
Click on the above“Beginner Learning Vision”, select to add Star or Top”
Essential insights delivered in real-time
This is for academic sharing only and does not represent the views of this public account. Contact for removal in case of infringement.Reprinted from: New Intelligence Source
The Transformer architecture has swept across multiple fields including natural language processing, computer vision, speech, and multimodal tasks. However, the experimental results are stunning, while research on the working principles of Transformers remains quite limited.
The biggest mystery is why Transformers can emerge efficient representations from gradient training dynamics relying solely on a “simple prediction loss”?
Recently, Dr. Tian Yuandong announced his team’s latest research findings, mathematically analyzing the SGD training dynamics of a 1-layer Transformer (one self-attention layer plus one decoder layer) on the next token prediction task.

Paper link: https://arxiv.org/abs/2305.16380
This paper opens the black box of how the self-attention layer combines the dynamic process of input tokens and reveals the nature of potential inductive biases.
Specifically, under the assumption of no positional encoding, long input sequences, and that the decoder layer learns faster than the self-attention layer, the researchers demonstrated that self-attention operates as a discriminative scanning algorithm:
Starting from uniform attention, for a specific next token to be predicted, the model gradually focuses on different key tokens while paying less attention to common tokens that appear in multiple next token windows.
For different tokens, the model will gradually decrease the attention weights, following the order of co-occurrence between key tokens and query tokens from low to high in the training set.
Interestingly, this process does not lead to a winner-takes-all scenario but slows down due to phase transitions controlled by two learning rates, ultimately resulting in (almost) fixed token combinations, a dynamic that is also validated on synthetic and real-world data.
Dr. Tian Yuandong is a researcher and research manager at Meta AI Research, leading the Go AI project. His research focuses on deep reinforcement learning and its applications in games, as well as theoretical analysis of deep learning models. He obtained his bachelor’s and master’s degrees from Shanghai Jiao Tong University in 2005 and 2008, respectively, and his PhD from Carnegie Mellon University’s Robotics Institute in 2013.

He was nominated for the Marr Prize Honorable Mentions at the 2013 International Conference on Computer Vision (ICCV) and received an Outstanding Paper Honorary Nomination at ICML 2021.
After his PhD graduation, he published a series called “Five-Year Summary of PhD” summarizing experiences and insights on research direction selection, reading accumulation, time management, work attitude, income, and sustainable career development.
Unveiling the 1-Layer Transformer
Pre-trained models based on the Transformer architecture usually include very simple supervised tasks, such as predicting the next word or filling in blanks, yet they can provide very rich representations for downstream tasks, which is truly puzzling.
While previous work has demonstrated that Transformers are essentially universal approximators, traditional machine learning models like kNN, kernel SVM, and multilayer perceptrons are also universal approximators. This theory cannot explain the significant performance gap between these two classes of models.
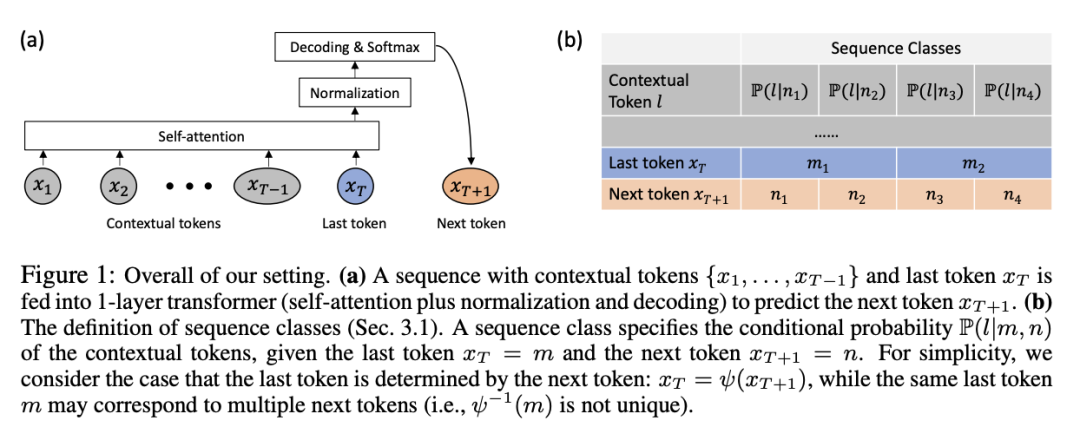
The researchers believe that understanding the training dynamics of Transformers is crucial, meaning how the learnable parameters change over time during training.
The article first rigorously mathematically defines and formalizes the training dynamics of a 1-layer Transformer without positional encoding during the next token prediction (a common training paradigm for GPT series models).
A 1-layer Transformer consists of a softmax self-attention layer and a decoder layer for predicting the next token.
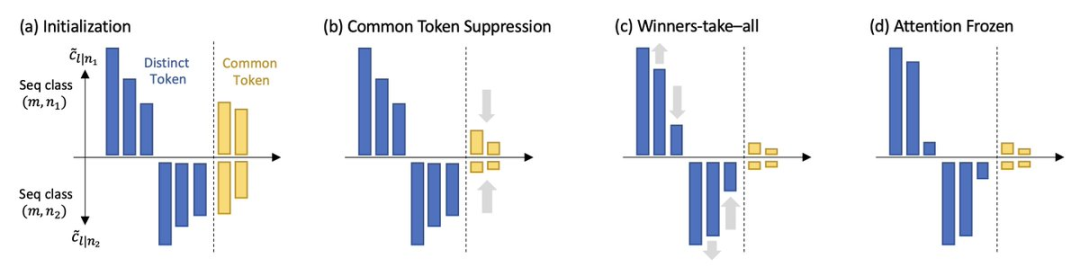
Under the assumption of long sequences and that the decoder learns faster than the self-attention layer, the dynamic behavior of self-attention during training is demonstrated:
1. Frequency Bias
The model gradually focuses on key tokens that co-occur frequently with the query token while decreasing attention on those that co-occur less.
2. Discriminative Bias
The model pays more attention to unique tokens that appear only in the next token to be predicted, while losing interest in common tokens that appear in multiple next tokens.
These two characteristics indicate that self-attention implicitly runs a discriminative scanning algorithm and has an inductive bias towards unique key tokens that frequently co-occur with the query token.
Moreover, although the self-attention layer tends to become sparser during training, as suggested by the frequency bias, the model does not collapse into one-hot due to the phase transitions in the training dynamics.

The final stage of learning does not converge to any saddle point with zero gradients but enters a region where attention changes slowly (i.e., logarithmically over time), resulting in parameter freezing and learned behaviors.
The research results further indicate that the onset of phase transitions is controlled by the learning rate: a large learning rate produces sparse attention patterns, while a large decoder learning rate under a fixed self-attention learning rate leads to faster phase transitions and dense attention patterns.
The researchers named the SGD dynamics discovered in their work as scan and snap:
Scan Phase: Self-attention focuses on key tokens, i.e., different tokens that frequently co-occur with the next predicted token; the attention on all other tokens decreases.
Snap Phase: Attention almost freezes, and the token combinations become fixed.
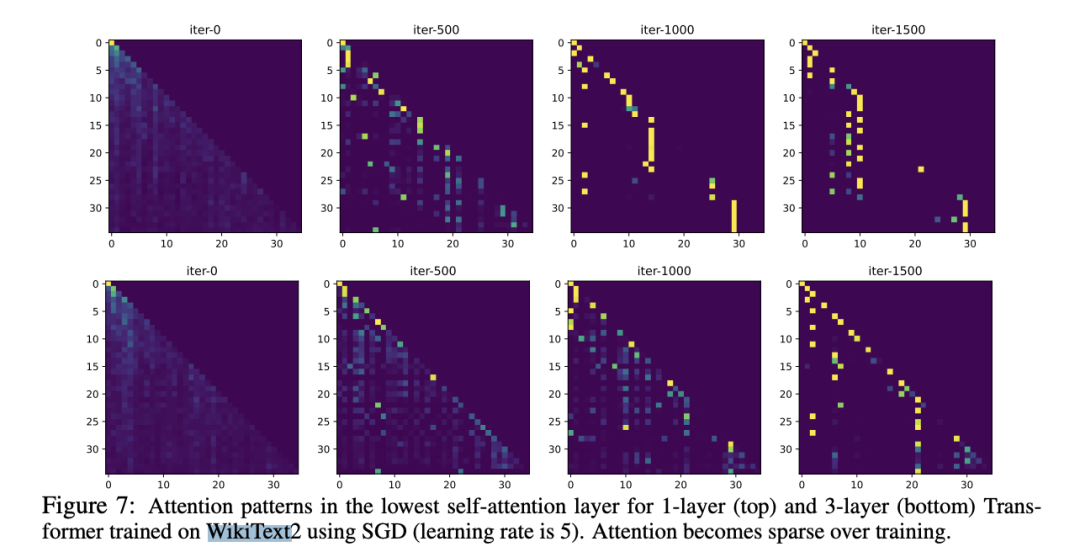
This phenomenon is also validated in simple real-world data experiments. Observations of the minimum self-attention layer of 1-layer and 3-layer Transformers trained on WikiText using SGD reveal that even with a constant learning rate throughout training, attention can freeze and become sparse at certain points in the training process.
References:https://arxiv.org/abs/2305.16380
Download 1: Chinese Tutorial for OpenCV-Contrib Extension Modules
Reply "Chinese Tutorial for Extension Modules" in the "Beginner Learning Vision" public account backend to download the first Chinese version of the OpenCV extension module tutorial online, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: 52 Lectures on Python Vision Practical Projects
Reply "Python Vision Practical Projects" in the "Beginner Learning Vision" public account backend to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and facial recognition to help you quickly learn computer vision.
Download 3: 20 Lectures on OpenCV Practical Projects
Reply "20 Lectures on OpenCV Practical Projects" in the "Beginner Learning Vision" public account backend to download 20 practical projects based on OpenCV for advanced learning.
Group Chat
You are welcome to join the public account reader group to exchange ideas with peers. Currently, we have WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, noting: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, you will not be approved. After successful addition, you will be invited to join related WeChat groups based on your research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~