In today’s rapidly advancing field of artificial intelligence, Retrieval-Augmented Generation (RAG) technology has become a hot topic for research and application due to its unique advantages. RAG technology combines the powerful generation capabilities of Large Language Models (LLMs) with efficient information retrieval systems, providing users with a new interactive experience. However, as the technology is applied in depth, challenges have gradually emerged.
Existing RAG systems face dual pressures of efficiency and accuracy when dealing with massive amounts of data. Although LLMs can generate fluent text, they often struggle to accurately grasp and recall key information when faced with complex, unstructured data. Additionally, the limitations of RAG systems in data management and understanding lead to the “Garbage In, Garbage Out” (GIGOut) problem, where the quality of input data is low, resulting in generated answers that also fall short of expected accuracy.
It is against this backdrop that RAGFlow was born.This end-to-end RAG solution aims to address the challenges of existing RAG technology in data processing and answer generation through deep document understanding techniques.RAGFlow not only supports processing of various document formats but also intelligently identifies the structure and content within documents to ensure high-quality data input.Its design philosophy is “High-Quality Input, High-Quality Output”, providing explainable and controllable generation results to build user trust in the answers provided by the system.
On April 1, 2024, RAGFlow officially announced its open-source release, which caused a stir in the tech community. On the day of the open-source release, RAGFlow quickly gained thousands of followers on GitHub, attracting 2,900 stars in less than a week. This not only reflects the community’s high recognition of RAGFlow but also shows the enthusiasm for this new technology.
With the open-sourcing of RAGFlow, it brings new vitality to the tech community and provides new ideas and tools to address the challenges faced by RAG technology. The emergence of RAGFlow marks a solid step forward in building a more intelligent, efficient, and reliable RAG system.
Overview of Core Functions
RAGFlow is based on deep document understanding and can extract key information from various complex formats of unstructured data. It can quickly complete needle-in-a-haystack information extraction, automatically recognizing the layout of documents uploaded by users, including titles, paragraphs, line breaks, and other elements, while also handling complex images and tables. For tables, it not only recognizes their existence but also analyzes their internal layout, including merged cells, and ensures that data is sent to the database in an appropriate format based on header information.
Additionally, RAGFlow provides various text templates for users to choose from, ensuring that results possess controllability and explainability. During document processing, users can select different types of templates, such as Q&A, resumes, papers, etc., with options continuously expanding to better meet user needs.
Reducing hallucinations is one of RAGFlow’s key goals. It allows LLMs to answer questions in a controllable manner and provides users with references at any time, allowing them to view the original text on which the LLM-generated answers are based. This process not only generates links to the original text but also allows users to hover over to view the content of the original text, thus reducing the risk of information hallucinations.
Compatibility is also a major highlight of RAGFlow. It supports various file types, including Word documents, PPT, Excel sheets, PDFs, etc., while performing key information extraction from unordered text data and converting it into structured representations. Ultimately, data from these different sources will be uniformly indexed and retrieved, providing users with a one-stop data processing experience.
Technical Architecture
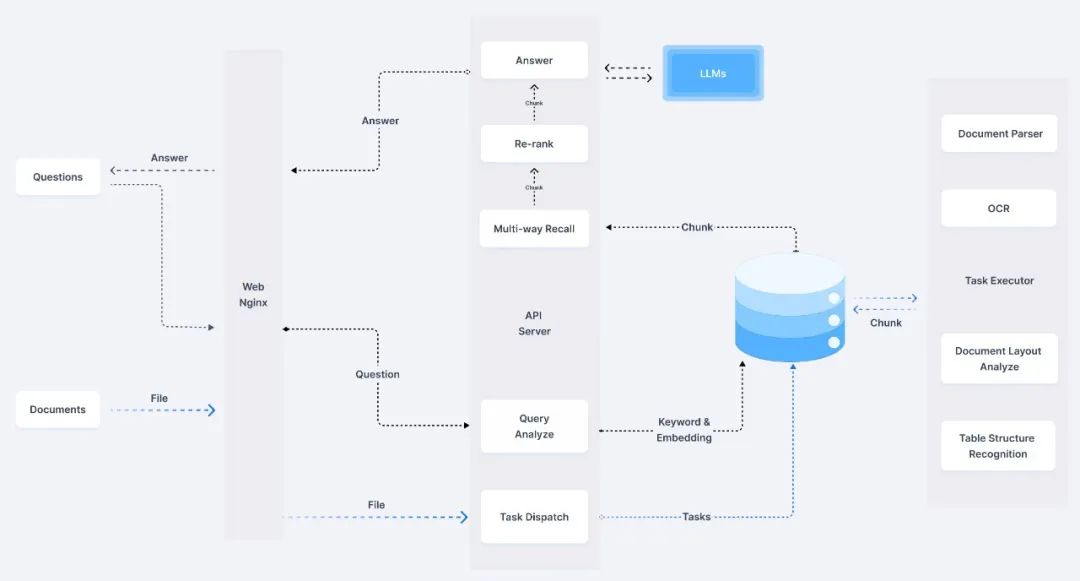
The RAGFlow system is an efficient and intelligent information processing platform that achieves rapid response and precise handling of complex queries through carefully designed components. The document parser serves as the brain of the system, responsible for parsing various formats of documents and extracting key information; the query analyzer deeply analyzes user queries to identify key information, guiding subsequent retrieval; the retrieval module quickly finds relevant information from massive documents, while the re-ranking module ensures that the information presented to users is the most relevant and valuable; finally, the LLM integrates this information and generates natural and fluent answers.
This system architecture ensures that user queries are accurately processed through a series of precise and efficient workflows, thereby enhancing information retrieval efficiency and user experience.
DeepDoc: The Foundation of Deep Understanding
DeepDoc is one of the core components of RAGFlow, utilizing visual information and parsing technology to deeply understand documents and extract information. Its functional modules include OCR technology, layout recognition, and table structure recognition. These functions enable DeepDoc to support various document formats and convert unstructured text into structured data.
LLM and Embedding Models
In RAGFlow, LLMs and embedding models work together to achieve efficient information retrieval and generation tasks. LLMs are responsible for understanding user queries and generating relevant answers, while embedding models convert text data into vector representations for similarity comparison and data retrieval. This collaborative working mechanism greatly enhances RAGFlow’s application potential in knowledge base Q&A and multimodal information processing scenarios.
Visualization and Human Intervention
Finally, RAGFlow emphasizes visualization and explainability in the intelligent document processing process, allowing users to clearly see how documents are chunked and parsed. This design not only increases user trust in AI processing results but also enables users to make necessary adjustments to ensure the final output is accurate and reliable.
If you want to learn how to set up and deploy RAGFlow,
please message us in the backend or directly contact customer service~~