Once upon a time, image recognition technology seemed like a strange term, but now it is increasingly integrated into people’s lives. A classic application in recent years is the image recognition feature launched by Google and Baidu, which many of you have likely experienced; facial recognition, which has been a hot topic among IT colleagues, is also a prime example of image recognition applications. Of course, in our daily lives, we can’t ignore image recognition in online shopping; just take a picture of the item you want to buy on the Taobao APP, and it will immediately search for the types and prices of that item.
But how are these amazing functions actually realized? What deeper interactions will image recognition have with our lives in the future, and what is its relationship with big data? Let me explore this with you.
A digital image (also known as a digital image or pixel image) is a two-dimensional image represented by a limited number of numerical pixel values. The process of recognizing a digital image generally involves the following steps: Information acquisition image collection -> Image preprocessing (such as binarization, color inversion, etc.) to obtain feature data -> Training process (involving classifiers and classification decisions) -> Recognition. Since both digital images and text/numbers are based on pixels as basic elements, and the basic process of digital image recognition is similar to that of digital recognition, I will briefly explain the recognition process using the more basic digit recognition in image recognition technology.
First, let me introduce some basic concepts that will be used later:
1
Pattern Recognition
Currently, the application scope of pattern recognition is very broad, encompassing external information that human senses receive directly or indirectly. The purpose of using pattern recognition is to utilize computers to mimic human recognition capabilities to identify the observed objects. Pattern recognition methods can be roughly divided into two types: structural methods and decision-theoretic methods, with the latter also known as statistical methods. Character pattern recognition methods can be roughly classified into statistical pattern recognition, structural pattern recognition, and artificial neural networks. The aforementioned steps in image recognition are the basic steps of pattern recognition.
One of the commonly used pattern recognition methods is template matching, which, as the name suggests, involves continuously cutting out temporary images from the input image and matching them with template images. If the similarity is sufficiently high, it is considered that we have found the target we are looking for. The most common matching methods include squared difference matching, correlation matching, and correlation coefficient matching. Below, we will use template matching as an example to illustrate the concept of model recognition.
2
Support Vector Machine (SVM)
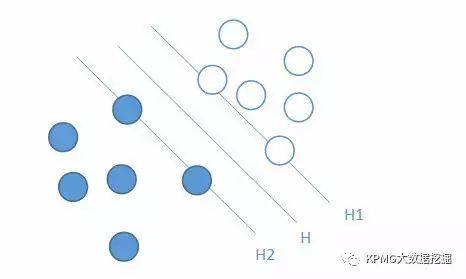
Support Vector Machine is a general machine learning method that can be trained and is based on the principle of structural risk minimization; in simple terms, it is a classifier. The principle of the SVM method can be simply described as a process of linearization and dimensionality increase. SVM is developed from the optimal classification hyperplane in the case of linear separability. As shown in the figure below, hollow points and solid points represent two classes of samples, H is the H-dimensional classification hyperplane, and HI and H2 are hyperplanes that pass through the respective class points and are closest to the classification hyperplane and parallel to H. The optimal classification hyperplane theory requires that the classification hyperplane maximizes the margin while correctly separating the two classes.
3
OpenCV
OpenCV is a cross-platform computer vision library licensed under the BSD license. Compared to other function libraries, it is dedicated to real-world real-time applications. Additionally, its execution speed has been objectively improved through optimized C code.
4
LIBSVM
LIBSVM is a simple and easy-to-use SVM pattern recognition and regression software package. The package includes folders such as python, svmtoy, and tools such as SVM-predict, svm-scale, and svm-train.
Firstly, I used the OpenCV library to read image data from the original image library and stored the feature values in an external .txt document. Then, I preprocessed the data and formed the training data; next, I optimized parameters for the preprocessed data and trained the model. After extracting feature data from the test images, I input the feature data into the model for prediction and obtained the recognition rate prediction value. Finally, I analyzed the recognition rate situation.
Here are my practical steps:
I hand-drew ten digits from 0 to 9, with ten samples for each digit, totaling 100 samples. Each sample is a 5*5 template. I implemented code to obtain the feature information of the handwritten digit images.
After obtaining the feature data, certain preprocessing is required to ensure the normal operation of subsequent tasks. This time, we chose normalization processing, implemented with svm-scale. The purpose of normalization is to ensure that the extracted data is within a certain range, avoiding excessively large or small situations, thereby providing assurance for model training.
Additionally, parameter optimization was also utilized during the process, aiming to provide good parameters for model training to achieve a higher accuracy model. The following image is a screenshot of the parameter optimization operation.
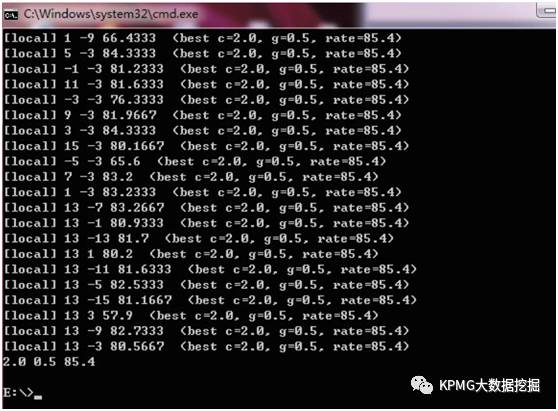
The last row in the image shows the best parameters. Typically, we would use several correct models to extract feature values as the result of parameter optimization; thereafter, all prediction tasks should use the optimal values found as benchmarks for prediction, and those that meet these feature values will be successfully recognized.
Model training involves classifying the sample feature data extracted earlier into the LIBSVM classifier, based on the labels of each group of feature values. The SVM machine learning method is based on statistical theory, so a large amount of data will yield a more accurate model file.
Practical Results:
I conducted several simple experiments.
❶ Using the same training set and test samples, I compared the recognition methods based on template matching and SVM to observe the impact of data dimensions on recognition accuracy.

Cause Analysis: The template matching method uses the feature extraction method of the network to count the number of black pixels in each region and calculates the percentage of each region in the overall area; while SVM conducts statistical analysis based on the coordinates of each pixel point. Additionally, higher dimensions enable more precise coordinate positioning, giving SVM a significant advantage.
Conclusion: Under the premise of the same test samples and dimensions, the model trained using the SVM method achieved higher accuracy than the template matching method when predicting under 16 and 25 dimensions.
❷ Using the SVM method, I compared the accuracy under different dimensions with the same training and test samples. The training samples totaled 500, with 100 test samples.

Conclusion:For the same samples, using the SVM method for model prediction showed that the height of dimensions positively affects accuracy, but accuracy does not infinitely increase with higher dimensions.
❸ For the same test samples, I analyzed the impact of the number of training samples on accuracy under the same dimensions.

Cause Analysis: Since SVM’s image recognition is based on statistical theory, a large number of training samples helps achieve a more accurate training model, positively influencing the prediction accuracy of model training.
Image recognition is closely related to big data. Some predecessors have pointed out that data mining = big data + machine learning; some experts believe that pattern recognition = data + machine learning. Big data is a contemporary concept and an inevitable product of social development. We achieve our ultimate goal through big data technology—data mining. Undoubtedly, “images” are also a form of data, and image recognition is a necessary process for structuring unstructured data.
Image recognition technology is increasingly popular, updating new technologies and achievements at a rocket-like speed every year, and it is not limited to image processing and shopping. Nowadays, image recognition technology has evolved from searching for images to the video domain, constantly bringing us surprises. For example, the emerging interactive video technology video++, can now capture faces and similar clothing to be recognized in videos. Technology is the primary productive force, and in the 21st century, one of the hottest technologies is artificial intelligence; however, image recognition technology is at the core of artificial intelligence, and its development will undoubtedly drive the rapid growth of artificial intelligence. The future is here; are you ready?
References: Zeng Zhiqiang, Research on Training and Simplification Algorithms of Support Vector Classification [D] Zhejiang: Zhejiang University 2007.6,29.
After reading this article, feel free to leave a comment at the end to share your thoughts with us.