

I decided to write a long-overdue article to provide a simple introduction for those who want to understand machine learning. It won’t delve into advanced principles but will discuss real-world problems and practical solutions in simple language. Whether you are a programmer or a manager, you will be able to understand.
So let’s get started!
Why Do We Want Machines to Learn?
Here comes Billy, who wants to buy a car and needs to calculate how much to save each month to afford it. After browsing dozens of ads online, he learns that a new car costs around $20,000, a one-year-old used car is $19,000, a two-year-old car is $18,000, and so on.
As a smart analyst, Billy discovers a pattern: the price of a car depends on its age, decreasing by $1,000 for each additional year, but it won’t go below $10,000.
In machine learning terms, Billy has invented “regression” — predicting a value (price) based on known historical data. When people try to estimate a reasonable price for a used iPhone on eBay or calculate how many ribs to prepare for a barbecue, they are using a method similar to Billy’s — is it 200g per person? 500?
Yes, it would be great if there were a simple formula to solve all the world’s problems — especially for barbecue parties — but unfortunately, that’s not possible.
Let’s return to the car-buying scenario. Now the question is, besides age, there are different production dates, dozens of accessories, technical conditions, seasonal demand fluctuations… who knows what other hidden factors there are… Ordinary Billy cannot consider all this data when calculating the price, and neither can I.
People are both lazy and foolish — we need robots to help them with math. Therefore, we adopt a computational approach — provide the machine with some data and let it discover all the potential patterns related to price.
Finally, it works! The most exciting part is that compared to a human carefully analyzing all the dependent factors, the machine does it much better.
Thus, machine learning was born.
The Three Components of Machine Learning
Setting aside all the nonsense related to artificial intelligence (AI), the only goal of machine learning is to predict outcomes based on input data, that’s it. All machine learning tasks can be represented this way; otherwise, it wouldn’t be a machine learning problem from the start.
The more diverse the samples are, the easier it is to find related patterns and predict outcomes. Therefore, we need three components to train the machine:
Data
Want to detect spam? Get samples of spam messages. Want to predict stock prices? Find historical price information. Want to identify user preferences? Analyze their activity records on Facebook (no, Mark, stop collecting data — that’s enough). The more diverse the data, the better the outcome. For a machine that is working hard, at least hundreds of thousands of lines of data are needed.
There are two main ways to obtain data — manually or automatically. Manually collected data tends to be less mixed with errors but takes more time — usually costing more. Automated methods are relatively cheap; you can collect all available data (hopefully the data quality is good).
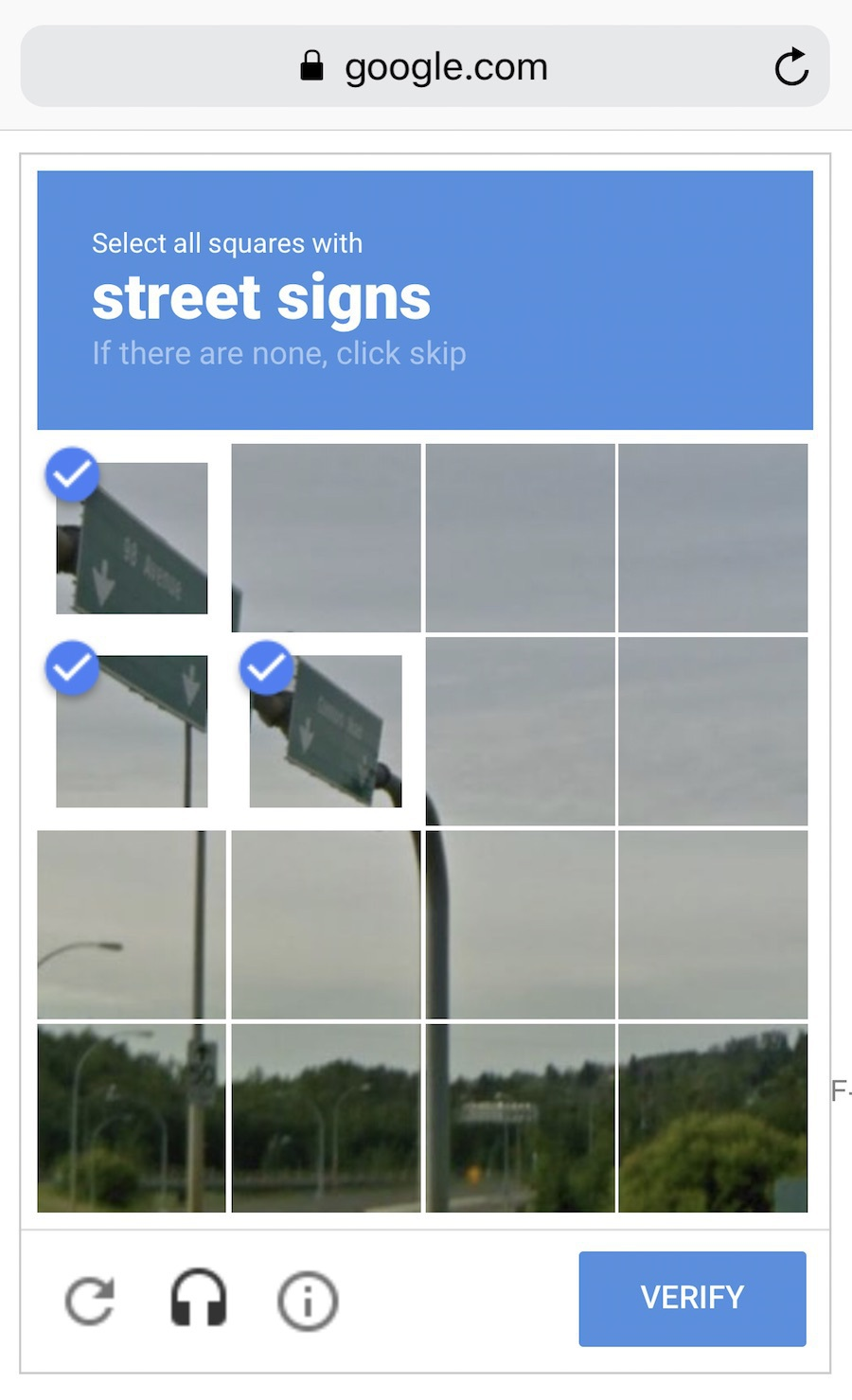
Some smart companies like Google utilize their users to label data for free. Remember ReCaptcha (human verification) forcing you to “select all the road signs”? That’s how they gather data, free labor! Well done. If I were them, I would show those verification images more frequently, but wait…
Good datasets are really hard to obtain; they are so important that some companies may even open their algorithms but rarely disclose their datasets.
Features
Also known as “parameters” or “variables,” such as the mileage of a car, user gender, stock prices, word frequency in documents, etc. In other words, these are the factors that the machine needs to consider.
If the data is stored in tabular form, features correspond to column names, which is relatively simple. But what if it’s 100GB of cat images? We can’t treat every pixel as a feature. That’s why selecting appropriate features often takes more time than other steps in machine learning, and feature selection is a major source of error. Human subjective bias can lead people to choose features they like or feel are “more important” — this should be avoided.
Algorithms
The most obvious part. Any problem can be solved in different ways. The method you choose will affect the final model’s accuracy, performance, and size. One thing to note: if the data quality is poor, even the best algorithm won’t help. This is known as “garbage in, garbage out (GIGO).” Therefore, before spending a lot of effort on accuracy, more data should be acquired.
Learning Vs. Intelligence
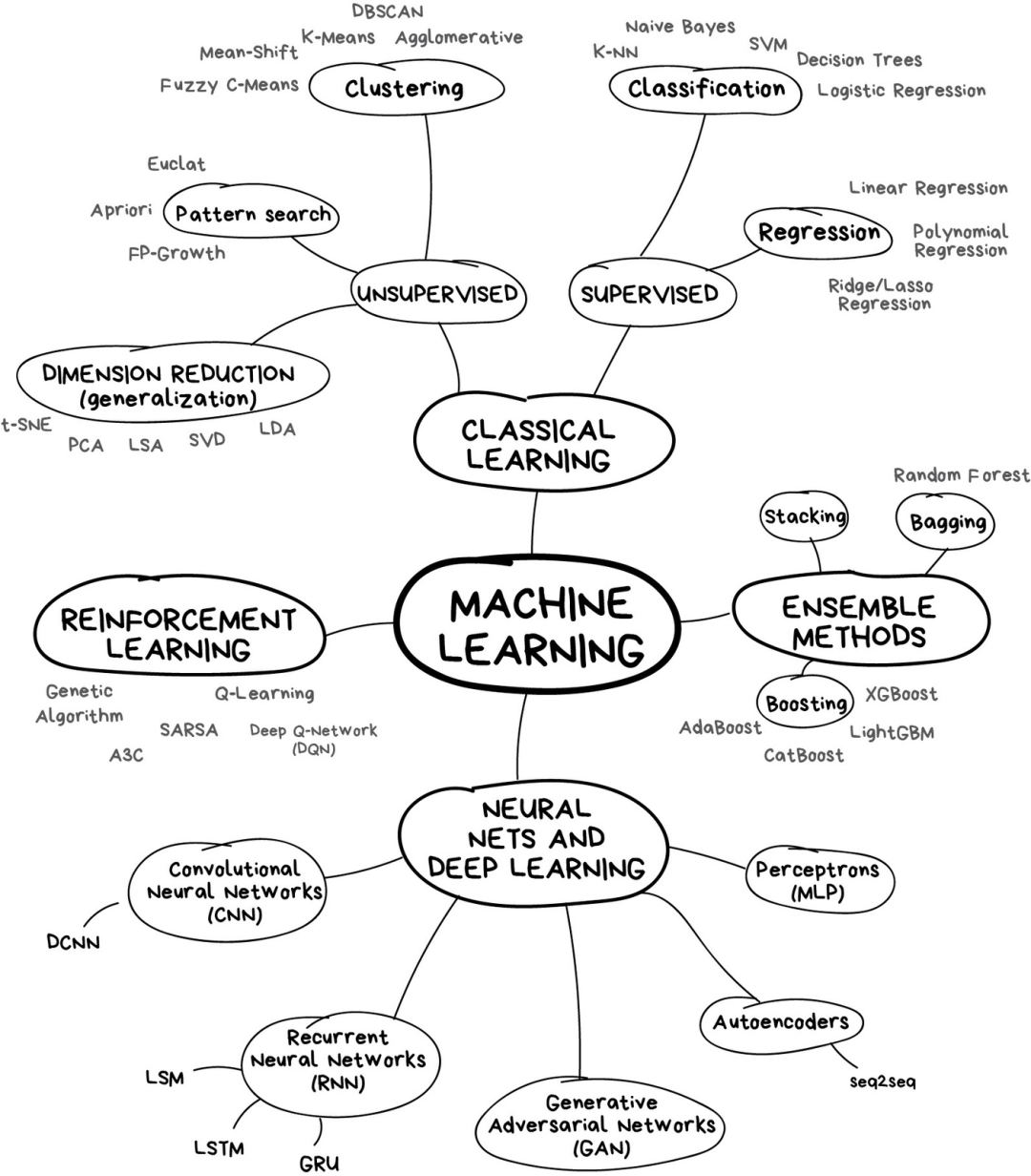
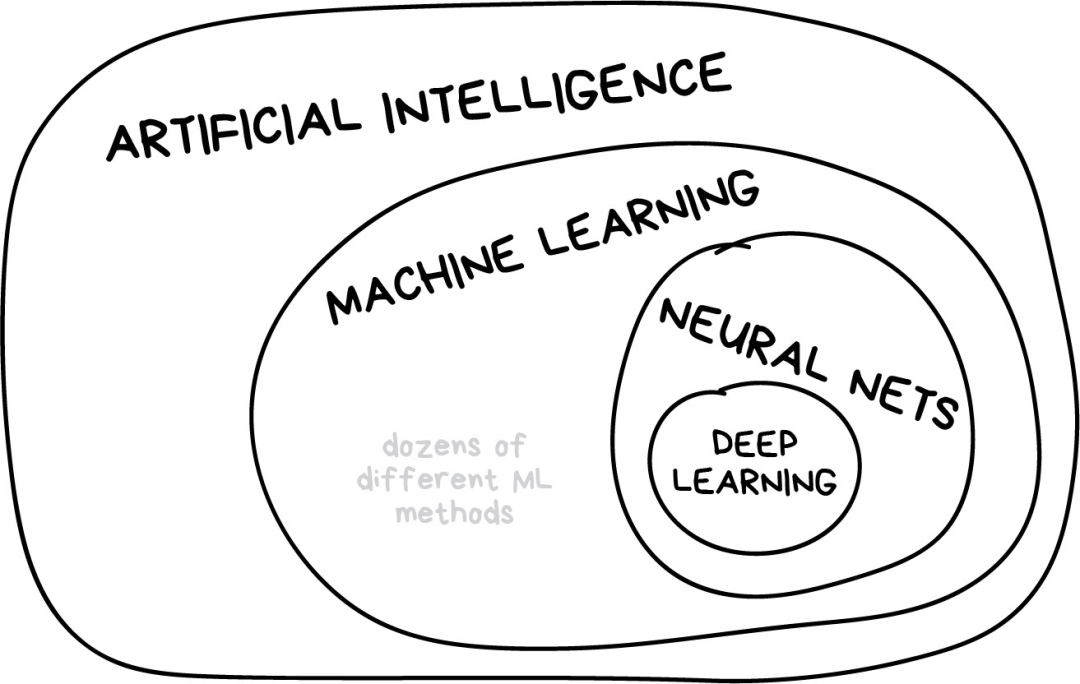
I once saw an article titled “Will Neural Networks Replace Machine Learning?” on some popular media sites. These media people always strangely exaggerate techniques like linear regression as “artificial intelligence,” almost calling it “Skynet.” The following diagram shows the relationship between several easily confused concepts.
-
“Artificial Intelligence” is the name of the entire discipline, similar to “biology” or “chemistry.” -
“Machine Learning” is an important part of “artificial intelligence,” but not the only part. -
“Neural Networks” is a branch method of machine learning that is quite popular, but there are other branches under the machine learning family. -
“Deep Learning” is a modern approach to building, training, and using neural networks. Essentially, it is a new architecture. In current practice, no one distinguishes between deep learning and “ordinary networks,” as the libraries called upon when using them are the same. To avoid looking foolish, you’d better specify the type of network directly and avoid using buzzwords.
The general principle is to compare things at the same level. That’s why “neural networks will replace machine learning” sounds like “wheels will replace cars.” Dear media, this will significantly damage your reputation.
| What Machines Can Do | What Machines Cannot Do |
|---|---|
| Predict | Create new things |
| Remember | Become smart quickly |
| Copy | Go beyond task scope |
| Select the best option | Eliminate all of humanity |
The Landscape of Machine Learning
If you’re too lazy to read long texts, the following image can help you gain some understanding.
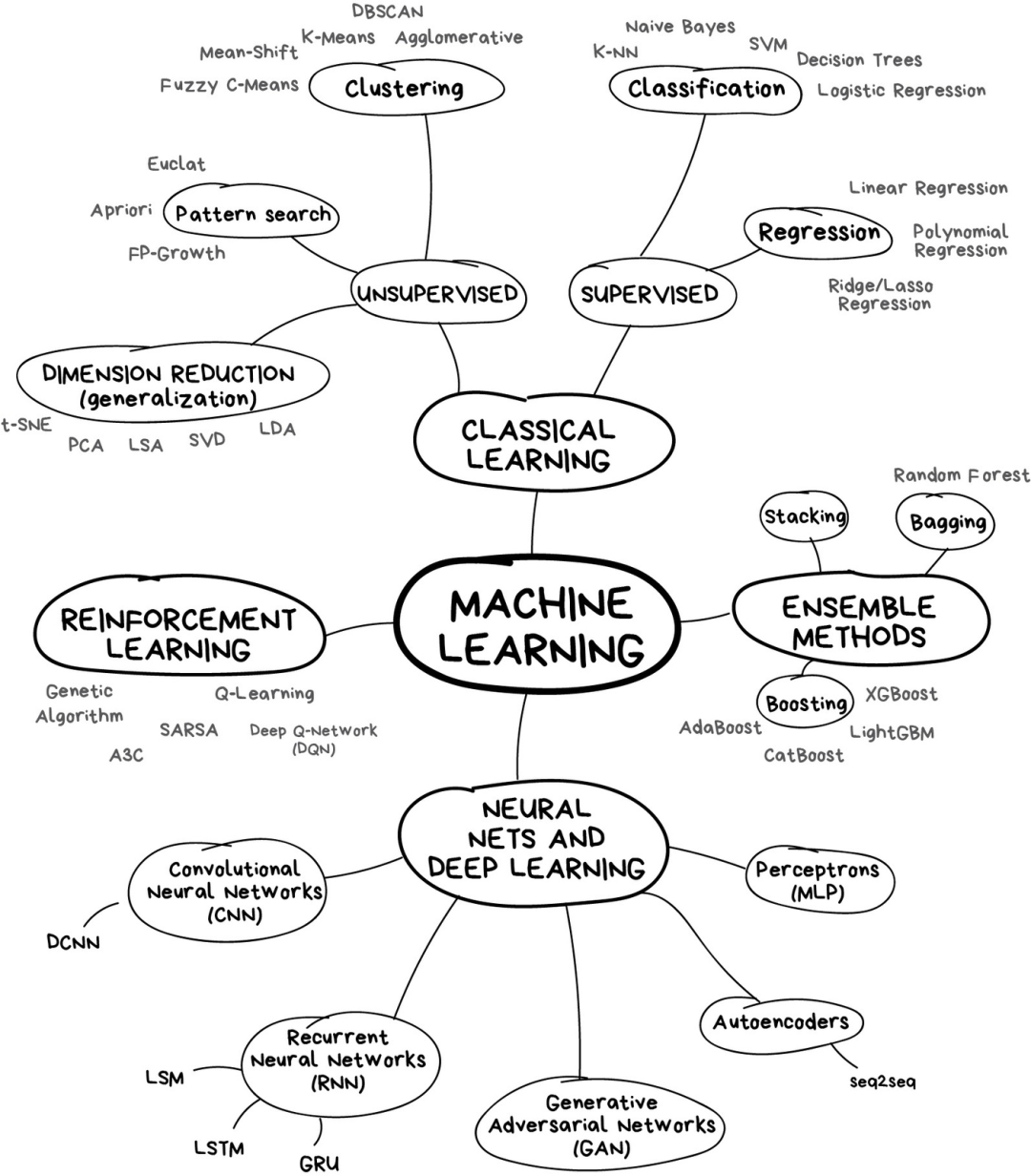
In the world of machine learning, there is never a single way to solve a problem — it’s important to remember this — because you will always find several algorithms that can be used to solve a particular problem, and you need to choose the one that fits best. Of course, all problems can be handled with “neural networks,” but who will bear the hardware costs behind the computing power?
Let’s start with some basic overviews. Currently, machine learning mainly has four directions.
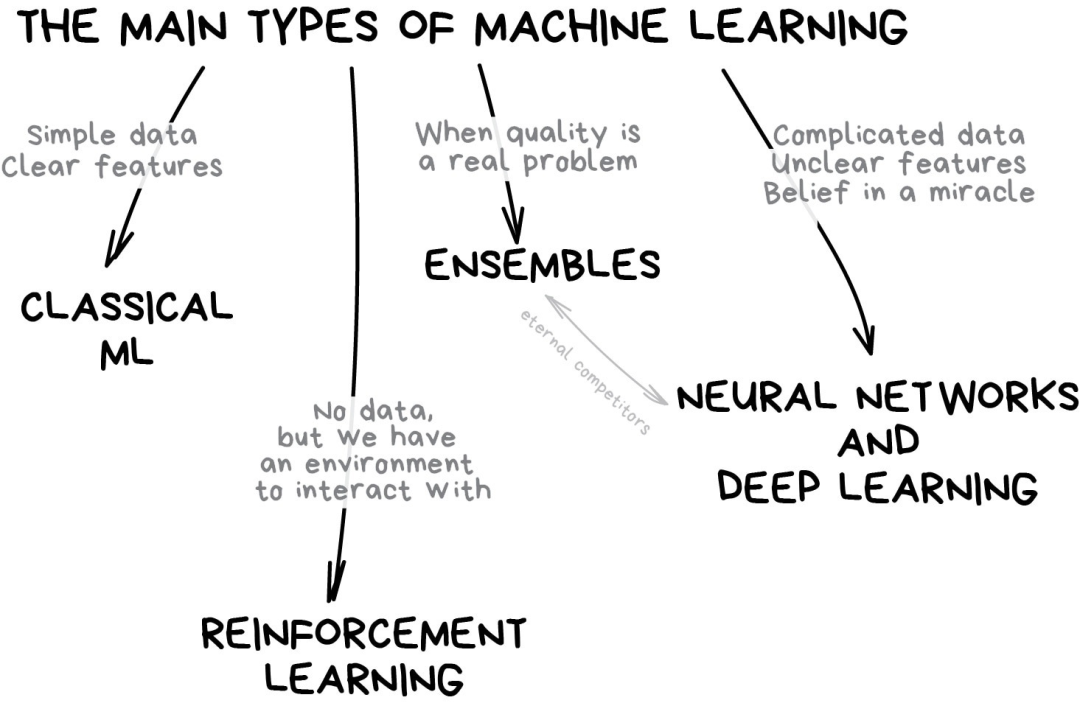
Part 1Classic Machine Learning Algorithms
Classic machine learning algorithms originate from pure statistics in the 1950s. Statisticians addressed formal math problems such as finding patterns in numbers, estimating distances between data points, and calculating vector directions.
Today, half of the internet is researching these algorithms. When you see a column of “continue reading” articles, or when you find your bank card locked at some remote gas station, it’s likely the work of one of these little guys.
Large tech companies are staunch advocates of neural networks. The reason is obvious; for these large enterprises, a 2% accuracy improvement means an additional $2 billion in revenue. However, when the business scale is small, it’s not that important. I heard of a team that spent a year developing a new recommendation algorithm for their e-commerce site, only to find that 99% of the site’s traffic came from search engines — their algorithm was useless since most users wouldn’t even open the homepage.
Although classic algorithms are widely used, their principles are quite simple, and you can easily explain them to a toddler. They are like basic arithmetic — we use them every day without even thinking.
1.1 Supervised Learning
Classic machine learning is usually divided into two categories: Supervised Learning and Unsupervised Learning.
In “supervised learning,” there is a “supervisor” or “teacher” who provides the machine with all the answers to assist in learning, such as whether the image is of a cat or a dog. The “teacher” has already completed the dataset labeling — marking it as “cat” or “dog,” and the machine uses these example data to learn to distinguish between cats and dogs.
Unsupervised learning means the machine completes the task of distinguishing who is who among a pile of animal images on its own. The data is not pre-labeled, and there is no “teacher,” so the machine has to find all possible patterns by itself. This will be discussed later.
It’s clear that when a “teacher” is present, the machine learns faster, so supervised learning is more commonly used in real life. Supervised learning is divided into two categories:
-
Classification (classification), predicting the category to which an object belongs; -
Regression (regression), predicting a specific point on a number line;
Classification
“Classifying objects based on a known attribute, such as classifying socks by color, documents by language, and music by style.”
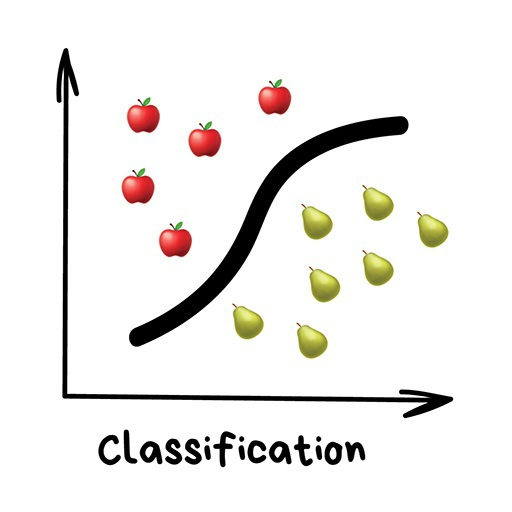
Classification algorithms are commonly used for:
-
Filtering spam; -
Language detection; -
Finding similar documents; -
Sentiment analysis; -
Recognizing handwritten letters or numbers; -
Fraud detection;
Common algorithms include:
-
Naive Bayes -
Decision Tree -
Logistic Regression -
K-Nearest Neighbours -
Support Vector Machine
Machine learning mainly addresses “classification” problems. This machine is like a toddler learning to classify toys: this is a “robot,” this is a “car,” this is a “machine-car”… uh, wait, wrong! Wrong!
In classification tasks, you need a “teacher.” The data must be pre-labeled so the machine can learn to classify based on these labels. Everything can be classified — users can be classified based on interests, articles can be classified by language and topic (which is important for search engines), music can be classified by type (Spotify playlists), and your emails are no exception.
The Naive Bayes algorithm is widely used in spam filtering. The machine counts the frequency of words like “Viagra” appearing in both spam and normal emails, then applies Bayes’ theorem multiplied by their respective probabilities and sums the results — ha, the machine has completed its learning.
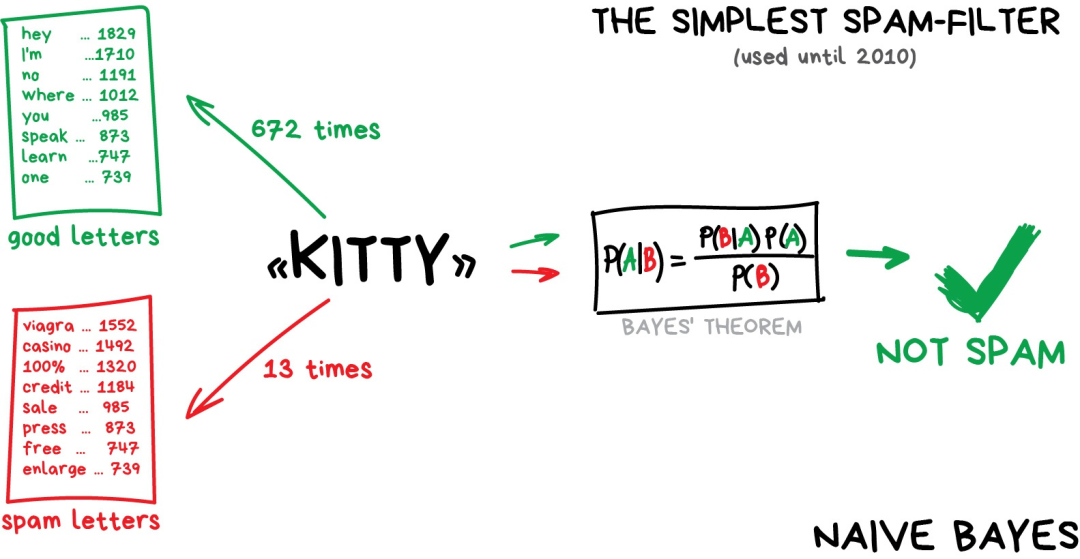
Later, spammers learned how to counteract Bayesian filters — by adding many “good” words at the end of the email content — this method is ironically referred to as “Bayesian poisoning.” Naive Bayes is recorded in history as the most elegant and first practical algorithm, but now there are other algorithms to handle spam filtering.
Another example of a classification algorithm. Suppose you need to borrow some money; how does the bank know if you will repay it in the future? They can’t be sure. But the bank has many historical borrower profiles with data such as “age,” “education level,” “occupation,” “salary,” and — most importantly — “whether they repaid.”
Using this data, we can train the machine to find patterns and derive answers. Finding answers is not the problem; the problem is that banks cannot blindly trust the answers given by the machine. What if the system fails, gets hacked, or a drunken graduate just patched the system in an emergency?
To deal with this issue, we need to use decision trees (Decision Trees), where all data is automatically divided into “yes/no” questions — for example, “Does the borrower’s income exceed $128.12?” — this sounds a bit inhumane. However, the machine generates such questions to optimally partition the data at each step.
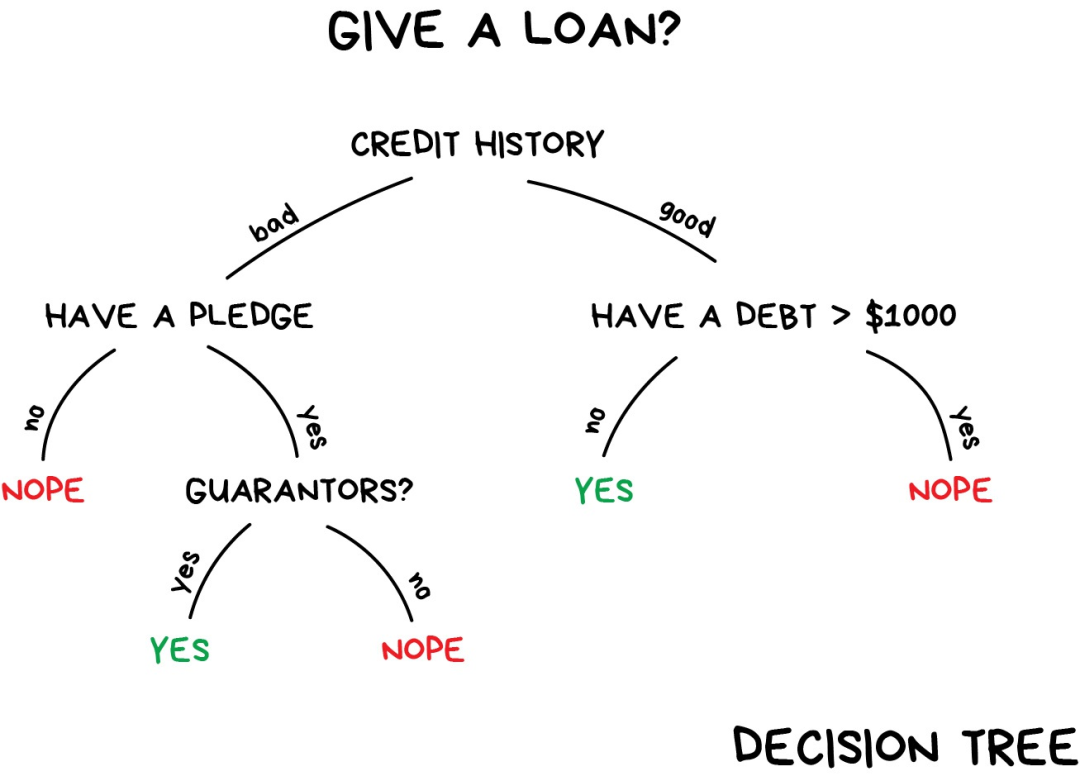
This is how the “tree” is formed. The higher the branches (closer to the root node), the broader the range of questions. All analysts can accept this approach and provide explanations afterward, even if they do not understand how the algorithm works; they can easily explain the results (typical analyst!).
Decision trees are widely used in high-responsibility scenarios: diagnostics, medicine, and finance.
The two most well-known decision tree algorithms are CART and C4.5.
Nowadays, pure decision tree algorithms are rarely used. However, they are the foundation of large systems, and the effects of ensemble decision trees can even outperform neural networks. We will discuss this later.
When you search on Google, it’s a bunch of clumsy “trees” helping you find answers. Search engines favor such algorithms because they run fast.
In theory, Support Vector Machines (SVM) should be the most popular classification method. Anything that exists can be classified using it: classifying plants in images by shape, classifying documents by category, etc.
The idea behind SVM is simple — it tries to draw two lines between data points and maximizes the distance between the two lines as much as possible. As illustrated below:
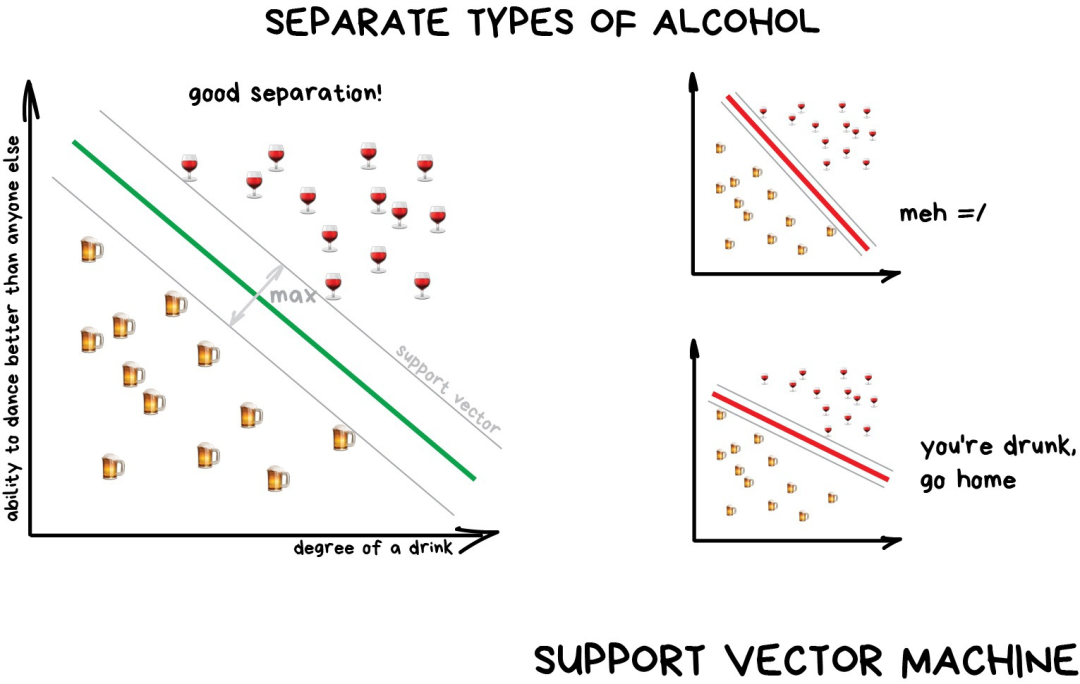
Classification algorithms have a very useful scenario — anomaly detection. If a certain feature cannot be assigned to any category, we mark it. This method is now used in medicine — in MRI (Magnetic Resonance Imaging), the computer will mark all suspicious areas or deviations within the detection range. The stock market uses it to detect traders’ abnormal behaviors to find insiders. When training the computer to distinguish what is correct, we also automatically teach it to recognize what is incorrect.
The rule of thumb states that the more complex the data, the more complex the algorithm. For text, numbers, and tabular data, I would choose classic methods to operate. These models are smaller, learn faster, and have clearer workflows. For images, videos, and other complex big data, I would definitely study neural networks.
Just five years ago, you could still find SVM-based face classifiers. Now, it’s easier to pick one from hundreds of pre-trained neural network models. However, spam filters haven’t changed; they are still written using SVM, and there’s no reason to change that. Even my website filters spam comments using SVM.
Regression
“Draw a line through these points, hmm~ this is machine learning”
Regression algorithms are currently used for:
-
Stock price prediction; -
Supply and sales analysis; -
Medical diagnosis; -
Calculating time series correlations;
-
Linear Regression -
Polynomial Regression
The “regression” algorithm is essentially also a “classification” algorithm, except it predicts a value instead of a category. For example, predicting the price of a car based on mileage, estimating the traffic volume at different times of the day, and forecasting the changes in supply as the company grows. Regression algorithms are the best choice for handling time-related tasks.
Regression algorithms are favored by finance or analytics professionals. It has even become a built-in feature of Excel, making the whole process very smooth — the machine simply tries to draw a line representing the average correlation. However, unlike a person with a pen and whiteboard, the machine accomplishes this by calculating the average distance between each point and the line with mathematical precision.
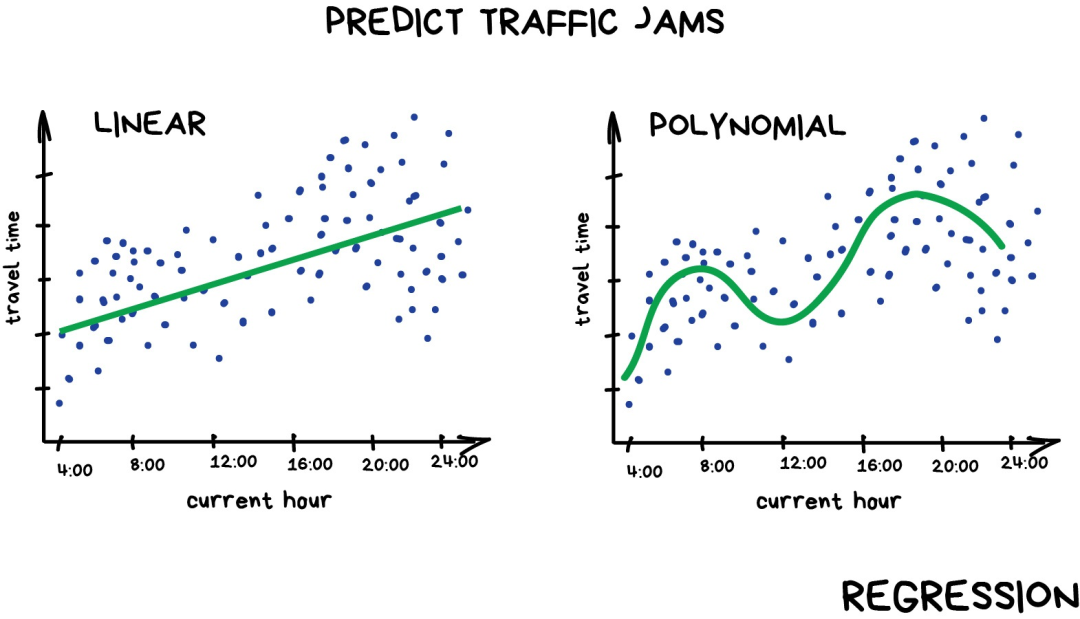
If the line drawn is straight, it’s “linear regression”; if the line is curved, it’s “polynomial regression.” They are the two main types of regression. Other types are less common. Don’t be fooled by Logistics regression being a “bad apple”; it’s a classification algorithm, not regression.
However, it’s okay to confuse “regression” and “classification.” Some classifiers can turn into regression after adjusting parameters. In addition to defining the category of an object, remember how close the object is to that category, which leads to the regression problem. If you want to dive deeper, you can read the article“Machine Learning for Humans”[1](highly recommended).
1.2 Unsupervised Learning
Unsupervised learning emerged slightly later than supervised learning — in the 1990s, these algorithms were relatively less used, sometimes simply because there were no other options.
Having labeled data is a luxury. Suppose I want to create a — let’s say “bus classifier,” do I have to personally go out and take millions of photos of those damn buses and label each image? No way, that would take my whole life; I still have many games on Steam to play.
In this case, let’s still have a little hope for capitalism; thanks to the social crowdsourcing mechanism, we can get millions of cheap labor and services. For example, Mechanical Turk[2], where a group of people is always ready to help you complete tasks for a reward of $0.05. That’s how things usually get done.
Or you can try using unsupervised learning. But I don’t recall any best practices regarding it. Unsupervised learning is usually used for exploratory data analysis, rather than as a primary algorithm. Those with Oxford degrees and special training feed a bunch of garbage to the machine and start observing: Are there any clusters? No. Can we see any connections? No. Well, next, you still want to work in data science, right?
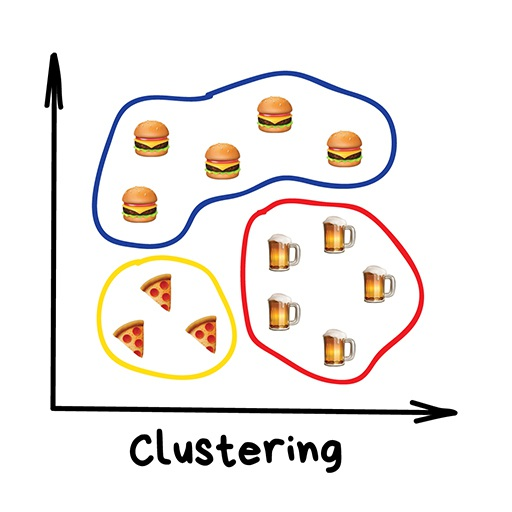
Clustering
“The machine will choose the best way to distinguish things based on some unknown features.”
Clustering algorithms are currently used for:
-
Market segmentation (customer types, loyalty); -
Merging nearby points on a map; -
Image compression; -
Analyzing and labeling new data; -
Detecting abnormal behavior;
-
K-Means Clustering -
Mean-Shift -
DBSCAN
Clustering is performed without pre-labeled categories. It’s like you can still classify socks even if you can’t remember all their colors. Clustering algorithms try to find similar things (based on certain features) and gather them into clusters. Objects with many similar features group together and are assigned to the same category. Some algorithms even allow setting the exact number of data points in each cluster.
Here’s a good example of clustering — markers on online maps. When you look for vegetarian restaurants nearby, the clustering engine groups them and displays them with numbered bubbles. If it didn’t do this, the browser would freeze — as it would be trying to plot all 300 vegetarian restaurants in that trendy city on the map.
Apple Photos and Google Photos use more complex clustering methods. By searching for faces in photos, they create albums of your friends. The application doesn’t know how many friends you have or what they look like but can still find common facial features. This is typical clustering.
Another common application scenario is image compression. When an image is saved in PNG format, you can set the colors to 32. This means the clustering algorithm must find all the “red” pixels, calculate the “average red,” and assign this average to all red pixels. Fewer colors mean smaller files — a good deal!
However, it becomes tricky with colors like . Is this green or blue? This is where the K-Means algorithm comes into play.
First, randomly select 32 color points as “cluster centers” from the colors, then label the remaining points according to the nearest cluster center. This gives us “star clusters” around the 32 color points. Next, we move the cluster centers to the center of the “star clusters” and repeat the process until the cluster centers stop moving.
Done. Exactly 32 stable clusters are formed.
Here’s a real-life example:
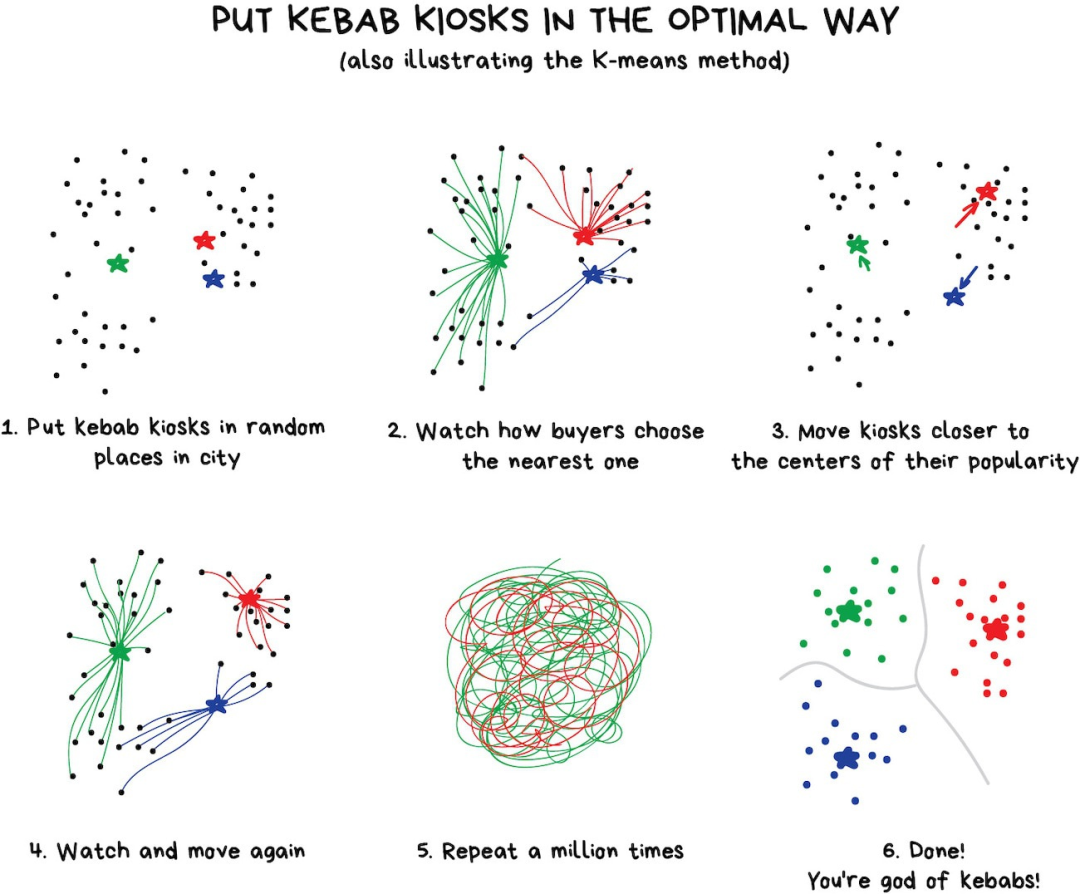
Finding cluster centers this way is convenient, but real-world clusters are not always circular. Suppose you are a geologist and need to find similar ores on a map. In this case, the shape of the clusters can be strange, even nested. You might not even know how many clusters there will be, 10? 100?
The K-means algorithm won’t work here, but the DBSCAN algorithm will. We treat data points like people in a square, asking any three people standing close to each other to hold hands. Next, we tell them to grab the hands of any reachable neighbors (the positions of people must not move during the process), repeating this until new neighbors join in. This way, we get the first cluster and repeat the process until everyone is assigned to a cluster. Done. One unexpected benefit: a person with no one holding hands — an anomaly.
The whole process looks cool.

If you’re interested in learning more about clustering algorithms, you can read this article“5 Clustering Algorithms Every Data Scientist Should Know”[3].
Like classification algorithms, clustering can also be used to detect anomalies. If a user logs in and performs abnormal operations? Let the machine temporarily disable their account and create a ticket for technical support to check what’s going on. Perhaps the person is a “robot.” We don’t even need to know what “normal behavior” looks like; we just need to pass the user’s behavior data to the model and let the machine decide whether the person is a “typical” user.
This method, while not as effective as classification algorithms, is still worth a try.
Dimensionality Reduction
“Assembling specific features into higher-level features”
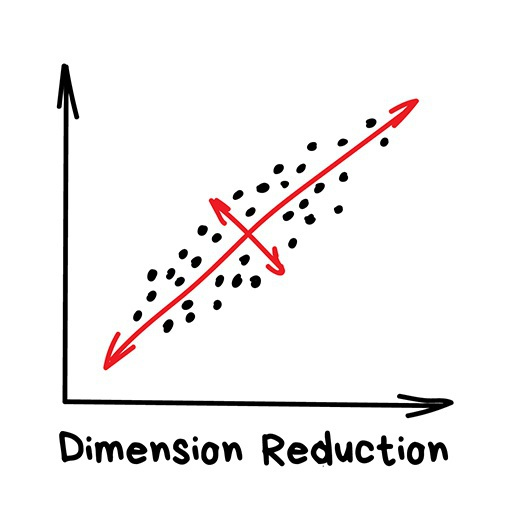
“Dimensionality reduction” algorithms are currently used for:
-
Recommendation systems; -
Beautiful visualizations; -
Topic modeling and finding similar documents; -
Fake image recognition; -
Risk management;
-
Principal Component Analysis (PCA) -
Singular Value Decomposition (SVD) -
Latent Dirichlet Allocation (LDA) -
Latent Semantic Analysis (LSA, pLSA, GLSA) -
t-SNE (for visualization)
In earlier years, “hardcore” data scientists would use these methods, determined to find “interesting things” in a pile of numbers. When Excel charts didn’t work, they forced the machine to do the pattern-finding work. Thus, they invented dimensionality reduction or feature learning methods.
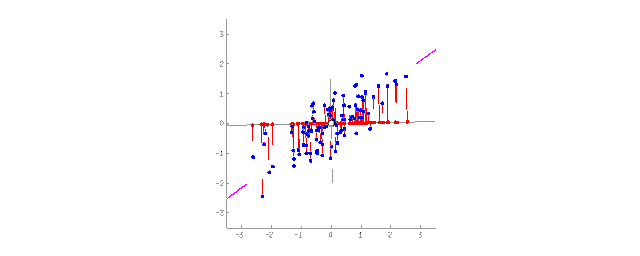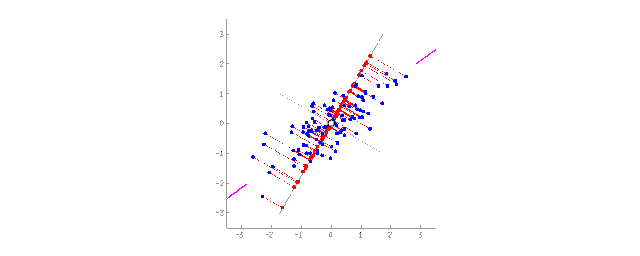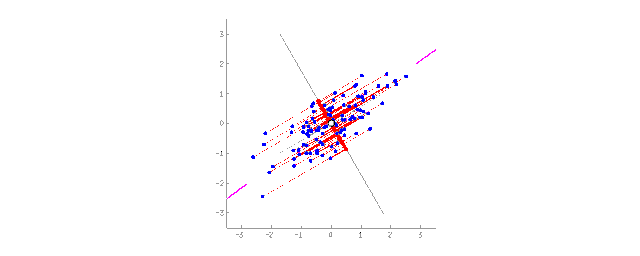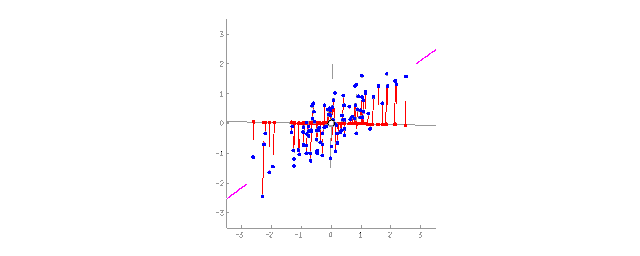
Projecting 2D data onto a line (PCA)
For people, abstract concepts are more convenient than a pile of fragmented features. For example, we can combine a dog with triangular ears, a long nose, and a large tail into the abstract concept of a “sheepdog.” Compared to specific sheepdogs, we lose some information, but the new abstract concept is more useful for situations that require naming and explanation. As a reward, such “abstract” models learn faster, require fewer features during training, and reduce overfitting.
These algorithms can shine in “topic modeling” tasks. We can abstract meanings from specific phrases. Latent Semantic Analysis (LSA) does this, based on the frequency of specific words you see on a topic. For instance, technology-related terms are likely to appear more frequently in tech articles, or a politician’s name mostly appears in political news, and so on.
We can create clusters from all words of all articles, but doing so would lose all important connections (for example, in different articles, “battery” and “accumulator” mean the same thing). LSA can handle this problem well, which is why it’s called “latent semantic.”
Thus, we need to connect words and documents into a feature to maintain the latent connections — people found that Singular Value Decomposition (SVD) can solve this problem. Those useful topic clusters can easily be seen from the grouped phrases.

Recommendation systems and collaborative filtering are another high-frequency area using dimensionality reduction algorithms. If you extract information from user ratings, you’ll get a great system to recommend movies, music, games, or anything else you want.
Here’s a book I love, “Programming Collective Intelligence,” which was my bedside book during college.
Fully understanding this abstraction on machines is almost impossible, but you can pay attention to some correlations: some abstract concepts relate to user age — little kids play “Minecraft” or watch cartoons more, while others may relate to movie styles or user preferences.
Just based on user rating information, the machine can find these high-level concepts without even needing to understand them. Well done, Mr. Computer. Now we can write a paper on “Why Bearded Lumberjacks Love My Little Pony.”
Association Rule Learning
“Finding patterns in transaction data”
“Association rules” are currently used for:
-
Predicting sales and discounts; -
Analyzing items purchased together; -
Planning product placement; -
Analyzing web browsing patterns;
Common algorithms include:
-
Apriori -
Euclat -
FP-growth
Algorithms used to analyze shopping carts, automate marketing strategies, and other event-related tasks are all here. If you want to discover patterns from a sequence of items, give them a try.
For example, a customer takes a six-pack of beer to the checkout. Should we place peanuts along the checkout lane? How often do people buy beer and peanuts together? Yes, association rules might apply to the beer and peanuts scenario, but what other sequences can we predict? Can we make small changes in product layout that lead to significant profit increases?
This thinking also applies to e-commerce, where the tasks are even more interesting — What will the customer buy next?
I don’t know why rule learning seems to be rarely mentioned in the realm of machine learning. The classic approach applies trees or set methods based on a positive check of all purchased items. The algorithm can only search for patterns but cannot generalize or reproduce those patterns on new examples.
In the real world, every large retailer has established its own proprietary solutions, so this won’t bring you any revolutions. The highest-level technology mentioned in this article is recommendation systems. However, I may not be aware of any breakthroughs in this area. If you have anything to share, please let me know in the comments.
Editor / Zhang Zhihong
Reviewer / Fan Ruiqiang
Recheck / Zhang Zhihong
Click below
Follow us
Read the original article