

This article is about 3200 words long and is recommended for a 6-minute read.
This paper is co-authored by three top experts - "Deep Learning".
This is a must-read paper for anyone learning deep learning, co-authored by the father of convolutional neural networks, Yann Le Cun, Yoshua Bengio, and the leading figure in deep learning, Geoffrey Hinton – “Deep Learning”!

Abstract
Deep learning utilizes multi-layer processing models to learn hierarchical abstract data representations, significantly improving performance in areas such as speech recognition and visual recognition. The BP algorithm guides the model in adjusting internal parameters to discover complex structures. Deep convolutional networks excel at processing images and videos, while recursive networks perform notably well on sequential data such as text.
Machine learning techniques are widely applied in web search, content filtering, product recommendations, and are integrated into consumer products like cameras and smartphones. Deep learning is gradually replacing traditional techniques, automatically learning representations of raw data. It transforms raw data into high-level abstract representations through non-linear models, suitable for complex function learning.
Deep learning feature representations are learned automatically from data, eliminating the need for manual design, addressing long-standing challenges in the field of AI. It has been applied across various domains including science, business, and government, outperforming other techniques in drug prediction, particle data analysis, and brain circuit reconstruction.
Particularly in natural language understanding, deep learning has shown significant results, such as topic classification and sentiment analysis. With increasing computational power and data volume, deep learning is expected to achieve further success. New learning algorithms and architectures will accelerate this process.
Supervised Learning
Supervised learning is the most common form of machine learning, involving training a model on a labeled dataset to classify objects. For example, by collecting and labeling image datasets of houses, cars, people, and pets, a classification system can be established. During training, the machine generates outputs represented by vector scores from the images, one for each category. Initially, the scores for the desired categories are not high, but by calculating the target function to obtain the error between the output and the expected result, the machine adjusts its internal weights to reduce this error. These weights define the machine’s functionality.
In deep learning systems, millions of samples and weights are used for training. The algorithm computes the gradient vector for each weight, indicating how small changes in the weight affect the error. The weights are then adjusted in the opposite direction of the gradient vector, aiming to minimize the average output error.
Practitioners often use the Stochastic Gradient Descent (SGD) algorithm, which computes the error for a sample and adjusts the weights accordingly. Training is repeated with small sample sets until the target function stabilizes. SGD is simple and fast. After training, the system is tested with a test set to evaluate its performance, specifically its ability to recognize new samples.
Many machine learning techniques use linear classifiers to handle manually designed features. A binary classifier decides the category based on weighted sums of features. However, linear classifiers are only suitable for simple separations and fail in tasks requiring robustness and specific sensitivity, such as image and speech recognition. For example, images of a wolf and a Samoyed dog may appear similar against the same background, but they differ significantly at the pixel level.
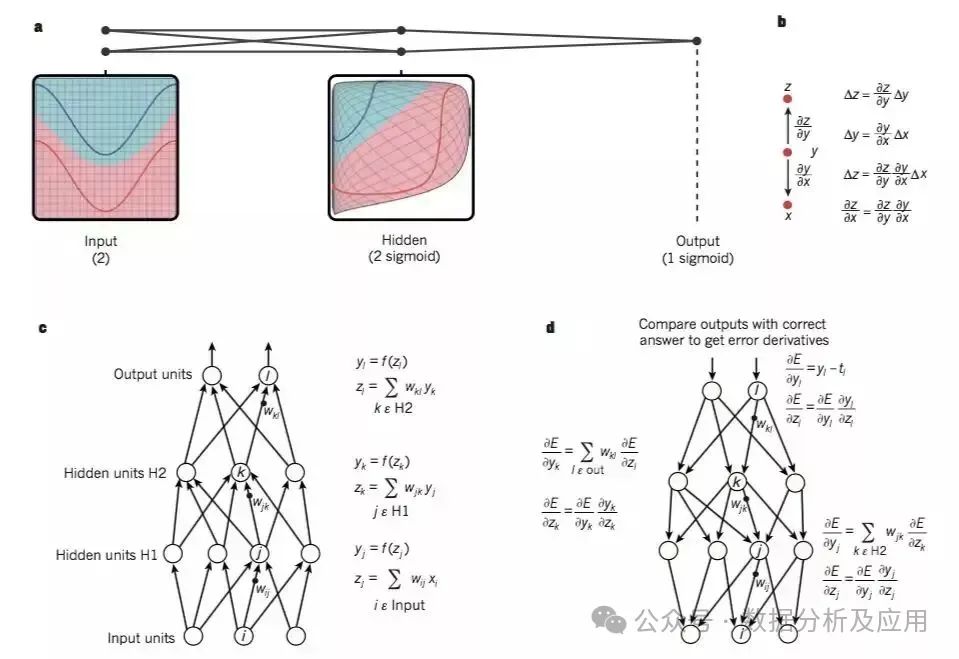
A multilayer neural network integrates the input space through connection points, making the data linearly separable. This example demonstrates two input nodes, two hidden nodes, and one output node, but in practical applications, the network is much larger. The chain rule describes how small changes propagate. In a neural network, each layer computes the total input z and calculates the output through a non-linear function. Common non-linear functions include ReLU and sigmoids. During backpropagation, the output unit error is computed and propagated back to the input layer. Simple classifiers cannot distinguish complex data, while deep learning overcomes this issue by stacking multiple simple modules, with each layer increasing the expressiveness and invariance of the representation. The key advantage of deep learning lies in its ability to automatically extract good features through a general learning process.
Multilayer neural networks are trained using backpropagation. In early pattern recognition tasks, researchers aimed to replace manual feature selection with multilayer networks, but the training results of multilayer neural networks were poor. It wasn’t until the 1980s that simple stochastic gradient descent methods changed this situation. The backpropagation algorithm is key to solving the gradient of weights in multilayer networks, propagating derivatives backward through the chain rule. Deep learning often employs feedforward neural networks, where ReLU as an activation function performs excellently. Hidden layers disrupt input data non-linearly, making the categories linearly separable in the final layer. In the late 1990s, neural networks and backpropagation faced skepticism due to gradient descent getting stuck in local minima. However, theory and experiments showed that local minima are not a major issue, and the solution space often consists of saddle points. In 2006, CIFAR drove the resurgence of deep feedforward neural networks by pre-training network layers through unsupervised learning and then fine-tuning with backpropagation, significantly improving performance in handwritten digit and pedestrian prediction, especially suitable for small labeled datasets. This method achieved significant acceleration in speech recognition applications implemented on GPUs, successfully mapping acoustic coefficient windows and achieving remarkable results on standard tests. Subsequently, deep network versions were developed for Android smartphones. For small datasets, unsupervised pre-training can prevent overfitting and enhance generalization performance.
Convolutional Neural Networks (CNN)
Convolutional Neural Networks (CNN) are a type of deep feedforward network that are easy to train and have better generalization performance, widely adopted by computer vision teams. CNNs process multidimensional array data, utilizing local connections, weight sharing, pooling, and multi-layer network structures to handle data such as images, sounds, and videos.
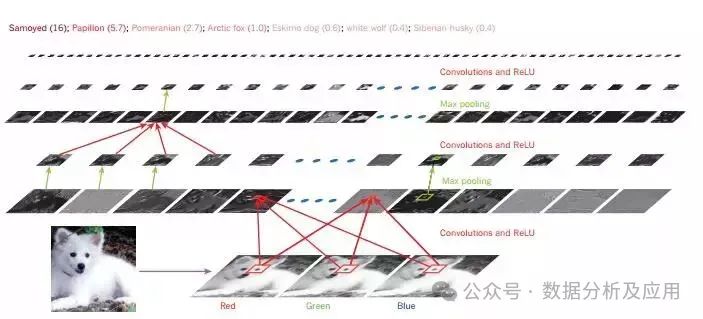
A typical convolutional neural network structure consists of convolutional layers and pooling layers, detecting local features and connecting to upper local blocks through filters. Feature maps share filters to recognize features appearing at multiple locations. Convolutional layers detect local connections, while pooling layers merge similar features. By combining convolution, non-linear transformations, and pooling layers, feature extraction is achieved. Deep neural networks leverage hierarchical properties, with high-level features obtained by combining low-level features. The pooling operation makes feature representations robust to positional changes. Convolutional neural networks are inspired by visual neuroscience, simulating the hierarchical structure of visual circuits. Since the 1990s, CNNs have been applied in areas such as speech recognition, document reading, and character recognition.
Using Deep Convolutional Networks for Image Understanding
In the 21st century, CNNs have been widely used in image detection, segmentation, and object recognition, achieving significant success particularly in facial recognition. Images can be labeled at the pixel level, facilitating technologies such as automatic answering and autonomous driving. Mobileye and NVIDIA have employed CNNs in automotive vision systems. This technology achieved great success in the 2012 ImageNet competition, significantly reducing error rates and driving a revolution in computer vision. Today, CNNs are widely used for recognition and detection tasks, and even for generating image captions. Advances in hardware, software, and algorithms have greatly shortened training times. Companies like Google and Microsoft have recognized the potential of this technology, while NVIDIA is developing CNN chips for smart devices.

Distributed Feature Representation and Language Processing
Distributed feature representation demonstrates the advantages of deep networks, including generalization ability and the exponential potential of composite representations. Multilayer neural networks learn the features of input data to predict target outputs. For example, in text prediction, the network learns word vectors and predicts the next word in a sentence. These semantic features are not explicit in the input but are learned by the network. During the process of utilizing “micro-rules”, we find that it helps parse the relationships between input and output symbols. Even when sentences come from real texts and micro-rules are unreliable, learning word vectors still performs well. When predicting new instances, similar conceptual words can easily confuse, such as Tuesday and Wednesday, Sweden and Norway. This approach is called distributed feature representation, where elements are not mutually exclusive, constructing information corresponding to changes in observed data. Word vectors are constructed based on automatically learned features rather than expert decisions. Word vector learning is now widely used in natural language.
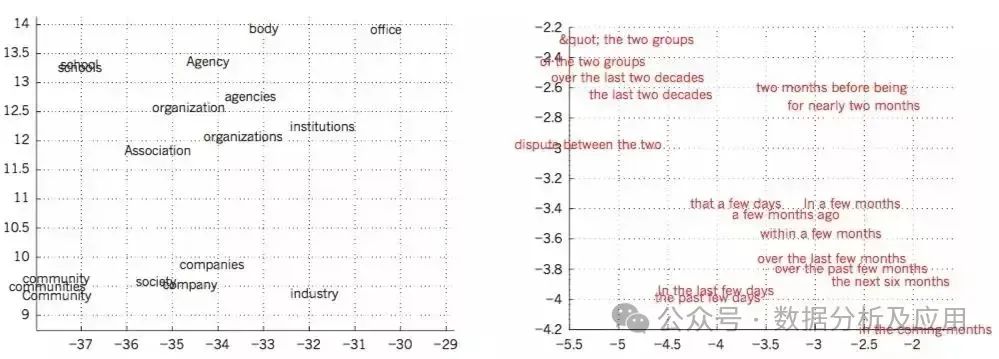 Figure 4 Visualization of Word Vector Learning
Figure 4 Visualization of Word Vector LearningThe debate over feature representation revolves around logical heuristics versus neural networks. In logical heuristics, symbolic entities represent things due to shared or differing attributes. Neural networks, on the other hand, achieve rapid “intuition” for common sense reasoning through active carriers, weight matrices, and non-linearization.
Standard methods based on statistical language models do not utilize distributed feature representations but rely on N-grams to statistically analyze the frequency of short symbol sequences. This requires large corpora. N-grams treat words as atomic units, failing to handle semantically related sequences. Neural network language models associate words with real-valued feature vectors, making semantically related words close in vector space (Figure 4).
Recurrent Neural Networks (RNNs) are suitable for sequential input tasks such as speech and language. RNNs maintain historical information in an implicit unit, the “state vector”, while processing sequence elements. Although RNNs are powerful, they face training issues due to gradients growing or decaying over time, leading to results either exploding or vanishing.
RNNs can predict the next character in text or the next word in a sentence, suitable for complex tasks. For example, after reading an English sentence, the “encoder” network is trained to represent the meaning of the sentence in the implicit unit state vector. This “thought vector” can serve as the initial state or additional input for a French “encoder” network, outputting the probability distribution of the first word in the French translation. A special first word is chosen as input for the encoding network, outputting the probability distribution of the second word in the translated sentence, continuing until stopping. This process generates a sequence of French vocabulary based on the probability distribution of the English sentence. This method performs comparably to advanced approaches, raising questions about whether sentence understanding requires internal symbolic representation. This aligns with everyday reasoning perspectives. Similarly, the encoder translates the content of images into English sentences (as shown in Figure 3). The decoder is similar to RNNs. Deep learning has sparked immense interest (see [86]). RNNs, when unfolded, are viewed as deep feedforward networks but struggle to learn and retain long-term information. To address this, Long Short-Term Memory (LSTM) networks were proposed, which are more effective than traditional RNNs, especially in speech recognition. LSTMs or related gated units perform well in encoding, decoding networks, and machine translation. In recent years, scholars have proposed various enhancements to RNNs’ memory, such as Neural Turing Machines and Memory Networks, both showing excellent performance. Memory networks can be trained to track story states and answer complex reasoning questions.

Future Prospects of Deep Learning
While unsupervised learning has fueled the deep learning boom, supervised learning is receiving more attention. Unsupervised learning dominates in human and animal learning, discovering the structure of the world through observation. Future advancements in machine vision are expected, with enhanced learning systems based on ConvNets and RNNs developing, which have surpassed passive systems in classification tasks and shown significant effects in games.
In the coming years, natural language understanding will be an important area of deep learning, with hopes of better understanding sentences and documents. Major advancements in artificial intelligence will come from systems that combine complex reasoning and representation learning, requiring a new paradigm to replace rule-based character manipulation.
About Us
Data Party THU is a data science public account backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a data talent aggregation platform, creating the strongest group of big data in China.

Weibo: @Data Party THU
WeChat Video Account: Data Party THU
Today’s Headlines: Data Party THU