

Reported by Xinzhi Yuan
Reported by Xinzhi Yuan
Editor: QJP
[Xinzhi Yuan Guide] One of the biggest challenges in using machine learning (ML) algorithms (especially modern deep learning) for image recognition is the difficulty in understanding why a particular input image produces the predicted result. We have integrated visual interfaces for the state-of-the-art image interpretation techniques over the past decade and provided a brief description of each technology.
How have the latest methods for interpreting neural networks developed over the past 11 years?
This article attempts to demonstrate explanations using guided backpropagation on the Inception network image classifier.
Why is “explanation” important?
One of the biggest challenges in using machine learning (ML) algorithms (especially modern deep learning) for image recognition is the difficulty in understanding why a particular input image produces the predicted result.
Users of ML models often want to understand which parts of the image are important factors in the prediction. These explanations or “interpretations” are valuable for many reasons:
-
Machine learning developers can analyze the explanations to debug models, identify biases, and predict whether the model might generalize to new images.
-
If an explanation is provided for why a specific prediction was made, users of the machine learning model may trust the model more.
-
Regulations around machine learning, such as GDPR, require that some algorithmic decisions can be explained in human terms.
Thus, researchers have been developing many different methods to open the “black box” of deep learning to make the underlying models easier to explain since at least 2009.
Below, we have integrated visual interfaces for the state-of-the-art image interpretation techniques over the past decade and provided a brief description of each technology.
We have used many great libraries, but particularly relied on Gradio to create the interfaces you see in the gif files below and the TensorFlow implementation of PAIR-code.
The model used for all interfaces is the Inception Net image classifier, and you can find the complete code to replicate this blog post in this Jupyter notebook and Colab.
Before we dive into the papers, let’s start with a very basic algorithm.
Seven Different Explanation Methods
Leave-one-out (LOO)

Leave-one-out (LOO) is one of the easiest methods to understand. If you want to know which parts of the image are responsible for the prediction, this might be the first algorithm that comes to mind.
The idea is to first segment the input image into a set of smaller regions, and then run multiple predictions, masking one region each time. Based on the impact of each “masked” region on the output, an importance score is assigned to each region. These scores quantify which region is most responsible for the prediction.
This method is slow as it relies on many iterations of running the model, but it can generate very accurate and useful results. The above is an example image of a Doberman dog.
LOO is the default explanation technique in the Gradio library and requires no access to the internal workings of the model—this is a significant advantage.
Vanilla Gradient Ascent [2009 and 2013]

Paper: Visualizing Higher-Layer Features of a Deep Network [2009]
Paper: Visualizing Image Classification Models and Saliency Maps [2013]
These two papers are similar in that they both explore the internals of neural networks using gradient ascent. In other words, they consider that small changes to the input or activations will increase the likelihood of predicting a category.
The first paper applies it to activations, and the authors report that “it is possible to find good qualitative explanations for high-level features, which we demonstrate, perhaps counterintuitively, can be achieved at the unit level, is easy to implement, and the results of various techniques are consistent.”
The second approach also uses gradient ascent but probes directly into the pixel points of the input image rather than activations.
The author’s method “calculates class saliency maps specific to given images and classes, such maps can be used for weakly supervised object segmentation using classification ConvNets.”
Guided Back-Propagation [2014]

Paper: Striving for Simplicity: The All Convolutional Net [2014]
This paper introduces a new neural network composed entirely of convolutional layers. Since previous explanation methods were not applicable to their network, they introduced guided backpropagation.
This backpropagation filters out negative activations generated during standard gradient ascent. The authors claim that their method “can be applied to a broader range of network architectures.”
Grad-CAM [2016]

Paper: Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization [2016]
Next is Gradient-weighted Class Activation Mapping (Grad-CAM). It utilizes “the gradients of any target concept flowing into the last convolutional layer to produce a rough localization map highlighting important regions in the image for the predicted concept.”
The main advantage of this method is that it further generalizes interpretable neural network classes (such as classification networks, captions, and visual question answering (VQA) models), and provides a good post-processing step to focus and locate explanations around key objects in the image.
SmoothGrad [2017]

Paper: SmoothGrad: removing noise by adding noise [2017]
Like the previous papers, this method begins with computing the gradient of the class score function with respect to the input image.
However, SmoothGrad sharpens these gradient-based saliency maps visually by adding noise to the input image and then calculating the gradient for each of these perturbed versions of the image. Averaging the saliency maps together yields clearer results.
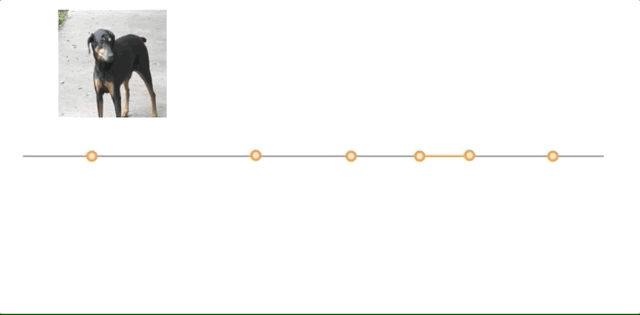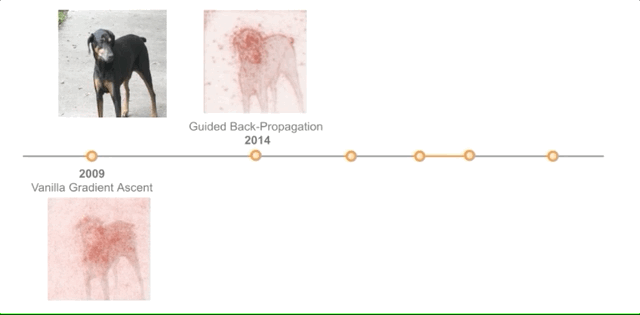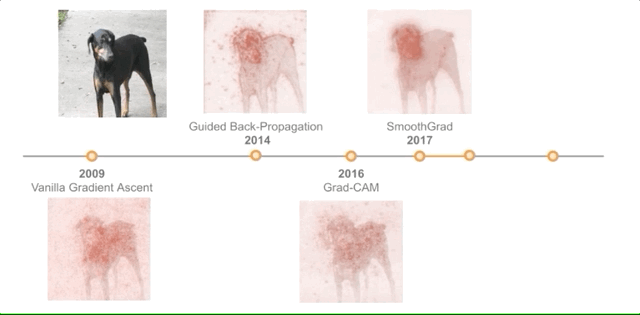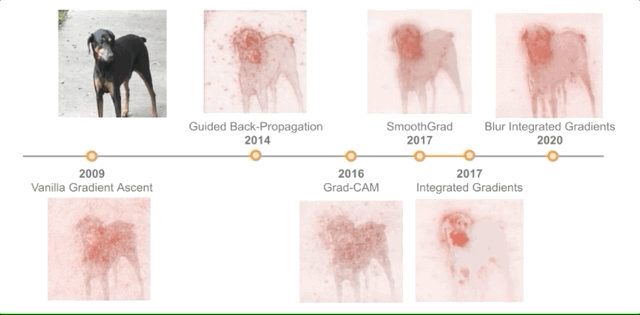
Integrated Gradients [2017]

Paper: Axiomatic Attribution for Deep Networks [2017]
Unlike previous papers, the authors of this paper start from the theoretical foundations of explanations. They “identify two fundamental axioms that attribution methods should satisfy—sensitivity and implementation invariance.”
They use these principles to guide the design of a new attribution method (called Integrated Gradients) that can produce high-quality explanations while still only requiring access to the model’s gradients; however, it adds a “baseline” hyperparameter that may affect the quality of the results.
Blur Integrated Gradients [2020]

Paper: Attribution in Scale and Space [2020]
This paper studies a cutting-edge technique—this method was proposed to address specific issues, including eliminating the “baseline” parameter and removing certain visual artifacts that tend to arise in explanations.
Additionally, it also “produces scores in the scale/frequency dimension,” essentially providing a sense of scale for important objects in the image.
The image below compares all these methods:

Reference Links:
https://gradio.app/blog/interpretation-history
https://github.com/gradio-app/history-of-interpretation/blob/master/History-of-Interpretation.ipynb
