-
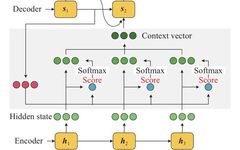
Attention Mechanism
The core idea of the attention mechanism is to allow the model to allocate different attention weights based on the importance of the data while processing it. This mechanism enables the model to focus more resources on critical parts, thus extracting and utilizing information more effectively. In deep learning, the attention mechanism has been widely applied in various tasks, such as natural language processing and computer vision, achieving significant results.

-
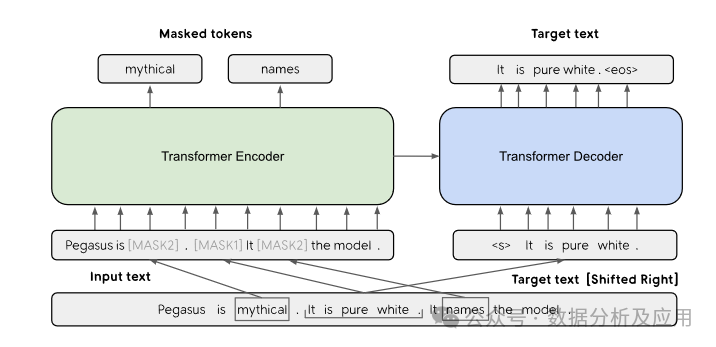
Self-Supervised Learning
The core idea of self-supervised learning is to utilize the structure or characteristics of the data itself for learning. This learning method does not require manually labeled data but guides the model to learn by designing specific tasks or objectives. Self-supervised learning can pre-train models on unlabeled data and achieve excellent performance on downstream tasks. This method is increasingly widely used in deep learning, providing strong support for many tasks.
-
Contrastive Learning
Unlike traditional supervised and unsupervised learning, the core idea of contrastive learning is to learn the similarities or differences between data by constructing positive and negative sample pairs. In this way, the model can learn the inherent patterns and structures contained in the data, achieving outstanding performance in various tasks. Contrastive learning has become an indispensable technique in many areas of deep learning.
Simple Stunning Techniques
-
BP Algorithm (Backpropagation)
The simple and effective backpropagation technique has cleared the obstacles for the development of deep learning. The BP algorithm is one of the core technologies for training neural networks. It updates the parameters by calculating the gradient of the loss function concerning the model parameters, allowing the model to gradually approach the optimal solution. The implementation of the BP algorithm is simple and efficient, making it one of the indispensable technologies in the field of deep learning.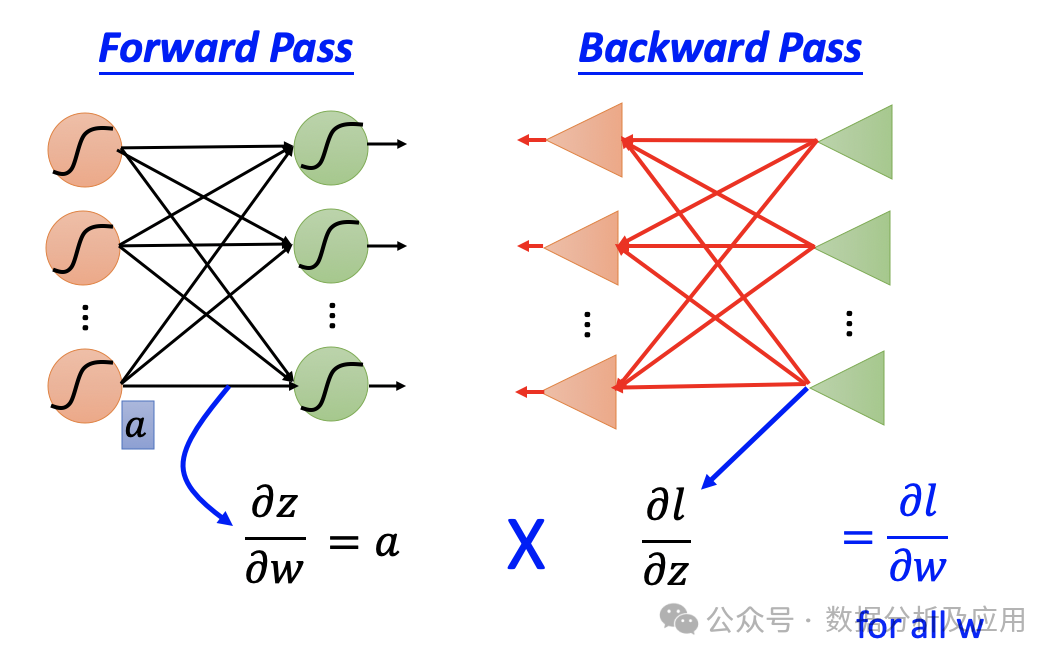
-
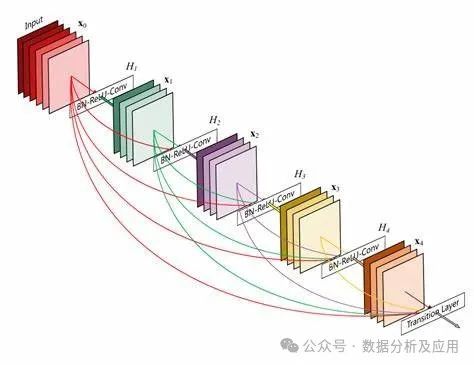
Residual/Skip Connections
Residual connections are a technique used to address the issues of gradient vanishing and model degradation in deep networks. By introducing residual connections in the model, input information can be directly passed to deeper layers, avoiding gradient attenuation during the transmission process. This technique makes it easier for the model to learn identity mappings, enhancing the model’s performance and stability.
-
Dropout and BatchNorm
Dropout and BatchNorm are two commonly used deep learning techniques. Dropout prevents overfitting by randomly deactivating a portion of neurons, enhancing the model’s generalization ability. BatchNorm accelerates the training process by normalizing the outputs of each layer, improving the model’s stability and convergence speed.
Stunning Models/Papers
-
GAN (Generative Adversarial Network)
GAN, as a breakthrough technology in the field of deep learning, is based on the idea of introducing two opposing networks—the generator and the discriminator—to conduct adversarial training. The generator is responsible for generating data that is as realistic as possible, while the discriminator is responsible for distinguishing between generated data and real data. This adversarial training mechanism enables GANs to generate extremely realistic images, audio, and other data, greatly advancing the development of generative models.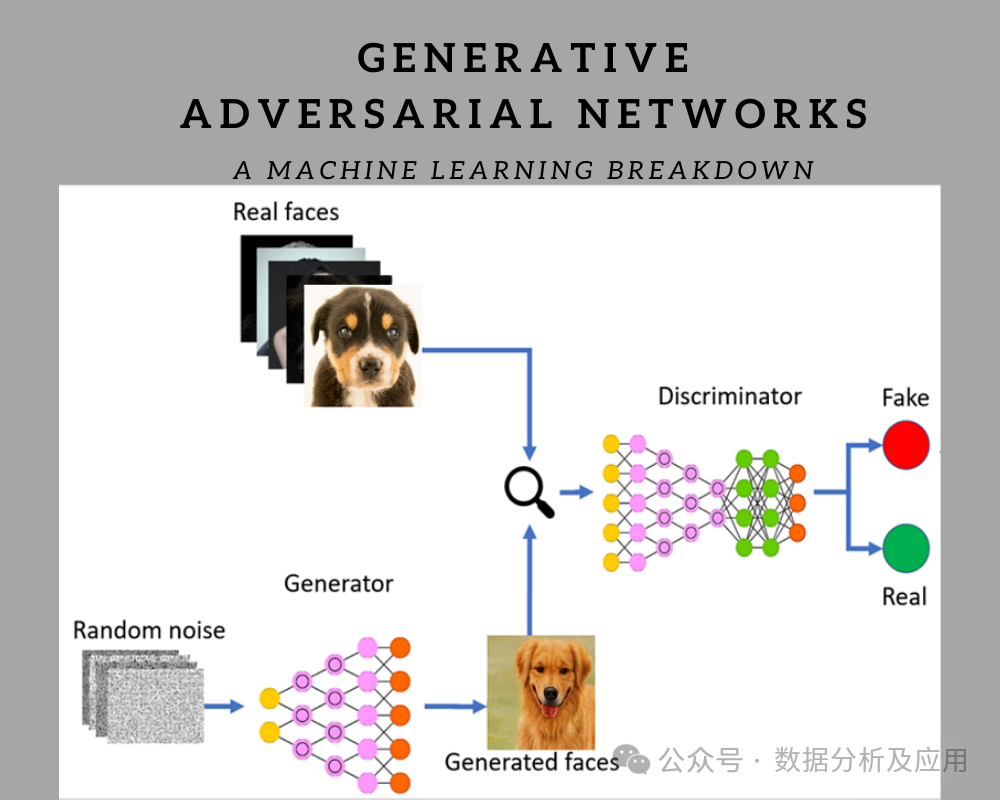
Reference:Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
Example code (using the PyTorch framework):
import torch import torch.nn as nn # Define the generator class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.model = nn.Sequential( nn.Linear(100, 256), nn.LeakyReLU(0.2), nn.Linear(256, 512), nn.LeakyReLU(0.2), nn.Linear(512, 784), nn.Tanh() ) def forward(self, z): return self.model(z).view(-1, 1, 28, 28) # Define the discriminator class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Linear(784, 512), nn.LeakyReLU(0.2), nn.Linear(512, 256), nn.LeakyReLU(0.2), nn.Linear(256, 1), nn.Sigmoid() ) def forward(self, img): img_flat = img.view(img.size(0), -1) return self.model(img_flat)-
Word2Vec
Word2Vec is a pioneering work in representation learning. It is used to learn word vector representations by predicting the context of words or the words in the context. The two main implementations of Word2Vec are Skip-Gram and CBOW (Continuous Bag of Words). These models can capture the semantic relationships between words, placing similar words close together in the vector space.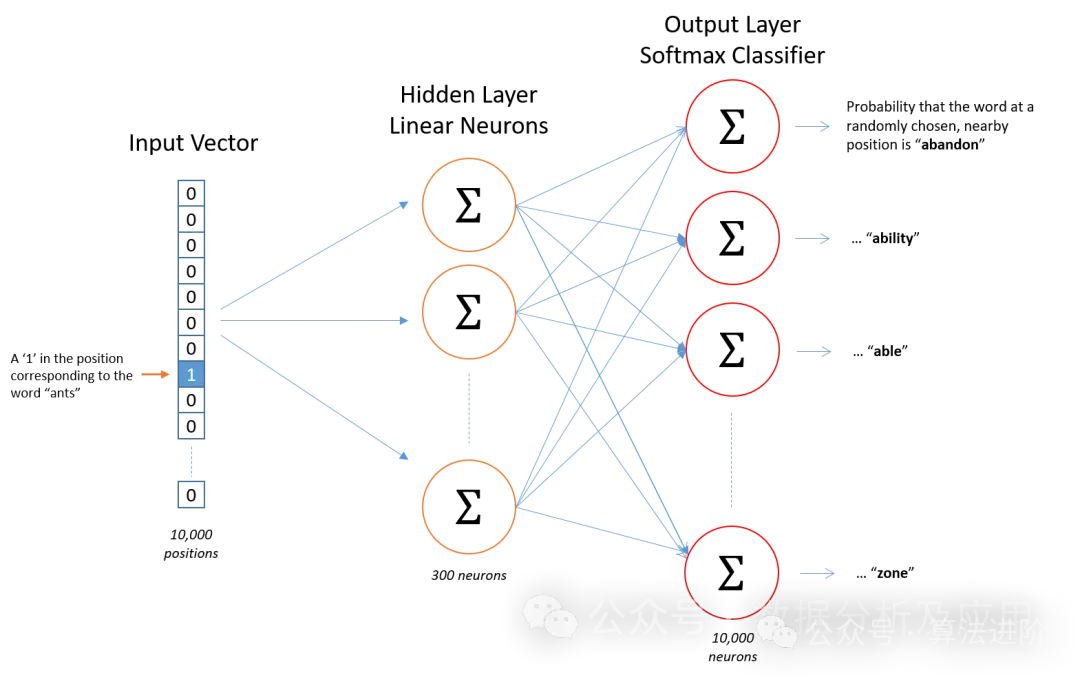
Paper:
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations (ICLR 2013).
Example code:
from gensim.models import Word2Vec # Assume sentences is a list containing multiple sentences, each composed of a list of words sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]] # Train Word2Vec model model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4) # Get the vector for a word vector = model.wv['cat'] print(vector) # Find the most similar words to a given word similar_words = model.wv.most_similar('cat', topn=5) print(similar_words)-
AlexNet
AlexNet is the landmark of deep learning in the field of computer vision. It introduced technologies such as ReLU and Dropout and won the championship in the ImageNet challenge. The success of AlexNet proved the immense potential of deep learning in computer vision, driving rapid development in this field.
import torch import torch.nn as nn import torch.nn.functional as F class AlexNet(nn.Module): def __init__(self, num_classes=1000): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), # ... Other layers omitted for brevity ... nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) return x # Instantiate model model = AlexNet(num_classes=1000) # Assume it's a 1000-class classification task -
Transformer
In the early stages of deep learning, convolutional neural networks (CNNs) achieved significant success in image recognition and natural language processing. However, as task complexity increased, sequence-to-sequence (Seq2Seq) models and recurrent neural networks (RNNs) became common methods for processing sequential data. Despite RNNs and their variants performing well on certain tasks, they often encounter issues of gradient vanishing and model degradation when processing long sequences. To address these problems, the Transformer model was proposed. Subsequent models like GPT and BERT are based on the Transformer, ushering in the era of large AI models.
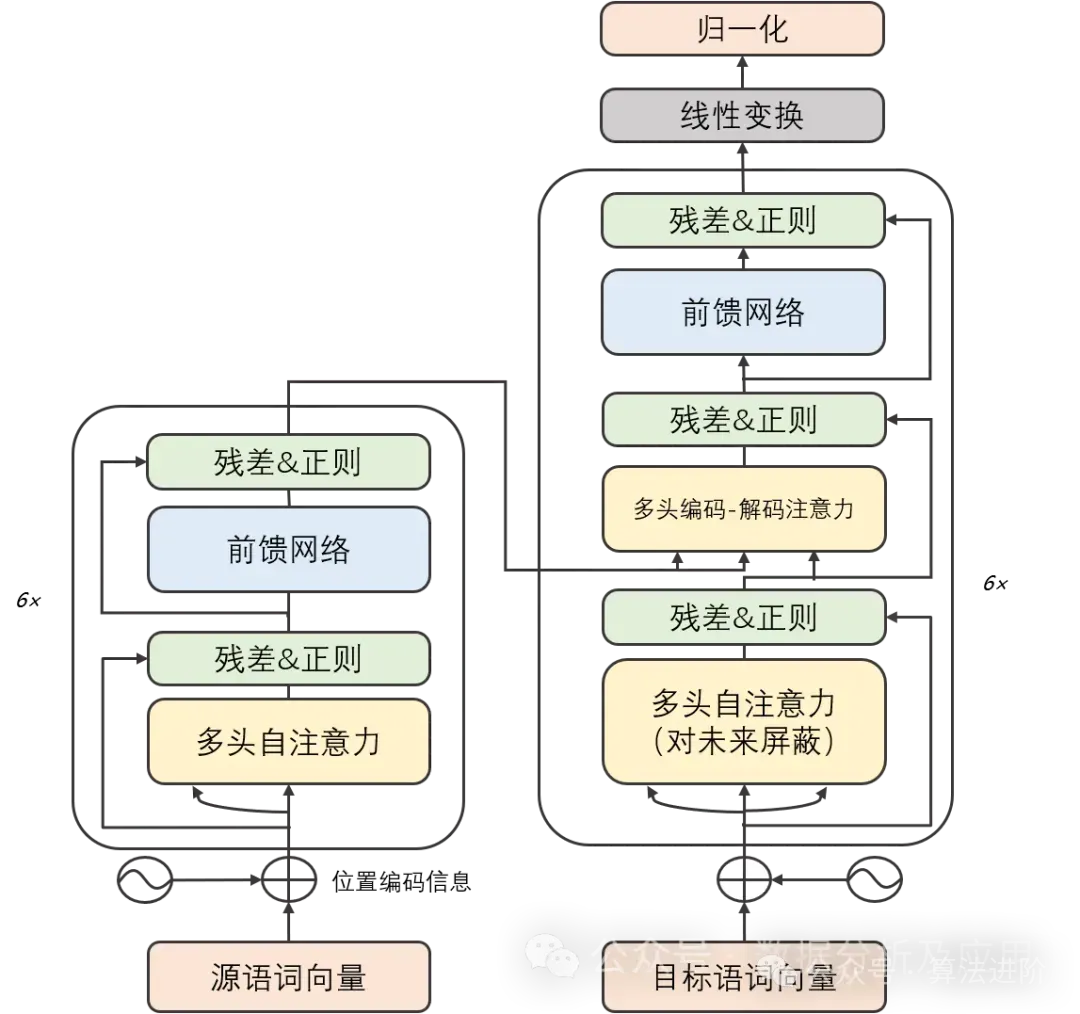
Paper: Attention Is All You Need!
Python Example Code (Simplified Version):
import torchimport torch.nn as nnimport torch.optim as optim# This example is only for illustrating the basic structure and principles of the Transformer. Actual Transformer models (like GPT or BERT) are much more complex and require additional preprocessing steps such as tokenization, padding, masking, etc. class Transformer(nn.Module): def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward=2048): super(Transformer, self).__init__() self.model_type = 'Transformer' # encoder layers self.src_mask = None self.pos_encoder = PositionalEncoding(d_model, max_len=5000) encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward) self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_encoder_layers) # decoder layers decoder_layers = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward) self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers) # decoder self.decoder = nn.Linear(d_model, d_model) self.init_weights() def init_weights(self): initrange = 0.1 self.decoder.weight.data.uniform_(-initrange, initrange) def forward(self, src, tgt, teacher_forcing_ratio=0.5): batch_size = tgt.size(0) tgt_len = tgt.size(1) tgt_vocab_size = self.decoder.out_features # forward pass through encoder src = self.pos_encoder(src) output = self.transformer_encoder(src) # prepare decoder input with teacher forcing target_input = tgt[:, :-1].contiguous() target_input = target_input.view(batch_size * tgt_len, -1) target_input = torch.autograd.Variable(target_input) # forward pass through decoder output2 = self.transformer_decoder(target_input, output) output2 = output2.view(batch_size, tgt_len, -1) # generate predictions prediction = self.decoder(output2) prediction = prediction.view(batch_size * tgt_len, tgt_vocab_size) return prediction[:, -1], prediction class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=5000): super(PositionalEncoding, self).__init__() # Compute the positional encodings once in log space. pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1).float() div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(torch.log(torch.tensor(10000.0)) / d_model)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) self.register_buffer('pe', pe) def forward(self, x): x = x + self.pe[:, :x.size(1)] return x # Hyperparametersd_model = 512nhead = 8num_encoder_layers = 6num_decoder_layers = 6dim_feedforward = 2048 # Instantiate modelmodel = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward) # Randomly generated data src = torch.randn(10, 32, 512)tgt = torch.randn(10, 32, 512) # Forward pass prediction, predictions = model(src, tgt) print(prediction)Bonus: Secrets of Deep Learning
-
Random Seed is all you need: In deep learning, the random seed has a significant impact on the model’s training results. Sometimes, changing the random seed can even lead to a substantial improvement in model performance. Those who have dabbled in this should have deep insights!
-
Money is all you need: Although deep learning technology itself is already very advanced, achieving better results often requires more computational resources and data. More funding support is needed; ultimately, what is lacking is the ability to spend money.
