
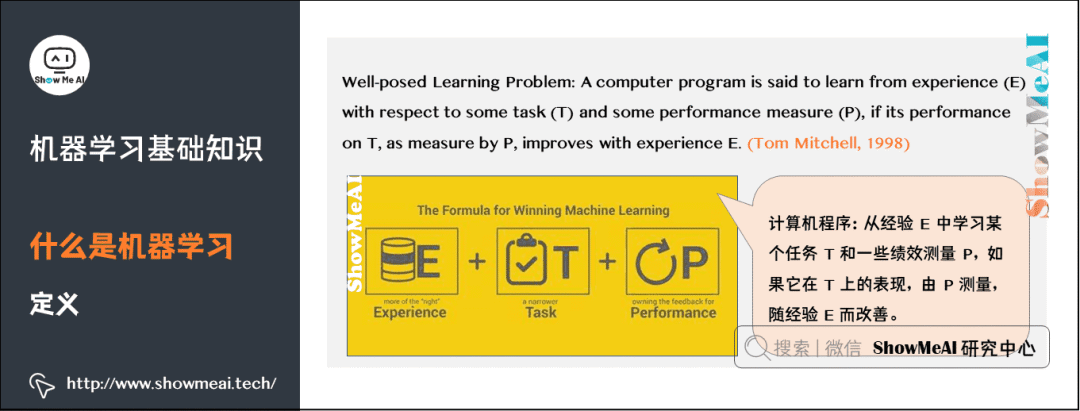
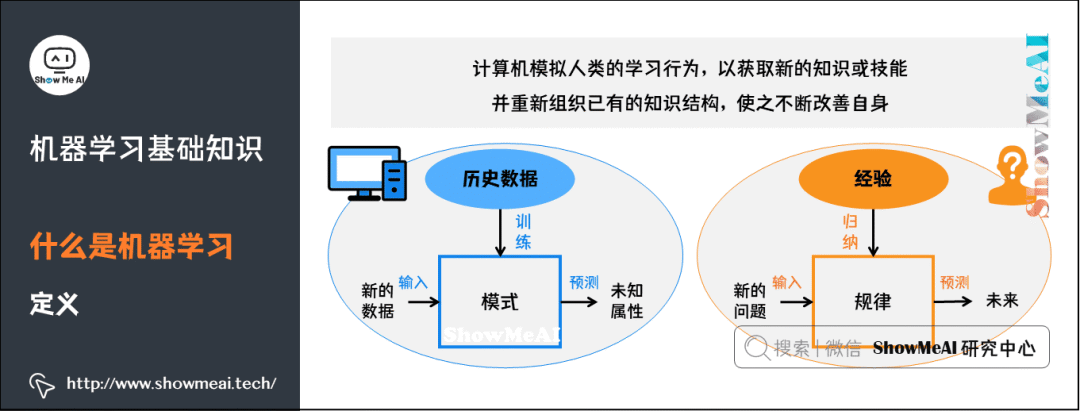
1) What is Machine Learning

2) Three Elements of Machine Learning
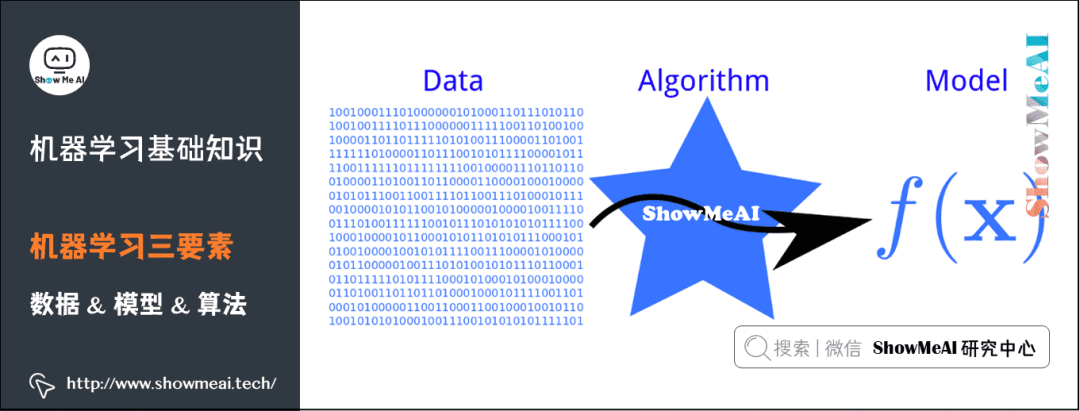
(1) Data

(2) Model & Algorithm

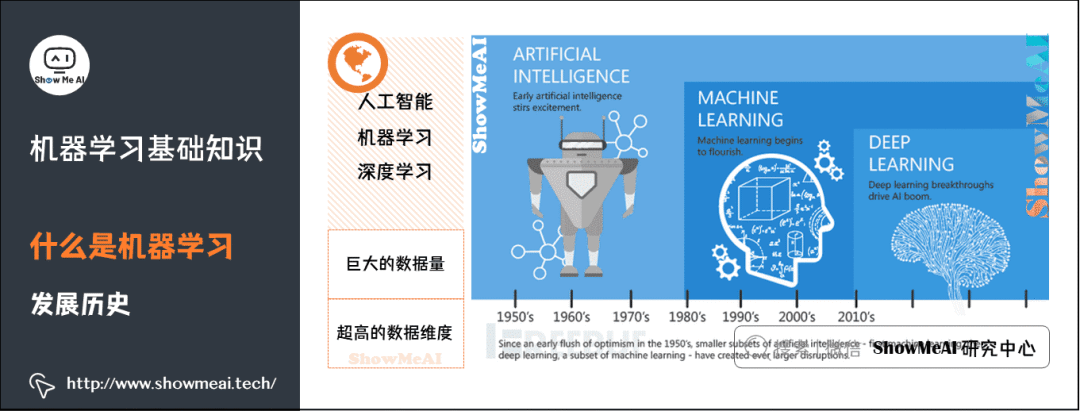
3) Development History of Machine Learning
4) Core Technologies of Machine Learning
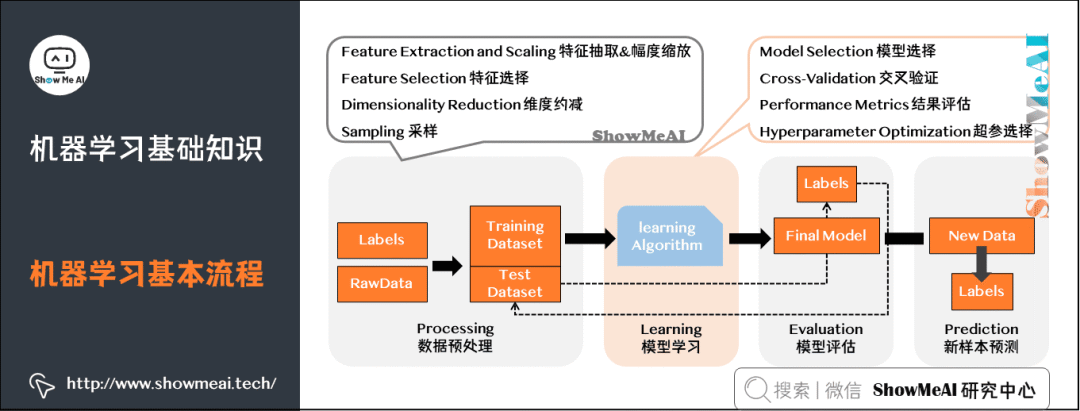
5) Basic Process of Machine Learning
6) Application Scenarios of Machine Learning

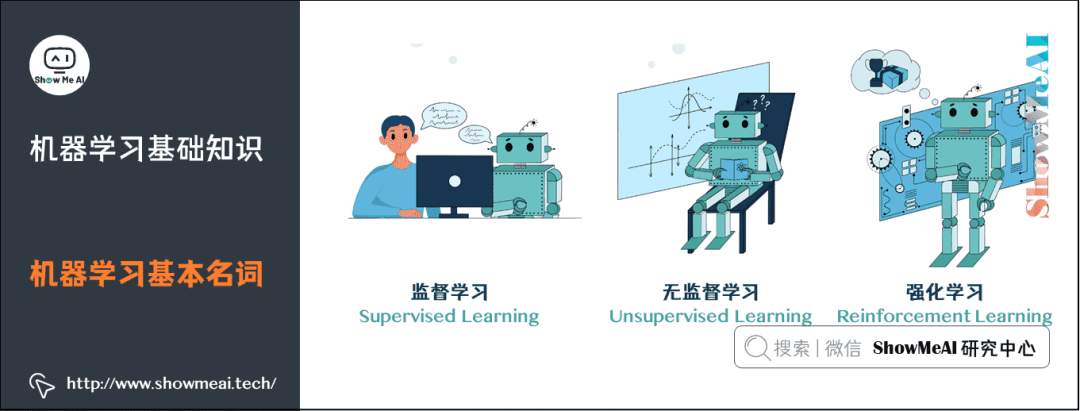
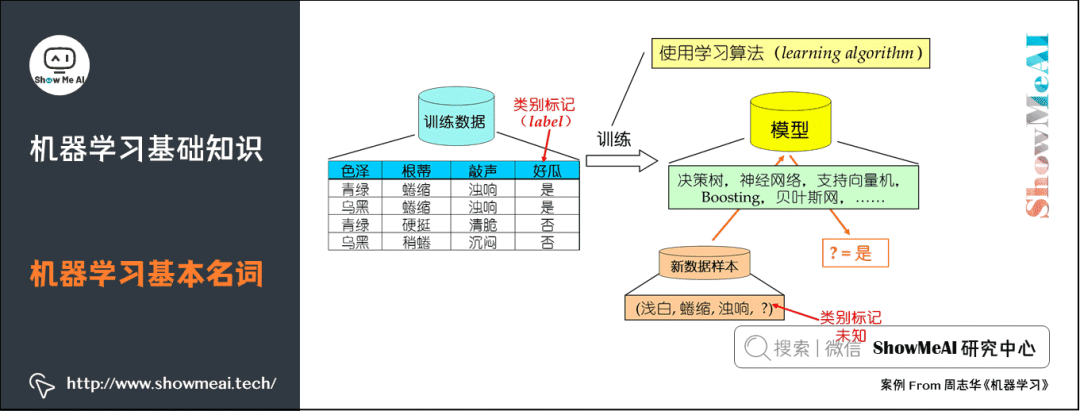
2. Basic Terminology of Machine Learning
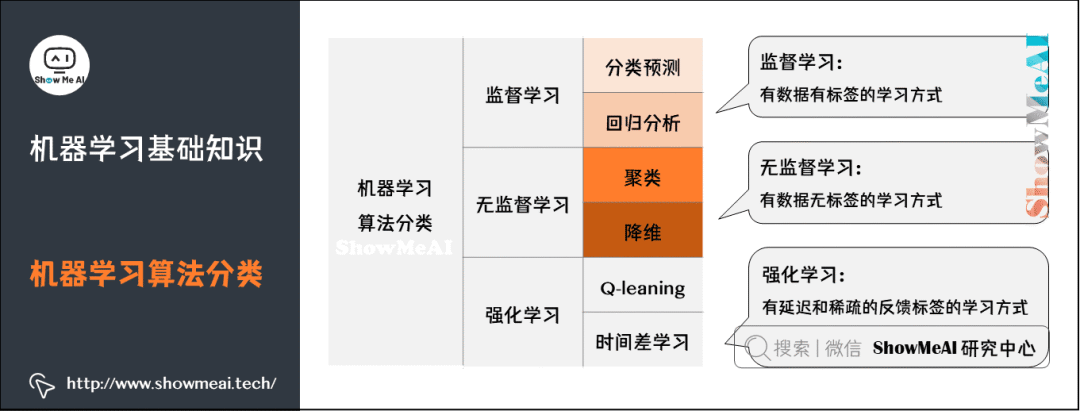
3. Classification of Machine Learning Algorithms
1) Problem Scenarios of Machine Learning Algorithms

For more summaries of supervised learning algorithm models, please refer to the article by ShowMeAI AI Knowledge Skills Quick Reference | Machine Learning – Supervised Learning (the public account cannot be redirected, link at the end of this article).
For more summaries of unsupervised learning algorithm models, please refer to the article by ShowMeAI AI Knowledge Skills Quick Reference | Machine Learning – Unsupervised Learning.
2) Classification Problems
For more information on machine learning classification algorithms: KNN algorithm, logistic regression algorithm, naive Bayes algorithm, decision tree model, random forest classification model, GBDT model, XGBoost model, support vector machine model, etc. (the public account cannot be redirected, link at the end of this article).
3) Regression Problems
For more information on machine learning regression algorithms: decision tree model, random forest classification model, GBDT model, regression tree model, support vector machine model, etc.
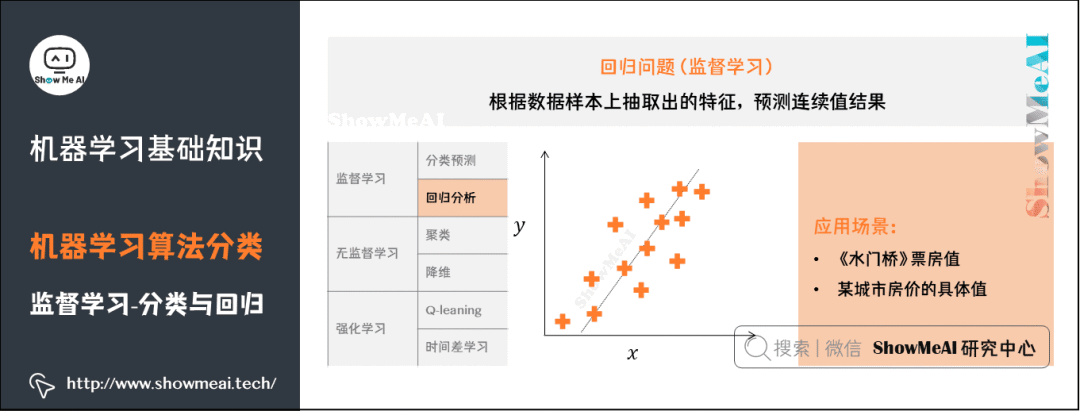
4) Clustering Problems
For more information on machine learning clustering algorithms: clustering algorithms.

5) Dimensionality Reduction Problems
For more information on machine learning dimensionality reduction algorithms: PCA dimensionality reduction algorithm.

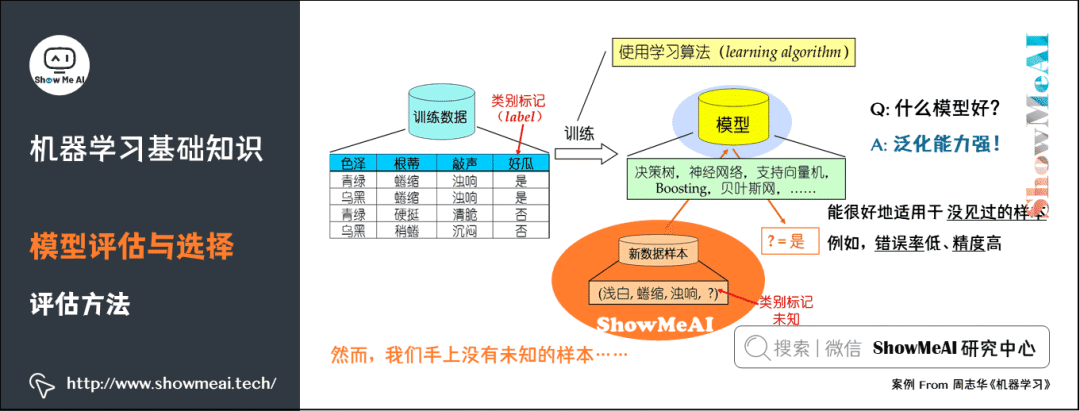
4. Model Evaluation and Selection in Machine Learning
1) Machine Learning and Data Fitting
2) Training Set and Dataset
3) Empirical Error
4) Overfitting
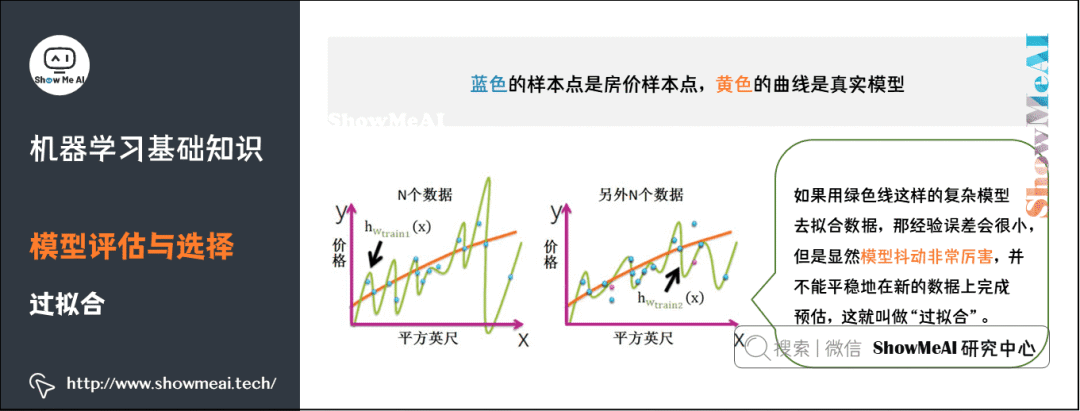
5) Bias
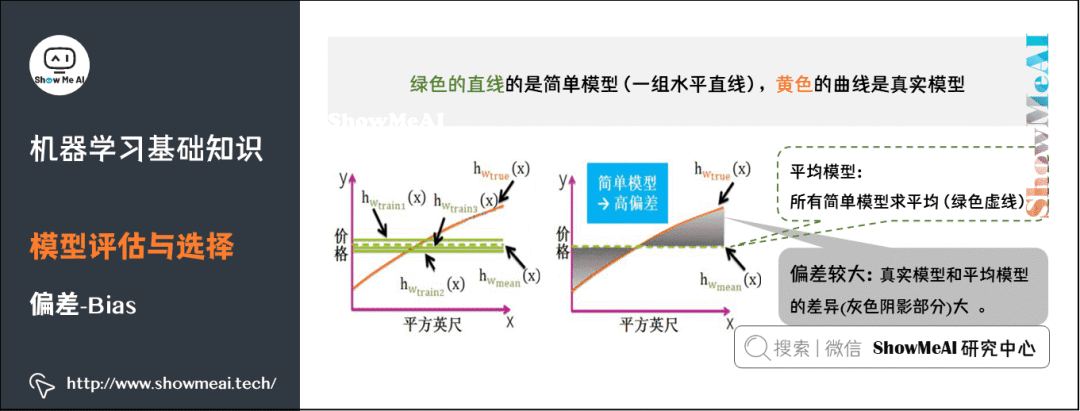
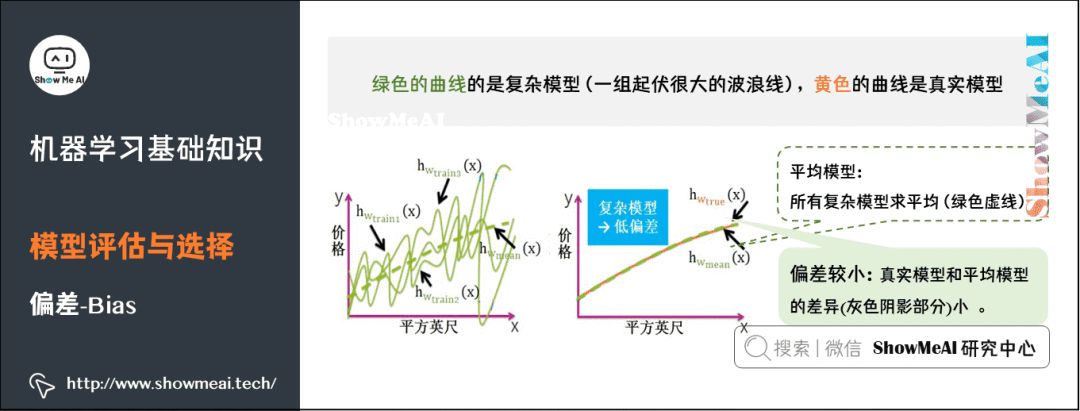
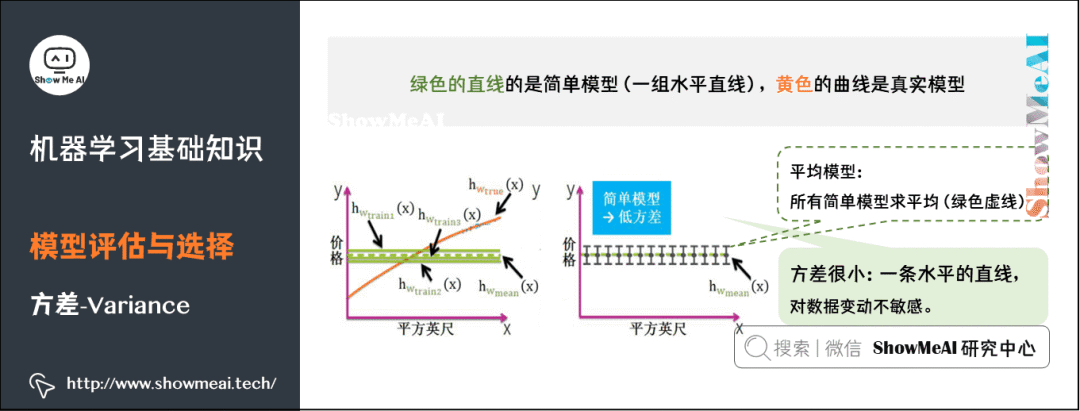
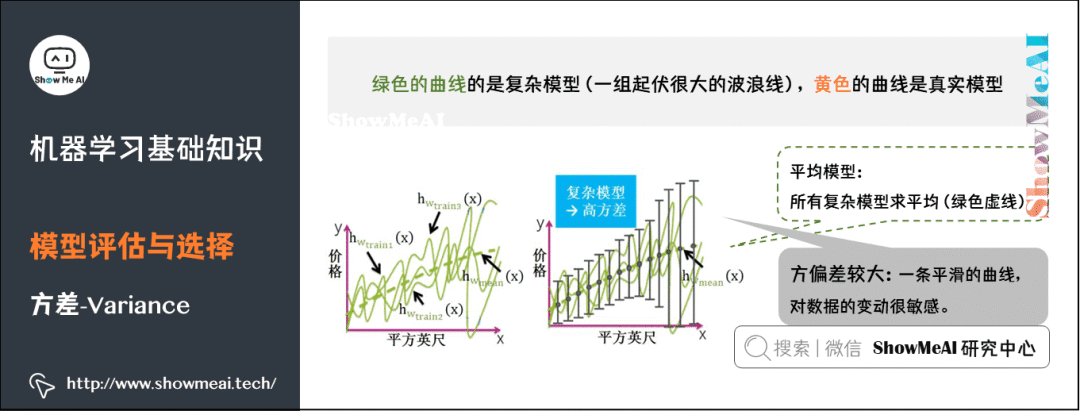
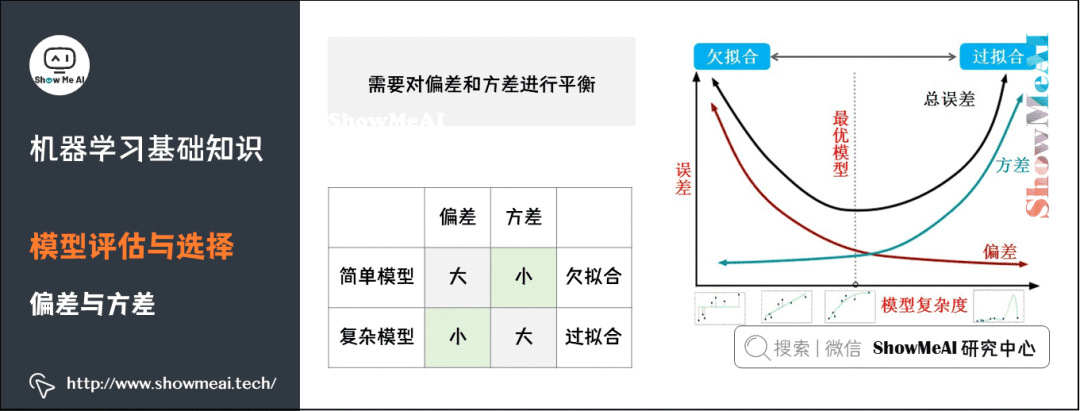
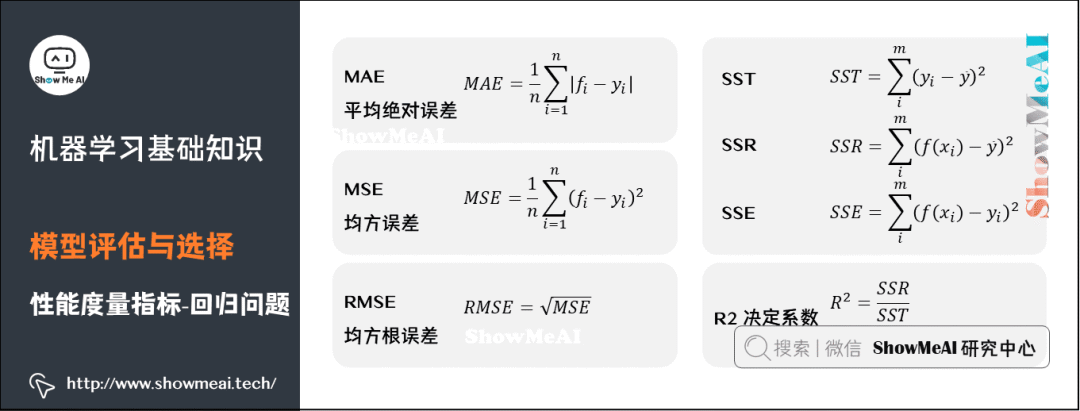
8) Performance Metrics
(1) Regression Problems
(2) Classification Problems
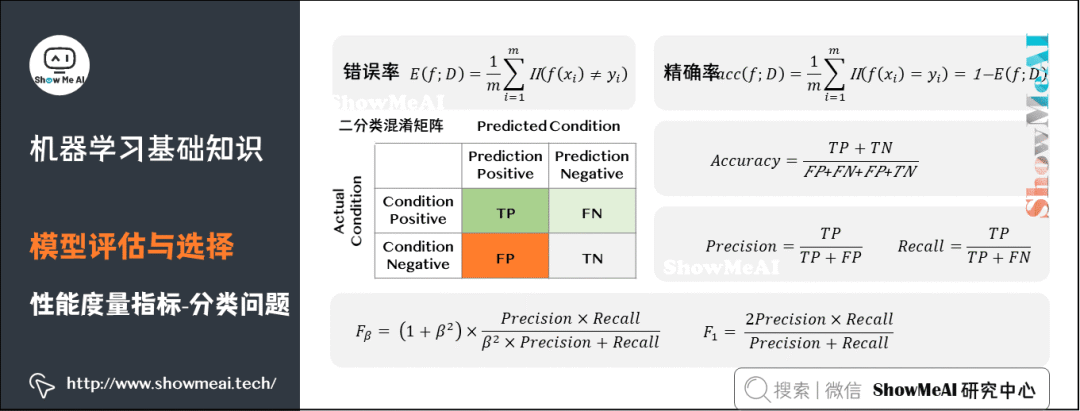
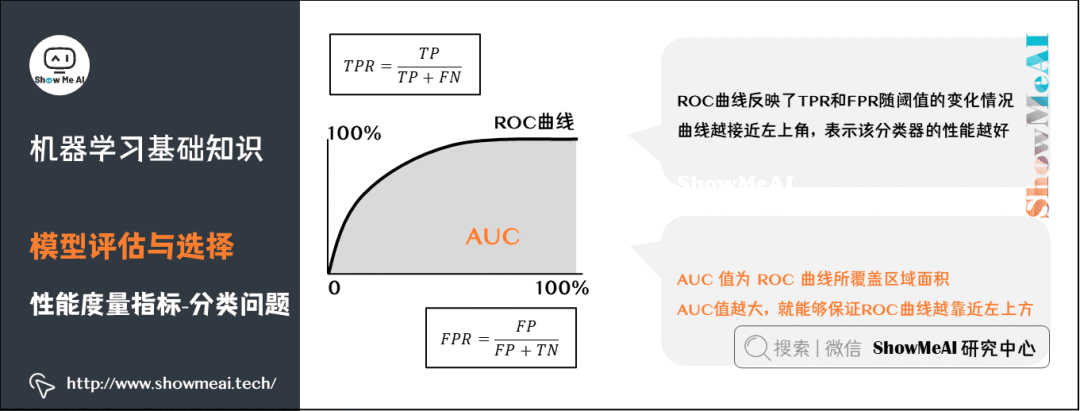
From a higher perspective, understanding AUC: still using the example of identifying anomalous users, a high AUC value means that the model can identify as many anomalous users as possible while maintaining a low false positive rate for normal users (not misclassifying a large number of normal users as anomalous just to identify anomalous users).
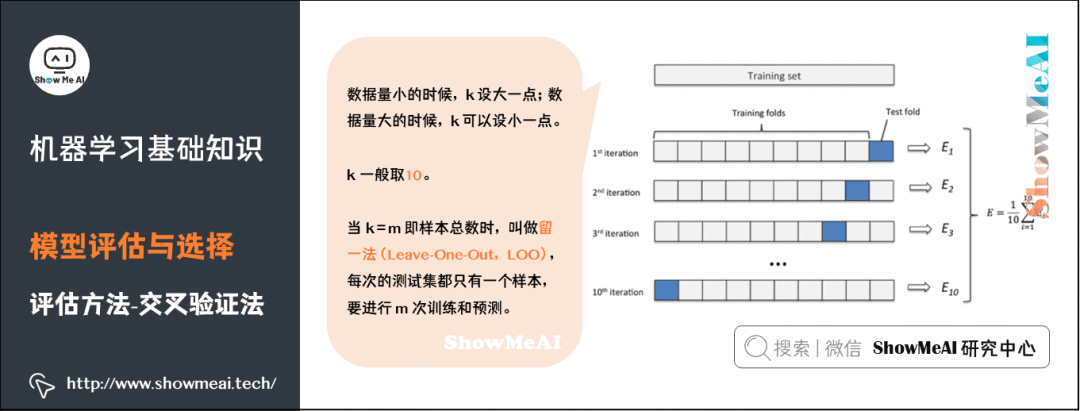
9) Evaluation Methods
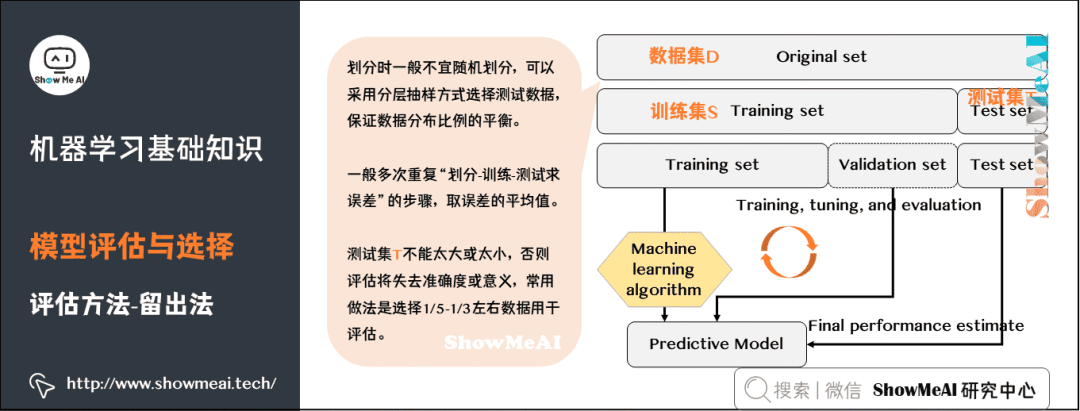

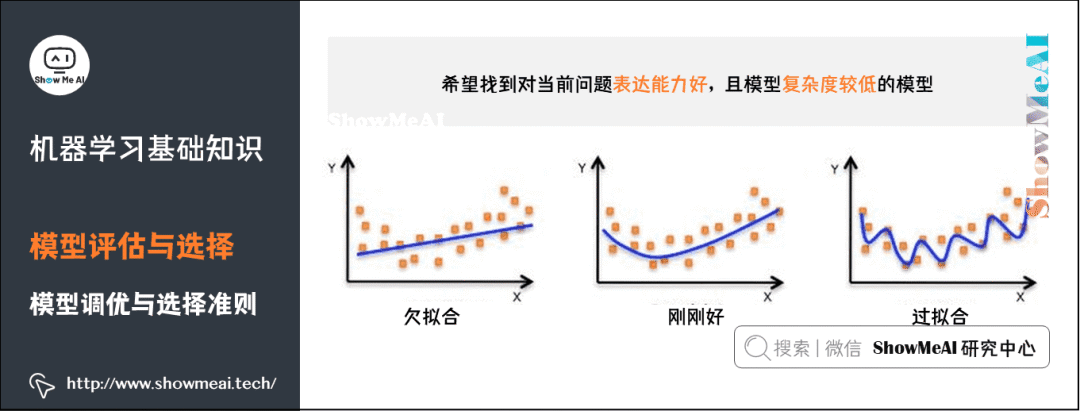
10) Model Tuning and Selection Criteria
-
A model with good expressiveness can learn the patterns and rules in the training data well;
-
A low-complexity model has a smaller variance, is less prone to overfitting, and has better generalization.
11) How to Choose the Optimal Model
(1) Validation Set Evaluation Selection
-
Split the data into training and validation sets.
-
For the prepared candidate hyperparameters, train the model on the training set and evaluate on the validation set.
(2) Grid Search/Random Search Cross Validation
-
Generate candidate hyperparameter sets through grid search/random search.
-
Evaluate the effect of each set of hyperparameters using cross-validation.
-
Select the best-performing hyperparameters.
(3) Bayesian Optimization
-
Hyperparameter tuning based on Bayesian optimization.

END
Edit / Fan Ruiqiang
Review / Fan Ruiqiang
Recheck / Fan Ruiqiang
Click below
Follow us