Figure: Agentic RAG (Image from the author)
1. Introduction
Given the way technology evolves, we have become accustomed to thinking about certain solution constructs from the perspective of specific tools and platforms. For example, Retrieval-Augmented Generation (RAG) is ubiquitous in today’s Gen AI world. Given its emergence in the Gen AI era, we mainly view RAG as a pipeline for processing unstructured data/documents. However, in reality, RAG solution constructs can be effectively applied to retrieve structured data from databases and data warehouses using SQL, and then enhance prompts with the retrieved structured data.
The above observation has been prompted by discussions around recent Gen AI use cases and their solutions, and we are increasingly seeing the need to query SQL and document repositories in an integrated manner – integrating the respective query pipelines.
For instance, let’s consider the followingmarketing data:
- Profile data of customers, products, and sales agents stored in documents,
- Transaction data of orders placed by customers (including the involved sales agents) stored in SQL DB.
In light of this, we need to gain insights from both profile (unstructured) and transaction (structured) data repositories to answer the following query:
“Provide a detailed summary of the top 3 sales agents for product X in 2023.”
Needless to say, resolving the query above requires a sequential breakdown of the user query:
- First, retrieve the top 3 sales agents for product X from the SQL DB, and then
- Retrieve their respective profiles from the profile document repository, and then
- Generate a summary based on the retrieved profiles and sales data.
In subsequent articles, we outline the solution workflow for the above scenario
Utilizing the Agentic AI framework for query decomposition,
followed by SQL and document query agents querying the underlying SQL and document repositories respectively.
Finally, the RAG pipeline is completed by adding the retrieved structured and/or unstructured data to the original query (prompt) – thereby generating contextual responses.
2. Using RAG to Query Document Repositories
We first demonstrate how to build a RAG pipeline over unstructured data/documents. Along with fine-tuning, RAG constitutes one of the main mechanisms for “tuning” pre-trained large language models (LLMs) using enterprise data to make them more contextual – reducing hallucinations during the process (as shown in the Gen AI lifecycle stages in Figure 1).
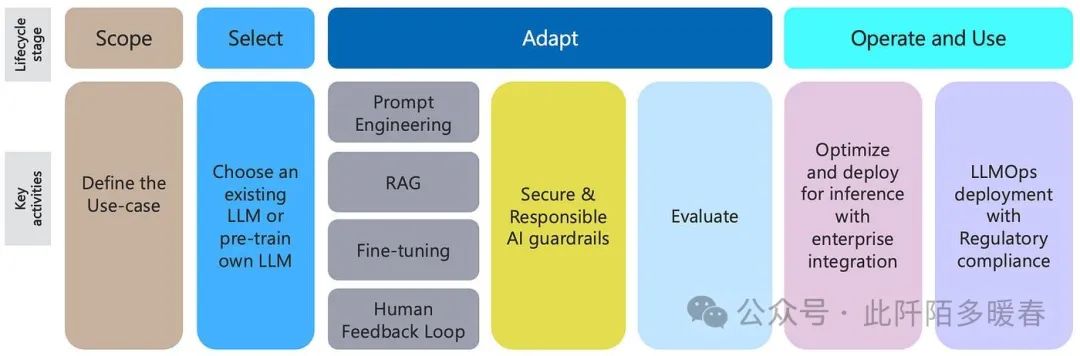
Figure 1: Stages of the AI Lifecycle (Image from the author)
Given a user query, the RAG pipeline actually consists of the following 3 stages (Figure 2):
- Retrieve: Converting the user query into embeddings (vector format) to compare its similarity scores (search) with other contents.
- Augment: Retrieving search results/context from the vector store, which is kept updated and synchronized with the underlying document repository.
- Generate: Generating contextualized responses by making the retrieved blocks a part of the prompt template, which provides additional context to the LLM on how to answer the query.
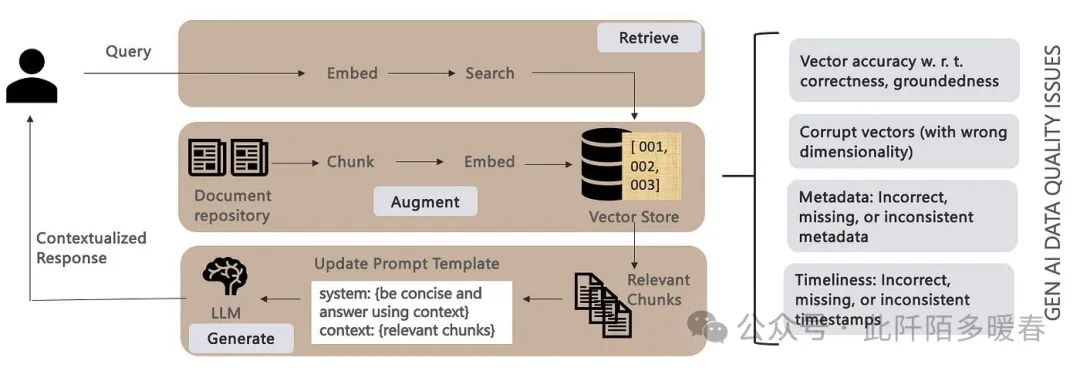
Figure 2: RAG Process Highlighting Data Quality Issues (Image from the author)
For example, Snowflake provides Cortex Search as a managed service to implement the retrieval and augmentation parts of the RAG pipeline. Thus, it can be used in conjunction with the Cortex LLM function to create a fully functional RAG pipeline using data in Snowflake as the underlying context repository (as shown in Figure 3).
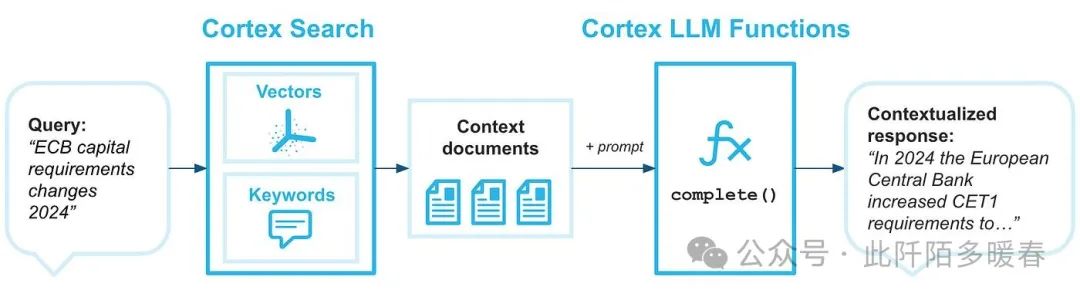
Figure 3: Implementing RAG Pipeline Using Cortex Search (Source: Snowflake)
2.1. Data Quality Issues in RAG
In this section, we focus on the potential (and needs to be addressed) data quality issues that can arise in this RAG pipeline (as shown in Figure 2). We first look at common data quality dimensions in today’s structured/SQL data world:
- Accuracy: How close is the data to the real-world situation?
- Completeness: Missing values, nulls, etc., in the data.
- Consistency: The same information is stored in different ways in different places.
- Timeliness: Freshness of the data captured in the form of timestamps.
Then we try to map them to the unstructured data world/vector databases.
In the Vector DB world, a collection corresponds to a SQL table, and each collection item can consist of the following parts: ID, vector (actual data captured in the form of an array of floating-point numbers), metadata (e.g., timestamps).
Accuracy: The accuracy of the data captured in the vector storage. Imagine AI writing news articles based on inaccurate information – it could end up producing incorrect information instead of valuable insights. We rely on the following two metrics to capture this:
- Correctness: Refers to the factual accuracy of the LLM’s responses,
- Groundedness: Refers to the relationship between the LLM’s responses and its underlying KB.
Research shows that the answer may be correct, but the basis is still incorrect.
Incorrect vectors and/or inconsistencies: Due to issues during the embedding process, some vectors may end up corrupted, incomplete, or generate vectors with differentdimensions. This could lead to confusing or disjointed outputs. For instance, if AI generates audio based on recordings of varying quality, the results may be noticeably uneven. In text generation, inconsistent grammar or tone in the data may lead to incoherent or disjointed content.
Missing data can be missing vectors or metadata. For instance, GenAI generating visual designs from incomplete datasets may output products lacking features.
Timeliness: If the documents in the vector storage (providing context related to the prompts in the RAG pipeline) are outdated, the GenAI system may produce irrelevant outputs. If a GenAI-enabled chatbot uses outdated policy documents when answering policy-related questions, it may provide inaccurate and misleading answers to the questions.
3. Text2SQL: Natural Language Queries for Structured Data
In this section, we extend the natural language query capability to structured data stored in SQL data repositories. This capability is calledText2SQL, also known as Conversational BI.
Cortex Analyst is the Text2SQL version of Cortex Search for querying structured data/SQL databases and data warehouses. Cortex Analyst is essentially an end-to-end text-to-answer solution as it also returns the generated SQL – providing the final query response. It is very easy to deploy (Figure 4): provided as an API, Snowflake also offers a simple Streamlit application that can be deployed in just a few lines of code.
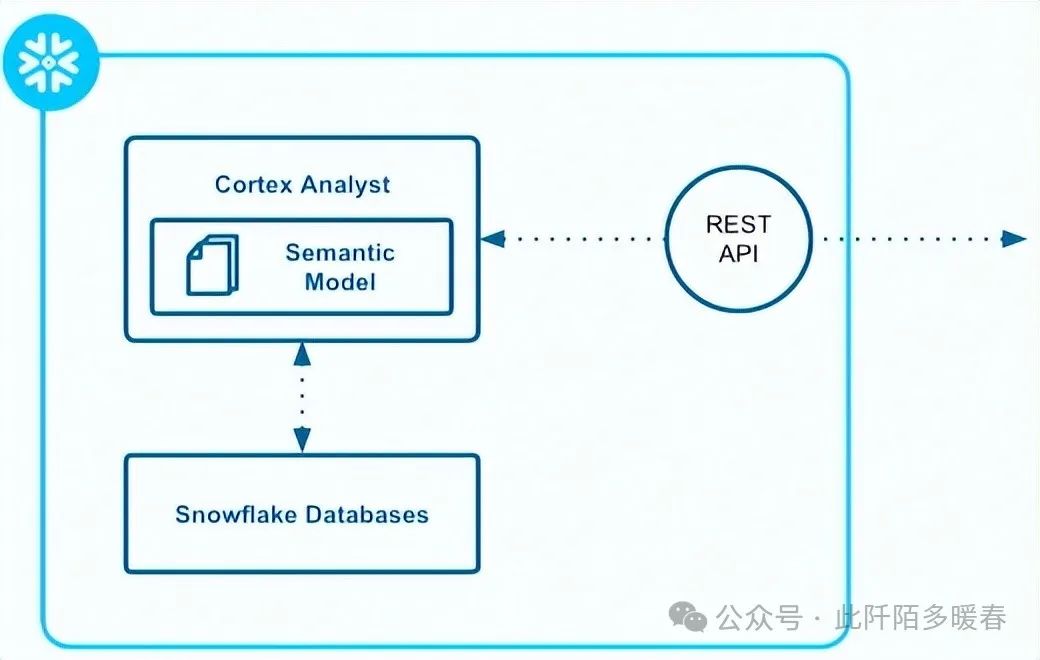
Figure 4: Cortex Analyst Architecture (Source: Snowflake)
Overall, it offers the following three differentiating features compared to other Text2SQL tools in the market:
- User intent validation and query explanation
- Lightweight semantic model
- Flexibility related to the underlying LLM
We all know that LLMs can produce hallucinations, so the first thing to do (and the best thing) is to first validate with the userthe system’s understanding of the given query before providing the final answer. Cortex Analyst achieves this by:
- Engaging in dialogue with the user, for any given query, it first shows the user its understanding of that query and explains how it generates the SQL query.
- Additionally, if ambiguities arise, it also provides suggestions to make the query more specific.
Secondly, Cortex Analyst utilizessemantic modelsto address the previously highlighted metadata mapping issues of the data repositories.
The semantic model is the bridge that maps the domain or business-specific terms used by the user to the database schema.
These additional semantic details (e.g., more descriptive names or synonyms) allow Cortex Analyst to answer natural language queries more reliably.
Finally, Cortex Analyst offers great flexibility in selecting the underlying LLM. By default, Cortex Analyst utilizesSnowflake-hosted Cortex LLMs, which have been extensively fine-tuned for text-to-SQL generation tasks and are among the most powerful LLMs available today. However, explicit choices can allow Cortex Analyst to use the latest OpenAI GPT models hosted by Microsoft Azure, as well as models hosted by Snowflake. At runtime, Cortex Analyst will choose the best model combination to ensure the highest accuracy and performance for each query.
4. RAG Agents Integrating Queries on SQL and Document Repositories
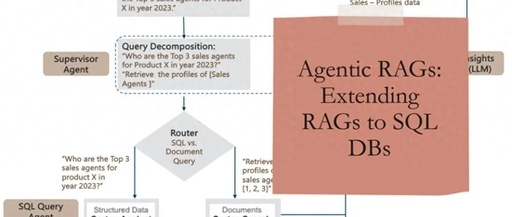
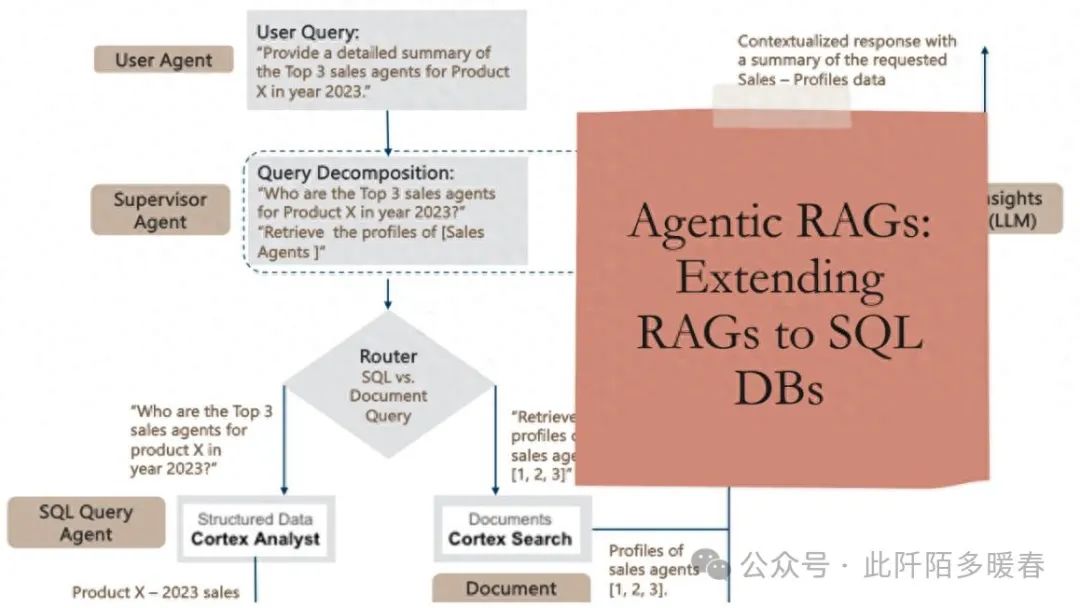
In this section, we will bring everything together by outlining the Agentic AI framework to build RAG pipelines that seamlessly handle structured and unstructured data stored in Snowflake. The reference architecture for this RAG agent is shown in Figure 5.
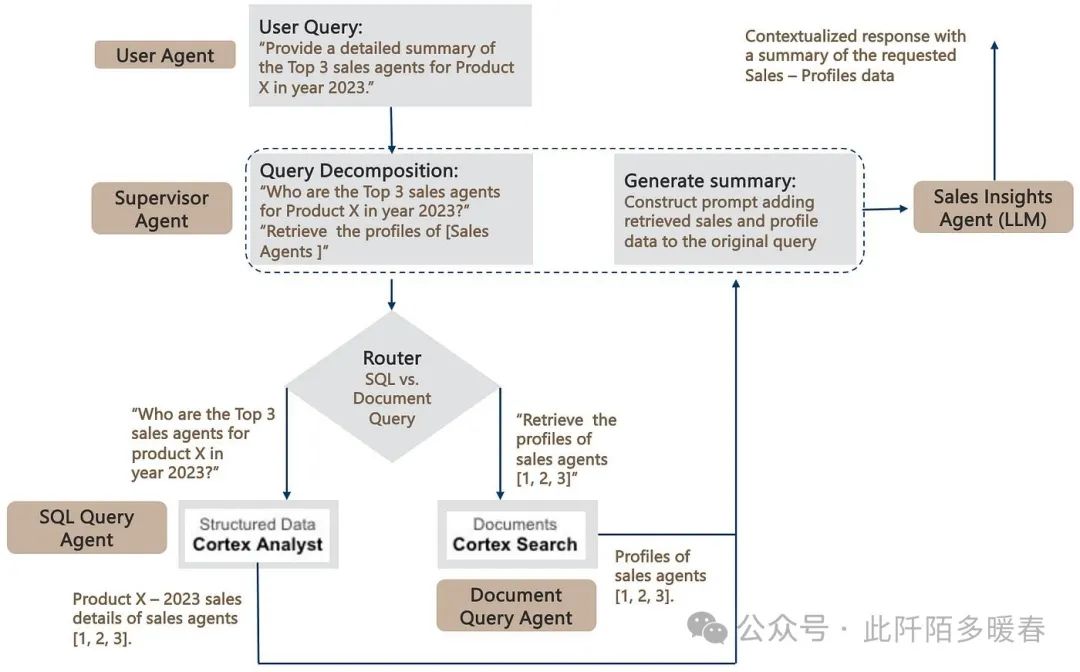
Figure 5: Reference Architecture for RAG Agents Querying SQL and Document Repositories (Image provided by the author)
We first focus onquery decomposition aspects. Given a user task, the goal of the AI agent is to identify (compose) agents (agent groups) capable of executing the given task. This is achieved by leveraging LLMs as reasoning engines that can decompose tasks (in this case, queries) into subtasks, orchestrated by an orchestration engine (e.g., LangGraph) that manages the execution of the individual agents.
The supervisory agent is responsible for coordinating the overall execution, routing the subqueries to the respective agents through if-then-else logic. Thus, the router is primarily used to route (SQL and/or document-related) subqueries to the SQL and document query agents.
The SQL and document query agents are self-explanatory and utilize the respective Snowflake Cortex Analyst and Search components detailed earlier to query the underlying SQL and document repositories. Finally, to complete the RAG pipeline, the retrieved data is added to the original query/prompt – thereby generating contextual responses.
It is important to emphasize the need for a comprehensive evaluation strategy for such complex systems.
Both pipelines utilize LLMs, so the main difference lies in retrieving information from structured and unstructured repositories. For SQL data retrieval, the challenge lies in the Text2SQL conversion. Once the correct SQL script is determined, the retrieved SQL table outputs will not produce confusion (hallucinations). As mentioned in Section 3, using semantic models and manually validating the generated SQL can address this issue.
For unstructured data/documents, we certainly need to evaluate based on the hallucinations of the outputs (generated text). Therefore, we apply an RAGAS-type evaluation strategy here. In our case, in the scenarios presented in the article, the two steps/agents happen to be sequential: retrieving SQL sales data and then summarizing the profiles of top sales agents. Therefore, we can evaluate them separately.
In summary, the boundaries between data and AI platforms are becoming increasingly blurred, and companies like AWS and Snowflakeare making it easier to leverage Gen AI/LLM capabilities to process securely and controlled data stored in Snowflake..