
Click the above “Beginner’s Visual Learning” and choose to add “Star” or “Top“.
Heavyweight content delivered in real timeAuthor | Peter Pan Xin Source | Xixiaoyao’s Cute Store
I have been dealing with deep learning frameworks for many years. From Google’s TensorFlow to Baidu’s PaddlePaddle, and now Tencent’s Wuliang. I am fortunate to have crossed several companies in China and the US during these explosive years of AI technology, witnessing the world undergo tremendous changes from a relatively good perspective. Throughout these experiences, my perspective has constantly shifted, from early algorithm research to later framework development, to machine learning platforms and more infrastructure, each phase has provided different feelings and deeper insights.
During the Qingming Festival, I took some time to write this article, connecting some interesting episodes in the history of deep learning frameworks from my perspective, along with some stories behind the technology, lest precious memories fade over time.
 TensorFlow
TensorFlow

Introduction
The story begins at the end of 2015 when I ended my work at Google Core Storage and Knowledge Engine and joined Google Brain as a Research Software Engineer under Samy Bengio. The RSWE role was created mainly because Google Brain and DeepMind found it challenging for Research Scientists to solve complex engineering problems in research and ultimately bring technology to fruition. Thus, it was necessary to involve some engineers and scientists with strong engineering capabilities to work together. I was relatively “lucky” to become the first RSWE at Google Brain.
Excited about joining the new group, I visited the Google Brain office a weekend before I started. The thought of working closely with Jeff Dean was a bit thrilling, as I had grown up reading papers like MapReduce, BigTable, and Spanner. The office was unremarkable; Jeff sat with everyone else, but I was surprised to find that a few meters from my workspace was an office doorplate with the names of Google founders Larry Page & Sergey Brin, surrounded by many trophies, certificates, and space suits. It seemed that the company placed a very high value on AI technology.
Back to the main topic, early TensorFlow lacked model examples, and the related API documentation was not very standardized, so I started building a model library for TensorFlow. I spent a year writing models for Speech Recognition, Language Model, Text Summarization, Image Classification, Object Detection, Segmentation, Differential Privacy, Frame Prediction, etc., which later became the prototype of the model zoo on TensorFlow’s GitHub. That year was still a time when low-hanging fruits were everywhere; there were no costly large models like GPT-3. Just making small adjustments to the models and scaling them up could refresh the State-Of-The-Art. Bengio often traveled around the world, and his occasional 1v1 meetings with me provided a lot of guidance. I vividly remember the first time we met; this paper-writing guru wrote some formulas for gradient descent on the whiteboard for me, a novice. In another 1v1, he sent me a draft PDF of a book by Ian Goodfellow, and I spent every night lying on the couch in the break room, experimenting while reading.
That year, an interesting episode occurred: AlphaGo battled human chess players. DeepMind and Brain had a very close collaboration; our group organized a round of paper reading, carefully studying the relevant papers, and then everyone brought beer and snacks to watch the matches, which felt a bit like watching a football game. I learned two things that time: reinforcement learning algorithms and that the English term for Go is Go.
2016 was a year of rapid development for TensorFlow. Jeff’s presentations often featured graphs showing the exponential increase in citations of TensorFlow code. However, 2016 was also a year when TensorFlow faced significant criticism. The granularity of TF’s Operators was very fine, reportedly a lesson learned from the previous generation framework DistBelief. Fine-grained Operators could be combined to form various high-level Layers, offering better flexibility and scalability. However, it posed serious issues for performance and usability, as a model could easily have thousands of Operators. For example:
When I was to implement the first ResNet based on TensorFlow, just writing a BatchNormalization (after checking several internal versions, I found issues with them) required assembling 5 to 10 fine-grained operators through addition, subtraction, multiplication, and division. The 1001-layer ResNet had many BatchNorms, resulting in thousands of Operators throughout the entire ResNet, which, as you can imagine, did not perform well. Soon after, my friend Yao created a Fused BatchNormalization, which reportedly sped up the entire ResNet significantly.
BatchNormalization was just the initial difficulty; when doing Speech Recognition, I spent considerable effort to complete BeamSearch using TensorFlow at the Python level. I wrote an End-to-End model using Seq2Seq with Attention, which could directly convert audio into text. To train the speech recognition data on the production line to convergence, it took 128 GPUs a full two months. Every morning, the first thing I did when I got to work was open TensorBoard to see the Loss drop a little more.
In 2016, TensorFlow’s training mode was mainly based on papers by Jeff and a few others, with asynchronous training based on parameter servers being mainstream. The linear scalability of training speed was good, but today, ring-based synchronous training has gained more traction in NLP and CV. I remember the first time I discussed distributed training for Speech Recognition with Jeff; adding 128 GPUs for asynchronous training could basically guarantee linear scalability, but the synchronous training speed with SyncOptimizer would be much slower. When Jeff asked me if the convergence effect was affected, I was a bit taken aback and said I hadn’t analyzed it in detail, quickly going back to look it up. By the way, gossiping a bit, Jeff is very thin; shaking hands with him felt almost like shaking hands with skin and bones.
After developing some models, I found that algorithm researchers still faced numerous pain points. 1. They didn’t know how to profile models. 2. They didn’t know how to optimize performance. To solve these two problems, I took some time to write tf.profiler. The principle of tf.profiler is quite simple; it analyzes Graph, RunMeta, and some other outputs, allowing users to quickly analyze model structure, Parameters, FLOPs, Device Placement, Runtime, etc., through CLI, UI, or Python API. Additionally, I developed an internal data capture task to collect metrics from the algorithm researchers’ training tasks. If GPU utilization was abnormal, network traffic was excessive, or data IO was slow, it would automatically send an email alert with some modification suggestions.
Getting an algorithm researcher to write a mathematical formula on a whiteboard is not difficult, but getting them to understand complex task configurations, performance issues in distributed systems, and resource and bandwidth problems is indeed a challenging task. No matter how brilliant the researcher, they will always ask why the task didn’t run; is it due to insufficient resources or incorrect configurations? I remember one evening when there weren’t many people around, Geoffrey Hinton suddenly walked over and asked, “Can you do me a favor? My job cannot start…” (Just as I was about to agree, Quoc Lee had already jumped in, what a spirited Vietnamese guy…)

Moonshots
Google Brain organizes a Moonshots proposal every year, many of the later successful projects were incubated this way, such as AutoML, Neural Machine Translation, etc. Team members propose projects that were technically difficult to achieve at the time, and everyone forms interest groups to invest in these projects.

Now, the wildly popular AutoML has, for commercial or other reasons, significantly expanded its original definition. When Brain incubated this project, there were two teams working on LearningToLearn projects; one small team hoped to use genetic algorithms to search for better model structures, while the other team decided to use reinforcement learning algorithms for the search. The genetic algorithm team was relatively cautious with resource usage, typically using only a few hundred GPUs. In contrast, the other team used several thousand GPUs. Ultimately, the reinforcement learning team produced results earlier, which is Neural Architecture Search. Although the other team later used more GPUs to achieve similar results, it was much later.
An interesting episode is that although Brain had tens of thousands of GPUs early on, there was always a shortage during the period leading up to paper submission deadlines, and those working on NAS often received hints in emails. To resolve resource allocation issues, leaders were drawn into a very long email thread, and the eventual solution was to allocate each person a small amount of high-priority GPUs and a reasonable amount of competitive GPUs. The NAS team, having completed the initial capital accumulation, became a very hot project and received special approval for an independent resource pool. To support this strategy, I developed a small tool, which in hindsight seems quite thankless.
 Pytorch
Pytorch

Dynamic Graph
Time flies quickly during a period of rapid growth. After Megan joined Brain, I was assigned to report to her. At that time, the RSWE team had more than a dozen people, and Google Brain had grown from tens to hundreds of people.
In early 2017, through Megan’s introduction, a senior expert from the TensorFlow team, Yuan Yu, approached me, asking if I had followed Pytorch and invited me to discuss it after some research. So I gathered some information on Pytorch online and tried it out. As a deep user of TensorFlow, my first reaction was that Pytorch solved many significant pain points of TensorFlow and felt very “natural” to use.
After talking with Yuan, we quickly decided to try to support a similar imperative programming usage in TensorFlow. The demo development process went relatively smoothly, and I spent about a month on it. I remember I named the project iTensorFlow, short for imperative TensorFlow (later renamed to eager, which felt strange).
The design idea of the demo was not complex: 1. The TensorFlow graph could be split into subgraphs of any granularity, which could be executed directly through function call syntax; 2. TensorFlow transparently records the execution process for backward gradient computation. The user experience felt similar to native Python execution.
This led to several deductions: 1. When the granularity of the subgraph is an operator, it is basically equivalent to Pytorch. 2. When the subgraph consists of multiple operators, it retains the ability for graph-level optimization, allowing for compilation optimization.
Finally, a foreshadowing: 1. tf.Estimator can automatically merge subgraphs to form larger subgraphs. Users can easily debug based on imperative operator-level subgraphs during the development phase. In the deployment phase, larger subgraphs can be automatically merged to form a larger optimization space.
After completing it, I was very excited to demonstrate the results to Yuan. Yuan also said he would help me promote this solution within TensorFlow. At that time, Pytorch was growing rapidly, and the TensorFlow director gathered many expert engineers to explore the solution simultaneously. At that time, I had not yet entered TensorFlow’s decision-making level; the final conclusion was: 1. Let’s form a virtual group dedicated to this project. 2. All previous demos would be scrapped and redone, with TensorFlow 2.0 being released with imperative mode (later renamed to Eager Mode, commonly referred to as dynamic graph in Chinese). I contributed some code as a team member in the project.

Later, a new genius, Chris Lattner, joined Brain; many people in the programming language and compiler field likely know him. He proposed implementing Deep Learning Model Programming using Swift, which later became Swift for TensorFlow. The reasoning was that Python is a dynamic language, making static compilation optimization difficult. I had several in-depth discussions with him, technically agreeing with his viewpoint but clearly stating that Swift for TensorFlow was a challenging path. Using Python was not because Python was a great language, but because many people used Python. Through some exchanges with Chris, I gained a deeper understanding of IR and Pass in the compilation process, which significantly influenced some of my later work in PaddlePaddle.
An episode is that a senior expert from the TensorFlow team once quietly told me, “Python is such a bad language.” I pondered over this statement for a long time, but like him, I didn’t have the courage to say it out loud…
At that time, the dynamic graph project also extended to two other interesting projects. Two guys from other teams wanted to perform syntax analysis on Python to compile control flow. I politely expressed that the possibility of making this a general solution was quite low, but this project was still persistently pursued for a long time and even open-sourced, although it gradually faded away. Another cool project was to construct a deep learning model entirely using numpy. It achieved automatic differentiation through an implicit tape; later, this project seemed to gradually evolve into the JAX project.
API
Later, I gradually transitioned to development in TensorFlow. I remember something impressive happened in 2017 when TensorFlow gained a massive user base; an article titled “TensorFlow Sucks” went viral online. Although I disagree with many points in that article, as many ideas are quite superficial, one thing cannot be denied: TensorFlow’s API is quite painful. 1. The same functionality often has multiple sets of redundant API support. 2. APIs often change and frequently have backward compatibility issues. 3. The usability of the API is not high.
Why did this happen? It may relate to Google’s engineering culture. Google strongly encourages free innovation and cross-team contributions. Often, someone contributes code to another team and uses this as influential evidence for promotion. Therefore, in the early days, when TensorFlow was not particularly mature, external teams often contributed code to TensorFlow, including APIs. Moreover, under Google’s unified code repository, APIs released could be easily upgraded and modified, often requiring just a grep and replace. However, APIs released on GitHub are entirely different; Google employees cannot modify TensorFlow usage code within Baidu, Alibaba, or Tencent. The TensorFlow team did not have a very effective solution early on, and later an API Committee was established to unify the public API’s oversight and planning.
While I was working on vision, I collaborated extensively with an internal vision team at Google, one of which was the slim API. This vision team was very strong and even won the CoCo championship that year. As their models gained popularity, their tf.slim API also became widely circulated. The slim API’s arg_scope utilized the python context manager feature. Those familiar with early TensorFlow know there were also tf.variable_scope, tf.name_scope, tf.op_name_scope, etc. With xxx_scope layered on top, the code became nearly unreadable when it got complex. Additionally, there were various global collections, such as global variable, trainable variable, local variable. In traditional programming language classes, global variables are often used as cautionary tales. However, the algorithm personnel’s perspective is different; with xxx_scope and global collections, they can reduce their code volume. Although we know reasonable programming design methods can achieve this too, algorithm experts likely prefer to spend their time reading papers rather than researching programming design issues.
I remember there were two factions debating in the early days: object-oriented vs. procedural API design.
Based on my educational history, I felt this was not a debatable issue. Keras’s Layer class and Pytorch’s Module class are undoubtedly very elegant in object-oriented interface design. However, in reality, there was indeed very heated debate at that time. Some authors of functional APIs argued that functional calls save code significantly: if a function can solve the problem, why construct an object first and then call it?
In the early development of TensorFlow’s dynamic graph capabilities, we repeatedly discussed the design scheme for interfaces in 2.0. As the cannon fodder, I took on the task of writing the demo.
After two weeks of seclusion, I proposed a scheme: 1. Reuse Keras’s Layer interface. 2. However, do not reuse Keras’s Network, Topology, and other higher-level complex interfaces.
The main reasons were: 1. Layer is very concise and elegant; a Layer can be nested inside another Layer, making the entire network a large Layer. Abstracting Layer into construction and execution phases is also very natural. 2. Keras has many high-level interfaces designed for extreme simplicity historically. Based on my personal experience, I felt it was challenging to meet users’ flexible needs, and there was no need for official provision. Moreover, this could lead to overly complex TensorFlow API layers.
Later, the scheme was partially adopted; the big shots hoped to reuse more Keras interfaces. In fact, there is no perfect API, only APIs best suited for certain groups. An interesting episode is that Keras’s author, François, was also at Google Brain. To use Keras’s interfaces in both TensorFlow 2.0’s dynamic and static graphs, many modifications had to be made within the Keras API. Usually, François was very reluctant when reviewing code, but in the end, he often compromised. Many times, especially on technical issues, the truth may lie with a few people who are not understood by the majority and requires time to discover.

TPU
In the years when internet companies were truly maturing and widely using AI chips, only Google managed to do so. TPU has always been a key focus for Google Brain and the TensorFlow team. The reason might be that Jeff often mentioned this, and at one point, optimizing GPU for TensorFlow seemed a rather unpromising endeavor.
TPUs have a unique feature in that they use the bfloat16 type. Nowadays, bfloat16 and NVIDIA’s latest TF32 on GPUs are widely recognized. At that time, it was a significant innovation.
The principle of bfloat16 is very simple: it truncates the last 16 bits of float32. Compared to IEEE’s float16, bfloat16 has fewer mantissa bits but more exponential bits. Retaining more exponential bits helps prevent gradients from disappearing when they are close to zero, ensuring that bfloat16 can better preserve model performance during training. In contrast, training based on float16 often requires loss scaling and other adjustments to achieve similar results. Therefore, bfloat16 allows AI chips to compute faster while ensuring that convergence effects typically do not suffer losses.
To fully support bfloat16 on TensorFlow, I spent considerable effort. Although there were previous communication solutions based on bfloat16, many tasks had to be seamlessly integrated everywhere, which required a lot of work. For example, eigen and numpy did not support this special type. Fortunately, they could both extend data types (though documentation was scarce). Then I had to fix hundreds of failing unit tests to prove that bfloat16 could be used comprehensively at the Python level.
TPU is a highly complex engineering project that spans teams and technical stacks. It is said that a very talented Google engineer spent half a year supporting depthwise convolution on a TPU kernel.
This is not an exaggeration; aside from the underlying hardware design, just compiling TensorFlow graphs into hardware binaries with the XLA project involved at least dozens of people early on. From HLO to the underlying target-specific code generation, the TensorFlow C++ layer was almost entirely rewritten, far more complex than the previous interpreter.
Once TPU training ran smoothly at the lower level, I completed the supporting API for the Python layer based on the underlying interface and implemented several models. At that time, I encountered several challenges; some were resolved within weeks, while others persisted for years after I left the team. Here are a few examples.
- At that time, a TPU Pod (I believe it had 512 chips) was so fast that even complex model calculations would get stuck on data IO and preprocessing. Later, I created a distributed data processing system that processed data simultaneously across multiple CPU machines to feed the TPU.
- The earlier TPU API had relatively weak usability. Usually, a model needed to train on TPU for several steps before returning to the Python layer; otherwise, TPU performance would degrade rapidly. This was very unfriendly to algorithm personnel, meaning a lack of debugging capabilities and many complex models could not be implemented. I remember that year, the OKR was forced to lower the goal to support common CV models.
- How to support dynamic graphs on TPU. I remember that due to TPU constraints, I created a so-called JIT capability. The Estimator would first iterate N steps on CPU or GPU for initial debugging, then automatically deploy to TPU. From the perspective of algorithm personnel, this satisfied the ability for single-step debugging while allowing the main training process to utilize TPU.
Team
Google Brain is a fascinating team. To be blunt, in the years following 2015, it captured over half of the world’s key technological breakthroughs in deep learning, such as TPU, TensorFlow, Transformer, BERT, Neural Machine Translation, Inception, Neural Architecture Search, GAN, Adversarial Training, Bidirectional RNN, etc. This team not only included Turing Award winners in deep learning but also top experts in programming languages, compilers, computer architecture, and distributed systems, as well as experts in biology and physics. When Jeff brought these people together, magical chemical reactions occurred, accelerating the pace of technology changing the world.
 PaddlePaddle
PaddlePaddle

Paddle actually originated quite early, reportedly around 2013-2014, from Professor Xu Wei’s work. Later, Andrew Ng thought that Paddle was not enough, so it was renamed PaddlePaddle. Paddle had similar problems as Caffe from that era, lacking flexibility. Many components were written in C++ as relatively coarse-grained Layers, making it impossible to quickly construct models using simpler programming languages like Python.
Later, in the second half of 2017, the team began to completely rewrite a framework while inheriting the Paddle name. By the end of 2017, the domestic Paddle team reached out to me, inviting me to lead the domestic R&D team for Paddle. Embracing the ideal of creating the first domestic framework, I accepted the invitation and started in Beijing a month later.
Early Design
When I joined the team, the new Paddle was still a relatively early prototype system, with some designs already developed. I found that some design concepts had clear differences from TensorFlow, but the implementation mimicked TensorFlow.
Language Simulation
The designers hoped to create a programming language to build deep learning models (similar to Julia, which embeds deep learning model features into programming languages). However, in implementation, I found it was quite similar to TensorFlow. Both declare a static model structure through Python and then hand the model structure over to an executor for interpretation. No new deep learning programming language was invented.
I did not make adjustments to this design. Essentially, it was no different from TensorFlow’s early static graphs. However, in detail, TF-based Graph models can selectively execute any subgraph through feed/fetch, making it more flexible. Paddle’s counterpart to Graph is Program. Program behaves like a normal program, only able to execute completely from start to finish without selective execution. Therefore, Paddle simplified this area, but it could supplement the lack of flexibility by constructing multiple Programs at the Python level; overall, the expressive power is sufficient.
Transpiler
The Transpiler directly rewrites the Program, allowing the model to run distributed or be optimized. The initial intention was good, aiming to reduce the difficulty for algorithm personnel. However, in implementation, it initially directly modified the Program structure at the Python level. Later, I redesigned an IR + Pass compiler system to achieve this in a more systematic way.
LoDTensor
Perhaps due to the team’s strong NLP and search background, there was a high emphasis on variable-length sequences. Paddle’s underlying data is LoDTensor, rather than a Tensor like other frameworks. LoDTensor couples variable-length sequence information into the Tensor. This can lead to many issues, as many Operators are completely sequence-independent and cannot process the relationship between sequence information in input and output Tensors, leading to random processing and creating robustness issues for the framework. Although I have always wanted to promote the decoupling of sequence information from Tensor, for various reasons, I did not thoroughly complete this reconstruction goal and hope to rectify it in the future.
Performance
At the beginning of 2018, Paddle was still a prototype system. Due to OKR goals, the team had begun to preliminarily integrate some business scenarios. One significant pain point was that performance was too poor. The speed on a single machine with a single card was very slow, with an acceleration ratio of only 1.x for a single machine with four cards. However, pinpointing performance issues was quite challenging. I spent some time writing profiling tools, such as timelines. Some obvious performance issues could be quickly identified and fixed.
However, the speed on multiple cards was still very slow. After timeline analysis, I found that there was a ParallelOp with a large number of barriers. I rewrote it as a ParallelExecutor, deploying the Program N times on multiple cards, inserting AllReduce communication operators, and having these N operators, based on graph dependencies, continuously throw ready operators into a thread pool for execution. Even so, we found that for performance on multiple cards, different models required different thread scheduling strategies to achieve optimal performance. It was challenging to have a perfect one-fits-all solution. Later, we discussed how to support different operator scheduling strategies through an IR + Pass method.
Distributed training also encountered many problems. Initially, it used gRPC, spending considerable effort on parallel requests, then switched to brpc, making many optimizations in RDMA, among others. The performance of distributed training gradually improved. Additionally, to achieve automated distributed deployment, the aforementioned Transpiler became increasingly complex as the scenarios increased, leading to more complicated Python code.

Model inference faced very strong competitors within the company. Anakin’s GPU inference speed was indeed fast, and I was surprised to learn that they developed a large number of basic operators using SASS assembly, performing exceptionally extreme optimizations for the Pascal architecture, even outperforming TensorRT in certain scenarios. I have always advocated that training and inference should ideally use the same framework, and there is no need for a separate inference framework to solve performance issues. Using different frameworks for inference can lead to many unexpected accuracy problems and manual overhead.
Due to performance issues with inference, we engaged in a prolonged competition with brother teams. As a military strategist, I fully leveraged the team’s technological accumulation in CPUs and our good relations with Intel to often gain an edge in CPU inference scenarios. In GPU aspects, due to the opponent’s bottomless use of assembly and our front lines being too numerous with insufficient personnel, we had to strategically abandon some head models, instead supporting subgraph extensions of the TensorRT engine to leverage Nvidia’s technological advantages to launch offensives in many common scenarios. Looking back now, it was indeed an interesting experience.
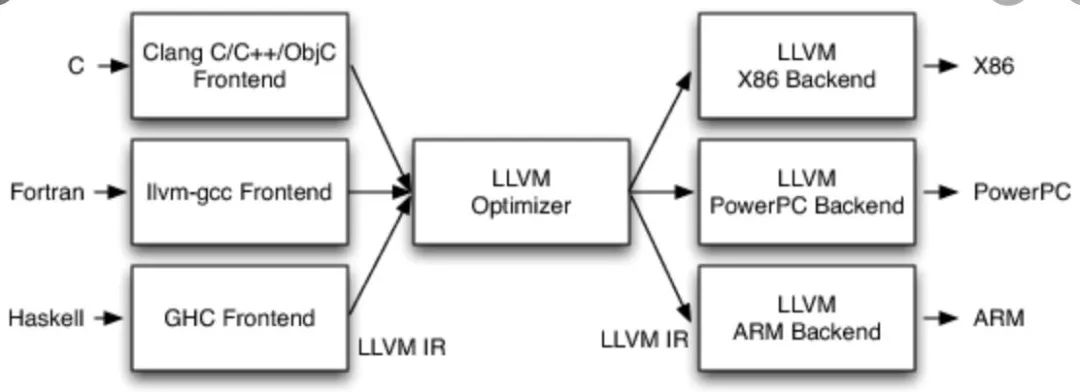
Intermediate Representation & Pass
The Intermediate Representation + Pass model is mainly inspired by the architecture of LLVM. In compilers, it is used to solve the problem of compiling any of M programming languages to execute on any of N hardware devices. A simple solution would be to write a compiler for each programming language and hardware, which would require M*N compilers. Clearly, this is very high cost for complex compiler development.
Intermediate Representation is a typical embodiment of abstract capability in architectural design. Different programming languages have varying levels of abstraction, or merely differences in functionalities supported. However, these programming languages ultimately need to execute on some hardware instruction set. Therefore, during compilation, they form a common expression at some abstract level. The IR + Pass method effectively utilizes this. The basic idea is to gradually rewrite different language expressions into a unified IR representation through multiple layers of Pass (the compilation rewriting process). In this process, the expression gradually approaches the underlying hardware. Moreover, IR and Pass can be reused effectively, significantly reducing development costs.
Deep learning frameworks also have very similar needs.
- Users wish to describe the execution logic of models through high-level languages, or even just declare the model structure without worrying about how the model will be trained or inferred on hardware.
- Deep learning frameworks need to solve the problem of efficiently executing models on various hardware, including coordinating multiple CPUs, GPUs, and even large-scale distributed clusters. It also involves optimizing memory, GPU memory costs, and improving execution speed.
More specifically, as mentioned earlier, there is a need to automatically parallelize user-declared model Programs across multiple GPUs, split Programs for distributed computing across multiple machines, and modify execution graphs for operator fusion and memory optimizations.
Paddle initially conducted the above-described work in a scattered manner, rewriting models in distributed, multi-GPU parallel processing, inference acceleration, and even model compression quantization. This process easily led to repetitive work and made it challenging to unify design patterns, making it difficult for different teams to quickly understand the code.
Realizing these issues, I wrote a Single Static Assignment (SSA) Graph, then transformed the Program into the SSA Graph through the first basic Pass. I wrote a second Pass to convert the SSA Graph into a multi-GPU parallel SSA Graph.
The subsequent processes can be inferred. For example, inference acceleration can be implemented based on this with OpFusionPass, InferenceMemoryOptimizationPass, PruningPass, etc., to achieve inference acceleration during execution. For distributed training, there can be DistributedTransPass, and for quantization compression, there can be ConvertToInt8Pass, etc. This whole set essentially resolves the Compiler problem from top-level Program declarations to the underlying executor.
During this process, I indeed encountered considerable resistance. For instance, the early distributed logic was completed through Python, needing to migrate to the C++ layer. The development of compression quantization preferred Python, while IR & Pass was based on C++. There were also dependencies and debugging issues between different Passes.
Complete Set of Deep Learning Framework Tools
TensorFlow Everywhere was originally a slogan from the TensorFlow team, meaning that TensorFlow needs to support deep learning models running in any scenario, thus achieving the goal of AI Everywhere. Deep learning frameworks hope to become the “operating system” for AI, just as fish cannot live without water, and apps cannot exist without iOS/Android.
Paddle, as a comprehensive counterpart to TensorFlow, naturally also hopes to provide a complete set of solutions. In the early days, Paddle collaborated with other teams to develop PaddleMobile, providing inference capabilities on mobile devices. Later, Paddle.js was developed to support inference capabilities in H5, Web, and other scenarios. To support B2B, Windows support was added on top of Linux. To support devices like self-driving cars, it also expanded to run on more different devices.
For example, PaddleMobile faces many challenges when deploying deep learning frameworks on mobile devices. Mobile devices have much smaller space and computing power than servers, and models initially trained on servers are relatively large, requiring various approaches. 1. Use smaller model structures. 2. Reduce model size through quantization and compression.
Additionally, mobile deep learning frameworks are usually based on ARM CPUs, with GPUs like Mali GPU and Adreno GPU. To pursue extreme performance, assembly language is often required. One colleague wrote that by the end, he almost doubted his life, feeling that what he learned in college was not quite right. To avoid significantly increasing the size of the app, the compiled framework must be at the level of KB to a few MB, so selective compilation based on the operators used in the deployed model structure is necessary. In extreme cases, it even required directly generating the necessary code for forward computation through C++ Code Gen, rather than using a universal interpreter.
Review
As project complexity increased, many tricky issues gradually shifted from deep learning domain technical problems to software engineering development and team management issues. As the team underwent constant changes, I sometimes found myself acting as a leader addressing problems, while at other times I was an independent contributor participating in discussions. I am grateful to have gone through this phase; some issues can only be understood clearly after personal experience, and sometimes it is about finding the direction to move forward amid constant compromise and exploration.
 Wuliang
Wuliang
Wuliang is a deep learning framework built by Tencent’s PCG, mainly aimed at solving training and inference problems in large-scale recommendation scenarios. The application of deep learning in recommendation scenarios differs from CV, NLP, and speech.
- Business continuously generates user behavior data. When the user base reaches tens of millions or even hundreds of millions, massive training data will be generated, such as user profiles, user clicks, likes, shares, and context, etc.
- This data is highly sparse, usually encoded into ID-type features and then entered into model training through embedding. As the business scale increases and feature engineering becomes increasingly complex, such as the accumulation of users, products, and content, along with the use of feature crosses, the volume of embedding parameters can reach GB or even TB levels.
- Recommendation scenarios change dynamically in real-time, with new users, content, and trends continually emerging. User interests and intentions gradually shift, so models need to continuously adapt to these changes, always maintaining the best state.
Adjustments
By mid-2019, this project had about 2-3 people. The team hoped to develop a new version based on TensorFlow to enhance it so that Wuliang could reuse existing capabilities of TensorFlow while supporting the special needs of recommendation scenarios. Initially, Wuliang adopted a parameter server-based architecture. TensorFlow was reused to provide Python APIs and execute basic operators. However, aspects like parameter servers and distributed communication were developed independently without reusing TensorFlow.
This choice was relatively reasonable given the team’s circumstances at the time. Choosing another direction, modifying TensorFlow at a lower level, would have posed significant research and development challenges and likely diverged from the community version of TensorFlow, making version upgrades difficult. By using TensorFlow as a locally executing library, development could occur externally without needing to understand TensorFlow’s internal complexity, while also reusing some other open-source components like pslib.
Early on, the software development process was relatively lacking. To ensure engineering progress, I helped with some foundational work, such as adding the first automated tests and continuous integration, and refactoring and simplifying some excessive encapsulations and odd code.
Additionally, I made some adjustments at the interface layer. Originally, once the framework started executing, it entered the C++ executor, unable to provide or return any execution results from the Python layer and unable to execute logic for plugin-based extensions at the Python level. To meet expected users’ future debugging needs, I simulated tf.Session and tf.Estimator to refactor the interface for the execution layer. This way, users could debug the execution process step by step using the feed/fetch method. They could also extend any logic before and after execution via hooks, enhancing the framework’s applicability.
Another issue was that the Python layer was essentially a global variable, making it challenging to encapsulate multiple models. Unlike TensorFlow, which has Graph instances or Paddle with Program instances. Since the restructuring of the Python layer required substantial changes, I temporarily added a Context encapsulation to forcefully encapsulate various states and configurations within the Context. Considering that there might not be more complex needs in the short term, I did not complete this task.
I also made some refactoring in the reader section. Initially, that section’s threading model was exceptionally complex, partly because the underlying infrastructure, like distributed file systems, could not provide a better SDK, forcing many logics to be embedded within the deep learning framework, such as local file caching. Given the complexity of feature processing logic and the fact that some older TensorFlow users might be accustomed to basic operator libraries like tf.Example and tf.feature_column, I introduced a TensorFlow-based tf.dataset in the reader layer. However, later I found that users seemed more concerned about performance issues and preferred to solve feature processing through custom C++ libraries.
API design is a challenging problem. TensorFlow, Paddle, and Wuliang have not escaped this. In a collaborative team, each developer often focuses more on whether each independent function is completed rather than considering the overall API design style, usability, and compatibility, which are often overlooked during rapid iterations. Unfortunately, APIs often cannot be optimized later like internal implementations. Once APIs are released to users, subsequent modifications often break the correctness of user code. Many times, I can only review them myself.
Upgrades
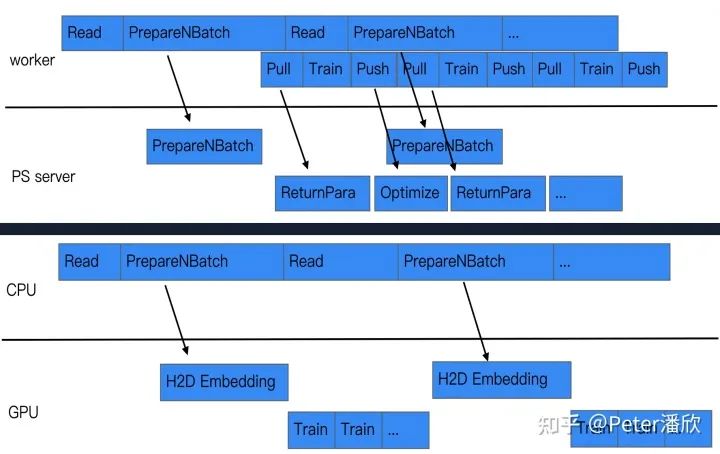
After a year of refining basic capabilities, Wuliang gradually became the unified large-scale recommendation model training and inference framework for the entire business group, supporting dozens of business scenarios and producing thousands of incremental and full models daily. Simply completing functions could no longer meet the demands of business and team development; more cutting-edge technology was needed.
Data Processing
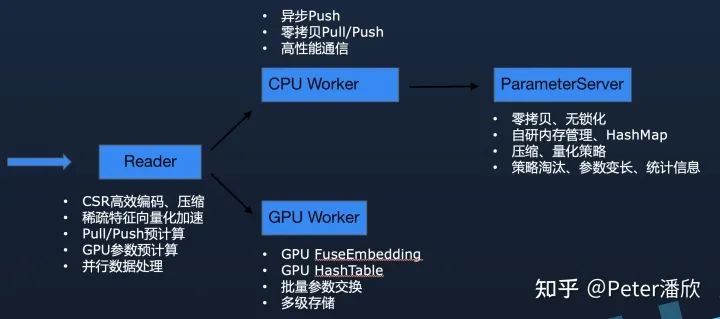
Data formats need to shift from plaintext to more efficient binary. Additionally, sparse data based on CSR encoding can further reduce extra overhead during data processing.
Pipeline
Efforts should be made to excavate places that can be parallelized during training, increasing concurrency and thus speeding up training. For instance, during data reading, data can be pre-partitioned according to the scale of parameter servers and informed to the parameter servers in advance about which parameters need to be prepared. This way, when pulling/pushing, calculations can be completed faster, thereby increasing the speed of each minibatch.
Similarly, when training with GPUs, during the parallel data IO process, future needed embedding parameters can be pre-computed. Thus, when the GPU trains the next round of data, the embeddings needed have already been computed and can be trained immediately, reducing waiting time.
Customized Parameter Server
Since Wuliang addresses a critical issue of massive parameters in recommendation models, the parameter server must be highly optimized. Moreover, it should reasonably incorporate domain knowledge of recommendation models into the design to produce differentiated advantages through special strategies.
Customized threading models, memory management, and HashMaps are necessary. Since parameters are divided and assigned to different threads, parameters can be processed without locks during each pull/push. Additionally, due to the massive parameter consumption, memory space needs to be managed through customized memory pools. Otherwise, there might be significant memory fragmentation that cannot be promptly returned to the operating system in the default memory library. Moreover, there is a lack of precise control over memory clearing mechanisms, leading to memory OOM or waste. Customized memory management can solve these issues, and even through special memory eviction strategies, further reduce memory costs without compromising model performance. High-performance HashMaps are also needed to solve the rapid add, delete, modify, and query issues with embeddings.
There are also many areas for improvement in managing embedding vectors. 1. Dynamically change the length of embedding vectors to support model compression and enhance model performance. 2. Extend embedding metadata to record statistics like popularity and click-through rates, which can help improve cache hit rates in advanced distributed architectures for training inference, as well as model training effects. 3. The recovery and export mechanisms of models in large-scale embedding scenarios can enable real-time loading of model updates during serving. Additionally, issues like resource scaling after task failures and restarts need to be considered.
GPU Training
Under the traditional PS architecture training model, due to limited computing power of a single machine, it requires dozens or even hundreds of instances for distributed training. However, this leads to significant computation being wasted on ineffective overhead, such as handling sparse features on both sides of network communication. Such additional overhead often exceeds effective computation.
GPUs and corresponding high-speed network connections can solve this issue. A single 8-card machine connected through NVLink can even exceed the performance of dozens of physical machines, offering better cost-effectiveness. However, due to the massive parameters in the hundreds of GB or even TB range and the embedding GPU computation issues, GPUs have not been widely utilized.
However, experiments have shown that sparse features exhibit a significant Power-law distribution, where a small number of hot features are used far more than a large number of non-hot features. Therefore, by statistically analyzing features during data processing and batch-loading the embeddings that will be needed in the future into the GPU, it allows the GPU to conduct continuous training for extended periods without needing to frequently swap parameters with CPU memory.
GPU Prediction
As the complexity of recommendation models increases, introducing traditional CV and NLP structures requires more computation. CPUs often struggle to complete inference on large candidate sets (hundreds or thousands) within effective time delays (tens of milliseconds). GPUs have thus become a potential solution.
Similarly, GPU inference also needs to address the issue of GPU memory being far smaller than embedding parameters. By pre-computing hot embeddings during training and loading them into the inference GPU, this issue can be alleviated to some extent. During inference, only a few embeddings that are not cached in GPU memory need to be copied from CPU memory into the GPU.
Moreover, model quantization and compression can further reduce the scale of embedding parameters. Experiments show that when most of the embedding parameter values are controlled to zero, the model can still perform similarly to its original effect, or even slightly better.
 Summary
Summary

The development of deep learning algorithms and deep learning frameworks complements and promotes each other. Since the publication of the Torch paper in 2002, the technological development of frameworks has been relatively slow, with performance not significantly improving, preventing exploration of more complex algorithm models or utilizing larger datasets.
After 2010, frameworks like Caffe and Theano gradually appeared, enabling the training of more complex CNN and RNN models through the introduction of higher-performing GPUs, significantly accelerating the development of deep learning algorithms.
Between 2014 and 2017, the emergence of TensorFlow allowed users to assemble various model structures using simple Python language. Moreover, models could be easily trained in a distributed manner and automatically deployed on servers, mobile phones, cameras, and various devices. Pytorch’s dynamic graph usage met researchers’ higher requirements for usability and flexibility, further advancing algorithm research.
During this wave, domestic deep learning framework technology kept pace with the world. Paddle emerged around 2014, accumulating a certain user base domestically, and was basically comparable to other frameworks at that time. Although with the emergence of more advanced frameworks like TensorFlow and Pytorch, the domestic field missed precious opportunities for technological upgrades and community ecosystem cultivation, we saw that between 2018 and 2020, new versions of PaddlePaddle, OneFlow, MindSpore, and other deep learning frameworks were successively open-sourced, gradually catching up in technology.
The booming recommendation scenarios in e-commerce, video, news, and many leading internet companies have led to the consumption of AI hardware in recommendation systems exceeding the total consumption in traditional NLP, CV, and speech applications in internet companies. Many companies began to customize and optimize deep learning frameworks for the special needs of recommendation scenarios (as well as advertising and search). Baidu’s abacus is an early framework, and like other early frameworks, it suffers from usability and flexibility issues. Wuliang and XDL have made improvements, balancing community compatibility, algorithm usability, and system performance.
The reach of deep learning frameworks extends far beyond what we commonly see. With the promotion of AI technology, many excellent deep learning frameworks have emerged in scenarios such as Web, H5, embedded devices, and mobile phones, such as PaddleMobile, TFLite, tensorflow.js, and more.
The technology of deep learning frameworks is also gradually expanding from more dimensions. ONNX was proposed as a unified model format, although it still has a long way to go and many issues to solve. However, its popularity shows the community’s desire for interoperability between frameworks. As Moore’s Law becomes harder to maintain, frameworks are increasingly seeking breakthroughs from new hardware and heterogeneous computing fields. To support the execution of massive operators on various AI chips, including CPU, FPGA, GPU, TPU, NPU, and Cerebras, TVM and XLA draw on decades of accumulated compiler technology to continue exploring on this challenging path, often bringing good news of new progress. Deep learning frameworks are no longer limited to deep learning but are also shining in areas like scientific computing and physical chemistry.
 End
End 
Disclaimer: Some content is sourced from the internet and is intended for academic exchange purposes only. The copyright of the article belongs to the original author. If there are any issues, please contact for deletion.
Good news!
Beginner's Visual Learning Knowledge Planet
is now open to the public 👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply: Extension Module Chinese Tutorial in the backend of "Beginner's Visual Learning" public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Projects 52 Lectures
Reply: Python Visual Practical Projects in the backend of "Beginner's Visual Learning" public account to download 31 visual practical projects, including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply: OpenCV Practical Projects 20 Lectures in the backend of "Beginner's Visual Learning" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to exchange with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided later). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiaotong University + Visual SLAM". Please follow the format; otherwise, access will not be granted. After successful addition, you will be invited to relevant WeChat groups based on research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~