Click the “AI Park” above, follow the public account, and choose to add “Star” or “Top”.
Author: Synced
Compiled by: ronghuaiyang
The attention mechanism is neither mysterious nor complex. It is simply an interface composed of parameters and mathematics. You can insert it anywhere appropriate, and it may enhance the results.
What is Attention?
Attention is a simple vector, usually obtained using the softmax function.
Before the attention mechanism, translation relied on reading a complete sentence and compressing all the information into a fixed-length vector. As you can imagine, representing a sentence composed of hundreds of words with a fixed-length vector will certainly lead to information loss and inadequate translation.
However, the attention mechanism somewhat solves this problem. It allows machine translation to look at all the information contained in the original sentence and then generate the correct word based on the current word being processed and the context. It even allows the translator to zoom in or out (focusing on local or global features).
The attention mechanism is not mysterious or complex. It is simply an interface composed of parameters and mathematics. You can insert it anywhere appropriate, and it may enhance the results.
Why Use Attention?
The core of probabilistic language models is to assign a probability to a sentence based on the Markov assumption. Since sentences consist of different numbers of words, it naturally introduces RNNs to model the conditional probabilities between words.
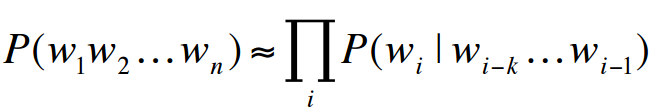
Vanilla RNNs (the most classic ones) often struggle during modeling:
-
Structural dilemma: In the real world, the lengths of outputs and inputs can be completely different, while ordinary RNNs can only handle fixed-length problems, which makes alignment difficult. Consider an EN-FR translation example: “he doesn’t like apples” → “Il n’aime pas les pommes”.
-
Mathematical nature: It has the problem of vanishing/exploding gradients, which means it is difficult to train when the sentence is long enough (up to 4 words).
Translation often requires arbitrary input and output lengths. To address the above shortcomings, a codec model is adopted, converting the basic RNN units into GRU or LSTM units and using ReLU instead of hyperbolic tangent activation. Here we use GRU units.
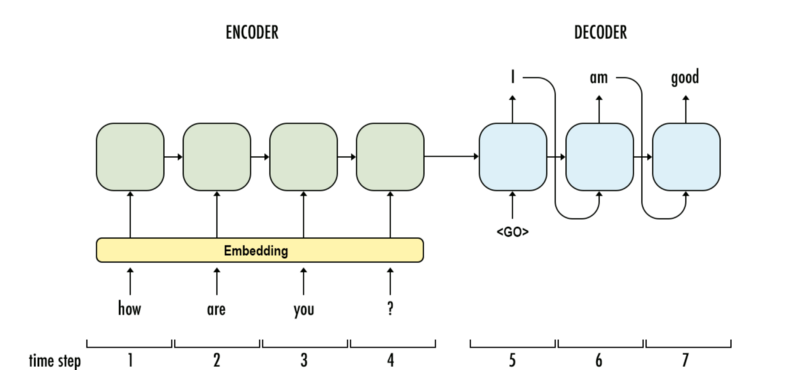
To improve computational efficiency, the embedding layer maps discrete words to dense vectors. The embedded word vectors are then sequentially input into the encoder, which is the GRU unit. What happens during the encoding process? Information flows from left to right, and each word vector learns not only based on the current input but also based on all previous words. When the statement is fully read, the encoder will generate an output and a hidden state at step 4 for further processing. For the encoding part, the decoder (also GRUs) retrieves the hidden state from the encoder and is trained by teacher forcing (using the output of the previous unit as the input pattern for the current input), then sequentially generates translated words.
This model can be applied to N-to-M sequences, which seems magical, but there is still a major flaw that remains unresolved: is one hidden state really enough?
Yes, this is where attention comes into play.
How Does Attention Work?
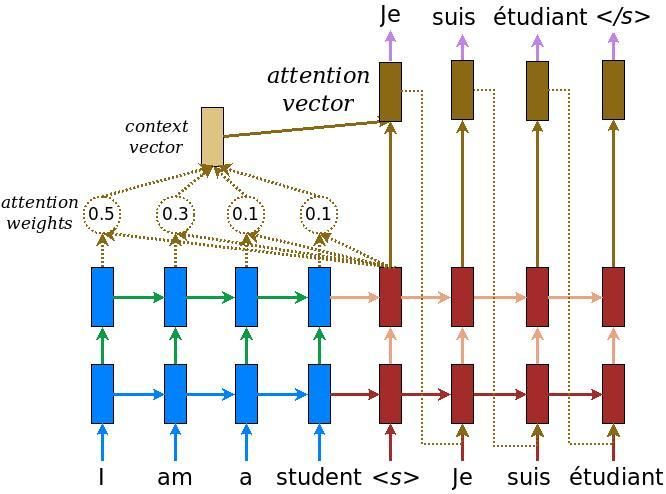
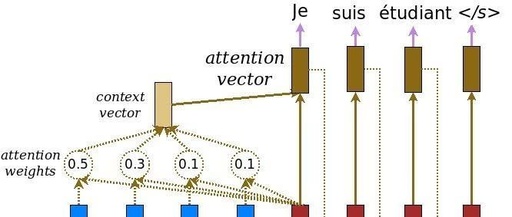
Similar to the basic codec architecture, this peculiar mechanism inserts a context vector between the encoder and the decoder. According to the above diagram, blue represents the encoder, and red represents the decoder. We can see that the context vector takes the output of all cells as input to calculate the probability distribution of the source language word that each decoder wants to generate. By utilizing this mechanism, the decoder can capture some global information rather than inferring based solely on one hidden state.
Constructing the context vector is quite simple. For a fixed target word, first, we loop through all states of the encoder to compare the target state and the source state, generating scores for each state in the encoder. Then we can use softmax to normalize all scores, resulting in a probability distribution conditioned on the target state. Finally, weights are introduced to make the context vector easy to train. That’s it. The mathematical calculations are as follows:
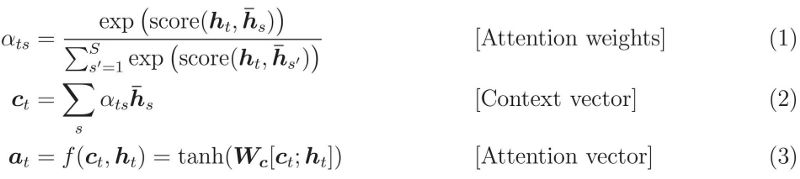
To understand the seemingly complex mathematics, we need to remember three key points:
-
During the decoding process, the context vector is calculated for each output word. We will obtain a two-dimensional matrix whose size is the number of target words multiplied by the number of source words. Equation (1) demonstrates how to calculate a single value given a target word and a set of source words.
-
Once the context vector is calculated, the attention vector can be computed using the context vector, the target word, and the attention function f.
-
We need a trainable attention mechanism. According to equation (4), both styles provide trainable weights (W in Luong’s, W1 and W2 in Bahdanau’s). Thus, different styles may lead to different performances.
Conclusion
We hope you understand why attention is one of the hottest topics today, and most importantly, the fundamental mathematics behind attention. We hope you implement your own attention layer. There are many variants in cutting-edge research, which basically differ in the choice of score functions and attention functions, or the difference lies in the choice of soft attention and hard attention (whether it is differentiable). But the basic concepts are the same.

Original English text:https://medium.com/syncedreview/a-brief-overview-of-attention-mechanism-13c578ba9129

Related Articles Links
1. Understanding Attention Mechanism in RNNs Using Detailed Examples
2. Introduction to Sequence Models: RNN, Bidirectional RNN, LSTM, GRU, with Illustrations
3. Animated Explanation of RNN, LSTM, and GRU, Nothing More Intuitive!

Please long press or scan the QR code to follow this public account