Click the above“Beginner’s Guide to Vision”, select to add a bookmark or “pin”Heavyweight content delivered at the first time
Source: Wenjiqi Dance
This article is about 6400 words and is recommended to read in 15 minutes.
This article introduces 20 must-know automated machine learning libraries.
AutoML refers to automated machine learning. It explains how to automate the end-to-end process of machine learning at the organizational and educational levels. Machine learning models basically include the following steps:
Data reading and merging to make it available.
Data preprocessing refers to data cleaning and data organization.
Optimizing the feature and model selection process.
Applying it to applications to predict accurate values.
Initially, all these steps were done manually. However, now with the emergence of AutoML, these steps can be automated. AutoML is currently divided into three categories:
AutoML for automatic parameter tuning (a relatively basic type)
AutoML for non-deep learning, such as AutoSKlearn. This type is mainly applied to data preprocessing, automatic feature analysis, automatic feature detection, automatic feature selection, and automatic model selection.
AutoML for deep learning/neural networks, including NAS and ENAS, and Auto-Keras for frameworks.
Why AutoML?
The demand for machine learning is growing. Organizations have adopted machine learning at the application level. Many improvements are still underway, and many companies are still working to provide better solutions for the deployment of machine learning models.To deploy, businesses need a team of experienced data scientists who expect high salaries. Even if a company does have a great team, often more experience is needed rather than AI knowledge to determine which model is best suited for the business. The success of machine learning in various applications has led to an increasing demand for machine learning systems. It should be easy to use even for non-experts. AutoML tends to automate as many steps as possible in the ML pipeline and maintain good model performance with minimal manpower.
Three Major Advantages of AutoML
It improves efficiency by automating the most repetitive tasks. This allows data scientists to spend more time on problems rather than models.
The automated ML pipeline also helps avoid potential errors caused by manual work.
AutoML is a major step towards democratizing machine learning, making ML capabilities accessible to everyone.
Let’s take a look at some of the most common AutoML libraries provided in different programming languages:
Here are implementations in Python
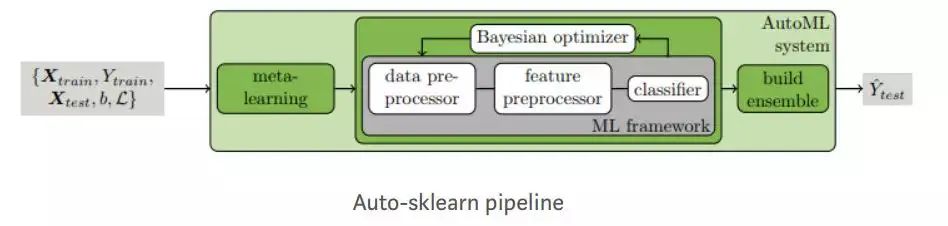
auto-sklearn
Imageauto-sklearn is an automated machine learning toolkit that serves as a direct replacement for scikit-learn estimators.Auto-SKLearn frees machine learning users from algorithm selection and hyperparameter tuning. It includes feature design methods such as one-stop, numeric feature standardization, and PCA. The model uses SKLearn estimators to handle classification and regression problems. Auto-SKLearn creates pipelines and uses Bayesian search to optimize them. In the ML framework, two components are added for hyperparameter tuning through Bayesian inference: meta-learning for using Bayesian initialization optimizers and evaluating configurations of automatic ensemble construction during optimization.Auto-SKLearn performs well on medium to small datasets but cannot generate state-of-the-art performance modern deep learning systems on large datasets.For detailed principles and case studies, see (click to view): A Comprehensive Understanding of Automated Machine Learning AutoML: Auto-Sklearn
MLBox is a powerful automated machine learning Python library. For detailed principles and case studies, see (click to view) A Comprehensive Understanding of Automated Machine Learning AutoML: MLBoxAccording to the official documentation, it has the following features:
Fast reading and distributed data preprocessing/cleaning/formatting
Highly powerful feature selection and leakage detection as well as precise hyperparameter optimization
Prediction with model interpretation, MLBox has been tested on Kaggle and shows good performance.
Pipeline
MLBox Architecture
The main MLBox package contains three sub-packages:
Preprocessing: Reading and preprocessing data
Optimization: Testing or optimizing various learners
Prediction: Predicting targets on the test dataset
Official website:https://github.com/AxeldeRomblay/MLBox
TPOT
TPOT stands for Tree-based Pipeline Optimization Tool, which uses genetic algorithms to optimize machine learning pipelines. TPOT is built on scikit-learn and uses its own regressor and classifier methods. TPOT explores thousands of possible pipelines and finds the one that best fits the data.TPOT automates the most tedious part of machine learning by intelligently exploring thousands of possible pipelines to find the one that best fits our data.TPOT is built on scikit-learn, so all the code it generates should look familiar… if we are familiar with scikit-learn. For detailed principles and case studies, see (click to view) A Comprehensive Understanding of Automated Machine Learning AutoML: TPOTTPOT is still under active development.Here are two examples for classification and regression problems:
Classification
This is an example with the optical recognition function of the handwritten digit dataset.
This code will discover a pipeline that achieves 98% test accuracy. The corresponding Python code should be exported to the tpot_digits_pipeline.py file, which looks similar to the following:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline, make_union
from sklearn.preprocessing import PolynomialFeatures
from tpot.builtins import StackingEstimator
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: 0.9799428471757372
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
StackingEstimator(estimator=LogisticRegression(C=0.1, dual=False, penalty="l1")),
RandomForestClassifier(bootstrap=True, criterion='entropy',
max_features=0.35000000000000003,
min_samples_leaf=20, min_samples_split=19,
n_estimators=100))
# Fix random state for all the steps in exported pipelineset_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
Regression
TPOT can optimize pipelines to solve regression problems. Here is a minimal working example using the Boston housing price dataset.
This will result in a pipeline achieving about 12.77 mean squared error (MSE), and the Python code in tpot_boston_pipeline.py should look similar to:
import numpy as np
import pandas as pd
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE',
sep='COLUMN_SEPARATOR',
dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: -10.812040755234403
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
ExtraTreesRegressor(bootstrap=False, max_features=0.5,
min_samples_leaf=2, min_samples_split=3,
n_estimators=100))
# Fix random state for all the steps in exported pipelineset_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
Github link https://github.com/EpistasisLab/tpot
Lightwood
A framework based on Pytorch that breaks down machine learning problems into smaller chunks, seamlessly integrating with one goal: to make it so simple that you only need one line of code to build a predictive model.
Installation
We can install Lightwood from pip:
pip3 install lightwood
Note: Depending on our environment, we may need to use pip instead of pip3 in the above command.Given a simple sensor_data.csv, we can predict the value of sensor3.Import the predictor variable from Lightwood
ImageMindsDB is an open-source AI layer for existing databases that allows you to easily develop, train, and deploy the latest machine learning models using SQL queries.Official link:https://github.com/mindsdb/mindsdb
mljar-supervised
Imagemljar-supervised is an automated machine learning Python package for tabular data. It is designed to save time for data scientists. It abstracts common methods for preprocessing data, building machine learning models, and performing hyperparameter tuning to find the best model. This is not a black box, as you can see exactly how the ML pipeline is constructed (each ML model has a detailed Markdown report).In mljar-supervised, it will help you:
Explain and understand your data,
Try many different machine learning models,
Create detailed Markdown reports about all models through analysis,
Save, rerun, and load analyses and ML models.
It has three built-in working modes:
Interpretation mode, very suitable for explaining and understanding data, which includes many data interpretations such as decision tree visualization, linear model coefficient display, permutation importance, and SHAP explanations of the data,
Execution, to build ML pipelines for production,
Competition mode, for training advanced ML models with ensemble and stacking capabilities, intended for ML competitions.
Official link:https://github.com/mljar/mljar-supervisedv
Auto-Keras
ImageAuto-Keras is an open-source software library for automated machine learning (AutoML) developed by the DATA Lab. Auto-Keras is built on top of the deep learning framework Keras and provides functionality for automatically searching for deep learning model architectures and hyperparameters.Auto-Keras follows the classic Scikit-Learn API design, making it easy to use. The current version provides functionality for automatically searching hyperparameters during deep learning.In Auto-Keras, the trend is to simplify ML by using an automated neural architecture search (NAS) algorithm. NAS essentially uses a set of algorithms to automatically tune models, replacing deep learning engineers/practitioners.Official link:https://github.com/keras-team/autokeras
Neural Architecture Search NNI
ImageNNI is an open-source AutoML toolkit for neural architecture search and hyperparameter tuning. NNI provides a CommandLine Tool as well as a user-friendly Web UI to manage training experiments. With a scalable API, you can customize your own AutoML algorithms and training services. To make it easier for new users, NNI also provides a set of built-in state-of-the-art AutoML algorithms and out-of-the-box support for popular training platforms.Official website https://nni.readthedocs.io/en/latest/
Ludwig
Ludwig is a toolbox that allows users to train and test deep learning models without writing code. It is built on top of TensorFlow, Ludwig is built on the principle of scalability and based on data type abstraction, easily adding support for new data types and new model architectures, allowing practitioners to quickly train and test deep learning models with strong benchmarks obtained by researchers for comparison, and with experimental setups that ensure comparability by performing the same data processing and evaluation.Ludwig provides a set of model architectures that can be combined to create end-to-end models for a given use case. For example, if deep learning libraries provide the foundation for building buildings, Ludwig provides the buildings to build cities, and you can choose from available buildings or add your own to the available buildings.
No coding required: No coding skills are needed to train models and use them for predictions.
Generality: The new data type-based deep learning model design approach makes the tool usable in many different use cases.
Flexibility: Experienced users have broad control over the building and training of models, while new users find it easy to use.
Scalability: Easy to add new model architectures and new feature data types.
Understandability: The internals of deep learning models are often considered black boxes, but Ludwig provides standard visualizations to understand their performance and compare their predictions.
Open-source: Apache License 2.0
Official link https://github.com/uber/ludwig
AdaNet
AdaNet is a lightweight framework based on TensorFlow that automatically learns high-quality models with minimal expert intervention. AdaNet builds on recent efforts in AutoML to provide fast, flexible learning guarantees. Importantly, AdaNet provides a general framework for learning not only neural network architectures but also ensembles for better models.AdaNet has the following goals:
Ease of use: Provides familiar APIs (e.g., Keras, Estimator) for training, evaluating, and serving models.
Speed: Scales with available computation and quickly generates high-quality models.
Flexibility: Allows researchers and practitioners to extend AdaNet to novel subnet architectures, search spaces, and tasks.
Learning guarantees: Optimizes to provide theoretical learning guarantees.
Official link https://github.com/tensorflow/adanet
Darts
The algorithm is based on continuous relaxation and gradient descent in the architecture space. It can efficiently design high-performance convolutional architectures for image classification (on CIFAR-10 and ImageNet), as well as recurrent architectures for language modeling (on Penn Treebank and WikiText-2). Only one GPU is needed.Official link https://github.com/quark0/darts
automl-gs
Provide an input CSV file and a target field you want to predict for automl-gs, and get a trained high-performance machine learning or deep learning model along with native Python code pipelines that allow you to integrate that model into any prediction workflow. No black box: you can see exactly how the data is processed, how the model is built, and how to adjust as needed.Imageautoml-gs is an AutoML tool that, unlike Microsoft’s NNI, Uber’s Ludwig, and TPOT, provides a zero-code/model definition interface to obtain optimized models and data transformation pipelines in several popular ML/DL frameworks with minimal Python dependencies.Official link https://github.com/minimaxir/automl-gsHere are implementations in R
AutoKeras R Interface
AutoKeras is an open-source software library for automated machine learning (AutoML). It is developed by the DATA Lab and community contributors at Texas A&M University. The ultimate goal of AutoML is to provide easy access to deep learning tools for domain experts with limited data science or machine learning backgrounds. AutoKeras provides functionality for automatically searching for deep learning model architectures and hyperparameters.Check the AutoKeras blog post on the RStudio TensorFlow for R blog.Official documentation https://github.com/r-tensorflow/autokeras
Here are implementations in Scala
TransmogrifAI
TransmogrifAI (pronounced trăns-mŏgˈrə-fī) is an AutoML library written in Scala that runs on Apache Spark. Its development focuses on increasing the productivity of machine learning developers through automation and an API for enforcing compile-time type safety, modularity, and reuse. Through automation, it achieves accuracy close to manual tuning of models, with time reduced by nearly 100 times.If you need a machine learning library to do the following, use TransmogrifAI:
Build production-ready machine learning applications in hours instead of months
Build machine learning models in machine learning without a PhD
Official link https://github.com/salesforce/TransmogrifAI
Here are implementations in Java
Glaucus
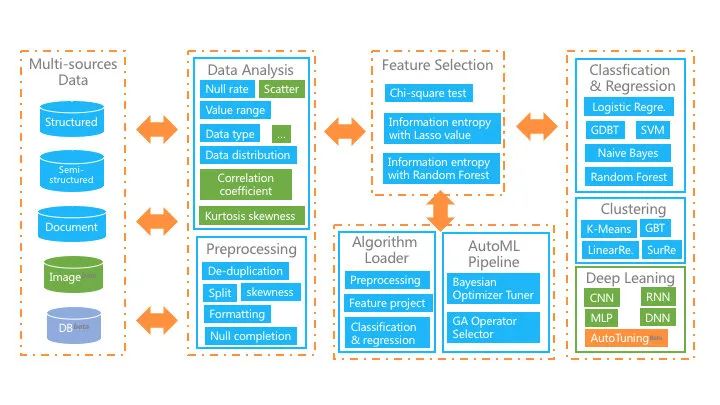
ImageGlaucus is a data stream-based machine learning suite that combines automated machine learning pipelines, simplifies the complex processes of machine learning algorithms, and applies excellent distributed data processing engines. It helps non-data science professionals across fields to easily gain the benefits of powerful machine learning tools in a simple way.Users only need to upload data, configure simply, select algorithms, and train algorithms through automatic or manual parameter tuning. The platform also provides rich evaluation metrics for training models, allowing non-professionals to maximize the role of machine learning in their fields. The overall structure of the platform is shown in the figure below, with the main functions:Image
Receive multi-source datasets, including structured, document, and image data;
Provide rich mathematical statistical functions, graphical interfaces to make it easy for users to grasp data situations;
In automatic mode, we achieve full pipeline automation from preprocessing, feature engineering to machine learning algorithms;
In manual mode, it greatly simplifies the machine learning process and provides automatic data cleaning, semi-automatic feature selection, and deep learning suites.
Official website https://github.com/ccnt-glaucus/glaucusIntroducing a Few Other Tools
H2O AutoML
ImageThe H2O AutoML interface is designed to have as few parameters as possible, so all the user needs to do is point to their dataset, identify the response column, and optionally specify time limits or limits on the total number of models to train.In R and Python API, AutoML uses the same data-related parameters x, y, training_frame, validation_frame as other H2O algorithms. Most of the time, all you need to do is specify the data parameters. Then, you can configure values for max_runtime_secs and/or max_models to set explicit time or model count limits during runtime.For detailed principles and case studies, see (click to view) A Comprehensive Understanding of Automated Machine Learning AutoML: H2OOfficial link https://github.com//h2oai/h2o-3/blob/master/h2o-docs/src/product/automl.rst
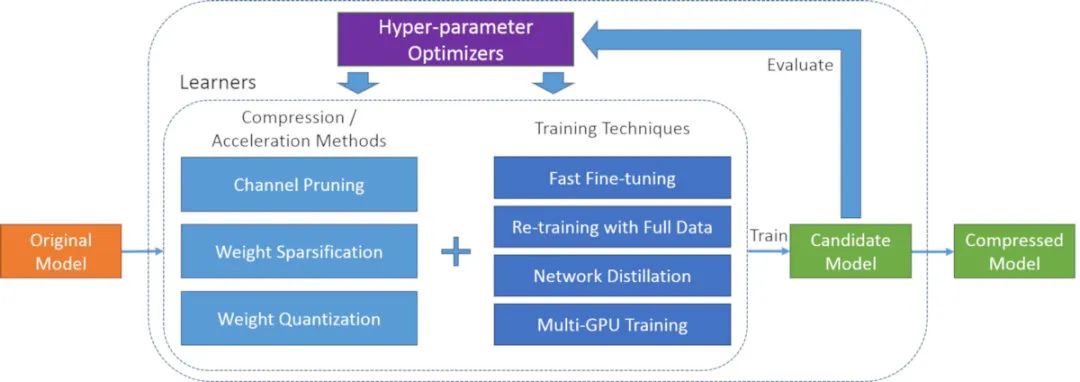
PocketFlow
PocketFlow is an open-source framework for compressing and accelerating deep learning models with minimal manpower. Deep learning is widely used in various fields such as computer vision, speech recognition, and natural language translation. However, deep learning models are often computationally expensive, which limits further applications on mobile devices with limited computing resources.PocketFlow aims to provide developers with an easy-to-use toolkit to improve inference efficiency without significantly compromising performance or degrading performance. Developers only need to specify the desired compression and/or acceleration ratio, and PocketFlow will automatically choose the appropriate hyperparameters to generate efficient compressed models for deployment.ImageOfficial link https://github.com/Tencent/PocketFlow
Ray
ImageRay provides a simple generic API for building distributed applications.Ray is packaged with the following libraries to accelerate machine learning workloads:
Tune: Scalable hyperparameter tuning
RLlib: Scalable reinforcement learning
RaySGD: Distributed training wrapper
Ray Serve: Scalable and programmable serving
Install Ray using the following: pip install rayOfficial link https://github.com/ray-project/ray
SMAC3
SMAC is a tool for algorithm configuration that can optimize the parameters of any algorithm across a set of instances. This also includes hyperparameter optimization for ML algorithms. The main core includes Bayesian optimization and an active racing mechanism to efficiently determine which of two configurations performs better.For a detailed explanation of its main ideas, see Hutter, F. and Hoos, H. H. and Leyton-Brown, K. Sequential Model-Based Optimization for General Algorithm Configuration In: Proceedings of the conference on Learning and Intelligent Optimization (LION 5)SMAC v3 is written in Python3 and has been continuously tested with Python3.6 and python3.6. Its random forest is written in C++.
Conclusion
AutoML libraries are important because they can automate repetitive tasks such as pipeline creation and hyperparameter tuning. They save time for data scientists so that they can spend more time on business problems. AutoML also allows everyone to use machine learning technology instead of just a small group. Data scientists can accelerate ML development by implementing truly effective machine learning using AutoML.Let’s see that the success of AutoML will depend on the usage and needs of organizations. Time will determine its fate. But for now, I can say that AutoML is important in the field of machine learning.
Reprinted from Wenjiqi Dance, copyright belongs to the original author, used for academic sharing only
Editor: Wang JingProofreader: Wang Xin
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Beginner's Guide to Vision" public account to download the first OpenCV extension module tutorial in Chinese on the Internet, covering more than twenty chapters including extension module installation, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of the "Beginner's Guide to Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV to achieve advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided later). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format when noting, otherwise, it will not be approved. After successful addition, invitations will be sent to relevant WeChat groups based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group, thank you for your understanding~