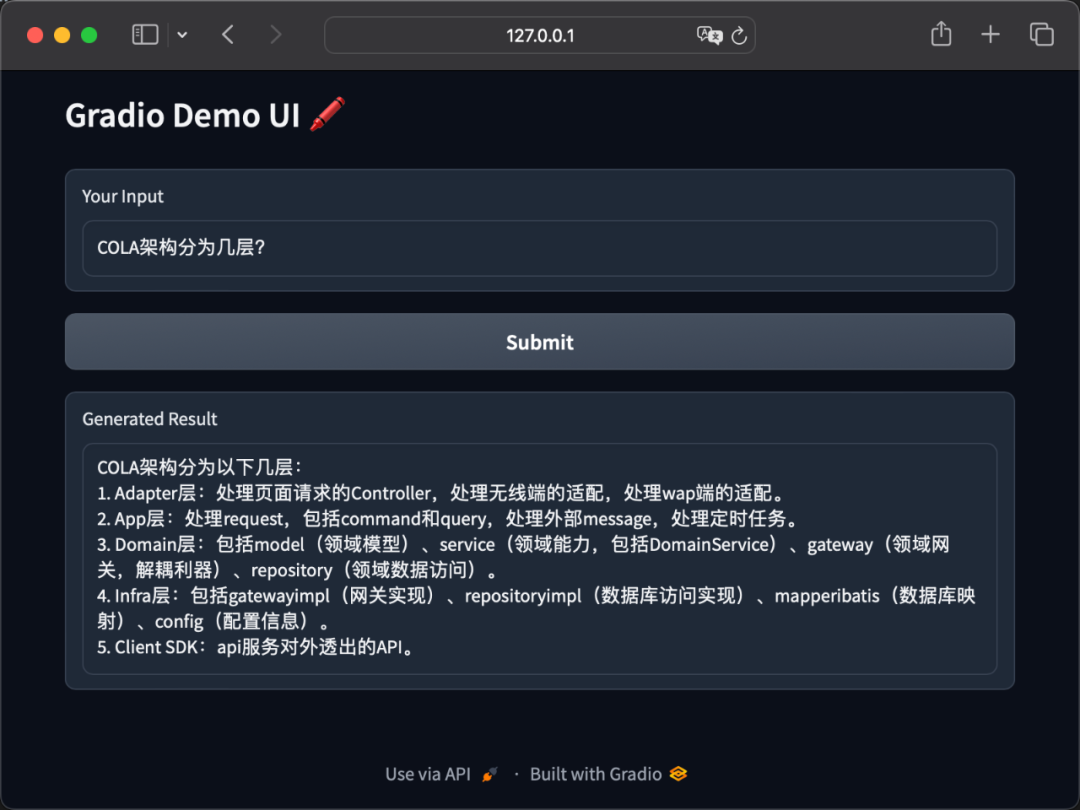 image-20240315213821301
image-20240315213821301
12 Expose a Restful API and Customize Frontend UI
from fastapi import FastAPI
from langchain.pydantic_v1 import BaseModel, Field
from langchain_core.messages import BaseMessage
from langserve import add_routes
# App definition
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
# Adding chain route
# We need to add these input/output schemas because the current AgentExecutor
# is lacking in schemas.
class Input(BaseModel):
input: str
chat_history: List[BaseMessage] = Field(
...,
extra={"widget": {"type": "chat", "input": "location"}},
)
class Output(BaseModel):
output: str
add_routes(
app,
agent_executor.with_types(input_type=Input, output_type=Output),
path="/agent",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
Convert the previous ipynb code with the above code into a Python file serve-demo.py, and then execute:
python serve-demo.py
Access http://localhost:8000/docs:
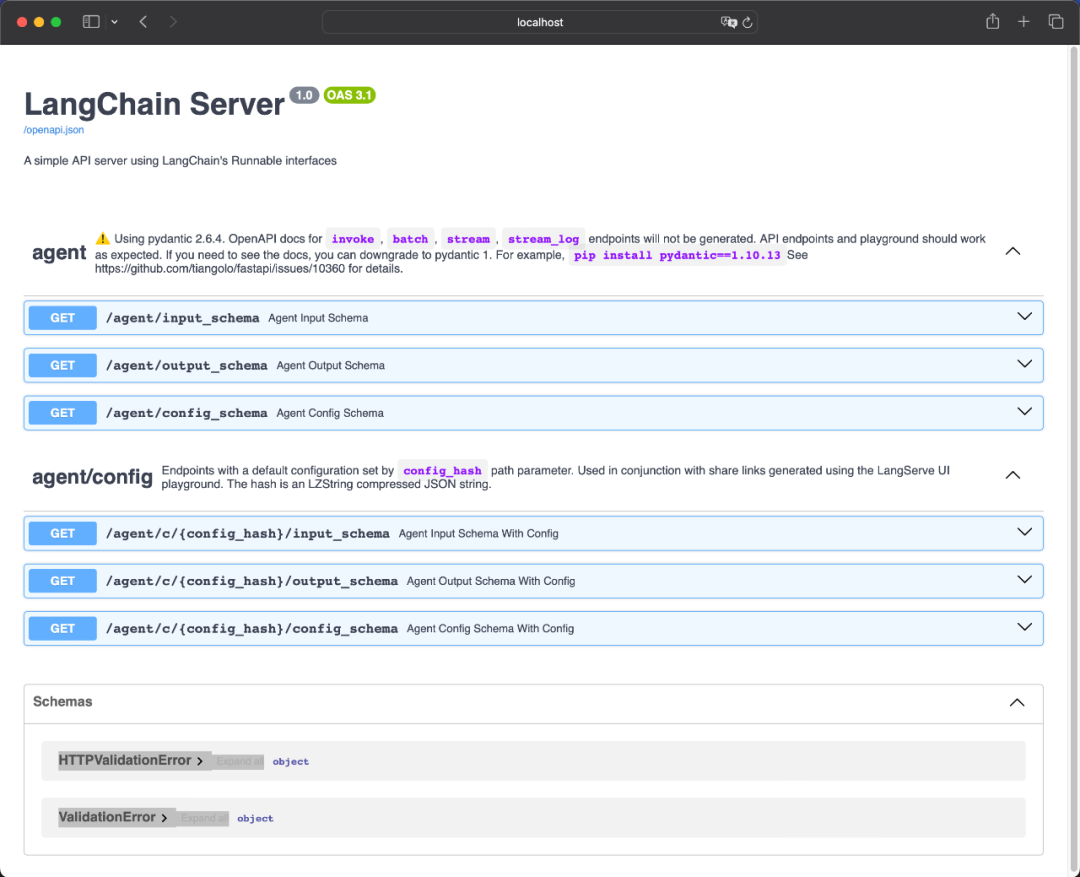 image-20240315215041518
image-20240315215041518
13 Link Tracing
You need to apply for a LangChain API key at: https://smith.langchain.com/ to register.
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY=os.getenv('LANGCHAIN_API_KEY')

Some Personal Thoughts
Many companies are currently racing in AI, with various AI platforms and tools emerging one after another. Having tried various overseas and domestic products, text-to-text, text-to-image, image-to-text, etc., while experiencing these products and tools, they are indeed very powerful. As a programmer learning AIGC knowledge, I often have these thoughts:
-
Can I catch up with the trend of the times? The current tools, frameworks, and product iterations are very fast, and many fundamentals have not been systematically learned, making the learning threshold relatively high, and I have not participated in mature and implemented projects. -
How much can my current high-cognition work improve? I have indeed gained significant improvement in information retrieval, but whether I can explore more scenarios that match my skills in the future. -
How to evaluate the correctness of AI-generated results at an enterprise level with high quality? For example, the generated SQL and PlantUML still require manual adjustments; the similarity of natural language responses inherently has a lot of uncertainty.
In the process of continuously learning knowledge in related fields, I hope to gradually clarify these doubts.