
In the previous article, we primarily used SimpleDirectoryReader to process documents. Today, we will explore how to use LlamaParse to handle more complex PDF documents, achieving more accurate document parsing and information extraction.
1. Introduction to LlamaParse
LlamaParse is a tool specifically designed for handling complex documents, with the following features:
-
Accurate layout recognition -
Table and chart extraction -
Format preservation -
Support for multiple output formats
Online experience address: https://cloud.llamaindex.ai/
2. Environment Configuration
First, we need to install the necessary dependencies and configure the environment:
import nest_asyncio
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
# Apply nest_asyncio to support asynchronous operations
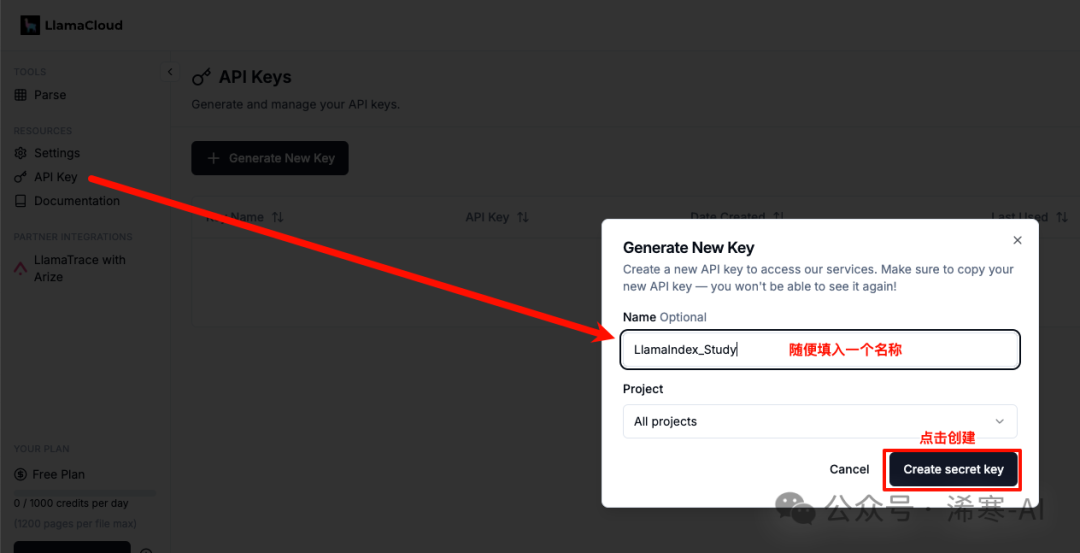
nest_asyncio.apply()Then, apply for an API Key on the LlamaCloud website https://cloud.llamaindex.ai/
3. Basic Implementation
3.1 Initializing LlamaParse
parser = LlamaParse(
api_key="your-llama-parse-api-key", # Can be set via environment variables
result_type="markdown", # Supports "markdown" and "text"
verbose=True # Enable detailed output
)3.2 Configuring Document Reader
# Set file extractor, specify PDF files to be parsed by LlamaParse
file_extractor = {".pdf": parser}
# Use SimpleDirectoryReader to read documents from the ./pdf directory
documents = SimpleDirectoryReader(
"./pdf",
file_extractor=file_extractor
).load_data()3.3 Creating Index and Querying
# Create vector storage index
index = VectorStoreIndex.from_documents(documents)
# Persist the index to the storage directory
index.storage_context.persist(persist_dir="storage")
# Create query engine
query_engine = index.as_query_engine()
# Execute query
response = query_engine.query("Your question")
print(response)4. Using Advanced Features
4.1 Custom Parsing Configuration
-
Performance-related configurations
parser = LlamaParse(
num_workers=4, # Number of worker threads for API requests (between 1-9)
check_interval=1, # Interval time to check parsing progress (seconds)
max_timeout=2000, # Maximum wait timeout (seconds)
show_progress=True, # Show progress when parsing multiple files
verbose=True, # Display detailed parsing process information
)-
Parsing control configurations
parser = LlamaParse(
parsing_instruction="", # Custom parsing instruction
skip_diagonal_text=False, # Whether to ignore diagonal text
fast_mode=False, # Fast mode (skip OCR and table/title reconstruction)
do_not_unroll_columns=False, # Keep the original column layout of the document
split_by_page=True, # Whether to split the document by page
)-
Page formatting configurations
parser = LlamaParse(
page_separator="\n---\n", # Page separator
page_prefix=None, # Page prefix
page_suffix=None, # Page suffix
bounding_box=None, # Bounding box for text extraction
target_pages=None, # Specify target pages to extract
)-
Cache control configurations
parser = LlamaParse(
invalidate_cache=False, # Whether to ignore cache and reprocess the document
do_not_cache=False, # Whether to not cache processing results
)-
GPT-4 and Multimodal Support
parser = LlamaParse(
gpt4o_mode=False, # Whether to use GPT-4 for text extraction
gpt4o_api_key=None, # GPT-4 API key
use_vendor_multimodal_model=False, # Whether to use vendor's multimodal model
vendor_multimodal_api_key=None, # Multimodal API key
vendor_multimodal_model_name=None, # Multimodal model name
take_screenshot=False, # Whether to take screenshots of each page
)5. Document Structure Handling
5.1 Table Extraction
from llama_parse import LlamaParse
# 1. Initialize the parser
parser = LlamaParse(
api_key="your-api-key",
verbose=True
)
# 2. Get JSON results
json_results = parser.get_json_result("your_file.pdf")
# 3. Process table data
for result in json_results:
for page in result['pages']:
# Get all tables on the page
tables = page.get('tables', [])
for table in tables:
print(f"Page number: {page['page']}")
print(f"Table location: {table.get('bbox')}") # Table position on the page
print(f"Table data: {table.get('data')}") # Table content
5.2 Chart Processing
from llama_parse import LlamaParse
# 1. Initialize the parser
parser = LlamaParse(
api_key="your-api-key",
verbose=True
)
# 2. Get JSON results
json_results = parser.get_json_result("your_file.pdf")
# 3. Process table data
for result in json_results:
for page in result['pages']:
# Get all tables on the page
tables = page.get('tables', [])
for table in tables:
print(f"Page number: {page['page']}")
print(f"Table location: {table.get('bbox')}") # Table position on the page
print(f"Table data: {table.get('data')}") # Table content
Conclusion
Through this article, we learned:
-
The basic usage of LlamaParse -
Advanced features and configurations -
Document structure handling
We hope this series helps you better use LlamaIndex to build powerful AI applications!