
Dream Morning Reporting from Aofeisi Quantum Bit | Public Account QbitAI
What algorithm is most likely to win prizes in machine learning competitions on Kaggle?
You might say: Of course, it’s deep learning.
Not really. According to statistics, the most winning algorithms are gradient boosting algorithms like XGBoost.
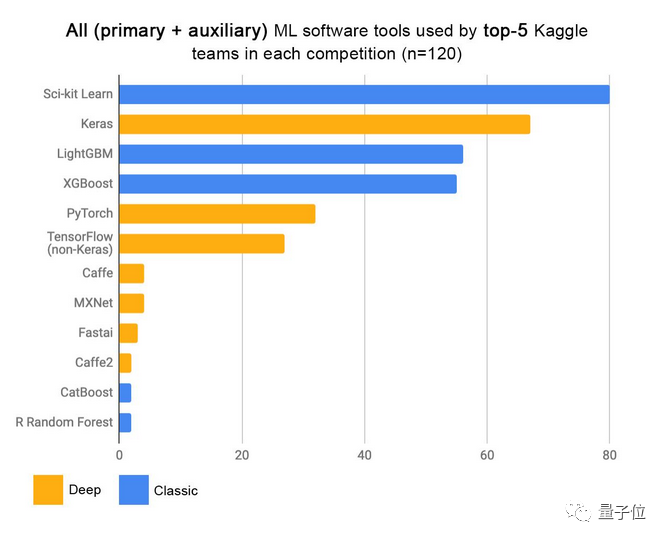
This is strange. Deep learning shines in fields like image and language processing, so why does it fall short in machine learning competitions compared to its older counterparts?
A Reddit user posted this question in the machine learning section (r/MachineLearning) and provided an intuitive conclusion:
Boosting algorithms perform best on tabular data provided in competitions, while deep learning is suitable for very large non-tabular datasets (like tensors, images, audio, and text).
But can the principles behind this be explained using mathematical principles?
Furthermore, can we determine which algorithm is more suitable for a given task based solely on the type and scale of the dataset?
This could save a lot of time. For an extreme example, if you try to use AlphaGo for logistic regression, you’re going down the wrong path.
The question has attracted many participants in the discussion, and some replied:
This is a very active research area; a doctoral thesis could easily be written on this topic.
Key Factor: Can Features Be Manually Extracted?
Some users indicated that while it’s difficult to provide a detailed argument, we can make some guesses.
The tree-based gradient boosting algorithm can simply separate data, like this:
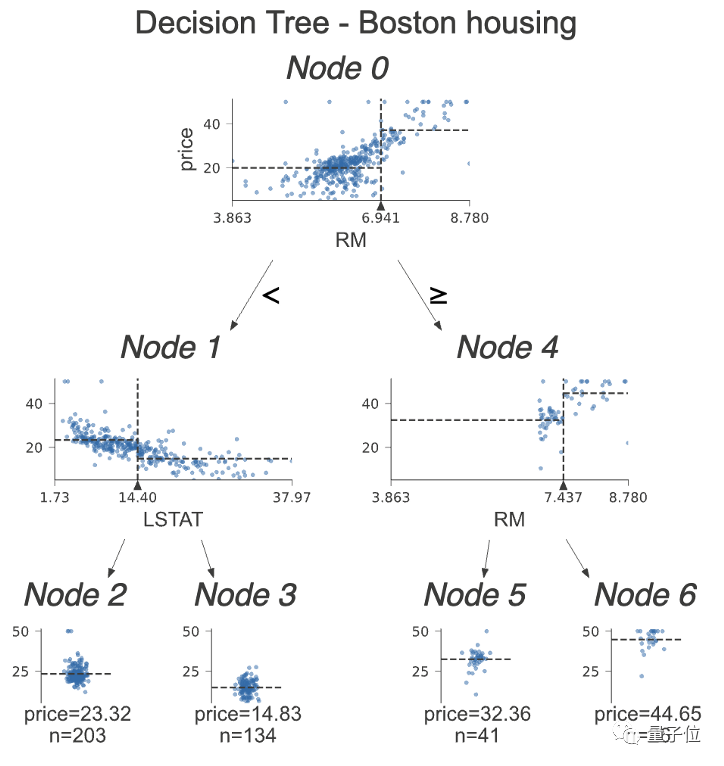
If the feature is less than a certain value, go left; otherwise, go right, breaking the data down step by step.
In deep learning, multiple hidden layers are needed to transform the input space into a linearly separable form:
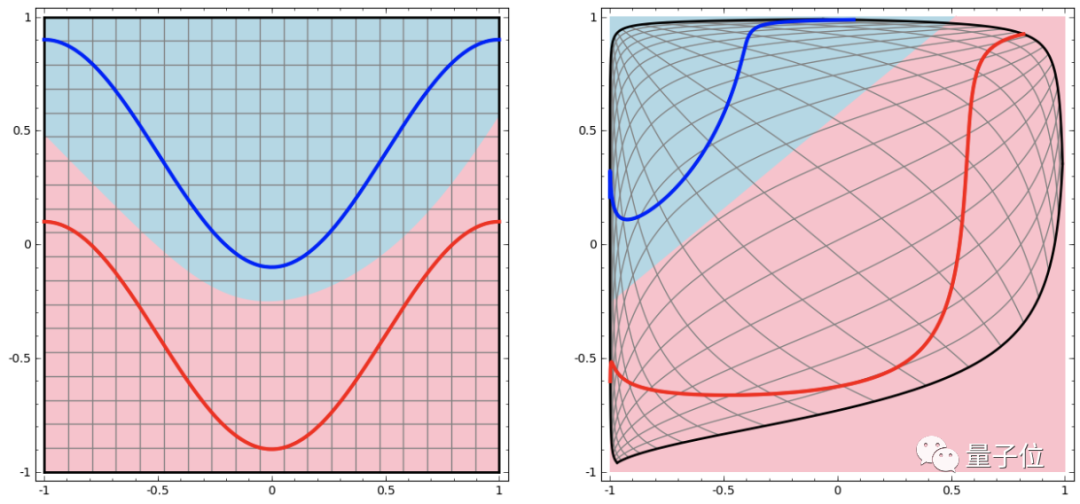
This process is like ‘kneading’ the input space in high dimensions:
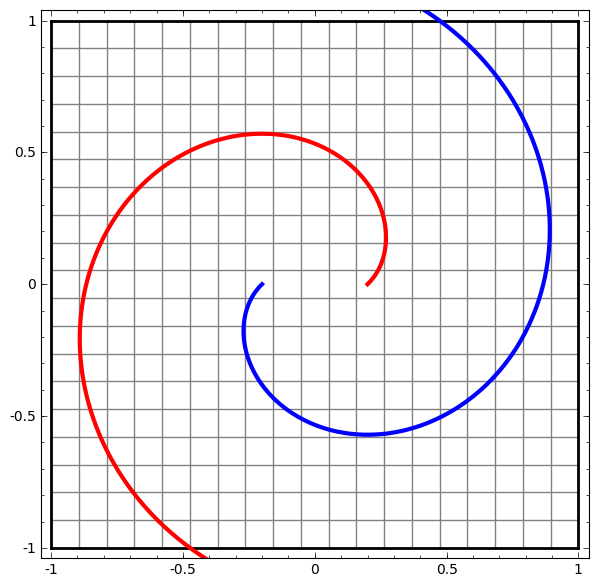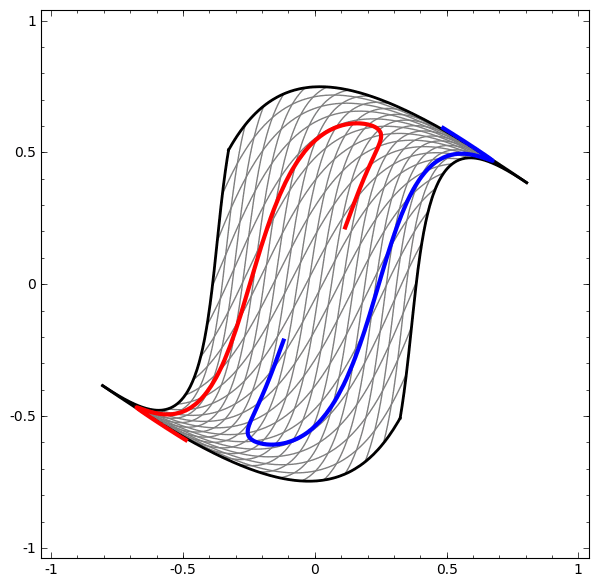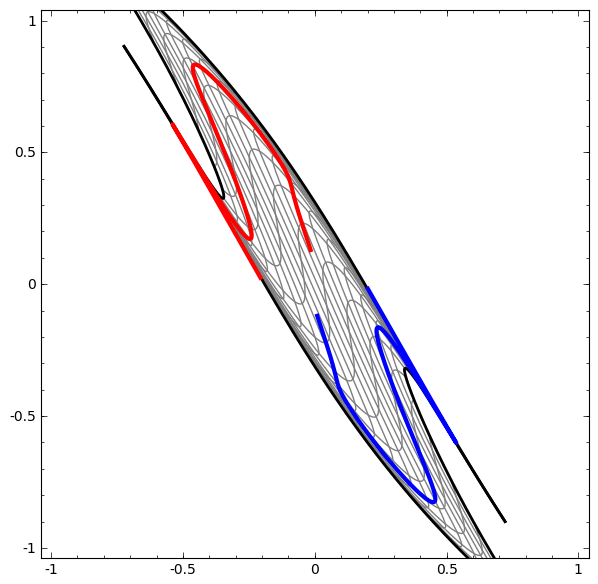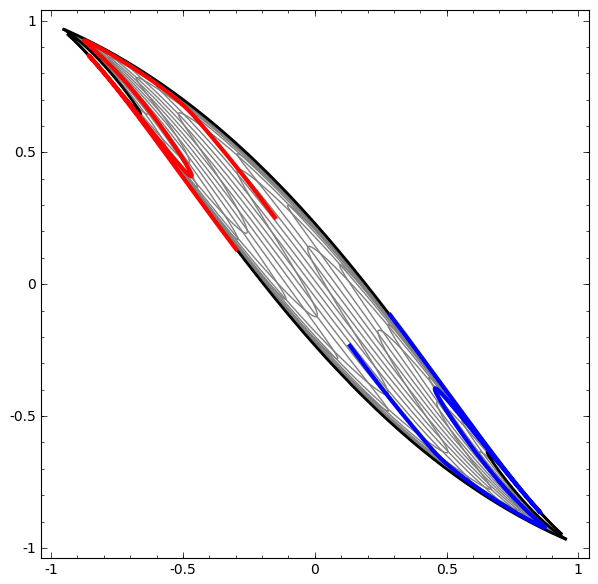
The more complex the dataset, the more hidden layers are required, and the transformation process is likely to fail, making the data more entangled:
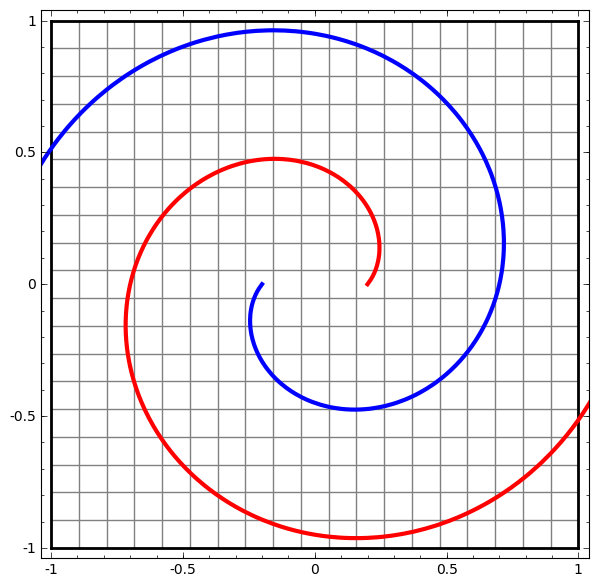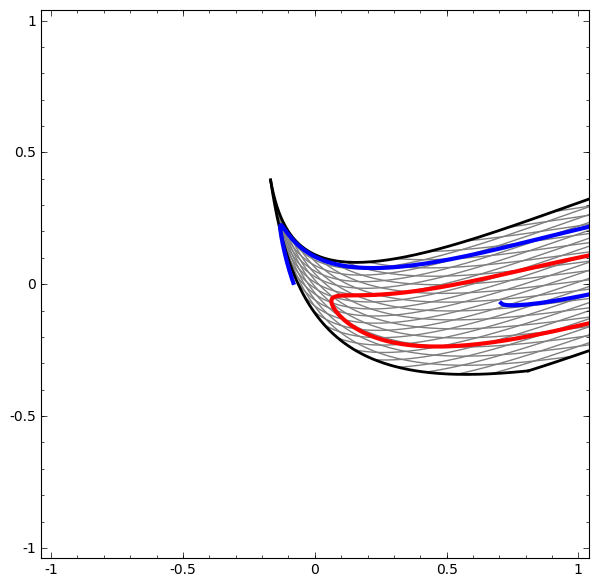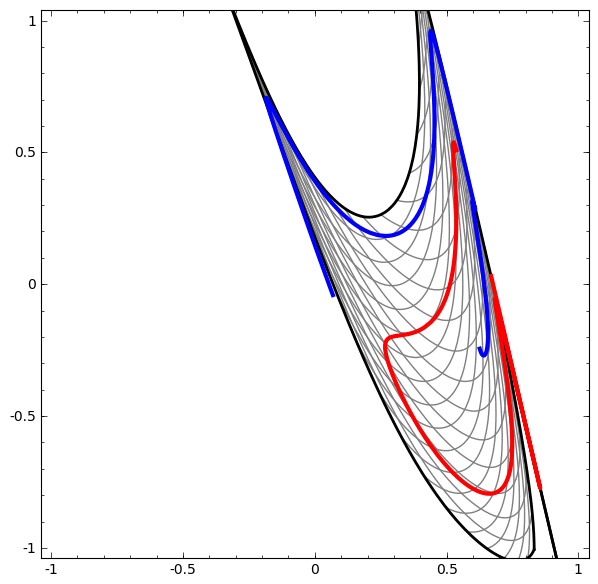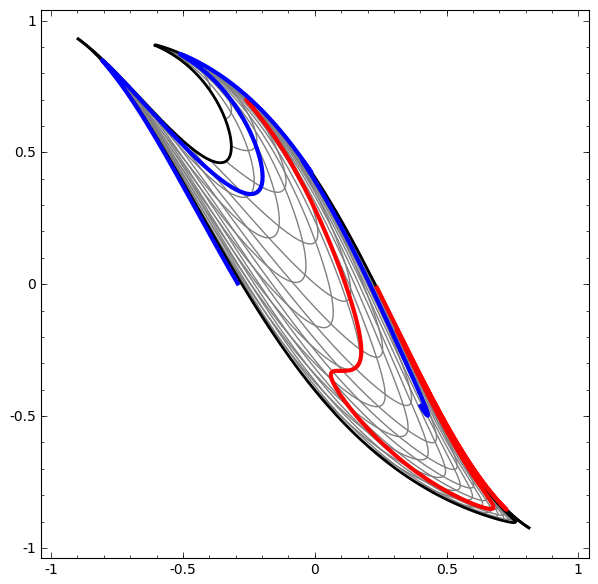
Even if it succeeds, it is still much less efficient compared to gradient boosting trees.
The advantage of deep learning is that it can automatically create hidden features from complex data where humans find it difficult to manually extract features.
Even if you manually create features, deep networks will still create hidden features on their own.
In Kaggle competitions, tabular data often already has features defined, which are the headers, so using gradient boosting directly is sufficient.
As the champion of the Kaggle Avito challenge said: ‘When in doubt, use XGBoost.’

The Data-Hungry Monster
Another highly upvoted reply was:
Most Kaggle competitions’ datasets are not enough to feed a neural network monster.

In small datasets, deep learning is prone to overfitting, and regularization methods depend on many conditions. In competitions with given datasets, gradient boosting is still faster and more stable.
Moreover, deep neural networks with more parameters require more data; since the datasets provided in competitions are limited and have relatively low dimensions, they cannot leverage the strengths of deep learning.
An expert with a good track record on Kaggle added:
Different deep networks are suitable for certain datasets; for example, CNNs are suitable for image processing, while RNNs are suitable for specific sequences. It’s challenging to find suitable pre-trained models for the datasets provided in competitions. Overall, deep learning’s performance on tabular data is definitely better than gradient boosting, but it takes a lot of time to optimize the network architecture. Winning solutions on Kaggle often combine both approaches, and experienced competitors can achieve good results in a few hours.
Reference links: [1] Link 1 [2] Link 2 [3] Link 3
— The End —
This article is original content from NetEase News and the NetEase Account Incentive Program, written by QbitAI. Unauthorized reproduction is prohibited.
Free Registration | NVIDIA CV Open Course
On June 17, NVIDIA experts will demonstrate how to quickly build a gesture recognition system, allowing everyone to learn AI model construction, training, and deployment with low barriers and high efficiency.
P.S. After registering, you can join the group to access a series of CV course live replays, PPTs, and source code!

Click here👇 to follow me, and remember to star it!
One-click three connections: ‘Share’, ‘Like’, and ‘See’
Meet the latest progress in technology every day!