
Recommended by New Intelligence1
Authorized Reprint by iFlytek
Author: iFlytek Research Institute
In recent years, artificial intelligence has become increasingly intertwined with human life. People have long envisioned a true Jarvis at their side, hoping that one day computers can truly listen, speak, understand, and think like humans. An important prerequisite for achieving this goal is that computers can accurately understand human speech, which means that a highly accurate voice recognition system is essential.
As a leader in the domestic intelligent voice and artificial intelligence industry, iFlytek has consistently driven the progress of Chinese voice recognition technology. On December 21 last year, at the annual conference held at the National Conference Center in Beijing, themed “AI Rebirth, Everything Renewed,” iFlytek introduced a new generation of voice recognition systems represented by the Feed-forward Sequential Memory Network (FSMN), which impressed everyone [1].
Through further research, we have launched a brand-new voice recognition framework based on FSMN, innovatively redefining the voice recognition problem as the issue of “seeing spectrograms.” By introducing mainstream deep convolutional neural networks (CNN) from image recognition, we have achieved a new interpretation of spectrograms while breaking the traditional deep voice recognition system’s reliance on DNNs and RNNs, ultimately raising recognition accuracy to new heights. Today, we will unveil its mysteries.
We detailed FSMN in our previous article (click to read the original), and here we will briefly review it.
Before the introduction of FSMN, the best voice recognition systems in academia and industry used Bi-directional Recurrent Neural Networks (BRNN), which could model the complex long-term correlations of speech, thus improving recognition accuracy. However, BRNNs suffer from high training complexity, instability during training, and high decoding latency, making them difficult to use.
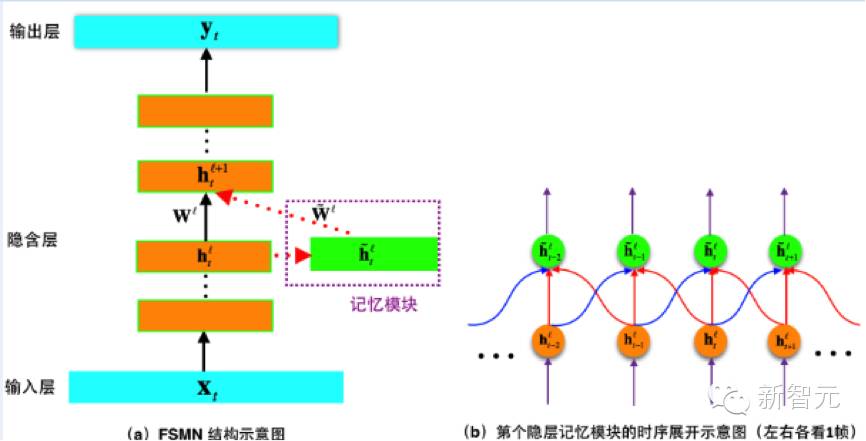
The introduction of FSMN effectively addressed these shortcomings. FSMN adds a “memory module” next to the hidden layer of the traditional DNN structure to store historical and future information around the current speech frame. The model structure of FSMN is shown in Figure (a), and Figure (b) illustrates the temporal expansion structure of the memory module when it remembers one frame of information on either side of the current speech frame. Since FSMN’s structure does not involve recursion, it avoids the instability of RNNs, while the memory module effectively models the long-term correlations of speech.
The success of FSMN has provided us with valuable insights: modeling long-term correlations in speech does not require observing the entire sentence, nor does it necessarily need to use recursive structures. As long as sufficiently long contextual information is well expressed, it can provide ample assistance for decision-making at the current frame, and convolutional neural networks (CNN) can achieve this as well.
CNNs were applied to voice recognition systems as early as 2012, and many researchers have been actively engaged in CNN-based voice recognition system research, yet no major breakthroughs have occurred. The main reason is that they have not broken free from the traditional feedforward neural network’s fixed-length frame splicing input mindset, thus failing to capture sufficiently long contextual information. Another flaw is that they only view CNN as a feature extractor, resulting in very few convolutional layers, typically only one or two, which severely limits the expressive power of such convolutional networks. To address these issues, drawing from our experience in developing FSMN, we have introduced a brand-new Deep Fully Convolutional Neural Network (DFCNN) voice recognition framework, which uses a large number of convolutional layers to directly model the entire speech signal, better expressing the long-term correlations of speech, achieving over 15% improvement in recognition rates compared to the best bi-directional RNN voice recognition systems in academia and industry. Below, we will specifically introduce the DFCNN voice recognition framework.
The structure of DFCNN is illustrated in Figure (c). DFCNN directly transforms a sentence of speech into an image as input, which involves performing a Fourier transform on each speech frame, then using time and frequency as the two dimensions of the image. Following this, a combination of a large number of convolutional layers and pooling layers models the entire sentence of speech, with the output units directly corresponding to the final recognition results, such as syllables or Chinese characters.
The working mechanism of DFCNN resembles that of a highly respected phonetics expert, who can determine the content expressed in speech just by “watching” the spectrogram. For many readers, this may sound like science fiction at first, but after our analysis below, we believe everyone will find this architecture quite natural.
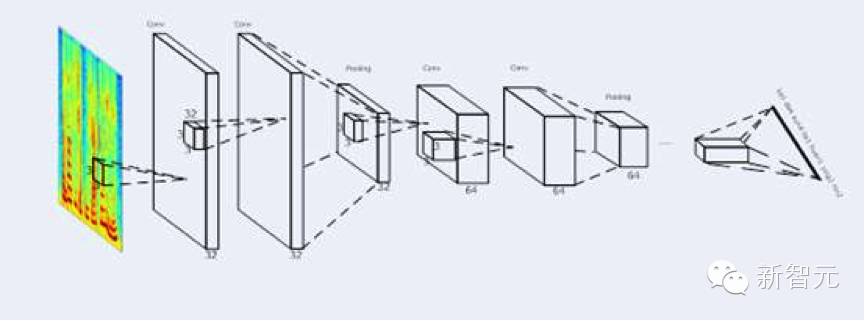 Figure (c): DFCNN Structure Diagram
Figure (c): DFCNN Structure Diagram
Firstly, from the input end, traditional speech features, after Fourier transformation, use various artificially designed filter banks to extract features, which results in information loss in the frequency domain, particularly in the high-frequency region. Moreover, traditional speech features must use very large frame shifts for computational efficiency, which undoubtedly leads to information loss in the time domain, especially prominent when the speaker speaks quickly.Therefore, DFCNN directly uses the spectrogram as input, which has inherent advantages compared to other voice recognition frameworks that use traditional speech features as input. Secondly, from the model structure perspective, DFCNN differs from traditional CNN approaches in voice recognition. It draws on the best network configurations from image recognition, using 3×3 small convolution kernels for each convolutional layer, and adding pooling layers after multiple convolutional layers, greatly enhancing the expressive power of CNNs. At the same time, by accumulating a large number of such convolutional-pooling pairs, DFCNN can observe very long historical and future information. These two points ensure that DFCNN can excellently express the long-term correlations of speech, and it is even more robust compared to RNN network structures. Finally, from the output end, DFCNN can also perfectly integrate with the recently popular Connectionist Temporal Classification (CTC) scheme for end-to-end training of the entire model, and its special structures, including pooling layers, can make the above end-to-end training more stable.
After integrating with several other technical points, the iFlytek DFCNN voice recognition framework achieved a 15% performance improvement over the currently best voice recognition framework in the industry—the bi-directional RNN-CTC system—on thousands of hours of internal Chinese voice transcription tasks. Combined with iFlytek’s HPC platform and multi-GPU parallel acceleration technology, the training speed also surpasses that of traditional bi-directional LSTM CTC systems. The introduction of DFCNN has opened up a new realm in voice recognition. In the future, based on the DFCNN framework, we will also conduct more related research, such as: both bi-directional LSTM and DFCNN can provide expressions for long-term historical and future information, but whether there is complementarity between these two expressions is a question worth pondering. We believe that with continuous research, iFlytek’s voice recognition system will continue to reach new heights!
References
[1] S. Zhang, C. Liu, H. Jiang, S. Wei, L. Dai, and Y. Hu, “Feedforward sequential memory networks: A new structure to learn long-term dependency,” arXiv preprint arXiv:1512.08301, 2015.