Source | Heart of Autonomous Driving
Editor | Deep Blue Academy
Abstract
Transformers, an encoder-decoder model based on attention, have revolutionized the field of Natural Language Processing (NLP). Inspired by these significant achievements, recent pioneering work has adopted transformer-like architectures in the field of Computer Vision (CV), demonstrating their effectiveness in three fundamental CV tasks (classification, detection, and segmentation) as well as multi-sensor data (images, point clouds, and vision-language data).
Due to their competitive modeling capabilities, visual transformers have achieved impressive performance improvements across multiple benchmarks compared to modern Convolutional Neural Networks (CNNs). This review comprehensively investigates over 100 different visual transformers based on the three fundamental CV tasks and various data flow types, proposing a taxonomy to organize representative methods according to their motivations, structures, and application scenarios.
Due to differences in training settings and dedicated visual tasks, the paper also evaluates and compares all existing visual transformers under different configurations. Furthermore, the paper reveals a range of important yet undeveloped aspects that may enable such visual transformers to stand out from numerous architectures, such as loose high-level semantic embeddings to bridge the gap between visual transformers and sequential models. Finally, promising future research directions are proposed.
Repository address: https://github.com/liuyang-ict/awesome-visual-transformers
This article aims to provide a more comprehensive review of the latest visual transformers and systematically categorize them:
-
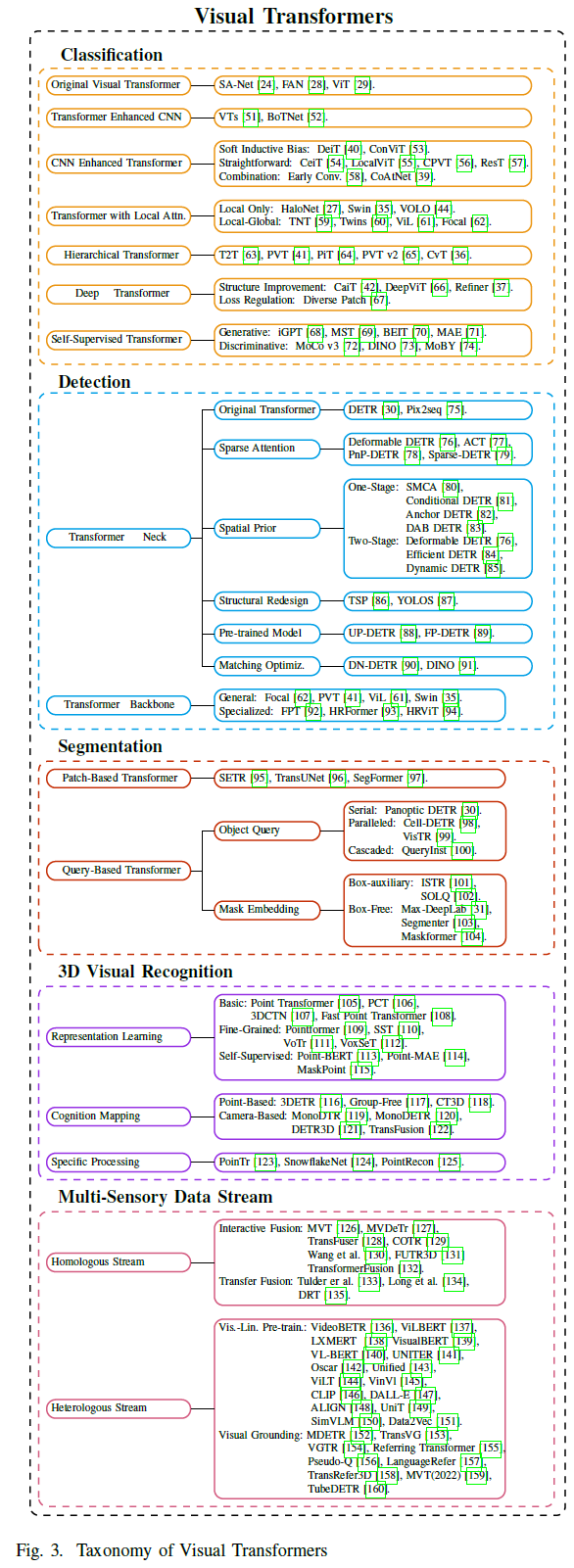
Comprehensiveness and Readability: This article comprehensively reviews over 100 visual transformers based on their applications in three fundamental CV tasks (i.e., classification, detection, and segmentation) and data flow types (i.e., images, point clouds, multi-flow data). The paper selects more representative methods and provides detailed descriptions and analyses while briefly introducing other related works. This article not only conducts an exhaustive analysis of each model from one perspective but also establishes their internal connections in a certain sense, such as progressive, comparative, and multi-perspective analyses. -
Intuitive Comparisons: Given that existing visual transformers follow different training schemes and hyperparameter settings for various visual tasks, this article conducts multiple horizontal comparisons across different datasets and constraints. More importantly, it summarizes a series of effective components designed for each task, including: (a) hierarchical shallow local convolutions; (b) sparse attention spatial priors to accelerate neck detector; (c) and a universal mask prediction scheme for segmentation; -
In-depth Analysis: The paper further delves into several aspects: (a) the transition from traditional sequential tasks to visual tasks; (b) the correspondence between visual transformers and other neural networks; (c) and the relevance of learnable embeddings (i.e., class token, object query, mask embedding) used in different tasks and data flow types. Finally, the paper outlines some future research directions. For instance, the encoder-decoder transformer backbone can unify multiple visual tasks and data flow types through query embeddings.
Original Transformer
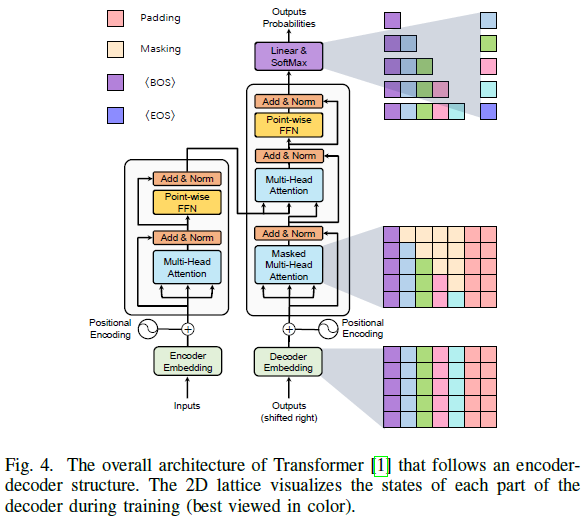
The original transformer[1] was first applied to sequence-to-sequence autoregressive tasks. Compared to previous sequence transduction models[49],[50], this original transformer inherits the encoder-decoder structure but completely abandons recursion and convolution by using a multi-head attention mechanism and point-wise feed-forward networks.
Figure 4 shows the overall transformer model with an encoder-decoder architecture. Specifically, it consists of N consecutive encoder modules, each of which is composed of two sublayers. 1) The MHSA layer aggregates the relationships within the encoder embeddings; 2) The position-wise FFN layer extracts feature representations.
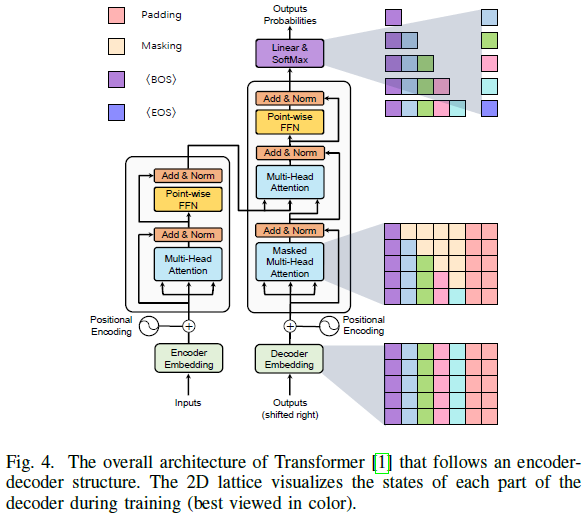
In natural language regression models, the transformer originated from machine translation tasks. Given a sequence of words, the transformer vectorizes the input sequence into word embeddings, adds positional encodings, and feeds the resulting vector sequence into the encoder.
During training, as shown in Figure 4, Vaswani et al. designed a masking operation based on the autoregressive task rules, where the current position only depends on the outputs of previous positions. Based on this masking, the transformer decoder is capable of processing the sequence of input labels in parallel. During inference, the same operation processes the previously predicted word sequences to predict the next word.
Classification Transformers
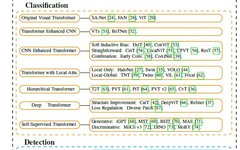
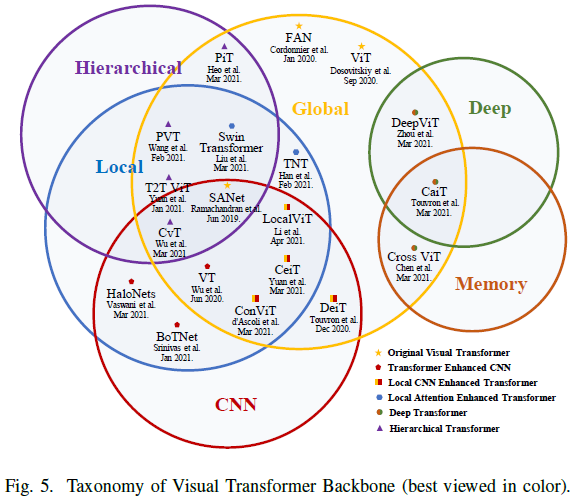
With the significant development of transformers in NLP[2]–[5], recent work has attempted to introduce visual transformers for image classification. This section comprehensively reviews over 40 visual transformers and categorizes them into six classes, as shown in Figure 5.
First, Fully-Attentional networks[24],[28] and Vision Transformer (ViT)[29] are introduced, where the original ViT first demonstrated its efficacy on multiple classification benchmarks. Then, transformer-enhanced CNN methods are discussed, which utilize transformers to enhance CNN’s representation learning. Due to the neglect of local information in the original ViT, CNN-enhanced transformers adopt appropriate convolutional inductive biases to enhance ViT, while local attention-enhanced transformers redesign patch partitioning and attention blocks to improve locality.
Following the hierarchical and deep structures in CNN[162], hierarchical transformers replace the fixed-resolution columnar structure with pyramids, while deep transformers prevent overly smooth attention maps and increase their diversity in deeper layers. Furthermore, the paper reviews existing self-supervised learning-based ViTs. Finally, a brief discussion based on intuitive comparisons organizes a milestone for ViT and discusses a common issue for further research.
Original Visual Transformer
Inspired by the tremendous success of transformers in the NLP field[2]-[5], previous technical trends in visual tasks[14]-[17],[163] combined attention mechanisms with convolutional models to enhance the model’s receptive field and global dependencies. Beyond this hybrid model, Ramachandran et al. considered whether attention could completely replace convolution, proposing a Stand-Alone self-attention network (SANet)[24], which achieved excellent performance on visual tasks compared to the original baseline.
Given the ResNet[11] architecture, the authors directly replaced the spatial convolution layers (3*3) in each bottleneck with local spatial self-attention layers while keeping other structures consistent with the original settings in ResNet. Moreover, extensive ablation studies have shown that positional encodings and convolutions can further enhance network efficiency. Following[24], Cordonnier et al. designed a prototype (termed the “Fully-Attentional Network”)[28], which includes a fully vanilla transformer and a secondary positional encoding.
The authors also theoretically demonstrated that convolutional layers can be approximated by a single MHSA layer with relative positional encoding and sufficient heads. Through ablation experiments on CIFAR-10[164], they further verified that such a prototype design could indeed learn grid-like patterns around each query pixel, which was their theoretical conclusion.
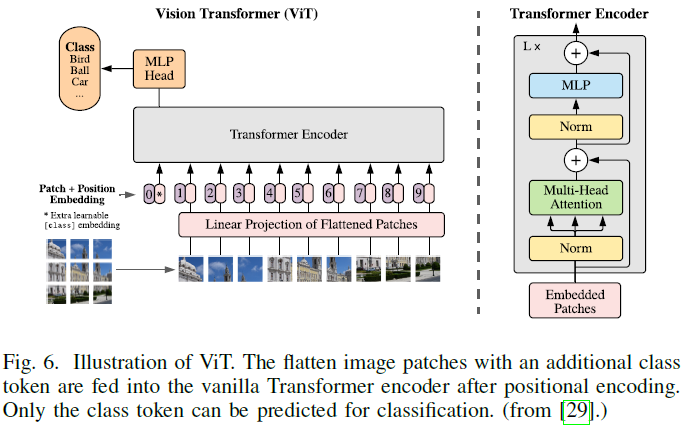
Unlike[28] which only focuses on small-scale models, ViT[29] further explored the effectiveness of vanilla transformers through large-scale pre-training, which had a significant impact on the community. Since vanilla transformers only accept sequence inputs, the input images in ViT are first split into a series of non-overlapping patches and then projected into patch embeddings.
A one-dimensional learnable positional encoding is added to the patch embeddings to retain spatial information, which is then fed into the encoder along with the joint embeddings, as shown in Figure 6. Similar to BERT[5], the learned [class] token is appended to the patch embeddings to aggregate global representations and is used as input for classification.
Additionally, 2D interpolation supplements the pre-trained positional encodings to maintain the consistent order of patches when feeding images of arbitrary resolution. By using a large-scale private dataset (JFT-300M[165]) for pre-training, ViT achieved similar or even better results on multiple image recognition benchmarks (ImageNet[166] and CIFAR-100[164]) compared to the most popular CNN methods. However, its generalization ability is often eroded by limited training data.
Transformer Enhanced CNNs
As mentioned, transformers have two key components: MHSA and FFN. There exists an approximation between convolutional layers and MHSA[28], and Dong et al. argue that transformers can further alleviate the strong bias of MHSA with the help of skip connections and FFN[167].
Recently, some methods have attempted to integrate transformers into CNNs to enhance representation learning. VTs[51] decouple the semantic concepts of input images into different channels and tightly associate them through encoder blocks (i.e., VT blocks). This VT block replaces the final convolution stage to enhance the semantic modeling capability of CNN models. Unlike previous methods that directly replace convolution with attention structures, Vaswani et al. proposed a conceptual redefinition, stating that consecutive bottleneck blocks with MHSA can be expressed as Bottleneck Transformer (BoTNet)[52] blocks.
Relative positional encoding[168] further simulates the original transformer. Based on ResNet[11], BoTNet is similarly parameterized in the ImageNet benchmark, outperforming most CNN models and further demonstrating the effectiveness of hybrid models.
CNN Enhanced Transformer
Inductive bias is defined as a set of assumptions about data distribution and solution space, which manifests as locality and translation invariance in convolution[169]. Since the covariance within local neighborhoods is significant and tends to stabilize gradually in images, CNNs can effectively process images with the help of bias.
However, when sufficient data is available, strong bias also limits the upper bound of CNNs. Recent efforts have attempted to leverage appropriate CNN bias to enhance transformers. Relevant algorithms include DeiT[40], ConViT[53], CeiT[54], LocalViT[55], ResT[57], CPVT[56], CvT[36], CoAtNet[39], etc.
Local Attention Enhanced Transformer
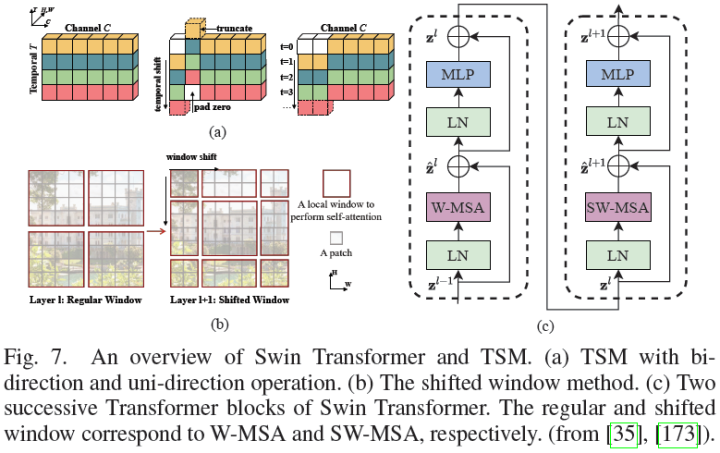
The coarse patchify process in ViT[29] neglects local image information. Beyond convolution, researchers have proposed a local attention mechanism to dynamically focus on adjacent elements and enhance local extraction capabilities. One representative method is the Swin Transformer[35]. Similar to TSM[173] (Figure 7(a)), Swin utilizes shifted windows along the spatial dimensions to model global and boundary features.
Specifically, two consecutive window-wise attention can facilitate cross-window interactions (Figure 7(b)-(c)), akin to the receptive field expansion in CNNs. This operation reduces computational costs. Other relevant algorithms include TNT[59], Twins[60], ViL[61], VOLO[44], which can be referenced in specific papers.
Hierarchical Transformer
Due to ViT[29] adopting a fixed-resolution columnar structure across the transformer layers, it neglects fine-grained features and incurs heavy computational costs. Following hierarchical models, Tokens to Token ViT (T2T-ViT) first introduces the paradigm of hierarchical transformers and employs overlapping unfold operations for down-sampling.
However, this operation incurs heavy memory and computational costs. Therefore, Pyramid Vision Transformer (PVT)[41] utilizes non-overlapping patch partitioning to reduce feature size. Additionally, the spatial-reduction attention (SRA) layer in PVT is applied to further reduce computational costs by learning low-resolution key-value pairs.
Empirically, PVT adapts transformers for dense prediction tasks across many benchmarks that require abundant input and fine-grained features while maintaining computational efficiency. Moreover, PiT[64] and CvT[36] utilize pooling and convolutions respectively for token down-sampling. Specifically, CvT[36] improves the SRA of PVT[41] by replacing linear layers with convolutional projections. Based on convolutional bias, CvT[36] can adapt to inputs of arbitrary sizes without positional encoding.
Deep Transformer
Empirically, increasing the depth of a model can enhance its learning capability[11]. Recent work has applied deep structures to transformers and conducted extensive experiments to study their scalability by analyzing cross-patch[67] and cross-layer[37],[66] similarities and the contributions of residuals[42]. In deep transformers, features from deeper layers often become less representative (attention collapse[66]), and patches are mapped to indistinguishable latent representations (patch over-smoothing[67]). To address these limitations, these methods propose corresponding solutions from two perspectives.
From the perspective of model structure, Touvron et al. proposed effective Class-attention (CaiT[42]) in image transformers, which includes two stages:
1) Multiple self-attention stages without class tokens. In each layer, a learnable diagonal matrix initialized with small values is used to dynamically update channel weights, providing some flexibility for channel adjustment;
2) The final class-attention stage freezes patch embeddings. The subsequent class token is then inserted into the model’s global representation, similar to DETR with an encoder-decoder structure. This explicit separation is based on the assumption that the class token is ineffective for the gradients of the patch embeddings during the forward pass. Through a distillation training strategy[40], CaiT achieved a new SOTA (86.5% TOP1 accuracy) on imagenet-1k without external data.
Deep transformers suffer from attention collapse and over-smoothing issues, yet largely retain the diversity of attention maps between different heads. Based on this observation, Zhou et al. proposed Deep Vision Transformer (DeepViT)[66], which aggregates cross-head attention maps and regenerates new attention maps using linear layers to enhance cross-layer feature diversity.
Moreover, Refiner[37] applies linear layers to expand the dimensions of attention maps (indirectly increasing the number of heads) to promote diversity. Then, distributed local attention (DLA) is used to achieve better modeling of local and global features, which is realized through head-wise convolutions affecting attention maps.
From the perspective of training strategies, Gong et al. proposed three Patch Diversity losses for deep transformers, which can significantly encourage diversity in patches and mitigate the over-smoothing problem[67]. Similar to[175], the patch-wise cosine loss minimizes the pairwise cosine similarity between patches. The patch-wise contrastive loss regularizes deeper patches through their corresponding patches in earlier layers.
Inspired by Cutmix[176], the patch-wise mixing loss mixes two different images and forces each patch to focus only on patches from the same image while ignoring unrelated patches. Compared to LV-ViT[43], they have similar loss functions but different motivations. The former focuses on patch diversity, while the latter emphasizes data augmentation regarding token labels.
Transformers with Self-Supervised Learning
Self-supervised transformers have achieved tremendous success in the NLP field[5], but visual transformers remain at the supervised pre-training stage[35],[40]. Recent work has also attempted to design various self-supervised learning schemes for ViT in both generative and discriminative ways. Generative-related works include iGPT[68], BEiT[70], dVAE[147]. Discriminative-related works include[72], DINO[73].
Discussion
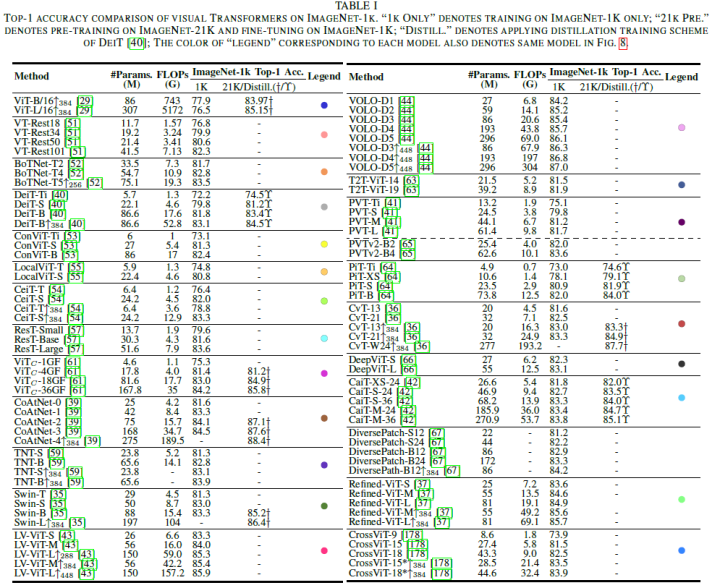
Algorithm Evaluation and Comparative Analysis: In the taxonomy of the paper, all existing supervised models are categorized into six classes. Table 1 summarizes the performance of these existing ViTs on the ImageNet-1k benchmark. To objectively and intuitively evaluate them, the paper uses the following three figures to illustrate their performance on ImageNet-1k under different configurations.
Figure 8(a) summarizes the accuracy of each model at an input size of 2242. Figure 8(b) focuses on their performance at higher resolutions with FLOPs on the horizontal axis. Figure 8(c) focuses on pre-trained models with external datasets. Based on these comparative results, the paper briefly summarizes several performance improvements in terms of efficiency and scalability as follows:
-
Compared to most structural improvement methods, basic training strategies like DeiT[40] and LV-ViT[43] are more applicable to various models, tasks, and inputs; -
Locality is essential for transformers, which is reflected in the advantages of VOLO[44] and Swin[35] in classification and dense prediction tasks respectively; -
Convolutional patchify stem (ViTc[58]) and early convolution stages (CoAtNet[39]) can significantly improve the accuracy of transformers, especially for large models. The paper speculates that the reason is that these designs introduce stricter high-level features than the non-overlapping patch projections in ViT; -
Deep transformers, such as Refined-ViT[37] and CaiT[42], hold great potential. As the model size grows quadratically with channel size, future research can further explore relevant trade-off strategies in deep transformers; -
CeiT[54] and CvT[36] have significant advantages for training small models (0 to 40M), indicating that this hybrid attention block for lightweight models is worth further exploration.

Overview of ViT Development Trends
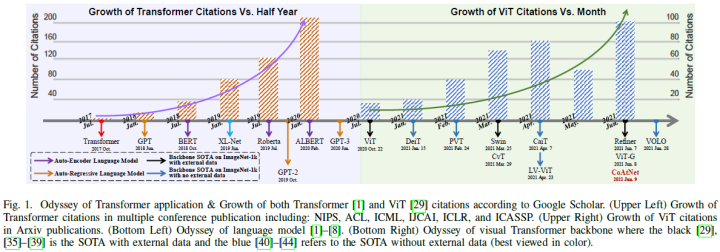
When the taxonomy of the paper matches the timeline of these models, we can clearly trace the development trends of transformers used for image classification (Figure 1). As a self-attention mechanism, visual transformers are primarily redesigned based on the naive structure in NLP (ViT[29] and iGPT[68]) or attention-based models in CV (VTs[51] and BoTNet[52]).
Then, many methods began to extend the hierarchical or deep structures of CNNs to ViT. T2T-ViT[63], PVT[41], CvT[36], and PiT[64] share a motivation to migrate hierarchical structures into transformers but achieve down-sampling in different ways. CaiT[42], Diverse Patch[67], DeepViT[66], and Refiner[37] focus on issues within deep transformers. Additionally, some methods turn to internal components to further enhance the image processing capabilities of previous transformers, namely positional encodings[56],[179],[180], MHSA[28], and MLP[167].
The next wave of transformers is the local paradigm. Most of these introduce locality into transformers through local attention mechanisms[35],[44],[59],[60] or convolutions[53]–[55]. Nowadays, the latest supervised transformers are exploring structural combinations[39],[58] and scaling laws[38],[181]. Besides supervised transformers, self-supervised learning occupies a considerable portion in ViT[68]–[70],[72]–[74]. However, it remains unclear which tasks and structures are more beneficial for self-supervised transformers in CV.
A brief discussion of alternatives: During the development of ViT, the most common question is whether ViT can completely replace traditional convolutions. By reviewing the historical performance improvement over the past year, there are no signs of relative disadvantages. ViT has transitioned from a purely structural form back to a hybrid form, and global information has gradually returned to a mixed stage with local bias. Although ViT can be equivalent to CNNs, even showcasing better modeling capabilities, this simple and effective convolution operation is sufficient to handle locality and semantic features in shallow layers. In the future, the spirit of combining the two will drive more breakthroughs in image classification.
Detection Transformers
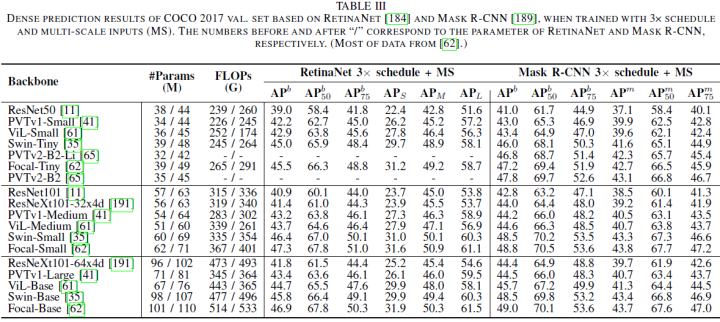
This section reviews ViTs used for object detection, which can be divided into two parts: Transformer Neck and Transformer Backbone. For the neck, the paper primarily focuses on a new representation specified for the transformer structure, termed object query, which is a set of learnable parameters that equivalently aggregates global features. Recent variants have attempted to address the optimal fusion paradigm in terms of convergence acceleration or performance improvement. Besides necks specifically designed for detection tasks, a portion of backbone detectors also considers specific strategies. Finally, the paper evaluates them and analyzes some potential methods for these detectors.
Transformer Neck
First, the paper reviews DETR[30] and Pix2seq[75], which are the original transformer detectors that redefine two different paradigms for object detection. Subsequently, the paper focuses on DETR-based variants that have improved the accuracy and convergence of transformer detectors from five aspects: sparse attention, spatial priors, structural redesign, assignment optimization, and pre-training models.
Original Detector: DETR[30] is the first end-to-end transformer detector that eliminates handcrafted representations[182]-[185] and non-maximum suppression (NMS) post-processing, redefining object detection as a set prediction problem. Specifically, a small group of learnable positional encodings, termed object queries, are fed in parallel to the transformer decoder to aggregate instance information from image features. The prediction head then directly generates detection results from the output queries of the decoder. During training, a bipartite matching strategy is used to identify one-to-one label assignments between predicted objects and ground truth, thereby eliminating redundant predictions during inference without the aid of NMS. In backpropagation, the Hungarian loss includes the log-likelihood loss of all classification results and the box loss of all matched pairs.
In summary, DETR provides a new paradigm for end-to-end object detection. Object queries gradually learn instance representations during interactions with image features. Bipartite matching allows direct set predictions to easily adapt to one-to-one label assignments, thus eliminating traditional post-processing. DETR achieves competitive performance on the COCO benchmark but faces slow convergence and poor performance on small objects.
Another groundbreaking work is Pix2seq[75], which treats universal object detection as a language modeling task. Given an image input, a vanilla sequential transformer is used to extract features and autoregressively generate a sequence of object descriptions (i.e., class labels and bounding boxes). This simplified yet more complex image captioning method is derived from the assumption that if the model understands both the location and labels of the objects simultaneously, it can be taught to generate descriptions with specified sequences[75]. Compared to DETR, Pix2seq achieves better results on small objects. How to combine these two concepts is worth further consideration.
Sparse Attention: In DETR, the dense interactions between queries and feature maps consume unaffordable resources and slow down DETR’s convergence speed. Therefore, recent efforts aim to design data-dependent sparse attention to address these issues.
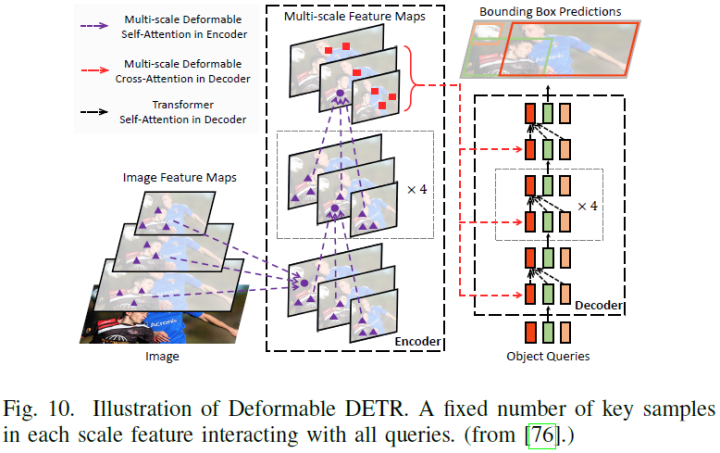
Following[186], Zhu et al. developed Deformable DETR to significantly improve training convergence and detection performance through multi-scale deformable attention[76]. Compared to the original DETR, the deformable attention module samples only a small number of key points for full feature aggregation. This sparse attention can easily extend to multi-scale feature fusion without the need for FPN[187], hence termed multi-scale deformable attention (MSDA), as shown in Figure 10. Other relevant algorithms include ACT[77], PnP[78], Sparse DETR[79], which can be referenced in specific papers.
Spatial Priors: Unlike anchors or other representations directly generated by content and geometric features[182],[188], object queries implicitly model spatial information through random initialization, which is weakly correlated with bounding boxes. The mainstream application of spatial priors is one-stage detectors with empirical spatial information and two-stage detectors with geometric coordinate initialization or regions of interest (RoI) features. One-stage relevant algorithms include SMCA[80], Conditional DETR[81], Anchor DETR[82], DAB-DETR[83]. Two-stage relevant algorithms include Efficient DETR[84], Dynamic DETR[85].
Structural Redesign: Besides focusing on modifications to cross-attention, some works have redesigned the structure of the encoder alone to directly avoid the issues of decoders. TSP[86] inherits the idea of set prediction[30] and removes the decoder and object queries to accelerate convergence. This encoder-only DETR reuses previous representations[182],[188] and generates a fixed number of interest features (FoI)[188] or proposals[182], which are then fed into the transformer encoder.
Moreover, matching distillation is applied to address the instability of bipartite matching, especially in the early training stages. Fang et al.[87] merged the encoder-decoder neck of DETR with the encoder-only backbone of ViT to develop YOLOS, a pure sequence-to-sequence transformer that unifies classification and detection tasks. It inherits the structure of ViT and replaces a single class token with a fixed number of learnable detection tokens. These target tokens are first pre-trained on classification tasks and then fine-tuned on detection benchmarks.
Bipartite Matching Optimization: In DETR[30], the bipartite matching strategy forces the predicted results to perform one-to-one label assignments during training. Such a training strategy simplifies the detection pipeline and builds an end-to-end system directly without the help of NMS. To gain deeper insights into the effectiveness of end-to-end detectors, Sun et al. dedicated themselves to exploring the theoretical perspective of one-to-one predictions[192].
Based on multiple ablations and theoretical analyses, they concluded that the classification cost of the one-to-one matching strategy is a key factor in significantly avoiding duplicate predictions. Nevertheless, DETR still faces multiple issues induced by bipartite matching. Li et al.[90] utilized denoising DETR (DN-DETR) to alleviate the instability of bipartite matching. Specifically, a series of targets with slight perturbations should reconstruct their true coordinates and classes. The denoising (or reconstruction) part’s main component is an attention mask that prevents information leakage between the matching part and the noise part, along with designated label embeddings indicating disturbances. Other works include DINO[91].
Pre-training: Inspired by pre-trained language transformers[3],[5], relevant works include UP-DETR[88], FP-DETR[89].
Transformer Backbone
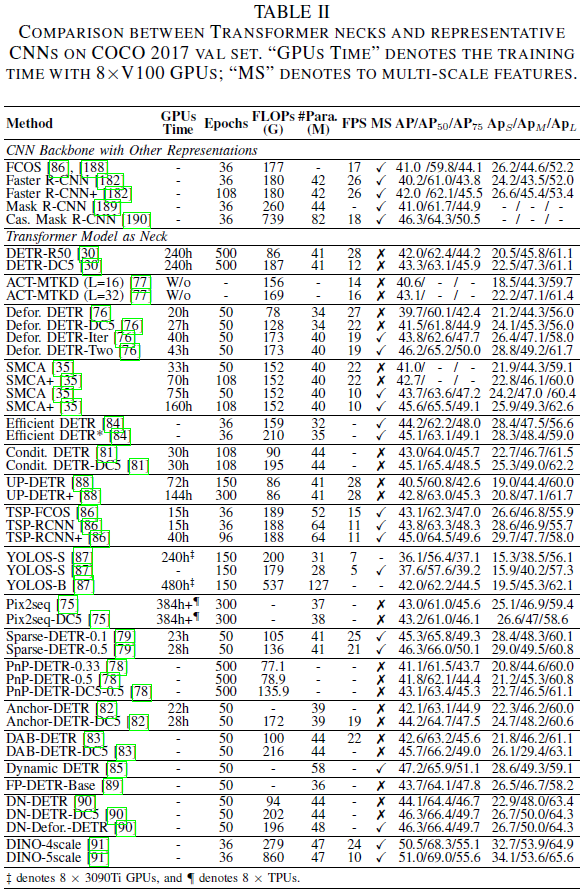
The previous sections have reviewed many image classification backbones based on transformers[29],[40]. These backbones can be easily incorporated into various frameworks (e.g., Mask R-CNN[189], RetinaNet[184], DETR[30], etc.) to perform dense prediction tasks. For instance, hierarchical structures like PVT[41],[65] construct ViT as a process from high resolution to low resolution to learn multi-scale features.
Local enhancement structures build the backbone as a combination from local to global, effectively extracting short-range and long-range visual correlations while avoiding secondary computational overhead, such as Swin Transformer[35], ViL[61], and Focal Transformer[62]. Table III includes a more detailed comparison of these models for dense prediction tasks. In addition to general transformer backbones, the Feature Pyramid Transformer (FPT)[92] combines spatial and scale characteristics using self-attention, top-down cross-attention, and bottom-up cross-channel attention.
Following[193], HRFormer[93] introduces the advantages of multi-resolution to transformers and non-overlapping local self-attention. HRViT[94] redesigns heterogeneous branches and cross-shaped attention modules.
Discussion
The paper summarizes five components of transformer neck detectors in Table II, and for more details on the transformer backbone for dense prediction tasks, see Table III. Most neck enhancements focus on the following five aspects:
-
1) Sparse attention models and scoring networks were proposed to address the redundancy in feature interactions. These methods can significantly reduce computational costs and accelerate model convergence; -
2) Explicit spatial priors decomposed into selected feature initialization and positional information extracted by learnable parameters will enable detectors to predict results accurately; -
3) Multi-scale features and layer-wise updates have been extended in the transformer decoder for small object refinement; -
4) Improved bipartite matching strategies are beneficial to avoid redundant predictions and achieve end-to-end object detection; -
5) The encoder-only structure reduces the entire transformer stack layers, but excessively increases FLOPs, while the encoder-decoder structure provides a good trade-off between FLOPs and parameters, but deeper decoder layers may lead to long training processes and over-smoothing issues.
Furthermore, many transformer backbones have been employed to improve classification performance, yet there is little work specifically targeting dense prediction tasks. In the future, the paper anticipates that transformer backbones will collaborate with deep high-resolution networks to address dense prediction tasks.
Segmentation Transformers
Patch-Based and Query-Based Transformers are the two main application methods for segmentation. The latter can be further divided into Object Query and Mask Embedding.
Patch-Based Transformer
Due to the receptive field expansion strategy[194], CNNs require multiple decoder stacks to map high-level features to the original spatial resolution. In contrast, patch-based transformers can easily combine with simple decoders for segmentation mask predictions due to their global modeling capabilities and resolution invariance.
Zheng et al. extended ViT[29] for semantic segmentation tasks and achieved pixel-wise classification through three methods of decoder: naive upsampling (naive), progressive upsampling (PUP), and multi-level feature aggregation (MLA). SETR demonstrated the feasibility of ViT for segmentation tasks, but it also introduced unacceptable additional GPU overhead. TransUNet[96] is the first method for medical image segmentation.
Formally, it can be viewed as a variant of SETR with MLA decoder[95], or as a hybrid model of U-Net[195] and transformers. Due to the powerful global modeling capability of transformer encoders, Segformer[97] designed a lightweight decoder with only four MLP layers. When tested with images of various corruption types, Segformer showed better performance and stronger robustness than CNNs.
Query-Based Transformer
Query embedding is a set of temporary semantic/instance representations learned progressively from image inputs. Unlike patch embeddings, queries can integrate information from features more “fairly” and naturally combine with set prediction loss[30] to eliminate post-processing. Existing query-based models can be divided into two categories. One is driven simultaneously by detection and segmentation tasks (referred to as object queries). The other is supervised only by segmentation tasks (referred to as mask embeddings).
Object Queries: Methods based on object queries have three training modes (Figure 11). As shown in Figure 11(a), Panoptic DETR[30]. In Figure 11(b), Cell-DETR[98] and VisTR[99], and as shown in Figure 11(c), QueryInst[100]
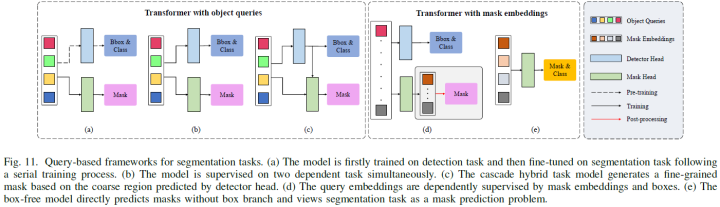
Mask Embeddings: Another framework uses queries to directly predict masks, and the paper refers to this query-based learning as mask embedding. Unlike object queries, mask embeddings are supervised solely by segmentation tasks. As shown in Figure 11(d), two disjoint sets of queries are used in parallel for different tasks, and box learning is treated as an enhanced auxiliary loss, with relevant algorithms including ISTR[101], SOLQ[102].
For semantic and box-free instance segmentation, a series of query-based transformers directly predict masks without the aid of box branches (Figure 11(e)), with relevant algorithms such as Max-DeepLab[31], Segmenter[103], Maskformer[104], etc.
Discussion
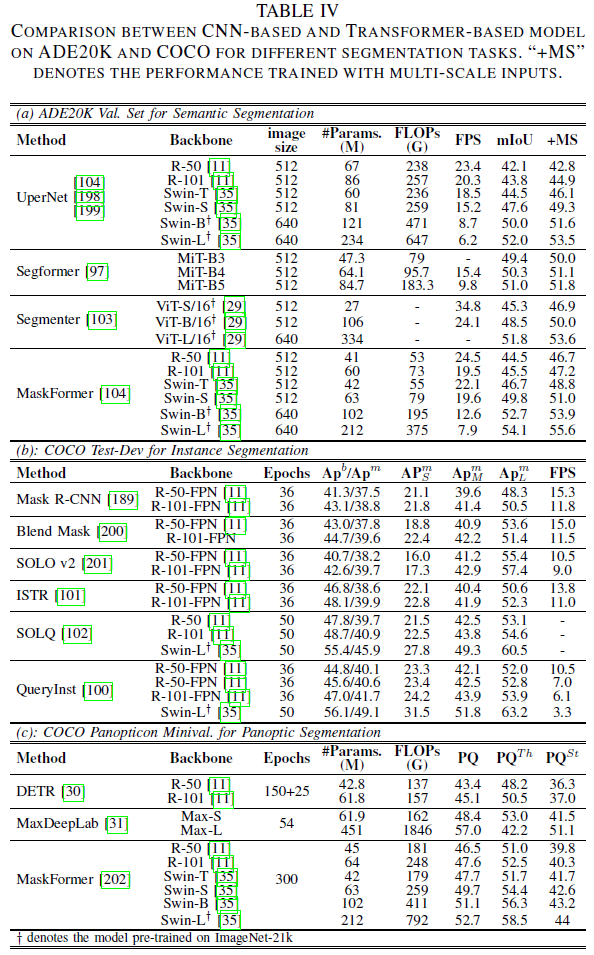
The paper summarizes the above transformers based on three different tasks. Table IV(a) focuses on ADE20K (170 classes). It can be indicated that when trained on datasets with a large number of classes, the segmentation performance of ViT significantly improves. Table IV(b) focuses on the COCO test dataset for instance segmentation. Evidently, in segmentation and detection tasks, ViTs with mask embeddings outperform most mainstream models. However, there is a significant performance gap between APbox and APseg.
Through a cascade framework, QueryInst[100] achieves SOTA across various transformer models. Combining ViT with hybrid task cascade structures is worth further research. Table IV(c) focuses on panoptic segmentation. Max-DeepLab[31] typically addresses the foreground-background problem in panoptic segmentation tasks through mask prediction, while Maskformer[104] successfully applies this format to semantic segmentation and unifies semantic and instance segmentation tasks into a single model. Based on their performance in the panoptic segmentation domain, we can conclude that ViT can unify multiple segmentation tasks into a box-free framework and perform mask predictions.
3D Vision Transformers
With the rapid development of 3D acquisition technologies, stereo/monocular images and LiDAR (Light Detection and Ranging) point clouds have become popular sensor data for 3D recognition. Unlike RGB (D) data, point cloud representations focus more on distance, geometry, and shape information. Notably, due to their sparsity, disorder, and irregularity, these geometric features are particularly well-suited for transformers. Following the success of 2D ViTs, numerous methods for 3D analysis have been developed. This section presents a brief overview of 3D ViTs following representation learning, cognitive mapping, and specific processing.
Representation Learning
Compared to traditional handcrafted networks, ViTs are better suited for learning semantic representations from point clouds, where this irregular and permutation-invariant nature can be transformed into a series of parallel embeddings with positional information. Given this, Point Transformer[105] and PCT[106] first demonstrate the effectiveness of ViTs for 3D representation learning. The former combines hierarchical transformers[105] with down-sampling strategies[203] and extends its previous vector attention block[25] to 3D point clouds.
The latter first aggregates neighboring point clouds and then processes these neighboring embeddings on a global off-set transformer, where knowledge transfer from Graph Convolutional Networks (GCNs) is applied for noise mitigation. Notably, due to the inherent coordinate information of point clouds, positional encoding (a crucial operation in ViTs) is reduced in both methods. PCT directly handles coordinates without positional encoding, while Point Transformer adds learnable relative positional encodings for further enhancement.
Following[105],[106], Lu et al. utilized a local-global aggregation module, 3DCTN[107], to achieve local enhancement and cost efficiency. Given a multi-step down-sampling group, explicit graph convolutions with max-pooling operations are used to aggregate local information within each group. The resulting group embeddings are concatenated and fed into improved transformers[105],[106] for global aggregation. Park et al. proposed Fast Point Transformer[108], optimizing model efficiency through voxel-hashing neighborhood search, voxel bridging relative positional encodings, and local attention based on cosine similarity.
For dense predictions, Pan et al. proposed a customized point cloud-based transformer backbone (Pointformer)[109], which engages in local and global interactions separately at each layer. Unlike previous local-global forms, it updates centroid points rather than surface points through a local attention-based coordinate refinement operation. The local-global cross-attention model fuses high-resolution features and subsequently applies global attention.
Fan et al. return to Single-stride Sparse Transformer (SST)[110], rather than down-sampling operations, to address small object detection issues. Similar to Swin[35], shifted groups in consecutive transformer blocks are used to process each group of tokens separately, further alleviating computational issues.
In voxel-based methods, Voxel Transformer (VoTr)[111] adopts a two-step voxel transformer to effectively operate on both empty and non-empty voxel positions, including local attention and dilated attention. VoxSeT[112] further decomposes self-attention into two cross-attention layers, linking them with a set of latent encodings to preserve global features in hidden space.
A series of self-supervised transformers have also been extended to 3D space, such as Point BERT[113], Point MAE[114], and MaskPoint[115]. Specifically, Point BERT[113] and Point MAE[114] directly transfer previous works[70],[71] to point clouds, while MaskPoint[115] alters the generative training scheme using a contrastive decoder similar to DINO (2022)[91] for self-training. Based on extensive experiments, the paper concludes that this generative/contrastive self-training method enables ViTs to perform effectively in images or point clouds.
Cognition Mapping
Given the rich representation features, how to directly map instance/semantic cognition to target outputs has also sparked considerable interest. Unlike 2D images, targets in 3D scenes are independent and can be intuitively represented by a series of discrete surface points. To bridge this gap, some existing methods transfer domain knowledge to mainstream 2D models. Following[30], 3DETR[116] extends the end-to-end module to 3D object detection through farthest point sampling and Fourier positional embeddings for object queries initialization. Group Free 3D DETR[117] applies a more specific and stronger structure than[116].
Specifically, when object queries are involved, it directly selects a set of candidate sampling points from the extracted point clouds and iteratively updates them layer by layer in the decoder. Sheng et al. proposed a typical two-stage method that utilizes a Channel-wise Transformer 3D detector (CT3D)[118] to simultaneously aggregate proposal-aware embeddings of point cloud features within each proposal and channel-wise contextual information.
For monocular sensors, MonoDTR[119] and MonoDETR[120] use auxiliary depth supervision during training to estimate pseudo depth positional encodings (DPE). DETR3D[121] introduces a multi-view 3D object detection paradigm, where both 2D images and 3D positions are related through camera transformation matrices and a set of 3D object queries. TransFusion[122] further leverages the advantages of LiDAR points and RGB images through continuous interactions with object queries across two transformer decoder layers.
Specific Processing
Due to limitations in sensor resolution and viewpoint, point clouds face issues of incompleteness, noise, and sparsity in real scenes. To address this, PoinTr[123] represents the original point cloud as a set of local point cloud proxies and utilizes a geometric-aware encoder-decoder transformer to migrate the centroids towards the incomplete point clouds. SnowflakeNet[124] formulates the process of point cloud completion as a snowflake-like growth, generating sub-point clouds from parent point clouds through a point-wise splitting deconvolution strategy. The skip-transformer between adjacent layers further refines the spatial context features between parent and child layers to enhance their connected areas.
Choe et al. unify various generative tasks (e.g., denoising, completion, and super-resolution) into a point cloud reconstruction problem, thus termed PointRecon[125]. Based on voxel hashing, it covers the local geometric structures of absolute scales and utilizes PointTransformer-like[105] structures to aggregate each voxel (query) with its neighboring voxels (value-key) for fine-grained transformations from discrete voxels to a set of point clouds. Additionally, enhanced positional encodings are applicable for voxel local attention schemes, realized by using the negative exponential function of L1 loss as weights for naive positional encodings. Notably, unlike masked generative self-training, the completion task directly generates a set of complete point clouds without requiring explicit spatial priors of incomplete point clouds.
Multi-Sensor Data Flow Transformers
In the real world, multiple sensors are always used complementarily rather than a single sensor. To this end, recent work has begun to explore different fusion methods to effectively coordinate multi-sensor data flows. Compared to typical CNNs, transformers are naturally suited for multi-flow data fusion due to their non-specific embeddings and dynamic interaction attention mechanisms. This section details these methods based on data flow sources (homologous streams and heterologous streams).
Homologous Stream
Homologous streams are a set of multi-sensor data with similar intrinsic features, such as multi-view, multi-dimensional, and multi-modal visual flow data. Depending on the fusion mechanism, they can be divided into two categories: interactive fusion and transfer fusion.
Interactive Fusion: The classic fusion pattern of CNNs employs channel concatenation operations. However, the same positions from different modalities may be anisotropic, which is not suited for the translational invariance bias of CNNs. In contrast, the spatial concatenation operation of transformers allows different modalities to interact beyond local constraints.
For local interaction, MVT[126] spatially connects patch embeddings from different views and enhances their interactions using modality-agnostic transformers. To mitigate redundant information from multi-modal features, MVDeTr[127] projects each view of feature maps onto the ground plane and extends multi-scale deformable attention[76] to multi-view designs. Other relevant algorithms include TransFuser[128], COTR[129], which can be referenced in specific papers.
For global interaction, Wang et al.[130] utilize shared backbones to extract features from different views. Instead of pixel-wise/patch-wise concatenation in COTR[129], the extracted global features from each view are concatenated spatially for view fusion in transformers. Considering the angle and position differences between different camera views, TransformerFusion[132] first transforms the feature of each view into an embedding vector with its internal and external camera views. These embeddings are then fed into a global transformer where the attention weights are used for frame selection to effectively compute. To unify multi-sensor data in 3D detection, FUTR3D[131] projects object queries in the class DETR decoder onto a set of 3D reference points in the cloud. These point clouds and their associated features are then sampled from different modalities and spatially concatenated to update the object queries.
Transfer Fusion: Unlike interactive fusion achieved through self-attention in transformer encoders, another form of fusion resembles transfer learning from source data to target data through cross-attention mechanisms. For instance, Tulder et al.[133] inserted two cooperative cross-attention transformers into intermediate backbone features to bridge unregistered multi-view medical images. Instead of pixel-wise attention forms, token-pixel cross attention has been further developed to alleviate heavy computations. Long et al.[134] proposed a cross-temporal transformer for multi-view image depth estimation.
Heterologous Stream
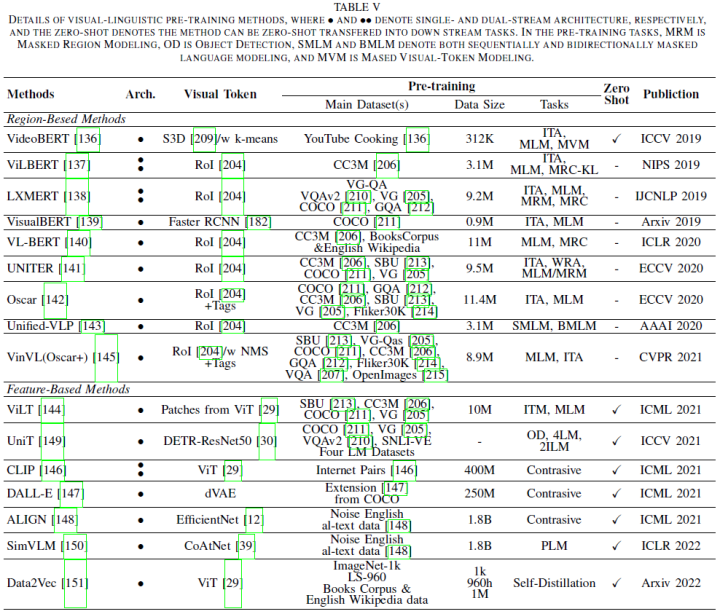
ViTs also excel in heterologous data fusion, particularly in visual-language representation learning. Although different tasks may adopt different training schemes, such as supervised/self-supervised learning or compact/large-scale datasets, the paper categorizes them into two types based solely on their cognitive forms: 1) Visual Language Pre-training, including vision-language pre-training (VLP)[204] and contrastive language-image pre-training (CLIP)[146]; 2) Visual Grounding such as Phrase Grounding (PG), Reference Expression Understanding (REC). More comparisons can be seen in Table 5.
Visual-Language Pre-training: Due to limited annotated data, early VLP methods typically relied on off-the-shelf object detectors[204] and text encoders[5] to extract data-specific features for joint distribution learning. Given image-text pairs, the pre-trained object detector on the Visual Genome (VG) first extracts a set of object-centered RoI features from images. These RoI features, used as visual tokens, are then merged with text embeddings pre-trained for predefined tasks. Essentially, these methods are divided into two-stream and single-stream fusions. Two-stream methods include ViLBERT[137], LXMERT[138].
Single-stream methods include VideoBERT[136], VisualBERT[139], VL-BERT[140], UNITER[141], Oscar[142], Unified VLP[143]. However, these methods heavily depend on visual extractors or their predefined visual vocabulary, leading to bottlenecks that diminish the upper limits of VLP expressiveness. Some algorithms like VinVL[145], ViLT[144], UniT[149], SimVLM[150] attempt to address these issues. Aside from traditional pre-training schemes with multi-task supervision, another recent contrastive learning route has been developed. Relevant algorithms include CLIP[146], ALIGN[148], Data2Vec[151].
Visual Grounding: Compared to VLP, visual grounding has more specific target signal supervision, aiming to locate target objects according to the corresponding descriptions of target objects. In image space, Modulated DETR (MDETR)[152] extends its previous work[30] to phrase grounding pre-training, which trains to locate and assign bounding boxes to each instance phrase within a description. Other relevant algorithms include Referring Transformer[155], VGTR[154], TransVG[153], LanguageRefer[157], TransRefer3D[158], MVT 2022[159], TubeDETR[160], which can be referenced in specific papers.
Discussion and Conclusion
Summary of Recent Improvements
-
For Classification, deep hierarchical transformer backbones are effective in reducing computational complexity[41] and avoiding over-smooth features in deeper layers[37],[42],[66],[67]. Meanwhile, early convolutions[39] are sufficient to capture low-level features, significantly enhancing robustness and reducing computational complexity in shallow layers. Additionally, convolutional projections[54],[55] and local attention mechanisms[35],[44] can improve the locality of ViT. The former[56],[57] may also serve as new methods to replace positional encodings; -
For Detection, transformer necks benefit from the encoder-decoder structure, which has lower computational costs than solely encoder transformers for detection[87]. Therefore, decoders are necessary, but due to their slow convergence, more spatial priors are needed[76],[80]–[85]. Furthermore, sparse attention[76] and scoring networks[78],[79] for foreground sampling help reduce computational costs and accelerate the convergence of ViT; -
For Segmentation, encoder-decoder transformer models can unify the three segmentation sub-tasks into a mask prediction problem through a set of learnable mask embeddings[31],[103],[202]. This box-free method achieves state-of-the-art performance across multiple benchmarks[202]. Additionally, specific hybrid tasks cascaded with box-based ViTs[100] have shown higher performance in instance segmentation; -
For 3D Vision, local hierarchical transformers with scoring networks can effectively extract features from point cloud data. The global modeling capability enables transformers to easily aggregate surface points without complex local designs. Moreover, ViTs can process multi-sensor data in 3D visual recognition, such as multi-view and multi-dimensional data; -
Visual-Language Pre-training mainstream methods have gradually abandoned pre-trained detectors[144] and focused on aligning different data streams in the latent space based on large-scale noisy datasets[148]. Another issue is adapting downstream visual tasks to pre-training schemes for zero-shot transfer[146]; -
Recently popular multi-sensor data fusion architectures are single-stream methods, which spatially connect different data streams and perform interactions simultaneously. Based on single-stream models, many recent works have focused on finding a latent space that ensures semantic consistency across different data streams.
Discussion on ViT
Despite significant advancements in ViT models, the “basic” understanding remains inadequate. Therefore, the paper will focus on reviewing some key issues for deeper and more comprehensive understanding.
How Transformers Bridge the Gap Between Language and Vision
Transformers were originally designed for machine translation tasks[1], where each word in a sentence is viewed as a basic unit representing high-level semantic information. These words can be embedded into representations in a low-dimensional vector space. For visual tasks, each pixel of an image cannot carry semantic information, which does not align with feature embeddings in traditional NLP tasks. Therefore, the key to transferring this feature embedding (i.e., word embedding) to CV tasks is to construct a conversion from images to vectors and effectively retain the features of images. For instance, ViT[29] transforms images into patch embeddings with multiple low-level information under strong relaxation conditions.
The Relationship Between Transformers, Self-Attention, and CNNs
From the perspective of CNNs, their inductive bias mainly manifests as locality, translation invariance, weight sharing, and sparse connections. This simple convolution kernel can efficiently perform template matching in low-level semantic processing, but due to excessive bias, its upper limit is lower than that of transformers.
From the perspective of the self-attention mechanism, with a sufficient number of heads, they can theoretically represent any convolutional layer[28]. This complete attention operation can combine local and global attention and dynamically generate attention weights based on feature relationships. Nevertheless, its practicality is still inferior to SOTA CNNs due to lower accuracy and higher computational costs.
From the perspective of transformers, Dong et al. demonstrated that self-attention exhibits a strong sensitivity bias towards “token uniformity” when trained on deep layers without short connections or FFN[167]. It can be concluded that transformers consist of two key components: self-attention that aggregates the relationships between tokens and position-wise FFN that extracts features from inputs. Although ViT possesses strong global modeling capabilities, CNNs can effectively handle low-level features[39],[58], enhance the locality of ViT[53],[81], and add positional features through padding[56],[57],[172].
Learnable Embeddings for Different Visual Tasks
A variety of learnable embeddings have been designed for different visual tasks. From the perspective of target tasks, these embeddings can be classified into class tokens, object queries, and mask embeddings. Structurally, these ViTs mainly adopt two different modes, encoder and encoder-decoder. As shown in Figure 15, each structure consists of three embedding levels. At the positional level, the application of learnable embeddings in encoder transformers is decomposed into initial tokens[29],[87] and later tokens[42],[103], while learnable positional encodings[30],[81],[202] and learnable decoder input embeddings[76] are applied in encoder-decoder structures.
In terms of quantity, encoders are designed to apply different numbers of tokens. For instance, ViT[29],[40] families and YOLOS[87] add different numbers of tokens in the initial layers, while CaiT[42] and Segmenter[103] utilize these tokens to represent features in the last few layers of different tasks. In the encoder-decoder structure, the learnable positional encodings of the decoder (object queries[30],[81] or mask embeddings[202]) are explicitly added to the decoder inputs[30],[202] or implicitly included in the decoder inputs[80],[81]. Unlike constant inputs, Deformable DETR[76] adopts learnable embeddings as inputs and focuses on encoder outputs.
Inspired by the multi-head attention mechanism, the strategy of using multiple initial tokens is expected to further improve classification performance. However, DeiT[40] points out that these additional tokens will converge towards the same results and will not benefit ViT. From another perspective, YOLOS[87] provides a paradigm by using multiple initial tokens to unify classification and detection tasks, but this encoder design only leads to higher computational complexity. According to observations from CaiT[42], later class tokens can slightly reduce the FLOPs of transformers and enhance performance (from 79.9% to 80.5%). Segmenter[103] also demonstrates the efficiency of strategies in segmentation tasks.
Unlike encoder-only transformers with multiple later tokens, the encoder-decoder structure reduces computational costs. It standardizes ViT in detection[30] and segmentation[202] fields through a small group of object queries (mask embeddings). By combining later tokens and object queries (mask embeddings), structures like Deformable DETR[76], which take object queries and learnable decoder embeddings (equivalent to later tokens) as inputs, can unify the learnable embeddings of different tasks into the transformer encoder-decoder.
Future Research Directions
ViT has made significant progress and achieved encouraging results, approaching or even exceeding SOTA CNN methods across multiple benchmarks. However, some key techniques of ViT are still inadequate to tackle the complex challenges in the CV field. Based on the above analyses, the paper points out several promising research directions for future research.
Set Prediction: Due to the identical gradients of loss functions, multi-class tokens will converge consistently[40]. The set prediction strategy with bipartite loss functions has been widely applied to ViT for many dense prediction tasks[30],[202]. Therefore, it is natural to consider the design of set prediction for classification tasks, such as multi-class token transformers predicting images in mixed patches, similar to the data augmentation strategies in LV-ViT[43]. Furthermore, the one-to-one label assignment in set prediction strategies leads to training instability in the early process, which may reduce the accuracy of final results. Using alternative label assignments and losses to improve set prediction may contribute to new detection frameworks.
Self-Supervised Learning: Self-supervised pre-training of transformers has standardized the NLP field and achieved great success in various applications[2],[5]. With the popularity of self-supervised paradigms in the CV field, convolutional twin networks use contrastive learning for self-supervised pre-training, differing from the masked autoencoders used in the NLP field. Recently, some studies have attempted to design self-supervised ViTs to bridge the differences in pre-training methods between vision and language. Most of them inherit masked autoencoders in the NLP field or contrastive learning schemes in the CV field. ViT does not have a specific supervised method but has radically changed NLP tasks like GPT-3. As mentioned earlier, the encoder-decoder structure can unify visual tasks through joint learning of decoder embeddings and positional encodings. Therefore, it is worth further exploring encoder-encoder transformers for self-supervised learning.
Conclusion
Since ViT demonstrated its effectiveness in CV tasks, it has garnered considerable attention and weakened the dominance of CNNs in the CV field. This article comprehensively reviews over 100 ViT models that have been successively applied to various visual tasks (i.e., classification, detection, and segmentation) and data flows (such as images, point clouds, image-text pairs, and other multi-modal data flows). For each visual task and data flow, a specific taxonomy is proposed to organize the recently developed ViTs, and their performance is further evaluated across various mainstream benchmarks. Through a comprehensive analysis and systematic comparison of all these existing methods, this paper summarizes significant performance improvements, discusses three fundamental issues concerning ViT, and proposes several potential research directions for future investment. We hope this review article will help readers better understand various visual transformers before deciding to explore them in-depth.
References
[1] A Survey of Visual Transformers
ABOUT
关于我们
深蓝学院是专注于人工智能的在线教育平台,已有数万名伙伴在深蓝学院平台学习,很多都来自于国内外知名院校,比如清华、北大等。