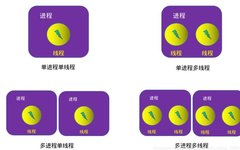
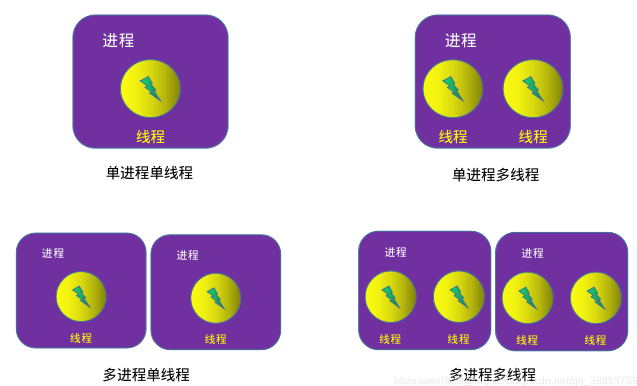
1. Two Parallelization Models in Torch
1.1 DataParallel
DataParallel is a data parallel method provided by PyTorch for model training on multiple GPUs within a single machine. It achieves parallel computation by splitting the input data into several sub-parts (mini-batches) and distributing these sub-parts to different GPUs.
During the forward pass, the input data is divided into multiple copies and sent to different devices for computation. The model is copied to each device, meaning the input batch is evenly distributed across each device, but each device has a copy of the model. Each model copy only needs to process its corresponding sub-part. Note that the batch size should be greater than the number of GPUs. During the backward pass, the gradients from each copy are accumulated into the original model. In summary, DataParallel automatically splits the data and loads it onto the corresponding GPUs, replicates the model on each GPU, performs forward propagation to compute gradients, and aggregates them.
Note: DataParallel is single-process multi-threaded and only works on a single machine.
Example of encapsulation:
import torch
import torch.nn as nn
import torch.optim as optim
# Define the model
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# Initialize model
model = SimpleModel()
# Use DataParallel to distribute the model across multiple GPUs
model = nn.DataParallel(model)1.2 DistributedDataParallel
DistributedDataParallel (DDP) is a module provided by PyTorch for distributed data parallel training, suitable for both single-node multi-GPU and multi-node multi-GPU scenarios. Compared to DataParallel, DDP is more efficient and flexible, capable of parallel training across multiple GPUs and nodes.
DistributedDataParallel is multi-process and can operate on a single machine or multiple machines. DataParallel is generally slower than DistributedDataParallel. Therefore, the mainstream approach is currently DistributedDataParallel.
Example of encapsulation:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def main(rank, world_size):
# Initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# Create the model and move it to GPU
model = SimpleModel().to(rank)
# Wrap the model as a DDP model
ddp_model = DDP(model, device_ids=[rank])
if __name__ == "__main__":
import os
import torch.multiprocessing as mp
# World size: total number of processes
world_size = 4
# Use mp.spawn to start multiple processes
mp.spawn(main, args=(world_size,), nprocs=world_size, join=True)2. Three Architectural Organization Methods for Multi-GPU Training
Based on the discussion in the previous section, all source code in this section is implemented using DDP.
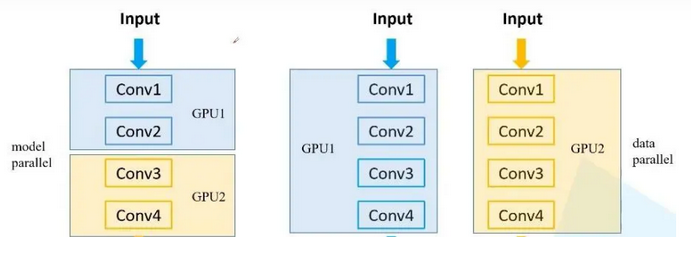
2.1 Data Splitting, Model Not Splitting (Data Parallelism)
Data parallelism splits the input data into several sub-parts (mini-batches) and assigns them to different GPUs for computation. Each GPU has a complete copy of the model. This method is suitable for scenarios where the model is relatively small but needs to handle a large amount of data.
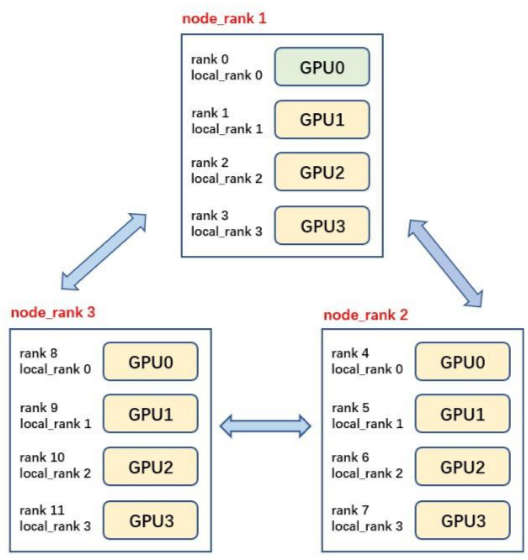
Since the following code involves concepts like rank and world_size, a brief introduction is provided here.
Rank
Rank is an integer that identifies the identity of the current process in the entire distributed training. Each process has a unique rank. The range of rank is from 0 to world_size – 1.
It is used to distinguish between different processes.
Data and model parts can be assigned based on rank.
World Size
World size is an integer that represents the total number of processes participating in distributed training.
It determines the number of all processes in distributed training.
It is used to initialize the communication group, ensuring all processes can communicate and synchronize correctly.
Backend
Backend specifies the backend library used for inter-process communication. Common backends include nccl (for GPUs), gloo (for CPUs and GPUs), and mpi (for various devices).
It determines the specific implementation method for inter-process communication.
It affects the efficiency and performance of training.
Init Method
Init method specifies the method for initializing the distributed environment. Common initialization methods include TCP, shared file systems, and environment variables.
It is used to set the initialization method for inter-process communication, ensuring that all processes can correctly join the distributed training.
Local Rank
Local rank is the local identifier of each process on its node (machine). Processes on different nodes may have the same local rank.
It is used to bind each process to a specific GPU or CPU.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.multiprocessing as mp
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
def train(rank, world_size):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)
model = SimpleModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
criterion = nn.MSELoss().to(rank)
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
inputs = torch.randn(64, 10).to(rank)
targets = torch.randn(64, 1).to(rank)
outputs = ddp_model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
world_size = 4
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)2.2 No Data Splitting, Model Splitting (Model Parallelism)
Model parallelism splits the model into several parts and assigns them to different GPUs. The input data is not split, but different parts of the model are processed by different GPUs. This method is suitable for scenarios where the model is very large and cannot fit entirely on a single GPU.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.multiprocessing as mp
class ModelParallelModel(nn.Module):
def __init__(self):
super(ModelParallelModel, self).__init__()
self.fc1 = nn.Linear(10, 10).to('cuda:0')
self.fc2 = nn.Linear(10, 1).to('cuda:1')
def forward(self, x):
x = x.to('cuda:0')
x = self.fc1(x)
x = x.to('cuda:1')
x = self.fc2(x)
return x
def train(rank, world_size):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)
model = ModelParallelModel()
ddp_model = DDP(model, device_ids=[rank])
criterion = nn.MSELoss().to('cuda:1')
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
inputs = torch.randn(64, 10).to('cuda:0')
targets = torch.randn(64, 1).to('cuda:1')
outputs = ddp_model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
world_size = 2
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)2.3 Data Splitting, Model Splitting (Pipeline Parallelism)
Pipeline parallelism combines data parallelism and model parallelism. Both the input data and the model are split into several parts, with each GPU processing part of the data and part of the model. This method is suitable for large-scale deep learning tasks that require balancing computation and memory demands.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.multiprocessing as mp
class PipelineParallelModel(nn.Module):
def __init__(self):
super(PipelineParallelModel, self).__init__()
self.fc1 = nn.Linear(10, 10)
self.fc2 = nn.Linear(10, 1)
def forward(self, x):
if self.fc1.weight.device != x.device:
x = x.to(self.fc1.weight.device)
x = self.fc1(x)
if self.fc2.weight.device != x.device:
x = x.to(self.fc2.weight.device)
x = self.fc2(x)
return x
def train(rank, world_size):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)
model = PipelineParallelModel()
model.fc1.to('cuda:0')
model.fc2.to('cuda:1')
ddp_model = DDP(model)
criterion = nn.MSELoss().to('cuda:1')
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
inputs = torch.randn(64, 10).to('cuda:0')
targets = torch.randn(64, 1).to('cuda:1')
outputs = ddp_model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
dist.destroy_process_group()
if __name__ == "__main__":
world_size = 2
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)3. NCCL and DistributedSampler
3.1 NCCL
NCCL is a communication library developed by Nvidia specifically for collective communication between multiple GPUs, or a framework for communication between multiple GPU cards. It has a certain degree of topology awareness and provides collective communication APIs including AllReduce, Broadcast, Reduce, AllGather, ReduceScatter, etc. It also supports users to use ncclSend() and ncclRecv() to implement various complex point-to-point communications, such as One-to-all, All-to-one, All-to-all, etc. In most cases, it can achieve high bandwidth and low latency through PCIe, NVLink, NVSwitch, etc. within the server and RoCEv2, IB, TCP networks between servers.
It addresses the issues of GPU topology recognition and optimization of collective communication mentioned earlier. NCCL abstracts the underlying complex details and provides APIs for training frameworks to call, while connecting the GPUs within and between machines to efficiently transfer model parameters.
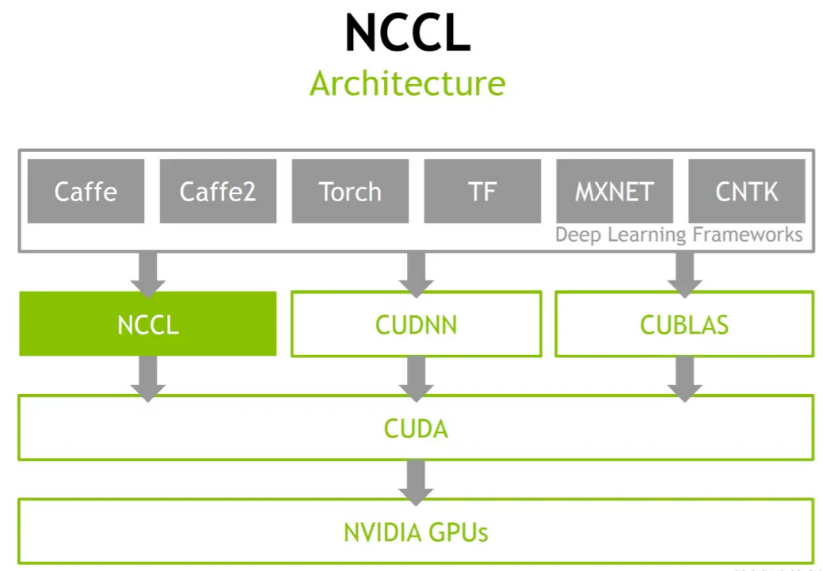
3.2 Common Parameters
Modify environment variables or change relevant parameter options in nccl.conf. This can change communication characteristics, thereby affecting performance.
NCCL_P2P_DISABLE is enabled by default, which is generally more efficient, and point-to-point communication latency and bandwidth will improve.
NCCL_P2P_LEVEL allows setting the level of P2P communication after it is enabled; for example, under certain conditions, P2P communication can be enabled, refer to the documentation for specifics (0-5).
NCCL_SOCKET_NTHREADS increasing its number can improve socket transmission efficiency, but will increase the CPU load.
NCCL_BUFFLE_SIZE defines the amount of cached data; the larger the cache, the larger the data transmitted in a single ring transmission, which naturally puts more pressure on bandwidth but reduces the total latency. The default value is 4M (4194304), and note to use bytes when setting (byte size).
NCCL_MAX/MIN_NCHANNELS defines the minimum and maximum rings; more rings will increase the pressure on GPU memory and bandwidth, affecting computational performance.
NCCL_CHECKS_DISABLE checks parameters before each collective communication, which will increase latency; in production environments, it can be set to 1. The default is 0.
NCCL_CHECK_POINTERS checks CUDA memory pointers before each collective communication, which will also increase latency; in production environments, it can be set to 1. The default is 0.
NCCL_NET_GDR_LEVEL defines the condition for GDR triggering; by default, it uses GDR when the GPU and NIC are mounted on the same switch.
NCCL_IGNORE_CPU_AFFINITY ignores CPU affinity with applications, focusing on GPU and NIC affinity.
NCCL_ALGO specifies the algorithm used for communication: ring, tree, Collnet.
NCCL_IB_HCA represents the devices used for IB: Mellanox mlx5 series HCA devices.
A40 (GPU3-A40:596:596 [2] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB ; OOB ib0:66.66.66.211<0>),
V100 (gpu196-v100:786:786 [5] NCCL INFO NET/IB : Using [0]mlx5_0:1/IB [1]mlx5_1:1/IB ; OOB ib0:66.66.66.110<0>),
A100 (GPU6-A100:686:686 [1] NCCL INFO NET/IB : Using [0]mlx5_0:1/RoCE [1]mlx5_2:1/IB [2]mlx5_3:1/IB ; OOB ib0:66.66.66.128<0>),
NCCL_IB_HCA=mlx5 will poll all devices by default.
NCCL_IB_HCA=mlx5_0:1 specifies one of the devices.
A100 has two ports; if both are enabled, there may be fluctuations in training speed; if only one port is specified, the training speed will decrease.
3.3 DistributedSampler
The principle of DistributedSampler is illustrated as follows: assuming the current dataset has 0-10, a total of 11 samples, using 2 GPUs for computation. First, the data order is shuffled, then 11/2 = 6 (rounded up), then 6 multiplied by the number of GPUs 2 = 12. Since there are only 11 data points, the first data (data with index 6) is added to the end, resulting in 12 data points that can be evenly distributed to each GPU. The data is then allocated: the data is distributed to different GPUs in intervals.
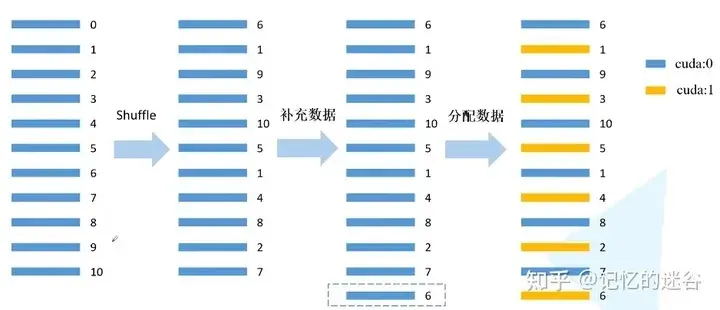
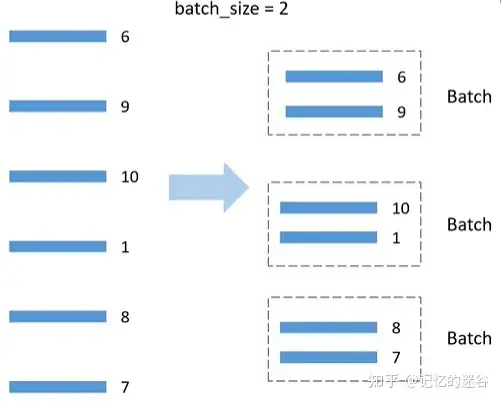
The principle of BatchSampler: DistributedSampler distributes the data to two GPUs. Taking the first GPU as an example, the distributed data is 6, 9, 10, 1, 8, 7. Assuming batch_size=2, the data is grouped in pairs sequentially. During training, each time a batch of data is retrieved, it is taken from the organized batches. Note: BatchSampler is only applied to the training set; the validation set does not use BatchSampler.
train_dset = NBADataset(
obs_len=self.cfg.past_frames,
pred_len=self.cfg.future_frames,
training=True)
self.train_sampler = torch.utils.data.distributed.DistributedSampler(train_dset)
self.train_loader = DataLoader(train_dset, batch_size=self.cfg.train_batch_size, sampler=self.train_sampler,
num_workers=4, collate_fn=seq_collate)4. Comprehensive Testing for Multi-Process Startup
4.1 Two Ways to Start Multi-Process Training on Multiple GPUs
There are two ways to start multi-GPU training: one is using PyTorch’s built-in torchrun, and the other is to design a custom multi-process program.

The following is a simple demo for torch.distributed.launch:
The running method is:
# Directly run torchrun --nproc_per_node=4 test.py
# Equivalent to python -m torch.distributed.launch --nproc_per_node=4 test.pytorchrun
Actually runs:
/usr/local/mambaforge/envs/led/lib/python3.7/site-packages/torch/distributed/launch.py (depending on the reader’s environment)
python -m torch.distributed.launch will also find and execute this program’s Python file, and this command helps set some environment variables to start the backend; otherwise, you need to set the environment variables manually.
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import os
def example(rank, world_size):
# create default process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "10086"
main()The following is a design demo of multiprocessing:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
dist.init_process_group(
backend='nccl',
init_method='tcp://localhost:12355',
rank=rank,
world_size=world_size
)
torch.cuda.set_device(rank)
dist.barrier()
def cleanup():
dist.destroy_process_group()
def demo_basic(rank, world_size):
setup(rank, world_size)
model = torch.nn.Linear(10, 10).to(rank)
ddp_model = DDP(model, device_ids=[rank])
inputs = torch.randn(20, 10).to(rank)
outputs = ddp_model(inputs)
print(f"Rank {rank} outputs: {outputs}")
cleanup()
def main():
world_size = torch.cuda.device_count()
mp.spawn(demo_basic, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
main()4.2 Multi-Process Debugging Methods for Multi-GPU Training (Using PyCharm as an Example)
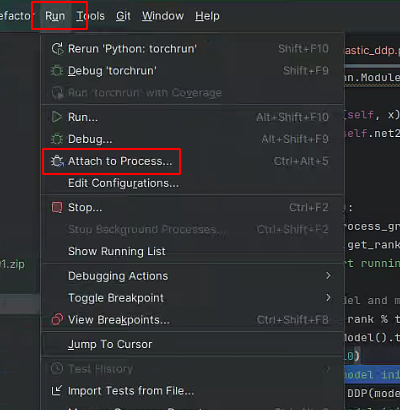
If readers are using the multiprocessing method, they can directly run and debug using local tools. If using the torchrun method, we need to manually configure Run/Debug Configurations. According to section 4.1, we need to find the prototype file launch.py. For example, in my environment, my launch file is located at /usr/local/mambaforge/envs/led/lib/python3.7/site-packages/torch/distributed/launch.py. I add a configuration, naming it torchrun, and selecting launch.py in the Script path column, with parameters:
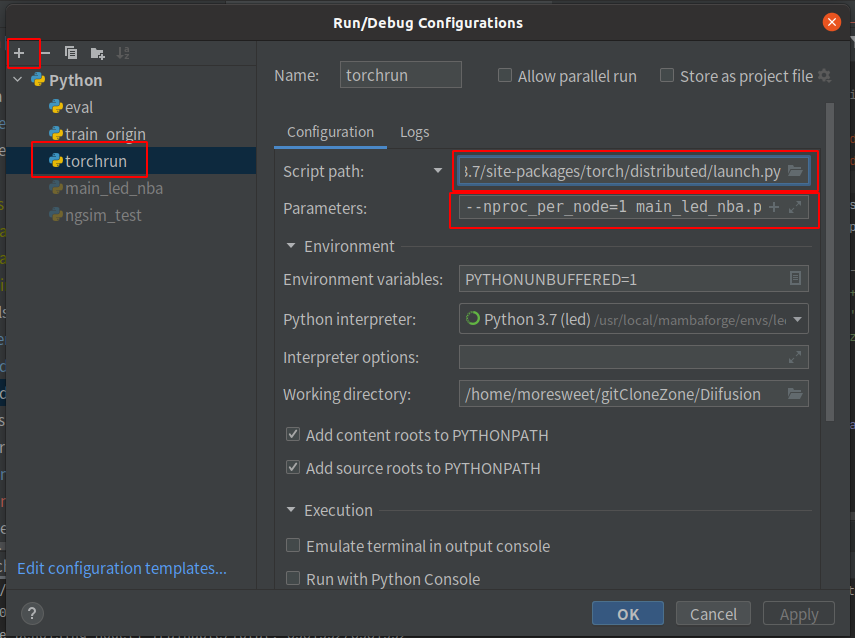
In methods like torchrun, we can see that multiple processes or threads are started, while the default debugging window can only provide breakpoints for the main process’s code flow. At this point, we need to look at the PID of the started processes.
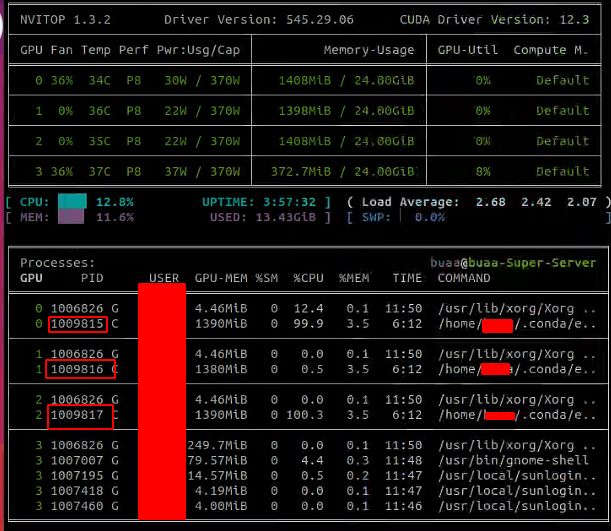
Bind to the corresponding process based on the PID.
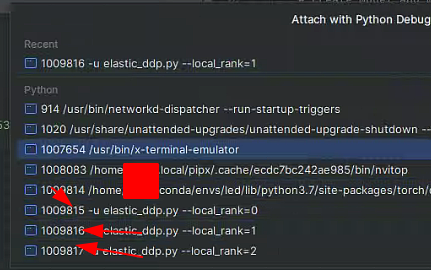
We can see that breakpoints can be set in the program of the second GPU.
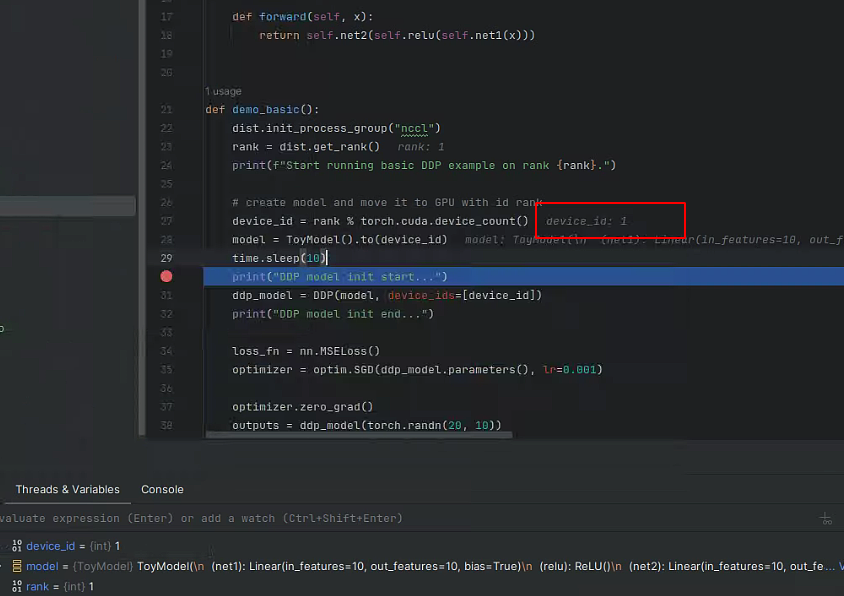
Test code, startup method torchrun.

import time
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
model = ToyModel().to(device_id)
time.sleep(10)
print("DDP model init start...")
ddp_model = DDP(model, device_ids=[device_id])
print("DDP model init end...")
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_id)
loss_fn(outputs, labels).backward()
optimizer.step()
if __name__ == "__main__":
demo_basic()Note: Forcibly terminating a DDP program may result in unreleased GPU memory. In this case, you need to find the port monitored by NCCL, for example, mine is 29500.

Appendix: Reference Links
Differences between DP and DDP: https://zhuanlan.zhihu.com/p/343951042?utm_id=0
DDP Initialization: https://www.cnblogs.com/rossiXYZ/p/15584032.htm
Common Deadlock Issues: https://blog.csdn.net/weixin_42001089/article/details/122733667
https://www.cnblogs.com/azureology/p/16632988.html
https://github.com/IDEA-CCNL/Fengshenbang-LM/issues/123
NCCL: https://zhuanlan.zhihu.com/p/667221519
NCCL Parameters:
https://zhuanlan.zhihu.com/p/661597951init_process_group:
https://blog.csdn.net/m0_37400316/article/details/107225030
Parameter Checks:
https://blog.csdn.net/weixin_46552088/article/details/138687997
Distributed Training Architecture: https://zhuanlan.zhihu.com/p/689464092https://zhuanlan.zhihu.com/p/706298084



