
Paper Weekly
WeChat Official Account: paperweekly
Introduction
Since its introduction, Word2Vec has become a fundamental component of deep learning in natural language processing. Various deep learning models rely on Word2Vec for word-level embeddings when representing words, phrases, sentences, paragraphs, and other text elements. The author of Word2Vec, Tomas Mikolov, is a scholar who has produced numerous high-quality papers, closely related to RNNLM, Word2Vec, and the recently popular FastText. Research on the same topic can last many years, with each year’s findings potentially inspiring peers. This issue of Paper Weekly will share three of his representative works, which are:
1. Efficient Estimation of Word Representation in Vector Space, 2013
2. Distributed Representations of Sentences and Documents, 2014
3. Enriching Word Vectors with Subword Information, 2016
Efficient Estimation of Word Representation in Vector Space
Authors
Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
Affiliation
Google Inc., Mountain View, CA
Keywords
Word Representation, Word Embedding, Neural Network, Syntactic Similarity, Semantic Similarity
Source
arXiv, 201309
Problem
How to quickly and accurately learn word representations on a large dataset?
Model
The traditional NNLM model consists of four layers: input layer, mapping layer, hidden layer, and output layer. The computational complexity largely depends on the calculations between the mapping layer and the hidden layer, and it requires specifying the context length. The RNNLM model was proposed to improve the NNLM model by removing the mapping layer, leaving only the input layer, hidden layer, and output layer, with computational complexity arising from the calculations between the hidden layers of the previous and next layers.
The two models proposed in this paper, CBOW (Continuous Bag-of-Words Model) and Skip-gram (Continuous Skip-gram Model), combine the characteristics of the above two models, each consisting of only three layers: input layer, mapping layer, and output layer. The CBOW model is similar to the NNLM model, using the context word vectors as input, sharing the mapping layer among all words, and the output layer being a classifier aimed at maximizing the probability of the current word. The Skip-gram model has its input and output reversed compared to CBOW, where the input layer is the current word vector, and the output layer aims to maximize the prediction probability of the context, as shown in the figure below. Training is done using SGD.
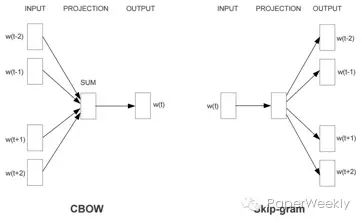
Resources
Code: C++ codeDataset: SemEval-2012, used to evaluate semantic relatedness.
Related Work
Bengio [1] proposed the idea of a language model in 2003, also using three layers (input layer, hidden layer, and output layer) to predict the middle word using context word vectors, but with higher computational complexity and lower efficiency on larger datasets; experiments also found that incorporating the frequency of n-grams in the context improves performance, a benefit reflected in the output layer of the CBOW and Skip-gram models, using hierarchical softmax (with Huffman trees) to calculate word probabilities.
Review
The experimental results of this paper show that CBOW performs better than NNLM in both syntactic and semantic predictions, while Skip-gram outperforms CBOW in semantic performance, but its computation speed is lower than CBOW. The results indicate that using larger datasets with fewer epochs can achieve good results and improve speed. Compared to LSI and LDA, word2vec utilizes the context of words, providing richer semantic information. Based on word2vec, phrase2vec, sentence2vec, and doc2vec emerged, seemingly entering a world of embeddings. These ideas in NLP are also applied in recommendations and combined with images to transform between image and text.
Authors
Quoc V. Le, Tomas Mikolov
Affiliation
Google Inc, Mountain View, CA
Keywords
Sentence Representation
Source
ICML 2014
Problem
Based on the idea of word2vec, how to represent sentences and documents?
Model
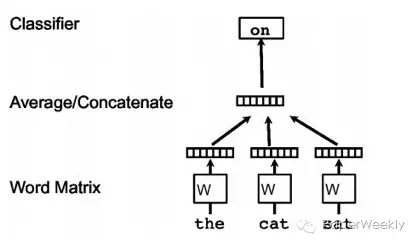
Using one-hot representation as input to the network, multiplying by the word matrix W, then obtaining each vector through averaging or concatenating to get the overall sentence representation, and finally performing a classification based on the task requirements. The W obtained in this process is the word vector matrix, essentially still following the word2vec approach.
Next is the vector representation method for paragraphs:
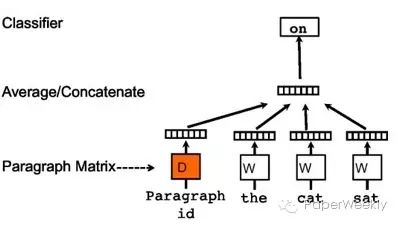
Still using the same method, but here an additional paragraph matrix is added to represent each paragraph. When these words are input into the i-th paragraph, the corresponding paragraph representation can be obtained from this matrix using the paragraph ID. It should be noted that within the same paragraph, the representation of the paragraph is the same. The motivation for this representation is that the paragraph matrix D can serve as a memory to retain information lost in the context of the words, effectively adding an extra piece of information. After training, we obtain the paragraph representation D, which can represent a segment or an entire article.
The last method is a paragraph vector representation method without word order:
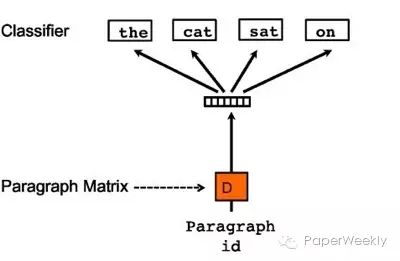
From the figure, it is clear that this method is quite similar to skip-gram, focusing on paragraph representation to predict the corresponding context word representations. Finally, we still obtain the paragraph matrix D, allowing us to vectorize the paragraph representation. However, the input is at least at the sentence level, while the output is the word vector representation, leading to some skepticism about the rationality of this method.
Review
This paper was proposed a year after the introduction of the word2vec method, and thus did not use the currently popular training methods of word2vec to train word vectors, but instead proposed a simpler network structure to train arbitrary-length text representation based on the ideas of word2vec. This approach is easier to train and reduces parameters, avoiding model overfitting. The advantage is that it incorporates a paragraph matrix when training paragraph vectors, thus retaining some information about paragraphs or documents during the training process. This is also seen as an advantage currently. However, with the rapid development of deep learning, which can handle very large computations, and the widespread application of word2vec and its variants, the approach proposed in this paper is more about the idea than the model, which we can draw inspiration from, but the model does not have advantages.
Authors
Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov
Affiliation
Facebook AI Research
Keywords
Word Embedding, Morphological, Character N-gram
Source
arXiv, 201607
Problem
How to address the poor performance of rare words in the word2vec method and improve the performance of morphologically rich languages?
Model
Word2vec has made significant contributions to vocabulary modeling; however, it relies on a large amount of text data for learning. If a word appears infrequently, the quality of the learned vector is also suboptimal. To address this issue, the authors propose using subword information to compensate for this problem. In simple terms, this means representing words through the vectors of their affixes. For example, “unofficial” is a low-frequency word, and its data volume is insufficient to train a high-quality vector, but it can learn a good vector through the high-frequency affixes “un” and “official.”
In terms of method, this paper follows the skip-gram model of word2vec, with the main difference lying in the features. Word2vec uses words as the basic unit, predicting other words in its context through the center word. In contrast, the subword model uses character n-grams as units, with n ranging from 3 to 6. Thus, each vocabulary can be represented as a string of character n-grams, and the embedding of a word is the sum of all its n-grams. Consequently, we shift from using the center word’s embedding to predict the target word to using the center word’s n-gram embedding to predict the target word.
The experiments are divided into three parts: (1) calculating the semantic similarity between two words and comparing it with human-annotated similarity; (2) conducting word analogy experiments similar to word2vec; (3) comparing with other methods that consider morphology. The results show that this method performs excellently in morphologically rich languages (such as Turkish and French) and small datasets, aligning with expectations.
Resources
The source code is published in Facebook’s fastText project: https://github.com/facebookresearch/fastText
Related Work
The use of morphology to improve NLP has a long history, and many interesting works regarding character-level and morphology mentioned in this paper are worth referencing.
Review
The ideas presented in this article are very meaningful for morphologically rich languages (e.g., Turkish, where the use of affixes is very common and interesting). Affixes serve as intermediate units between letters and words and contain certain semantic information. By fully utilizing this intermediate semantic representation for rare vocabulary, the approach seems very reasonable and applies the idea of compositionality.
There is abundant work on improving word embeddings through morphology, but it seems challenging to apply this idea in Chinese NLP. Personally, I feel that there are also units in Chinese similar to affixes, such as radicals, but they are not as easily handled as languages using an alphabetic system. I look forward to seeing brilliant work emerging in the Chinese context in the future.
Conclusion
From Word2Vec to FastText, from word representation to sentence classification, Tomas Mikolov’s work has influenced many. Although some models and experimental results have faced scrutiny, the overall impact remains significant. Word2Vec has greatly advanced research in NLP, and its ideas and applications can be seen not only in NLP but also in many other fields. It is precisely from Word2Vec that the world has become vectorized: person2vec, sentence2vec, paragraph2vec, anything2vec, world2vec. This is the main content of this issue of Paper Weekly. Thanks to memray, zhkun, gcyydxf, and jell for their organization.
Paper Weekly is a grassroots organization that shares knowledge and engages in academic discussions, focusing on various aspects of NLP. If you frequently read papers, enjoy sharing knowledge, and like to discuss and learn with others, please join us!

Weibo Account: PaperWeekly (http://weibo.com/u/2678093863)
Zhihu Column: PaperWeekly (https://zhuanlan.zhihu.com/paperweekly)
WeChat Group: WeChat + zhangjun168305 (please note: join group or join paperweekly)