

TrustRAG Project Address🌟: **https://github.com/gomate-community/TrustRAG**
Configurable Modular RAG Framework
Introduction to Chunking
In the RAG (Retrieval-Augmented Generation) task, chunking is a critical step, especially when dealing with complex PDF documents.PDF documents may contain images, strange layouts, etc., which increases the difficulty of chunking.
Impact of Chunk Granularity
-
Sentence/Word Granularity: Focuses on local, key information queries but may miss contextual information. -
Long Paragraph/Article Granularity: The embedding results reflect the overall meaning of the article, but it is difficult to pinpoint individual words.
Chunking Granularity in Different Scenarios
-
Weibo: Few characters, suitable for smaller chunk granularity. -
Zhihu/Xiaohongshu: Medium character count, suitable for medium chunk granularity. -
Blogs: Many characters, suitable for larger chunk granularity. -
Articles with Strong Professionalism and Many Technical Terms: Require smaller chunk granularity to retain professional information. -
Summary Articles: Suitable for larger chunk granularity to retain overall information.
Impact of Chunking on Information
-
Contextual Information: For example, the book “Elements of Statistical Learning” has 18 chapters, each focusing on a theme, with subtitles and second-level subtitles. People tend to understand articles in context. -
Positional Information: The weight of text depends on its position in the document. Text at the beginning and end of the document is more important than text in the middle. -
Continuous Information: A story might start with “in the beginning” and then continue with “then,” “therefore,” “after that,” until concluding with “finally.” Using chunking strategies, this connection may no longer be intact. -
Descriptive Information: With chunking, it may not be guaranteed that descriptive information is kept together.
Questions RAG Tasks Struggle to Answer
-
Narrow Descriptive Questions: For example, which subject has certain characteristics? -
Relational Reasoning: Finding paths from entity A to entity B or identifying groups of entities. -
Long-term Summaries: For example, “List all battles in Harry Potter” or “How many battles did Harry Potter have?”
Factors in Determining the Best Chunking Strategy
-
Nature of Indexed Content: Are you dealing with longer documents (like articles or books) or shorter content (like Weibo or instant messages)? -
Embedding Model Used: For example, the sentence-transformer model works well on single sentences, but models like text-embedding-ada-002 perform better on blocks containing 256 or 512 tokens. -
Length and Complexity of User Queries: Is the user’s question text short and specific, or lengthy and complex? -
How Retrieval Results Are Used: For semantic search, Q&A, summarization, or other purposes? The token limits of the underlying connected LLM also affect the chunk size.
In summary, there is no best chunking strategy, only the suitable chunking strategy. To ensure more accurate query results, it may sometimes be necessary to selectively use several different strategies.
Below is Langchain/Langchain-chatchat, which provides many text splitting tools. The default method used by Langchain is RecursiveCharacterTextSplitter, and there are other chunking methods such as:
-
RecursiveCharacterTextSplitter -
CharacterTextSplitter -
TokenTextSplitter -
MarkdownHeaderTextSplitter -
CodeTextSplitter -
spaCy (TokenTextSplitter variant) -
SentenceTransformersTokenTextSplitter (TokenTextSplitter variant) -
NLTKTextSplitter (TokenTextSplitter variant) -
GPT2TokenizerFast -
AliTextSplitter -
ChineseRecursiveTextSplitter -
ChineseTextSplitter -
zh_title_enhance -
..
How to Determine the Best Chunk Size
Determining the optimal chunk size usually requires A/B testing. Run a series of queries to evaluate quality and compare the performance of different chunk sizes. This is a repetitive testing process, testing different chunk sizes against different queries until the best chunk size is found.
Best Practices
-
Smaller Chunk Sizes: For better results, it is recommended to use smaller chunk sizes. Microsoft’s analysis indicates that smaller chunk sizes help improve performance.

-
Splitting Strategies: When splitting text, different splitting strategies can be chosen. The simplest method is to cut in the middle of words, but you can also try cutting in the middle of sentences or paragraphs. For better results, overlapping adjacent chunks can be beneficial.
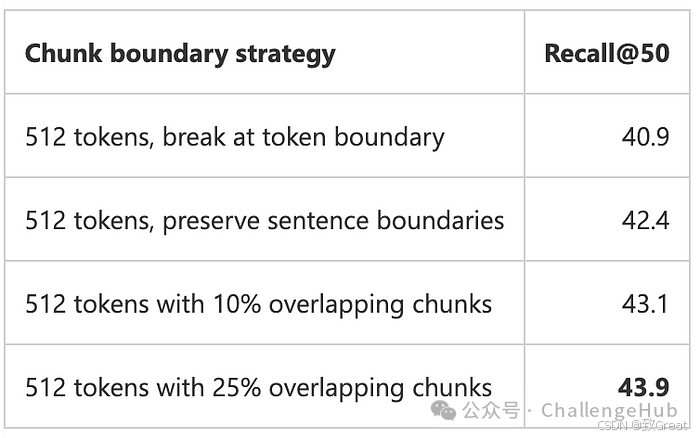
Limitations of Embedding Models
Embedding models are less effective at presenting multi-theme, multi-turn corpora than simple corpora. This is why RAG (Retrieval-Augmented Generation) prefers shorter chunks.
-
Range of Chunk Sizes: In Microsoft’s analysis, the minimum chunk size is 512 tokens. Some enterprise-level RAG applications have chunk sizes as small as 100 tokens. -
Information Loss: Chunking strategies break down text corpora into smaller pieces, leading to information loss. The smaller the data chunks, the more information is lost. Therefore, there is an optimal chunk size; overly small chunks may not be ideal.
Finding the Optimal Chunk Size
Finding the optimal chunk size is like hyperparameter tuning; you must experiment with your data or documents.
Text Overlap for Accuracy Improvement
The Role of Overlap
Overlapping can help link adjacent chunks together and provide better contextual information for the chunks. However, even a very aggressive 25% overlap can only improve accuracy by 1.5%, from 42.4% to 43.9%. This means it is not the most effective method for optimizing RAG performance.
Limitations of Overlap
-
Handling Pronouns: Overlap is effective in handling pronouns. For example, the previous chunk mentions “Xu Beihong is very good at painting horses,” and the next sentence says, “His main technique for painting horses is xxxxx.” Without overlap, the pronoun “he” would lose context. -
Small Chunks Not Applicable: Overlapping chunks may not work for small chunks.
Introduction of Knowledge Graphs
-
Advantages of Knowledge Graphs: With the help of knowledge graphs, RAG can store these relationships in a graph database, allowing connections between chunks to be fully retained. If relational reasoning is crucial to your project, this is a very considerable solution. -
Challenges: Building knowledge graphs from unstructured text is very important. Automatically extracted entities and relationships may contain a lot of noise, ignoring too much real information. The quality of the product must be checked very carefully.
Relational Databases Supporting Vector Search
-
pgvector: Databases like pgvector allow you to store complex information as columns while retaining semantic search capabilities. It is easier to integrate with other enterprise systems than knowledge graphs and is also more flexible.
Custom Chunking
Below is the implementation logic for a sentence chunker in the TrustRAG project:
1. Initialize Sentence Chunker
-
Function: Initialize SentenceChunkerclass, set tokenizer and maximum token count for chunking. -
Logic: -
Call the parent class’s __init__method. -
Set tokenizertorag_tokenizerfor counting tokens in sentences. -
Set chunk_size, default value is 512, indicating the maximum number of tokens per chunk.
2. Split Sentences
-
Function: Splits input text by sentences, supporting both Chinese and English sentence splitting. -
Logic: -
Use regular expression re.compile(r'([。!?.!?])')to match sentence-ending punctuation (Chinese: 。!?; English: .!?). -
Split the text by these punctuation marks to get a list of sentences and punctuation marks. -
Merge punctuation marks with preceding sentences to form complete sentences. -
Handle the last sentence (if it lacks punctuation). -
Remove whitespace from the beginning and end of sentences and filter out empty sentences. -
Return a list containing all sentences.
3. Process Chunks
-
Function: Preprocesses the chunked text, mainly normalizing excessive newlines and spaces. -
Logic: -
Replace four or more consecutive newlines with two newlines. -
Replace four or more consecutive spaces with two spaces. -
Iterate through each chunk and process newlines and spaces: -
Return a list of processed chunks.
4. Paragraph Chunking
-
Function: Chunks a list of input paragraphs, ensuring that each chunk’s token count does not exceed chunk_size. -
Logic: -
If the current chunk’s token count plus the current sentence’s token count does not exceed chunk_size, add the sentence to the current chunk. -
Otherwise, add the current chunk to chunkslist and start a new chunk. -
Merge the list of paragraphs into a complete text. -
Use split_sentencesmethod to split the text into a list of sentences. -
If no sentences are found, treat the paragraphs as sentences. -
Initialize chunkslist andcurrent_chunklist to store the current chunk’s sentences and token count. -
Iterate through the list of sentences, calculating the token count for each sentence: -
Process the last chunk (if it contains sentences). -
Use process_text_chunksmethod to preprocess the chunks. -
Return the final list of chunks.
Complete code is as follows:
import re
from trustrag.modules.document import rag_tokenizer
from trustrag.modules.chunks.base import BaseChunker
class SentenceChunker(BaseChunker):
"""
A class for splitting text into chunks based on sentences, ensuring each chunk does not exceed a specified token size.
This class is designed to handle both Chinese and English text, splitting it into sentences using punctuation marks.
It then groups these sentences into chunks, ensuring that the total number of tokens in each chunk does not exceed
the specified `chunk_size`. The class also provides methods to preprocess the text chunks by normalizing excessive
newlines and spaces.
Attributes:
tokenizer (callable): A tokenizer function used to count tokens in sentences.
chunk_size (int): The maximum number of tokens allowed per chunk.
Methods:
split_sentences(text: str) -> list[str]:
Splits the input text into sentences based on Chinese and English punctuation marks.
process_text_chunks(chunks: list[str]) -> list[str]:
Preprocesses text chunks by normalizing excessive newlines and spaces.
get_chunks(paragraphs: list[str]) -> list[str]:
Splits a list of paragraphs into chunks based on a specified token size.
"""
def __init__(self, chunk_size=512):
"""
Initializes the SentenceChunker with a tokenizer and a specified chunk size.
Args:
chunk_size (int, optional): The maximum number of tokens allowed per chunk. Defaults to 512.
"""
super().__init__()
self.tokenizer = rag_tokenizer
self.chunk_size = chunk_size
def split_sentences(self, text: str) -> list[str]:
"""
Splits the input text into sentences based on Chinese and English punctuation marks.
Args:
text (str): The input text to be split into sentences.
Returns:
list[str]: A list of sentences extracted from the input text.
"""
# Use regex to split text by sentence-ending punctuation marks
sentence_endings = re.compile(r'([。!?.!?])')
sentences = sentence_endings.split(text)
# Merge punctuation marks with their preceding sentences
result = []
for i in range(0, len(sentences) - 1, 2):
if sentences[i]:
result.append(sentences[i] + sentences[i + 1])
# Handle the last sentence if it lacks punctuation
if sentences[-1]:
result.append(sentences[-1])
# Remove whitespace and filter out empty sentences
result = [sentence.strip() for sentence in result if sentence.strip()]
return result
def process_text_chunks(self, chunks: list[str]) -> list[str]:
"""
Preprocesses text chunks by normalizing excessive newlines and spaces.
Args:
chunks (list[str]): A list of text chunks to be processed.
Returns:
list[str]: A list of processed text chunks with normalized formatting.
"""
processed_chunks = []
for chunk in chunks:
# Normalize four or more consecutive newlines
while '\n\n\n\n' in chunk:
chunk = chunk.replace('\n\n\n\n', '\n\n')
# Normalize four or more consecutive spaces
while ' ' in chunk:
chunk = chunk.replace(' ', ' ')
processed_chunks.append(chunk)
return processed_chunks
def get_chunks(self, paragraphs: list[str]) -> list[str]:
"""
Splits a list of paragraphs into chunks based on a specified token size.
Args:
paragraphs (list[str]|str): A list of paragraphs to be chunked.
Returns:
list[str]: A list of text chunks, each containing sentences that fit within the token limit.
"""
# Combine paragraphs into a single text
text = ''.join(paragraphs)
# Split the text into sentences
sentences = self.split_sentences(text)
# If no sentences are found, treat paragraphs as sentences
if len(sentences) == 0:
sentences = paragraphs
chunks = []
current_chunk = []
current_chunk_tokens = 0
# Iterate through sentences and build chunks based on token count
for sentence in sentences:
tokens = self.tokenizer.tokenize(sentence)
if current_chunk_tokens + len(tokens) <= self.chunk_size:
# Add sentence to the current chunk if it fits
current_chunk.append(sentence)
current_chunk_tokens += len(tokens)
else:
# Finalize the current chunk and start a new one
chunks.append(''.join(current_chunk))
current_chunk = [sentence]
current_chunk_tokens = len(tokens)
# Add the last chunk if it contains any sentences
if current_chunk:
chunks.append(''.join(current_chunk))
# Preprocess the chunks to normalize formatting
chunks = self.process_text_chunks(chunks)
return chunks
if __name__ == '__main__':
with open("../../../data/docs/news.txt","r",encoding="utf-8") as f:
content=f.read()
tc=SentenceChunker(chunk_size=128)
chunks = tc.get_chunks([content])
for chunk in chunks:
print(f"Chunk Content:\n{chunk}")
Output as follows:
Chunk Content:The Chief of the South Korean President's Security Service Resigns
#The Chief of the South Korean President's Security Service Resigns# Update: The Chief of the South Korean President's Security Service, Park Jong-jun, submitted his resignation to Acting President Choi Sang-mook today (January 10) before arriving to be investigated. #The Chief of the South Korean President's Security Service Arrives for Investigation# This morning, Park Jong-jun arrived at the National Investigation Headquarters of the South Korean Police Agency to undergo police investigation. Before the investigation, he told reporters on the scene that there are legal disputes regarding the arrest warrant for suspended President Yoon Suk-yeol, and the investigation procedure for Yoon Suk-yeol should comply with the presidential identity, rather than being conducted in the form of an arrest warrant. Chunk Content: He also stated that there should not be bloodshed among government agencies. The South Korean High-ranking Public Officials Crime Investigation Agency (Gongdiao Agency) organized personnel on January 3 to go to the presidential residence in Hannam-dong, Yongsan District, Seoul, to make an arrest, but faced resistance from the Presidential Security Service. After more than five hours of confrontation, the Gongdiao Agency announced the failure of the arrest operation. The South Korean "Joint Investigation Headquarters" has filed a case against Park Jong-jun on suspicion of obstructing the execution of special duties, requiring him to arrive for investigation. Park Jong-jun had previously refused to appear for police investigation twice. (Reporter Zhang Yun)References
-
Langchain – Let Langchain Talk to Your Data (Part 1): Data Loading and Splitting -
LangChain Token Splitting Text Content -
Chunking Strategies for LLM Applications | Pinecone -
Issues and Improvements Found in RAG Industry Communication -
The Most Detailed Text Chunking Methods, Directly Affecting LLM Application Effects -
Summary of RAG Chunking Technology Advantages, Disadvantages, Skills, and Methods (Part 5)
To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2) Please specify the specific direction + related technical points
About AINLP
AINLP is an interesting AI natural language processing community focused on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, job experience sharing, etc. Welcome to pay attention! To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2), specifying work/research direction + purpose of joining the group.
