
Delivering NLP technology insights to you every day!
Introduction
Today I want to share with you a paper on Chinese Named Entity Recognition by Professor Zhang Yue from Westlake University, published at the ACL conference in 2018, titled Lattice LSTM.
Paper Title: “Chinese NER Using Lattice LSTM”
Paper Link: https://arxiv.org/pdf/1805.02023.pdf
Code Repository: https://github.com/jiesutd/LatticeLSTM
The main reason for sharing this work is that it is of high quality and can be considered the pioneering work on vocabulary enhancement for Chinese NER, with clear ideas and innovative reasoning.
This article will focus on the following two points illustrated in the figure below:

1. Issues with Sequence Labeling-Based Entity Recognition
As shown in the figure below, this section mainly contains two parts: the classic LSTM-CRF entity recognition model and the issues associated with such models.

1.1 Classic LSTM-CRF Model
Entity recognition is typically treated as a sequence labeling task, where sequence labeling models need to predict entity boundaries and entity types to identify and extract the corresponding named entities. Before the advent of BERT, the SOTA model for entity recognition was LSTM+CRF, which is quite simple:
-
First, use embedding methods to convert each token in the sentence into a vector and input it into LSTM (or BiLSTM);
-
Then, use LSTM to encode the input information;
-
Finally, use CRF to label the sequence based on the output of LSTM.
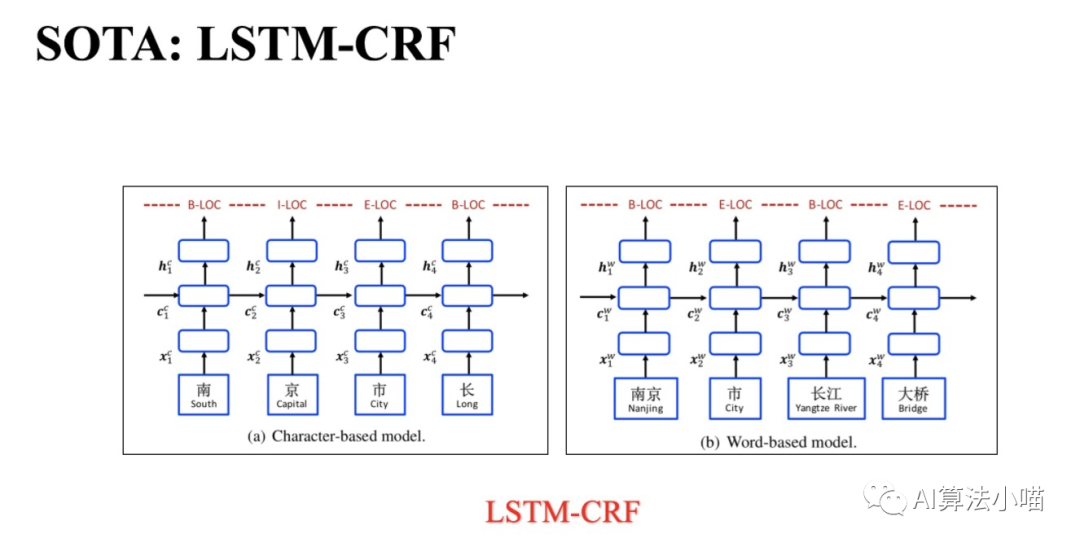
LSTM+CRF applied to Chinese NER can be further divided into two types: if the token is a word, the model is a Word-based model; if the token is a character, the model is a Character-based Model.
( Note: BERT+LSTM+CRF mainly replaces the embedding method from Word2vec to BERT.)
1.2 Error Propagation and Ambiguity Issues

-
Word-based models have error propagation issues
Word-based models require word segmentation before performing entity recognition, which means that word sequence labeling is necessary. The boundaries of words determine the boundaries of entities, so any segmentation error will affect the determination of entity boundaries. For example, in the figure above, using a segmentation tool, “东莞台协” and “会长” were split into “东莞”, “台”, “协会长”, ultimately causing “东莞台” to be recognized as GPE. In other words, Word-based models have the same error propagation issues as other two-stage models.
-
Character-based models have ambiguity issues
Since word segmentation can be problematic, why not avoid it altogether? Character-based models perform entity recognition directly at the character level, or character sequence labeling. Many studies indicate that character-based methods outperform word-based methods in Chinese NER. However, compared to words, single characters do not have complete semantics. Without utilizing the information from words in the sentence, it is difficult to handle ambiguity, and the recognition results may be unsatisfactory. For example, in the figure above, the character “会” should ideally combine with “长” to form “会长”, but the final model treats “会” and “东莞台协” as one entity and predicts “东莞台协会” as ORG.
1.3 Reflection
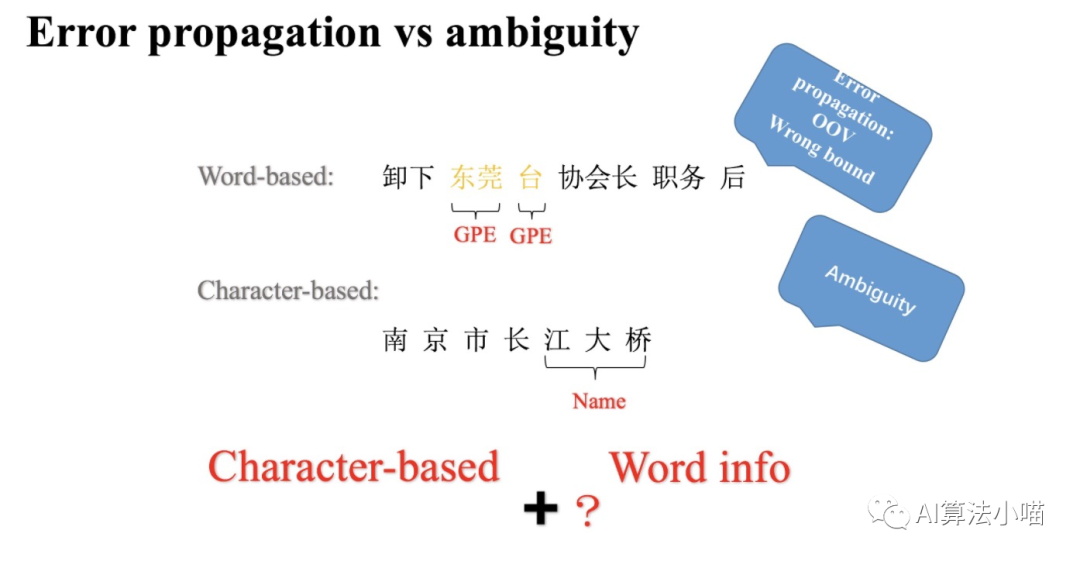
Given that both Character-based models and Word-based models have their pros and cons, could we combine the two for mutual benefit? In other words, can we incorporate word information into the Character-based model to take advantage of word information without being affected by segmentation errors? In fact, Lattice LSTM does exactly this. Let’s follow the subsequent content of this article to learn about Lattice LSTM.
2. Model Details
In this section, we will first introduce the simplest method for utilizing word information, followed by a detailed introduction to Lattice LSTM.

2.1 Simple Direct Concatenation Method
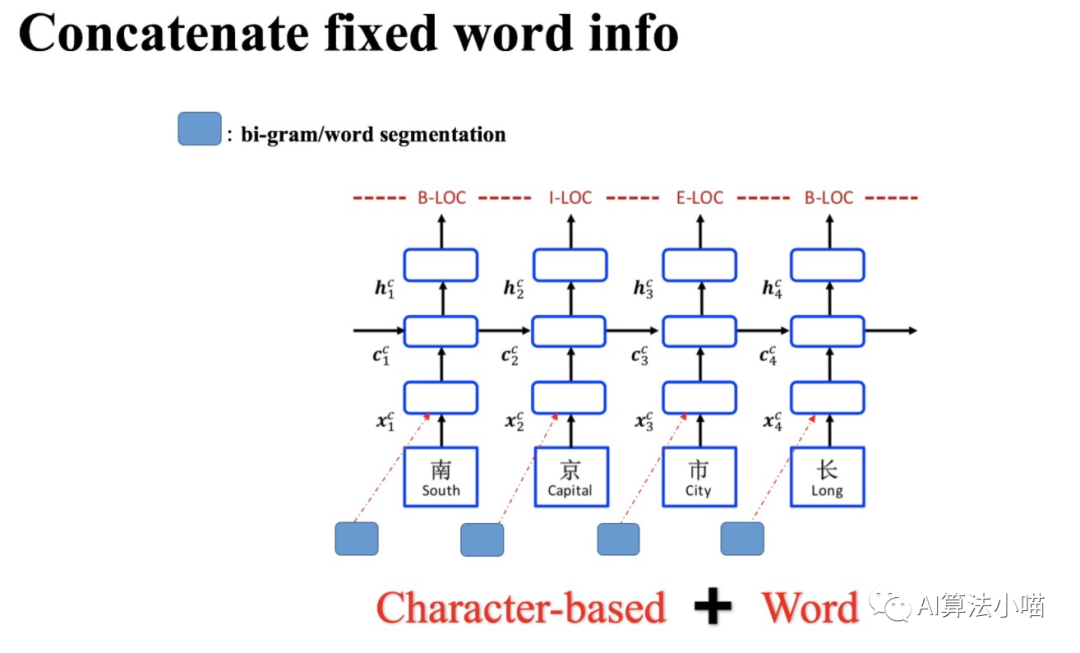
As shown in the figure, the most straightforward and simplest method for utilizing word information is to directly concatenate word representations with character vectors or directly concatenate word representations with the output of LSTM. The 2016 paper “A Convolution BiLSTM Neural Network Model for Chinese Event Extraction”[1] adopted this method to construct a Chinese event extraction model, with the model structure illustrated below:
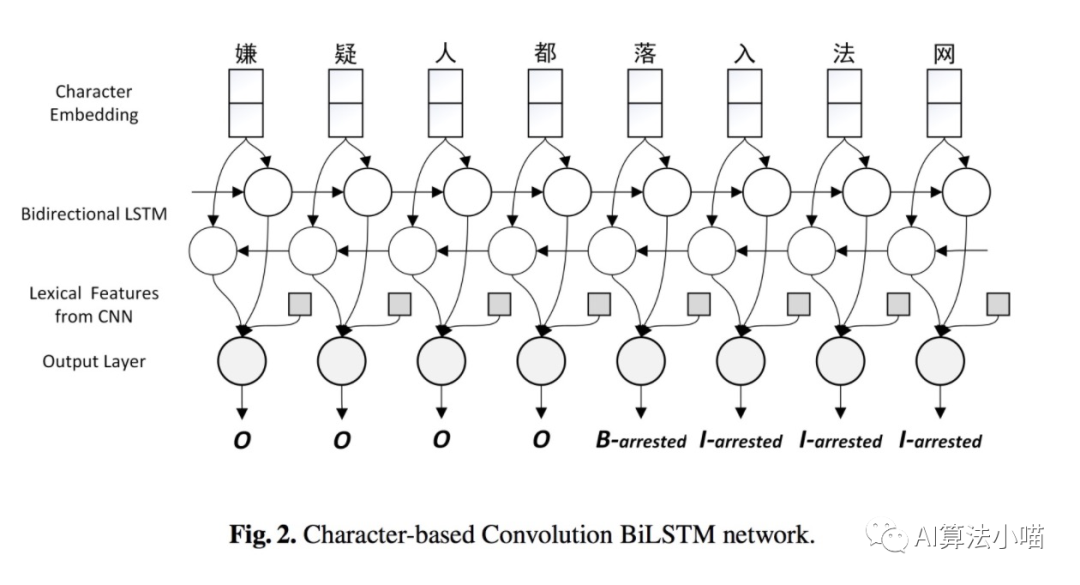
Of course, word representations can be obtained through Word2Vec, Glove, and other word vector models. Alternatively, as in the 2016 event extraction paper, CNN can be used to further convolve and obtain higher-level Local Context Features, which can then be concatenated into the model:
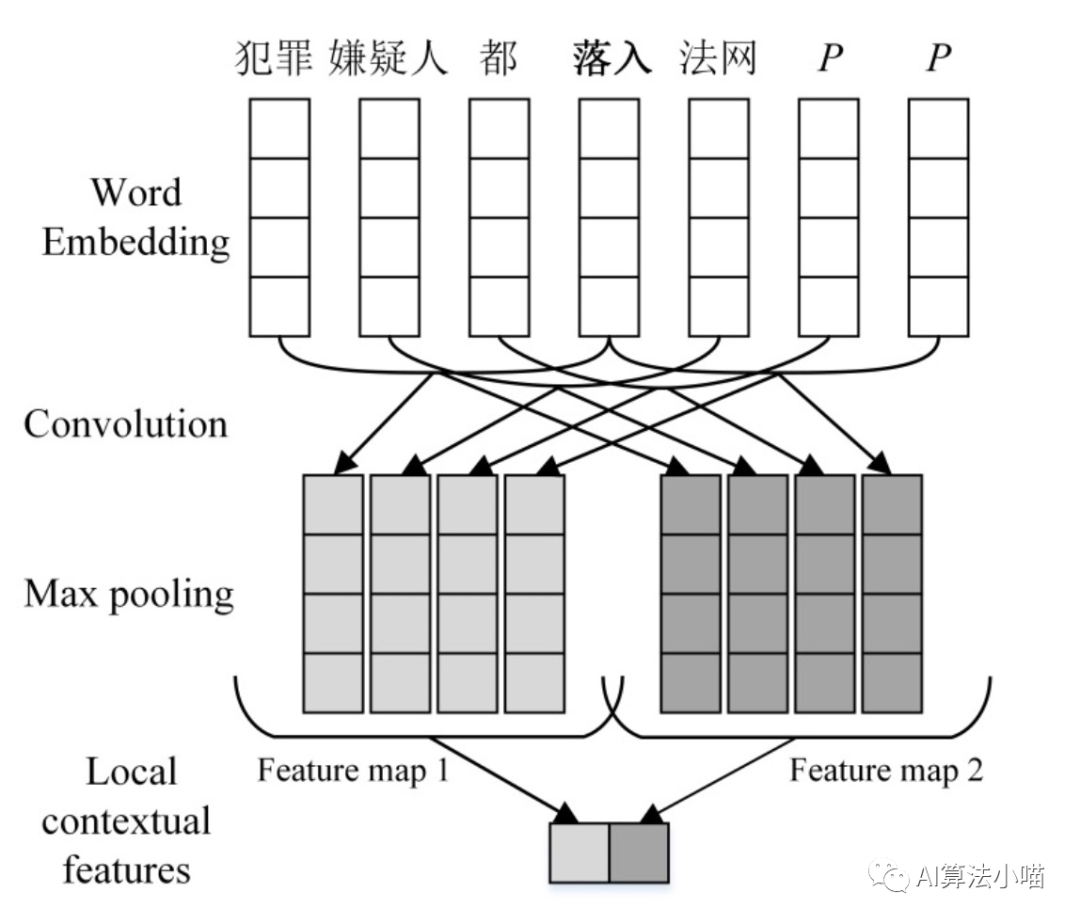
However, this is not the focus of this article; we are more interested in how Lattice LSTM incorporates word information.
2.2 Lattice and Potential Words
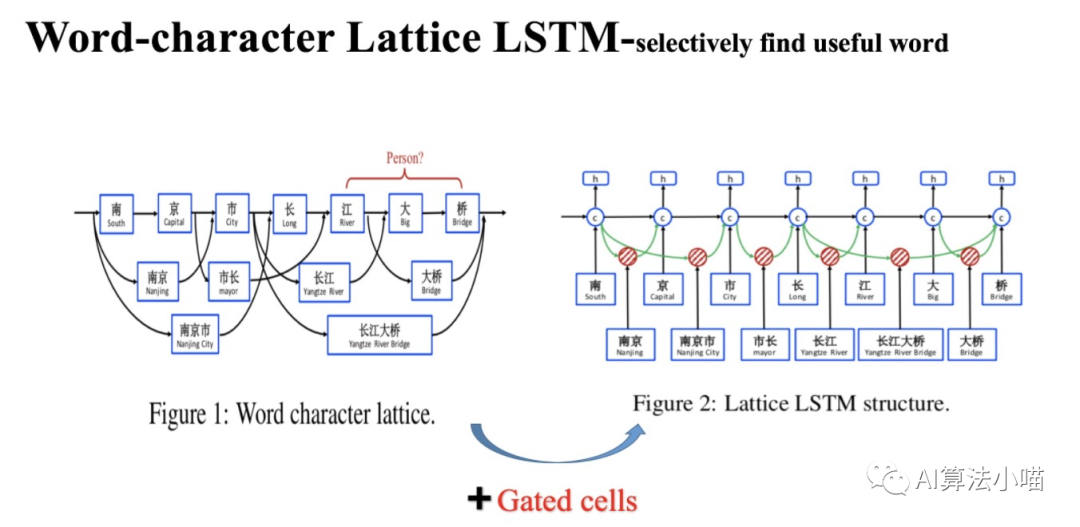
The structure of the Lattice LSTM model is shown on the right side of the figure above. Before formally introducing Lattice LSTM, let’s first take a look at the left part of the figure.
(1) Origin of the Name Lattice LSTM
We can see that in the network shown on the left side of the figure, in addition to the main part based on character LSTM, there are also many “lattices” connected, each containing a potential word. The information contained in these potential words will be merged with the corresponding Cell in the main LSTM, resembling a “grid (lattice)”. Hence, the model is named Lattice LSTM, meaning that it is an LSTM model with a grid structure.
(2) Obtaining Potential Words through Dictionary Matching
These potential words in the lattice are obtained by matching the input text with a dictionary. For example, by matching with the dictionary, the phrase “南京市长江大桥” contains potential words such as “南京”, “市长”, “南京市”, “长江”, “大桥”, and “长江大桥”.
(3) The Impact of Potential Words
Firstly, the correct result for the sentence “南京市长江大桥” should be “南京市-Location”, “长江大桥-Location”. If we directly use the Character-based model for entity recognition, the result may be: “南京-Location”, “市长-Position”, “江大桥-Person”. Now, by using dictionary information, we have obtained the potential words for the text: “南京”, “市长”, “南京市”, “长江”, “大桥”, and “长江大桥”. Among them, the introduction of words like “长江” and “大桥” helps the model avoid errors like “江大桥-Person”; however, the introduction of the word “市长” may lead to ambiguity, resulting in errors like “南京-Location”, “市长-Position”.
In other words, the words introduced through the dictionary can have both positive and negative effects. Of course, it is impossible to manually filter out the words that are detrimental to the model, so we hope to provide all potential words to the model and let it choose the beneficial ones to avoid ambiguity. Lattice LSTM does just that: it integrates potential vocabulary information into the Character-based LSTM+CRF framework, allowing the model to effectively utilize both character and word information.
2.3 Lattice LSTM Model Details
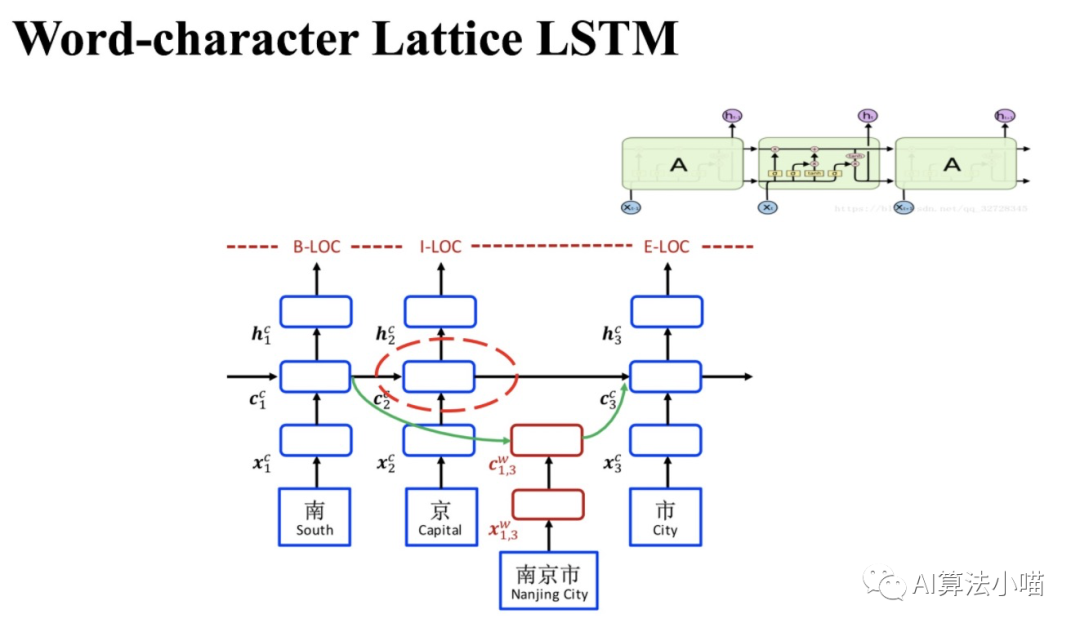
As shown in the figure, the main part of the Lattice LSTM model is the Character-based LSTM-CRF:
-
If the current input character does not have any words ending with it in the dictionary: the transmission between cells in the main structure behaves like a normal LSTM. That is, at this point, Lattice LSTM degenerates into a basic LSTM.
-
If the current input character has words ending with it in the dictionary: the relevant potential word information needs to be introduced through the red cell (see the right side of the figure in section 2.2) and merged with the corresponding cell in the character-based LSTM.
Next, we will briefly showcase the basic unit of LSTM, followed by an introduction to the red cell, and finally the information fusion part.
2.3.1 LSTM Unit
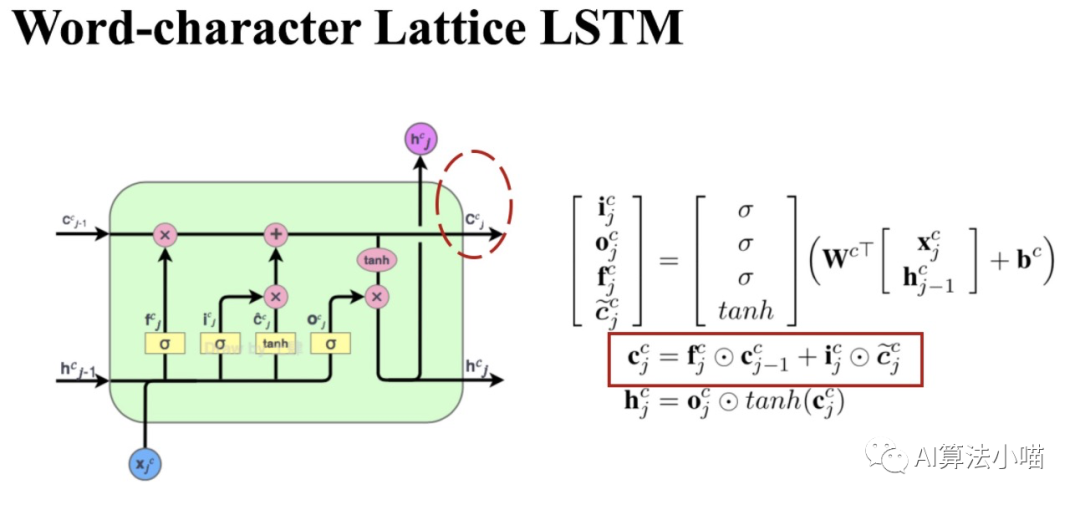
The left side of the figure shows the internal structure of an LSTM unit (Cell), while the right side shows the computation process of the Cell. Each Cell contains three gates: input gate, forget gate, and output gate. As shown in the calculation formulas on the right side, these three gates are actually small decimals between 0 and 1, calculated based on the current input and the hidden state output of the previous Cell:
-
Input Gate: Determines how much of the current input can be added to the Cell State;
-
Forget Gate: Determines how much information to retain in the Cell State.
-
Output Gate: Determines how much of the updated Cell State can be outputted.
A purely character-based LSTM can compute entirely based on the above process, while Lattice LSTM differs.
2.3.2 Red Cell
Earlier, we mentioned that “if the current character has words ending with it in the dictionary, we need to introduce related potential word information through the red cell and merge it with the corresponding cell in the character-based LSTM”. Taking the character