You can “listen” to this article anytime on your mobile phone or computer Edge browser.
Key Points:
Generative AI, based on predictive models, can accurately perceive numbers, possess absolute mathematical knowledge and undeniable logic, and tirelessly reason to derive the best or optimal output based on current prompts.
The tight connection between logic and the construction of knowledge and intent—generating expressions that conform to “logic” in countless inferences, such as concepts and causality—makes it easy for us to explain to others and also benefits ourselves. However, logic cannot reveal the true nature of things nor explain our common sense about the world. For example, in the world on Earth, we cannot find two identical leaves, two identical stones, let alone two identical intelligent organisms.
Human common sense operates effectively not because it conforms to the logic of thought but rather the logic of neurons. Generative AI possesses logic but lacks common sense. In this regard, many “articulate” autistic children seem somewhat similar in certain situations.
Neural Logic of Autism Intervention [Excerpt, Fragment]
2023-05-07

If in the future, we can create artificial neural networks that can self-reflect and think using their generated data, self-verify facts, and do not need to access all knowledge, then AI will start to resemble human intelligence.
If we further integrate possible robotic technologies such as vision, touch, hearing, smell, taste, and proprioception, and establish data architectures and algorithms that can integrate these multisensory information, it will enable AI to generate a more universal perception and understanding of the world, bringing us closer to General Artificial Intelligence (AGI).
The only instance that research on AGI can refer to—the human brain—is a product of human evolution, and it does not care whether it can be understood by itself. Even the aspects of the human brain that modern neuroscience has identified are far more complex than any of us can realize.
It is worth noting that, to date, AGI still lacks a definite, recognized definition—regarding this, the definition of “intelligence”—a more general concept is also vague.
Nevertheless, generative AI is destined to have a profound impact and change on certain professions and industries. Besides conversational AI services, this technology is being embedded in more industries and services. In this ecosystem’s three layers—hardware layer, infrastructure layer, foundational models, and application layer—there will be winners and new emergences.
This article was not generated by any form of generative AI.
We have already created artificial intelligence (AI) that can perform certain tasks of human intelligence. And we hope that one day, we can create General Artificial Intelligence (AGI), or strong AI, that can learn and complete any intelligent task that humans can do, even surpassing human intelligence to become superintelligence. Currently, this seems difficult because today’s AI is merely a predictive model based on existing data, used to observe and classify patterns in data.
The family of Generative AI is hailed as the first ray of light on the horizon of AGI; they are all based on artificial neural networks (ANN) with a Transformer architecture, controlled by a few resource-rich tech giants, such as Microsoft’s significant investment in OpenAI’s GPT-4, Google’s PaLM-2, and Meta’s LLaMA.
Generative AI can be used to generate new content based on prompts, including text, images, audio, video, code, simulations, and more. Among them, conversational AI models like OpenAI’s ChatGPT and Google’s Bard, powered by large language models (LLMs), are trained and fine-tuned through vast text or code corpora and can be accessed and used via APIs or platforms.
The model consists of two main modules: the encoder and the decoder. When receiving natural language or code queries, i.e., prompts, the encoder processes the input text and converts it into a series of vectors called embeddings, representing the meaning and context of each word. The length of the vectors is a parameter specified by the encoder, not manually specified. Parameters are obtained through training and learning. Based on the embeddings and preceding words, the decoder generates output text by predicting the next word in the sequence.The model’s built-in self-attention mechanism focuses on the most relevant parts of the input and output texts, capturing long-range dependencies and relationships between words.
The model is trained using a large corpus of text as input and output, minimizing the difference between predicted and actual words. The model can be fine-tuned or adjusted using smaller, more specialized datasets to fit specific tasks or domains. Complex mathematical techniques help the decoder estimate several different outputs and predict the most accurate or optimal output. During training, optimization algorithms are used to learn or update parameters, attempting to minimize the error or loss between predictions and actual outputs. By adjusting parameters, the model’s performance and accuracy can be improved for a given task or domain.

The quality of output obtained by users from conversational AI services and the costs incurred (if any), such as with ChatGPT, are determined by the prompt and optional parameters (such as temperature, top-p, frequency penalty, etc.), and users need to go through trial and error and learning to get the service they want. Because conversational AI services do not possess mind-reading capabilities, they require clear and specific instructions to understand what you want them to do. By understanding the complexity of generative AI behavior and using the best practices, one can maximize its utility to generate code, draft marketing plans, write emails, and more.
Current AI is rooted in one hypothesis: human intelligence is a generalized predictive model about objects in the world.
This seems quite correct; for instance, in war, economic activities, daily life, entertainment, creation, interpersonal interactions, driving, or walking, we instinctively make predictions everywhere. Thus, the brain is considered a predictive organ [Note that the concept of “prediction” here differs from the predictive coding theory of consciousness, which is beyond the scope of this article].
It is generally believed that the predictive model of human intelligence possesses a generalized knowledge of the world that is automatically acquired by individuals, also known as common sense. For example, infants understand that a ball that is blocked by a barrier is still there; they will pay more attention to a larger ball rolling down a slope compared to a smaller one; if you manipulate the ball to roll up the slope, they will watch in surprise. Infants react differently to hearing “pseudowords” compared to “nonwords,” indicating that even with very limited exposure to language, they can learn the probabilistic relationships between syllables; that is, infants learn which syllables always occur in pairs and which syllables rarely occur together. For instance, if we show children several pictures of cats, they will eventually recognize any cat they see. Children affected by autism lack these and similar common sense abilities.
 This common-sense ability is taken for granted in humans, but it has always been an open challenge in AI research. How can we enable machines to do the same thing?
The field of AI research has given rise to machine learning, one of which is called deep learning, based on deep neural networks (DNN) with representation learning capabilities, which is an artificial neural network with multiple layers between the input and output layers. Representation learning allows systems to automatically discover representations necessary for detecting or classifying features from raw data. Representation learning exists because tasks in machine learning, such as classification, typically require inputs that are mathematically and computationally manageable. However, real-world data like images, sounds, videos, and sensor data do not fully yield to attempts to define specific features through algorithms.
Machine learning is typically divided into three main learning paradigms: supervised, semi-supervised, or unsupervised (also known as self-supervised).
This common-sense ability is taken for granted in humans, but it has always been an open challenge in AI research. How can we enable machines to do the same thing?
The field of AI research has given rise to machine learning, one of which is called deep learning, based on deep neural networks (DNN) with representation learning capabilities, which is an artificial neural network with multiple layers between the input and output layers. Representation learning allows systems to automatically discover representations necessary for detecting or classifying features from raw data. Representation learning exists because tasks in machine learning, such as classification, typically require inputs that are mathematically and computationally manageable. However, real-world data like images, sounds, videos, and sensor data do not fully yield to attempts to define specific features through algorithms.
Machine learning is typically divided into three main learning paradigms: supervised, semi-supervised, or unsupervised (also known as self-supervised).
In the past decade, machine learning has become a key method, arguably the most important method, especially deep learning. Most of the progress in AI today involves machine learning, which is why some people equate AI with machine learning almost entirely.
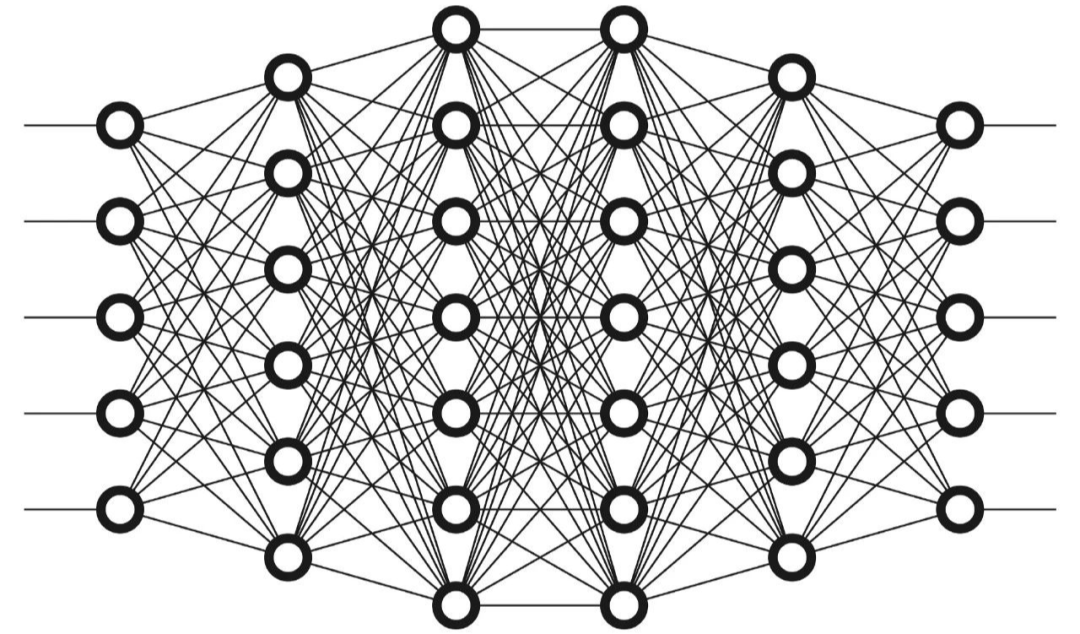
Artificial neural networks, commonly referred to as neural networks, are computational systems inspired by the neural networks of the brain. Initially, they attempted to use the structure of the human brain to perform tasks that traditional algorithms could hardly accomplish, but soon abandoned attempts to remain faithful to biological precursors. Artificial neural networks learn or train by processing instances and modeling nonlinear and complex relationships. This is achieved through artificial neurons connected in different patterns, allowing the output of some artificial neurons to become input for other artificial neurons. The network forms a directed, weighted graph.
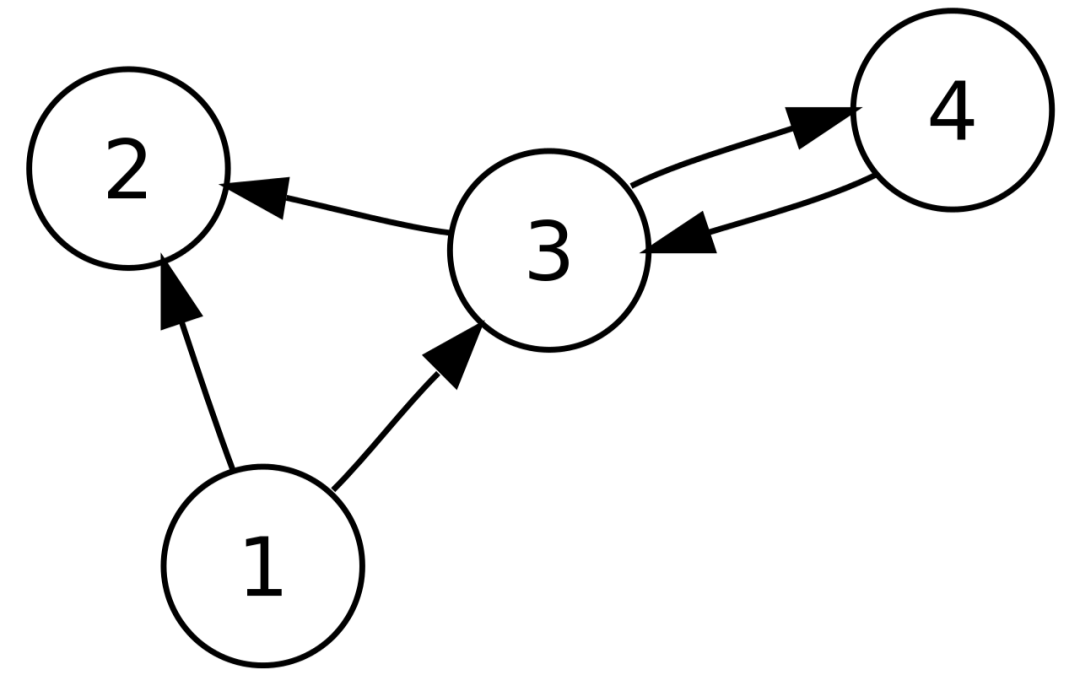
Machine learning, neural networks, and deep learning are all subfields of artificial intelligence. However, neural networks are actually a subfield of machine learning, and deep learning is a subfield of neural networks.
Not at All Like Human Intelligence
It is more accurate to view modern AI technology, primarily based on machine learning, as a powerful statistical inference device. To enable it to do something, scientists must first train it with all the knowledge. The model infers the most accurate or optimal output based on the long-range dependencies and relationships between words obtained from training.
Currently, well-known large language models are autoregressive, self-supervised, pre-trained, densely activated transformer-based models. It is certain that there are differences among these models: their sizes (number of parameters), the data they are trained on, the optimization algorithms used, batch sizes, the number of hidden layers, whether they have undergone instruction fine-tuning, etc. These variations can translate into meaningful performance differences. However, the core architecture remains largely unchanged.
Each time the model runs, every one of its parameters is used. For example, whenever you submit a prompt to ChatGPT powered by GPT-3, all 175 billion parameters of the model are activated to generate a response.
Footnote:
In large language models (LLMs) like GPT-3 or 4 or other transformer-based models, the term “parameters” refers to the numerical values that determine the behavior of the model. These parameters include weights and biases, which together define the connections and activations of artificial neurons in the model.Regardless of how good your model is, for instance, GPT-3 has 175 billion parameters (requiring 700GB to store) and used 499 billion tokens (45TB) of weighted pre-training datasets, it can only be as good as the data you provide.
However, our human thinking transcends sensations, whether as a detailed exposition of sensory materials or as an understanding of objects that are entirely beyond the scope of sensation.
We collect information externally through observation (i.e., social learning), self-practice (i.e., experiential learning), being taught (i.e., classroom learning), and reading (i.e., self-learning), such as skills, knowledge, and viewpoints, but we also deepen our understanding of the world through self-reflection and thought, thereby “emerging” entirely new ideas and insights, rather than relying solely on external inputs. We can also solve entirely new problems through analysis, comparison, abstraction, and reasoning without external input.
While AI companies have made significant claims about their respective AI powered by large language models and their “emergent” behaviors or showing early signs of AGI. For instance, earlier this year, a research team at Microsoft claimed that an early version of GPT-4 showed “sparks” of AGI. Then, a Google executive claimed that the company’s Bard chatbot miraculously learned to translate Bengali without the necessary training. However, a group of scientists from Stanford University explained the “emergent” capabilities displayed by large language models as follows: for fixed tasks and fixed model families, researchers can choose a metric to create emergent capabilities or choose a metric to eliminate emergent capabilities. Therefore, emergent capabilities may be a product of researchers’ choices rather than a fundamental property of the model family on specific tasks. Specifically, nonlinear or discontinuous metrics produce significant emergent capabilities, while linear or continuous metrics yield smooth, continuous, predictable changes in model performance. Any seemingly emergent capability of LLMs is merely an “illusion” produced by inherent defect metrics. In other words, when you use unpredictable metrics, you get unpredictable results.
For a long time, various disciplines from philosophy to physics, mathematics, and then to biology and neuroscience have been studying the emergent properties of complex systems. The concept of “emergence” was popularized by Nobel laureate P.W. Anderson in his 1972 article “More is Different: Broken Symmetry and the Nature of Science’s Hierarchies” published in Science. This theory posits that as the complexity of a system increases, new properties that cannot be predicted even with precise quantitative understanding of the system’s microscopic details may emerge.
Fairly speaking, this phenomenon can at least be partly attributed to some AI scientists seeing what they want to see in their machines. After all, if your technology has developed an “emergent” property, it is very tempting. For this reason, whether these “emergent” properties exist or not is not just exciting but also brings some worrying consequences—once a machine exhibits even one “emergent” property, does it mean we have officially lost control? All of this, including excitement and fear, undoubtedly attracts attention and triggers financial speculation around the technology—this means that claiming “sparks” of AGI through “emergent” properties is not entirely a bad thing for marketing purposes.

On February 24, OpenAI CEO Sam Altman wrote in his blog: “Our mission is to ensure that General Artificial Intelligence (AGI)—intelligent systems smarter than humans—benefits all of humanity. If AGI is successfully created, this technology can help us enhance humanity by increasing wealth, turbocharging the global economy, and aiding in the discovery of new scientific knowledge that changes the limits of possibilities. AGI has the potential to empower everyone with incredible new capabilities; we can imagine a world where all of us can receive assistance in almost all cognitive tasks, providing a tremendous multiplier for human intelligence and creativity. On the other hand, AGI also poses serious risks of misuse, severe accidents, and social chaos. Given AGI’s immense advantages, we do not believe it is possible or desirable for society to stop its development forever; rather, society and AGI developers must find ways to do it right.” After reading Sam Altman’s statement, how do you feel?
The plasticity of brain neurons allows us to generate entirely new information in our brains that has never appeared before in our minds and the external world through introspection, writing, and communication, sometimes just a dream (N1 sleep stage), changing the way neurons are connected in the brain, thus affecting and changing the external world; the changing external world, in turn, promotes the adaptive behaviors and evolution of human intelligence.
The best models will only know the relationships between words and will not know the meanings of words or sentences in the real world. Additionally, a large number of parameters do not equate to modeling the world more “accurately or optimally,” as they may “overfit” the signals received, which could be noise, but may also be meaningful signals with random fluctuations.
Despite the impressive progress made so far, scientists have a limited understanding of how the tools they create operate between input and output. That is to say, even when the system is working, scientists often do not know why. When a system does not work, scientists cannot identify and correct the problem. Overall, current deep neural networks are inexplicable “black boxes.” This may limit their usefulness in the real world, especially in high-risk environments like healthcare, where human oversight is crucial.
Most LLMs at this stage are trained on indiscriminate combinations of web text, rarely considering differences in reliability of sources. They treat articles published in the New England Journal of Medicine and those discussed on Reddit as equally authoritative. LLMs tend to generate factually incorrect outputs—referred to as hallucinations. The outputs of LLMs are constantly changing and fleeting. Because they generate text using probabilistic processes, making the same query multiple times may yield different responses. LLMs may also return different results based on the date and wording of the query. As a matter of proof, unless a doctor records the queries and outputs, it will be challenging to justify the reasonableness or unreasonableness of taking action based on the model’s output.
To achieve General Artificial Intelligence, scientists tend to use the only instance of general intelligence—the human brain—as a template, leading modern AI to be frequently described as functioning like the human brain.
In fact, AI is not like our brains in any way, at least not at present.
AI is on the path of “reducing” consciousness, exhausting the parameters used for predictions through massive data and supercomputing power, such as GPT-3 with 175 billion parameters and a training dataset of 499 billion tokens. However, the content of human consciousness is abstract, emergent, and irreducible!
Based on predictive models, generative AI can accurately perceive numbers, possess absolute mathematical knowledge and undeniable logic, tirelessly reasoning to derive the best or optimal answers based on current prompts.
Logic builds a close connection between knowledge and intent—generating expressions that conform to “logic” in countless inferences, such as concepts and causality, making it easy for us to explain to others and also benefiting ourselves. However, logic neither reveals the true nature of things nor explains our common sense about the world. For instance, in the world on Earth, we cannot find two identical leaves, two identical stones, let alone two identical intelligent organisms.
The human brain is not merely a predictive organ; human minds are not limited to predictive functions; human behaviors do not follow predetermined actions based on predictions. Because the world we rely on for survival is a random, chaotic world.
Humans pursue “satisfaction,” not absolute optimality. Two distinct cognitive processing modes: 1) the rapid, automated “habitual” responses in the vast majority of cases, and 2) the slow, effortful, thoughtful considerations in rare cases, promote human adaptive behaviors, social prosperity, and cultural diversity rather than behaviors derived from complex mathematical deductions of the “most accurate or optimal” actions.
Humans’ spontaneous responses to “survival” and “reproduction” give rise to our desire to explore and understand three realms that seem to encompass all cognition. Thus, we generate uniquely human minds encompassing experiences (categorization, conceptualization), learning, thinking, adaptive behaviors, planning and intentions, desires and beliefs, expressing opinions and viewpoints, as well as creativity and creation.
The first realm of these three is understanding the non-social environment, composed of inanimate objects and non-human living beings; the second realm is understanding our own feelings and thoughts; the third realm is understanding the feelings and thoughts of others. The differences in people’s understanding of these three realms ultimately reflect the differences in their social functions, as we humans can no longer return to the wilderness today. The deficiencies in understanding these three realms, varying in latitude and degree, are diagnosed as different neurodevelopmental disorders or mental disorders, such as autism. One extreme of the autism spectrum consists of children whose abilities to understand all three realms are impaired, while the other extreme consists of children whose ability to understand the third realm is impaired. Children distributed within these extremes are all different. Some children have a better understanding of the first realm than neurotypical peers of the same age.
Of course, I must admit that we instinctively retain recognition, longing, and imagination of superhuman power and intelligence! For instance, General Artificial Intelligence (AGI). Because a significant part of our minds is something we are unwilling or find it difficult to face, viewed as weak and irrational, which is emotion. And it is precisely emotions that make us live like humans and allow us to contemplate our longings and imaginations.
Thinking is an unlimited output based on limited language.
Commonly used Chinese characters are 3,500, but we have created countless thoughts, theories, and works. We do not first learn all knowledge to create certain thoughts, theories, or works, but rather become experts in a particular field.

If in the future, we can create artificial neural networks that can self-reflect and think using their generated data, self-verify facts, and do not need to access all knowledge, we would consider AI to start resembling human intelligence.
If we further integrate possible robotic technologies such as vision, touch, hearing, smell, taste, and proprioception, and establish data architectures and algorithms that can integrate these multisensory information, it will enable AI to generate a more universal perception and understanding of the world, bringing us closer to General Artificial Intelligence (AGI).
It is worth noting that, to date, AGI still lacks a definite, recognized definition—regarding this, the definition of “intelligence”—a more general concept is also vague.
In an interview, Christof Koch, chief scientist of the Mindscope project at the Allen Institute, explained: “The definition of AGI is unclear because we do not know how to define intelligence. Because we do not understand. Intelligence, in its broadest definition, is the ability to behave in complex environments where numerous different events occur over many different time scales, successfully learning and thriving in such environments.”
Massive Energy and Water Consumption
The human brain weighs only 3 pounds and has 100 billion neurons, performing human intelligence through 100 trillion to 500 trillion synapses and over 100 types of neurotransmitters. One synapse is equivalent to 5 to 8 layers of artificial deep neural networks. In synapses, there are over 2,500 proteins acting as sensors and effectors to control the excitability, inhibition, synaptic strength, and plasticity of neurons.
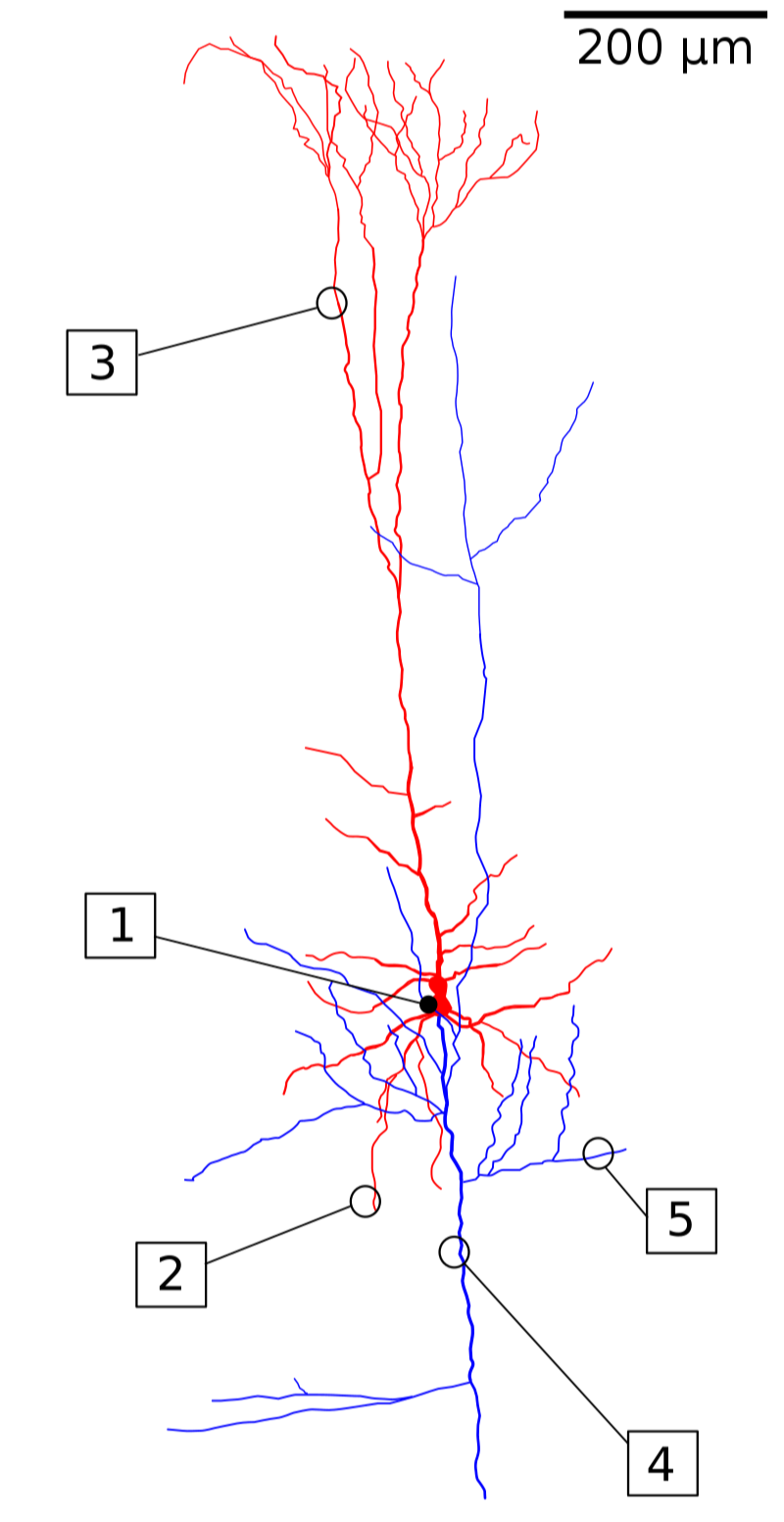
The above image is a reconstruction of the cone neurons in the human brain. The somatic cells and dendrites are marked in red, while the axonal axes are marked in blue. (1) Cell body, (2) basal dendrites, (3) apical dendrites, (4) axon, (5) collateral axon.
The human brain consumes only 17 to 20 watt-hours, mainly used for “communication” between neurons rather than “computation”: the energy consumption of the biophysical process of “communication” is an astonishing 35 times that of “computation.”
Warehouse-scale data centers—physical homes for most AI models, especially large models like GPT-3 and GPT-4, for physical training and deployment—are considered energy-intensive, accounting for 2% of global electricity consumption and producing a massive carbon footprint. However, it is less known that data centers are also very “thirsty,” consuming vast amounts of clean freshwater.
Training GPT-3 costs around 4 million dollars, using over 10,000 GPUs, with a power consumption of approximately 1,287 megawatt-hours. Based on the human brain’s 20 watt-hour power consumption, this equates to the power consumption of 64.35 million human brains. During training, it released 502 tons of carbon emissions and consumed 700,000 liters of clean water for evaporative cooling—enough to fill a giant nuclear reactor’s water tank or sufficient to produce 370 BMW cars or 320 Tesla electric vehicles. It should be noted that the “consumed” clean water refers to what was released back into the atmosphere through cooling towers, not the portion that “flowed away” from the water cycle. This evaporated clean water takes time to return to Earth in liquid form. Overall, the energy required to train GPT-3 could power an average American household for hundreds of years. Training GPT-3 was conducted in Microsoft’s state-of-the-art data center in the U.S., built specifically for OpenAI, costing tens of millions of dollars. If conducted in less energy-efficient data centers in other regions, energy and water consumption would multiply several times.
Research shows that ChatGPT needs to “drink” a 500ml bottle of water to complete basic communication with users, including about 25-50 questions.

Massive Costs That Will Continue to Rise
In addition to massive carbon emissions and water consumption, large language models are becoming larger and more expensive.
It is claimed that GPT-4 has 10,000 parameters, but OpenAI has not disclosed specific training details and scale, with training costs exceeding 100 million dollars. One thing is certain: more data, more GPUs, and more energy and clean water consumption were used.
Google’s PaLM, which trained 540 billion parameters, cost about 8 million dollars. Meta’s LLaMA, which trained 65 billion parameters, cost over 2.4 million dollars.
Large language models (LLMs), in addition to requiring immense computing power during training, also require substantial computing power for ongoing operations after construction, as they perform billions of calculations each time they respond to prompts. In contrast, the computing required to provide web applications or pages is much less.
These calculations also require specialized hardware. While traditional central processing units (CPUs) can run machine learning models, they are slow. Nowadays, most training and inference are conducted on graphics processing units (GPUs), which were originally designed for 3D gaming but have become the standard for AI applications because they can perform many simple calculations simultaneously.
Nvidia produces most GPUs for the AI industry, with its main data center workhorse chip costing $10,000. Scientists building these models often joke that they “melt GPUs.”

Regardless of whether generative AI shows signs of General Artificial Intelligence (AGI), it will undoubtedly have profound impacts and changes on certain professions and industries. At least for now, venture capital funding has shifted from subsidizing your taxi and Mexican food delivery to LLMs and generative AI. It is reported that the U.S. invested $47.4 billion in AI technology in 2022, which is 3.5 times that of our country. When it comes to burning money, the U.S. is unparalleled.
In addition to conversational AI services, this technology is being integrated into more industries and services. In this ecosystem’s three layers—hardware layer, infrastructure layer, foundational models, and application layer—there will be winners and new emergences.
We are simply too idle and lonely, needing a companion who is both intelligent and capable, yet emotionally calm.
Thank you for your attention.
For more content, click on the tags.