Today, let’s talk about Transformers. To make it easy for everyone to understand, we will explain it in simple language. If you need, feel free to click the “Click to Copy” below to receive it for free!
Transformer
Transformers can be described as a type of super brain designed to process sequential data, such as sentences, lyrics, and articles. They excel at such tasks because they can remember the relationships between each word in a sentence. Just like when chatting with a friend, you need to remember what they said and understand the meaning of those words in the conversation.
To enable the Transformer to understand and generate data, we can break it down into several steps:
1. Understanding Relationships Between Words
Imagine you have a sentence: “The cat is sitting on the blanket.” The Transformer needs to understand the relationship between “cat” and “blanket,” such as the fact that the “cat” is “sitting” on the “blanket,” not the other way around. This process is like a super intelligent assistant that continuously observes and understands the relationships between words.
2. Scoring Words
To understand the relationships between words, the Transformer scores the position of each word in the sentence. These scores indicate the importance of each word in the sentence. For example, in “The cat is sitting on the blanket,” the importance of “cat” to “sitting” might be very high because it is the subject of the action. In this way, the Transformer determines which words have the most influence on the overall meaning of the sentence.
3. Collaboration of Multiple Assistants
The Transformer is not just a single “assistant”; it has a group of “assistants,” each focusing on different information. For example, one “assistant” may focus on the relationship between “cat” and “blanket,” while another may focus on the verb “is sitting.” All the “assistants” work together to better understand the sentence.
4. Integrating Information from All Assistants
Once each “assistant” has completed its part of the work, the Transformer integrates this information to form a complete understanding of the sentence. This is similar to discussing a movie plot with friends, where everyone contributes their own perspectives, ultimately reaching a conclusion.
5. Processing Multiple Sentences
The Transformer can process not only one sentence but also multiple sentences, continually learning from them. This enables it to perform various tasks, such as translation, generating new sentences, answering questions, and more.
Core Principles
The core of the Transformer lies in the Self-Attention Mechanism, which allows the model to “attend” to different parts of the input sequence when processing each input. This mechanism enables the model to understand the relationships between each word or symbol and others, rather than processing inputs linearly one by one.
The Transformer consists of two main parts: the Encoder and the Decoder. The encoder converts the input sequence into a hidden representation, while the decoder generates the output sequence from the hidden representation. Both the encoder and decoder are made up of multiple layers, each including a self-attention mechanism and a feedforward neural network (FFN).
Sample Code
Below is a small Transformer model implementation based on PyTorch, trained on a simple dataset:
import torch
import torch.nn as nn
import torch.optim as optim
# Define Self-Attention Mechanism
class SelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(SelfAttention, self).__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.query = nn.Linear(d_model, d_model)
self.key = nn.Linear(d_model, d_model)
self.value = nn.Linear(d_model, d_model)
self.fc_out = nn.Linear(d_model, d_model)
def forward(self, x):
N, seq_length, d_model = x.shape
Q = self.query(x)
K = self.key(x)
V = self.value(x)
Q = Q.reshape(N, seq_length, self.num_heads, self.d_k)
K = K.reshape(N, seq_length, self.num_heads, self.d_k)
V = V.reshape(N, seq_length, self.num_heads, self.d_k)
energy = torch.einsum("nqhd,nkhd->nhqk", [Q, K])
attention = torch.softmax(energy / (self.d_k ** 0.5), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, V])
out = out.reshape(N, seq_length, d_model)
return self.fc_out(out)
# Define Transformer Encoder Layer
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, dropout):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.ff = nn.Sequential(
nn.Linear(d_model, d_model * 4),
nn.ReLU(),
nn.Linear(d_model * 4, d_model)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
attn_output = self.attention(x)
x = self.norm1(attn_output + x)
ff_output = self.ff(x)
x = self.norm2(ff_output + x)
return self.dropout(x)
# Define Transformer Encoder
class TransformerEncoder(nn.Module):
def __init__(self, input_dim, d_model, num_layers, num_heads, dropout):
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList([
TransformerBlock(d_model, num_heads, dropout)
for _ in range(num_layers)
])
self.embed = nn.Linear(input_dim, d_model)
def forward(self, x):
x = self.embed(x)
for layer in self.layers:
x = layer(x)
return x
# Sample Dataset
data = torch.rand(10, 5, 8) # (batch_size, seq_length, input_dim)
# Model Instance
model = TransformerEncoder(input_dim=8, d_model=32, num_layers=2, num_heads=4, dropout=0.1)
# Forward Pass
output = model(data)
print(output.shape)
In this code:
-
SelfAttentiondefines the self-attention mechanism. -
TransformerBlockincludes the self-attention mechanism and feedforward neural network. -
TransformerEncoderis a stack of multiple Transformer layers used to process input data.
Illustrative Sections
Self-Attention Mechanism
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Sample Data
d_model = 8
seq_length = 5
num_heads = 2
# Simulated Query, Key, Value
np.random.seed(42)
Q = np.random.rand(seq_length, d_model)
K = np.random.rand(seq_length, d_model)
V = np.random.rand(seq_length, d_model)
# Calculate Energy Values
energy = np.dot(Q, K.T)
# Calculate Attention Weights
attention_weights = np.exp(energy) / np.sum(np.exp(energy), axis=1, keepdims=True)
# Plot Attention Weight Heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(attention_weights, annot=True, cmap="viridis", xticklabels=range(seq_length), yticklabels=range(seq_length))
plt.title("Self-Attention Weights")
plt.xlabel("Key Positions")
plt.ylabel("Query Positions")
plt.show()
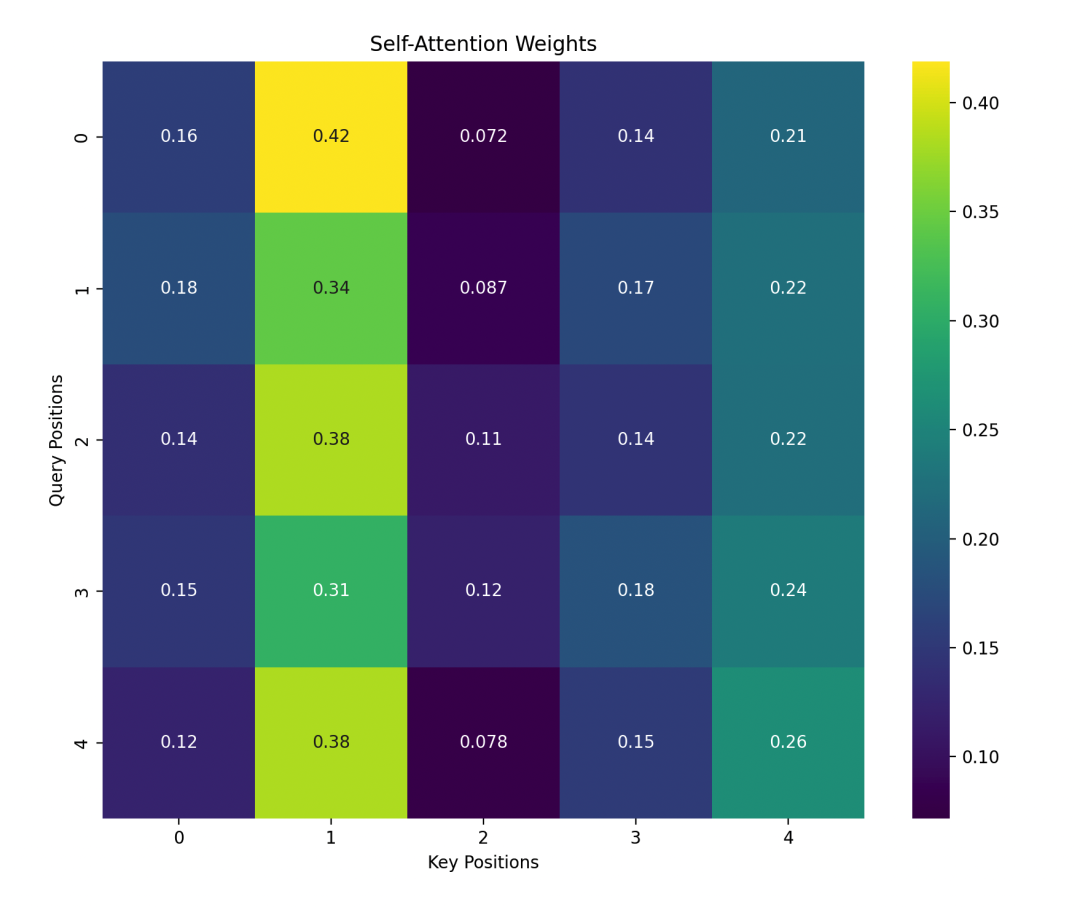
This heatmap shows the similarity between Query and Key, as well as the attention weights converted through softmax.
Multi-Head Attention Mechanism Illustration
# Sample Multi-Head Data
num_heads = 4
d_k = d_model // num_heads
# Simulated Multi-Head Query, Key, Value
Q_heads = np.random.rand(seq_length, num_heads, d_k)
K_heads = np.random.rand(seq_length, num_heads, d_k)
V_heads = np.random.rand(seq_length, num_heads, d_k)
attention_heads = []
for i in range(num_heads):
energy_head = np.dot(Q_heads[:, i, :], K_heads[:, i, :].T)
attention_head = np.exp(energy_head) / np.sum(np.exp(energy_head), axis=1, keepdims=True)
attention_heads.append(attention_head)
# Plot Attention Weights for Each Head
fig, axes = plt.subplots(1, num_heads, figsize=(20, 5))
for i, attention_head in enumerate(attention_heads):
sns.heatmap(attention_head, annot=True, cmap="viridis", ax=axes[i])
axes[i].set_title(f"Head {i + 1}")
plt.suptitle("Multi-Head Attention Weights")
plt.show()
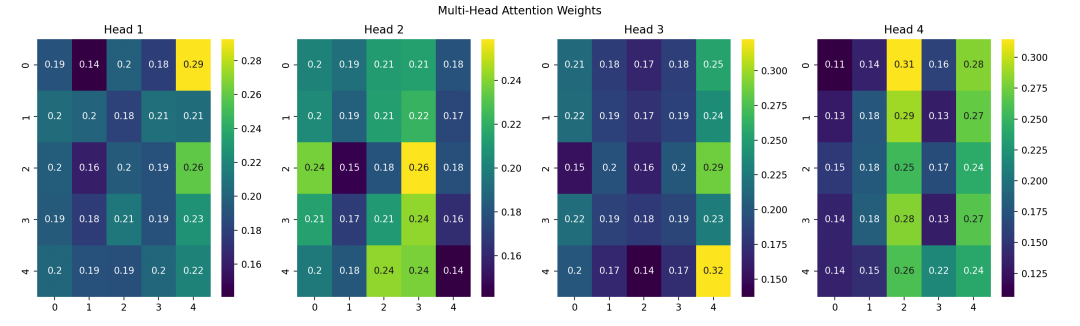
Each subplot shows the attention weights of different heads, illustrating how the model computes attention in different subspaces.
Transformer Encoder Layer Illustration
Demonstrates how data is processed through the self-attention mechanism and feedforward neural network.
# Simulated Data
x = np.random.rand(seq_length, d_model)
# Simulated Self-Attention Output
attn_output = np.random.rand(seq_length, d_model)
# Simulated Feed-Forward Network Output
ff_output = np.random.rand(seq_length, d_model)
# Plotting the Transformer Block Processing
plt.figure(figsize=(12, 6))
plt.subplot(1, 3, 1)
sns.heatmap(x, annot=True, cmap="Blues")
plt.title("Input Sequence")
plt.subplot(1, 3, 2)
sns.heatmap(attn_output, annot=True, cmap="Greens")
plt.title("Self-Attention Output")
plt.subplot(1, 3, 3)
sns.heatmap(ff_output, annot=True, cmap="Reds")
plt.title("Feed-Forward Output")
plt.suptitle("Transformer Block Processing")
plt.show()
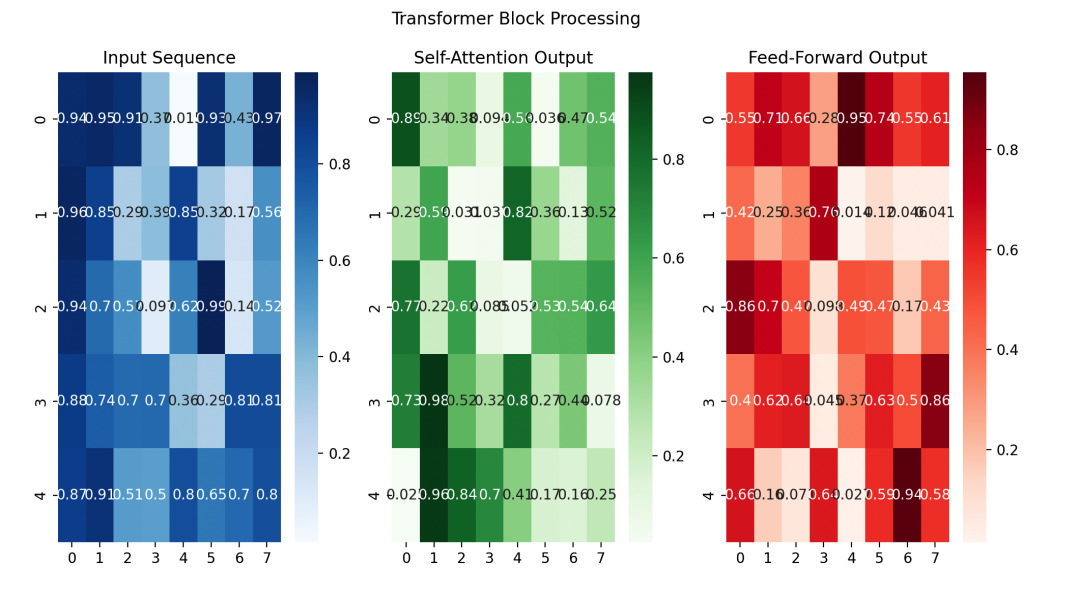
The left side shows the input sequence, the middle shows the output after processing by the self-attention mechanism, and the right side shows the output after processing by the feedforward neural network.
Transformer Encoder Illustration
Demonstrates the entire encoder process, including the embedding layer and multiple encoder layers.
# Simulated Input Data
x = np.random.rand(seq_length, d_model)
num_layers = 3
# Simulated Output for Each Layer
layer_outputs = [np.random.rand(seq_length, d_model) for _ in range(num_layers)]
# Plotting the Entire Transformer Encoder Process
fig, axes = plt.subplots(1, num_layers + 1, figsize=(18, 6))
sns.heatmap(x, annot=True, cmap="Blues", ax=axes[0])
axes[0].set_title("Input Sequence")
for i, layer_output in enumerate(layer_outputs):
sns.heatmap(layer_output, annot=True, cmap="Purples", ax=axes[i + 1])
axes[i + 1].set_title(f"Layer {i + 1} Output")
plt.suptitle("Transformer Encoder Layers")
plt.show()
The first subplot is the input sequence, and the subsequent subplots show the outputs after each encoder layer.
Conclusion
The core of the Transformer model lies in its self-attention and multi-head attention mechanisms, which allow the model to effectively understand and process complex relationships within sequential data. Although its formulas and implementation details may seem complex, the Transformer provides a powerful and flexible framework for handling various natural language processing tasks.
Surprise Material: Transformer Interview Question Bank
Click to copy the link to receive it~