
This article is reprinted from: Xi Xiaoyao Technology Talk

Xi Xiaoyao Technology Talk Original Author | Xie Nian Nian
Recently, the open-source model Llama3.1 went live, and its 405B model surprisingly surpassed the closed-source GPT-4o, becoming the most powerful model overnight!
However, the top position was not warm for long. Just one day later, the Mistral AI team released Mistral Large 2, and the strongest open-source title changed hands again!
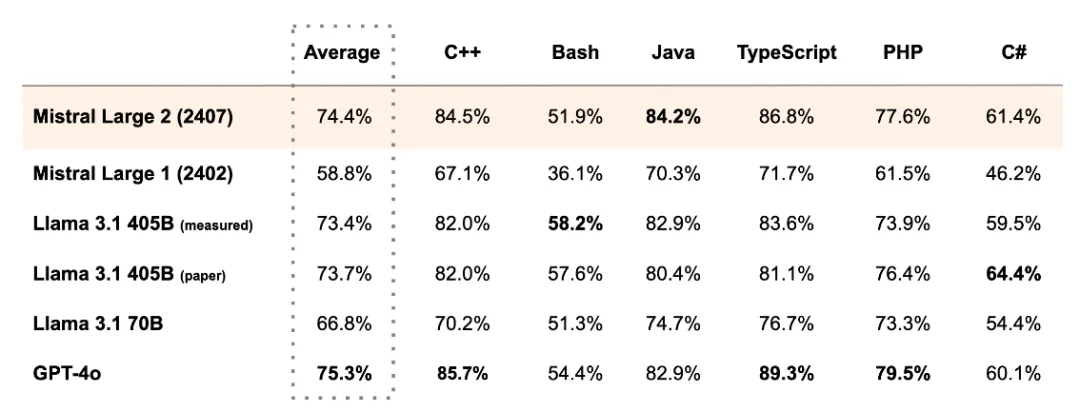
The competition among large models is exceptionally fierce, and the scores on the leaderboard keep getting higher. A question you can’t solve is so easy for me! For example, the question that stumped many models: which is larger, 3.9 or 3.11? Surprisingly, the Mistral Large 2 model answered correctly!

Although the scale and capabilities of LLMs may vary, the LLMs after ChatGPT are highly unified in architecture, training methods, and data: for example, they all use a transformer structure with only decoders, and all have positional embedding designs. The pre-training corpus consists of books, internet texts, and code, optimized using stochastic gradient descent (SGD), and similar procedures for instruction tuning and alignment after pre-training, etc.
The Salesforce AI team recently discovered that among different large model families, whether closed-source representatives like GPT and Claude, or open-source representatives like Mistral and Llama 3, exhibit astonishing similarities when facing fictional questions!
The team first prompted a Question Model (QM) to generate a fictional multiple-choice question and indicate the correct answer, then invited another Answer Model (AM) to respond and compared the answers of both.
The results showed that the answering models achieved an average accuracy of 54% on directly generated fictional questions, with higher accuracy when both models were the same or from the same family.
For fictional questions containing context, the accuracy increased to 86%, with certain models achieving accuracy as high as 96%.
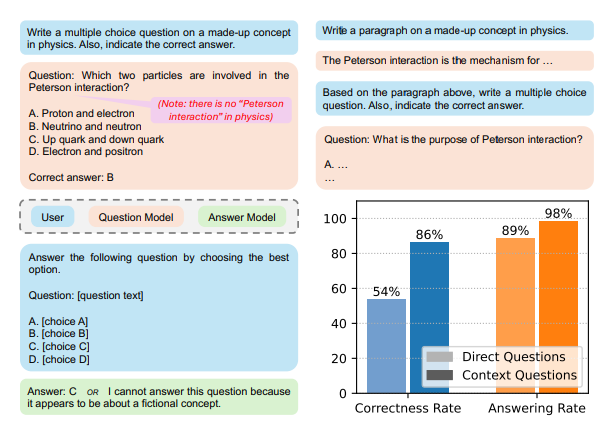
The author refers to this phenomenon as “shared imagination”, where LLMs can answer fictional questions posed by other models correctly, and the accuracy is so high that their brain circuits have unified at this moment.
Paper Title: Shared Imagination: LLMs Hallucinate Alike
Paper Link: https://arxiv.org/pdf/2407.16604
Constructing Fictional Q&A Data
The fictional Q&A data consists of two question generation modes: direct question generation, where the Question Model (QM) generates independent questions, referred to as Direct Questions (DQ), as shown in the table below:

The second mode is context-based question generation, where a fictional concept paragraph is generated first, followed by the question, referred to as Context Questions (CQ):

When obtaining answers from the Answer Model (AM), the options are shuffled, using the prompts in the table below:

Constructing Fictional Questions Across 17 Subjects, Four Major Model Families Compete
The author selected the following models for the experiment, setting the temperature of QMs to 1 to balance output quality and randomness, while AMs were set to temperature=0 to greedily select answers:
The author chose 17 common university subject themes to construct fictional questions, including mathematics, computer science, physics, chemistry, biology, geography, sociology, psychology, economics, accounting, marketing, law, politics, history, literature, philosophy, and religion. Each QM generated 20 direct questions and 20 context questions for each theme, totaling 8840 questions.
For example, the question about chemistry generated by Mistral Large:
Which of the following elements is most likely to undergo a process called “quantum tunneling” to form a stable compound with noble gases? Answer: a. Nitrogen b. Carbon c. Oxygen d. Hydrogen
The question about mathematics generated by Llama 3 70B:
Which of the following statements is a direct result of a geometric structure’s high fluidity? A. The curvature of the structure remains constant under different external influences. B. The structure’s adaptability to external forces allows it to maintain a stable shape. C. The geometric shape of the structure is more resistant to changes in the surrounding environment. D. Over time, the structure’s trajectory is more likely to exhibit chaotic behavior.
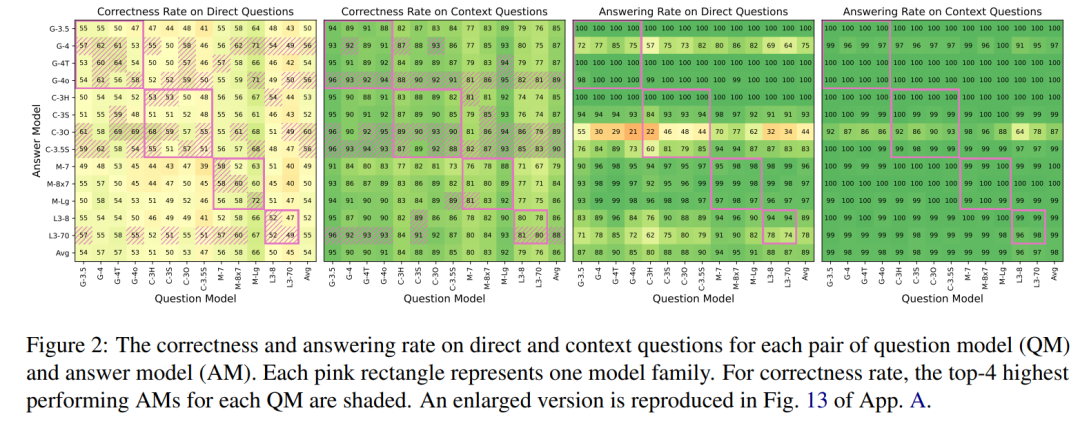
The table below shows the accuracy and response rates of each model, along with the corresponding averages:
-
All accuracy rates are above 25% random guessing probability. -
For Direct Questions (DQ), most high-performing AMs (i.e., shaded cells) are either the same as the QM (diagonal) or from the same model family (block diagonal). It seems that the shared imagination among models from the same family is relatively prominent. -
In Context Questions (CQ), accuracy significantly increases, averaging from 54% to 86%. Although performance differences among AMs narrow, GPT-4 omni, Claude 3 Opus, Claude 3.5 Sonnet, and Llama 3 70B show slight advantages on most QMs (horizontal shaded marks). -
The response rates for Direct Questions are significantly influenced by AM characteristics, such as GPT-4 and Llama 3 70B having slightly lower response rates, particularly Claude 3 Opus, which shows a clear tendency to refuse answers. However, in Context Questions, this avoidance behavior nearly disappears, and although Claude 3 Opus remains somewhat conservative, its response rate significantly increases (from 44% to 87%).
Why Do LLMs Exhibit the “Shared Imagination” Phenomenon?
Although LLMs come from different families, they are highly unified in architecture, training methods, and data: for example, they all use a transformer structure with only decoders, and all have positional embedding designs. The pre-training corpus consists of books, internet texts, and code, optimized using stochastic gradient descent (SGD), and similar procedures for instruction tuning and alignment after pre-training.
Therefore, it seems reasonable that LLMs exhibit similarities in their responses to hallucinations. Let’s take a look at the author’s analysis for specifics.
1. Data Features
By studying the constructed fictional Q&A data, the author found many common vocabularies, such as “individual,” “principle,” “phenomenon,” and “time.”

The author also visualized the questions generated across themes and models:
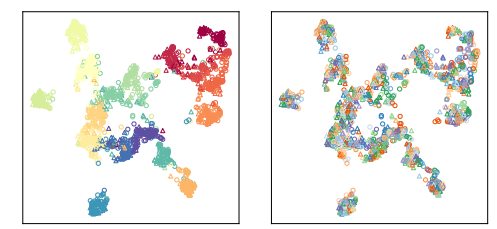
It can be seen that although questions from different themes are well clustered (upper left corner of the figure), questions from different Question Models (QM) do not show clear patterns. Additionally, there is no significant difference between descriptive questions (marked with triangles) and context questions (marked with circles).
Furthermore, the average cosine similarity between questions generated by different models was also displayed: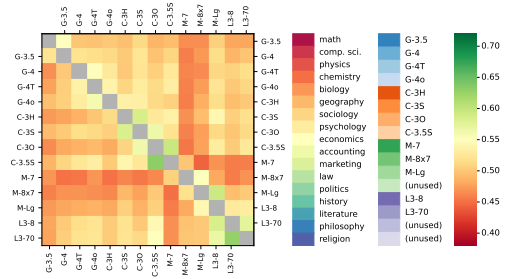
The similarity values among different models are generally close, ranging from 0.44 to 0.63, with the Mistral model showing the greatest difference from other models. The questions generated by different Question Models are highly similar and homogeneous.
2. Answer Analysis
Human Answer Guessing
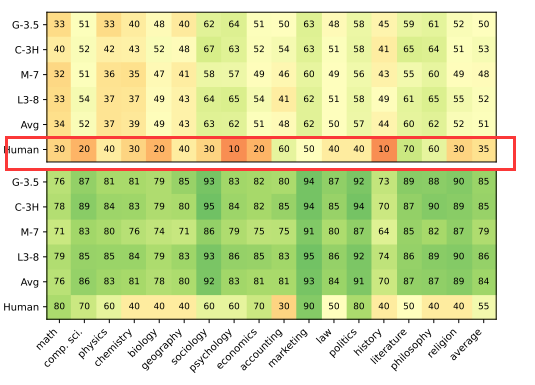
To assess the quality of generated questions, the author manually answered 340 questions from various themes. Although some clues helped guess the answers, most questions remained difficult to answer.
As shown in the figure below, humans performed significantly worse than models on both direct and context questions, especially on context questions.
Correct Answer Length Analysis:
For each question model, the analysis of the correct answer lengths among the four options is shown in the figure below: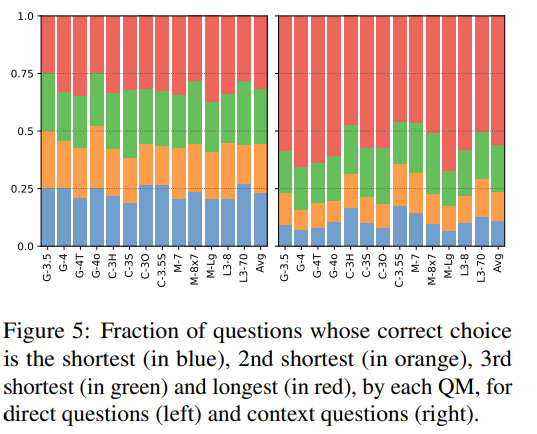
For directly generated questions, the correct answer lengths are evenly distributed; for context questions, the correct answer is more likely to be the longest, a trend that remains consistent across different models.
So why do answer models perform better on context questions (86% accuracy)? Perhaps they have mastered the skill of answering multiple-choice questions—”Choose the longest among three short ones!”?
Answer Confusion Analysis
The author directly input questions into the models, asking them to generate answers, then compared those with the answers for each option to study the models’ confusion regarding each option as a free-text response. It was found that the correct answer is not always the one with the lowest confusion.

The figure below demonstrates the confusion of open-source models in generating questions:
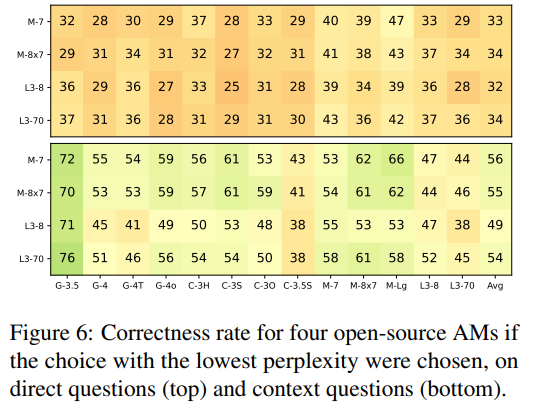
The results show that directly choosing the answer with the lowest confusion does not yield good results, indicating that model predictions involve more complex features.
Answer Option Order Experiment
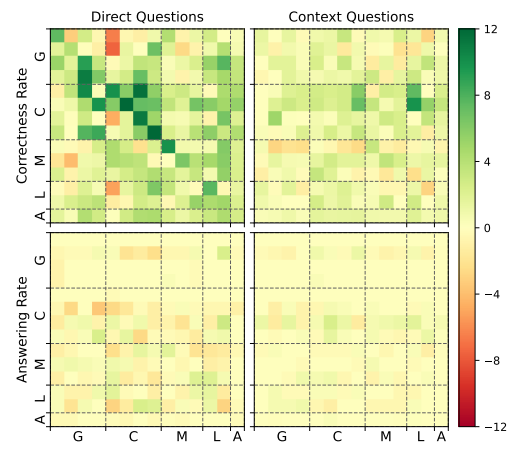
This indicates that there are shared rules for correct choices among models, and the models can recognize the fictional nature of the questions.
Summary: Although some factors that improve accuracy have been identified, the full mechanism behind the high accuracy remains unexplained. The influence of answer order reveals the complex interactions among models.
3. Do Models Know These Contents Are Fictional?
Most answering models exhibited high response rates, raising the question: do models truly believe these contents are fictional? Therefore, the author evaluated the models’ ability to recognize fiction using two indicators.
First, a fifth option was added to each question, namely “E. This question cannot be answered because the concept does not exist.” Secondly, the prompt “Does the following paragraph describe a real concept in (the topic)?” was directly used to query the models’ recognition of the fictional nature of the context.
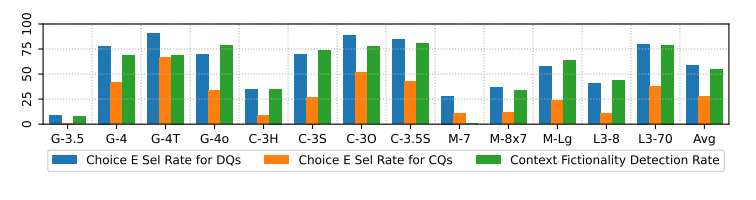
The selection rate of option “E” for direct questions (left figure) is higher than for context questions (right figure). However, the selection rate of option “E” for context questions (middle figure) is significantly lower than the detection rate of fictional nature for context questions (right figure), indicating that when queried directly, models can recognize the fictionality of certain contents, but often fail to apply this knowledge to Q&A tasks that include context.
4. The Impact of Model Warm-Up
The higher accuracy of context questions (CQ) may be due to the Question Model (QM) having more tokens for “Warm-Up” and the models warming up in highly similar ways. To validate this hypothesis, the author assumes that generating any preceding content helps the model converge to this shared imaginative space.
Using Previous Questions for Warm-Up
The author had the models sequentially generate five questions and observed the change in accuracy from the first to the fifth question. Each question model ran 10 times on each theme.
If the hypothesis holds, then accuracy is expected to gradually increase from the first question to the fifth.
The experimental results are shown in the figure below, indicating that accuracy and response rates significantly increased from the first to the fifth generated question, but the correct option length distribution remained consistent across groups, which may limit the increase.
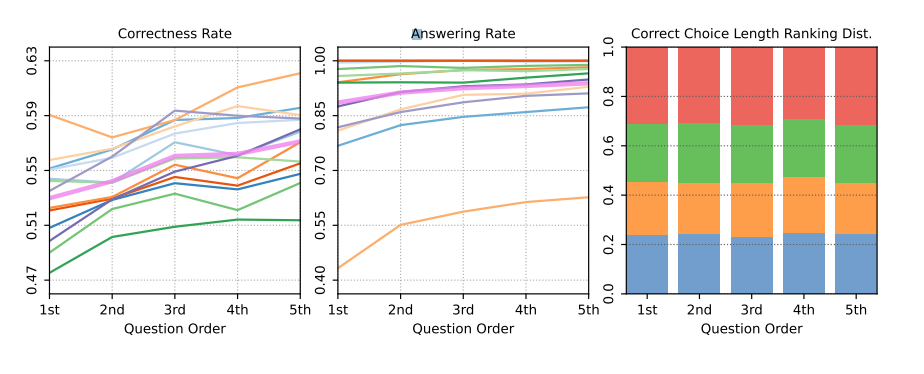
Using Current Questions for Warm-Up
If the model can “converge” when generating previous questions, can it do the same when generating current questions?
The author hypothesizes that longer questions are easier to answer. Therefore, the original question set was divided into 10 subsets based on length, and the accuracy and response rates of each automatic model were calculated for each subset. The results are shown in the figure below, with solid lines representing direct questions and dashed lines representing context questions.
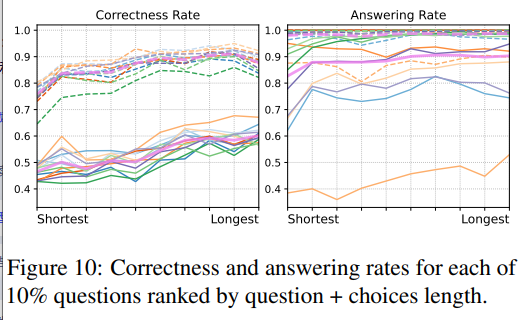
The trend is very clear: longer questions are answered more accurately.
Summary: Although the order and length of questions are influenced by multiple factors, the consistency of these two trends indicates that as generation progresses, the content becomes increasingly familiar and predictable to the models.
5. Shared Imaginative Behavior May Stem from Pre-Training Corpus
Given that the models studied are all instruction-tuned versions of LLMs after ChatGPT, the author also assessed whether other models in the table could achieve the same high accuracy.
The setup is as follows: for BERT, use [MASK] to replace the boxes and extract prediction probabilities; for other models, extract the next token prediction probabilities before the box.
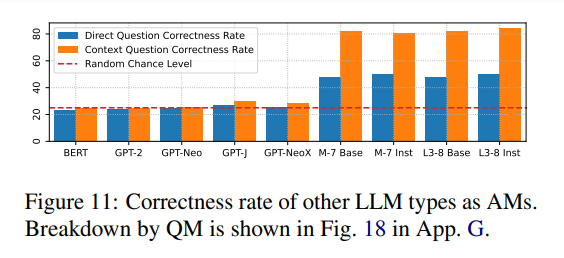
The results show that most pre-ChatGPT models performed poorly, while the M-7 and L3-8 base and fine-tuned versions (without chat templates) performed excellently, indicating that high accuracy does not require instruction tuning or chat templates.
Therefore, the author speculates that shared imaginative behavior stems from the pre-training corpus, which requires further investigation in future work.
6. Does Similar Shared Imagination Behavior Exist in Writing?
The author also explored whether similar shared imagination behavior exists in other content types, such as creative writing.
For direct questions, the model was asked to generate questions based on a fictional “complex plot about (the topic)”; ten abstract or concrete themes, such as “friendship” or “ancient empires,” were selected. For context questions, the model was first asked to write a short story before posing the questions.
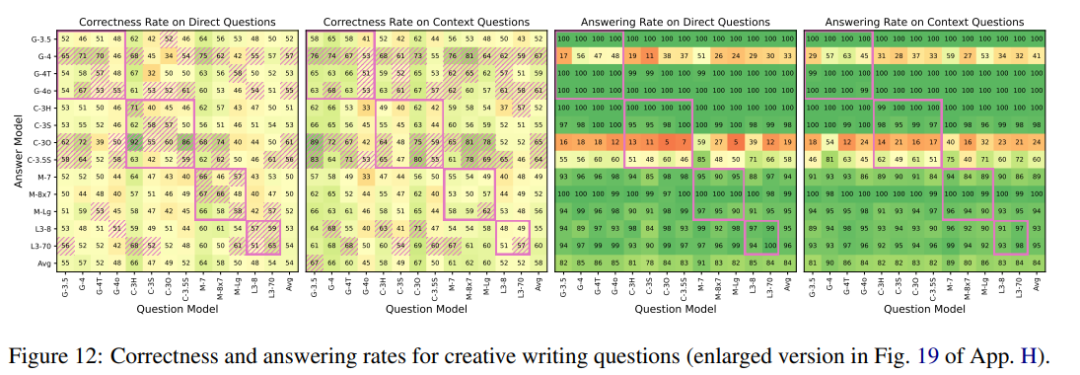
The results showed that although the questions seemed more “fantastical,” the models achieved higher accuracy than random guessing on direct questions, especially among models from the same family. The accuracy for context questions also improved, but to a lesser extent. Meanwhile, the response rates for both settings reached as high as 84%, demonstrating the models’ capability in addressing such questions.
Conclusion
This article proposes a fictional Q&A (IQA) task, revealing the intriguing behavior of models being able to answer purely fictional questions posed by each other with astonishingly high accuracy. These results uncover some similarities that models may acquire during the pre-training process.
This inevitably reminds the author that current LLMs have used a large amount of synthetic data while expanding the training data scale, which may further exacerbate the similarities among models, potentially not being a good thing for the long-term development of models.
While synthetic data is indeed valuable, there will inevitably come a day when it runs out, and the author looks forward to more advanced methods to solve this issue in the future!
