A word cannot be understood by a neural network; it needs to be converted into numbers before being fed into it. The most naive way is one-hot encoding, but it is too sparse and not effective. So we improve it by compressing one-hot into a dense vector.
The word2vec algorithm predicts words based on context, thus obtaining the word vector matrix.
The task of predicting words is merely a facade; what we need is not the predicted words, but the parameter matrix weights that are continuously updated through this prediction task.
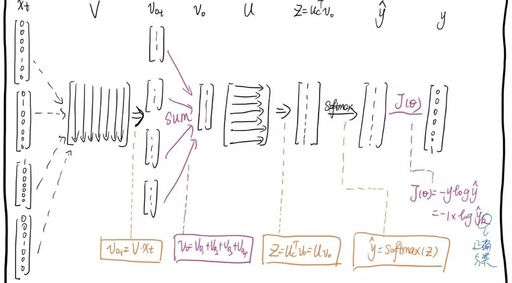
The prediction task is accomplished by a simple three-layer neural network, which has two parameter matrices V and U, where V∈RDh*|W| and U∈R|W|*Dh.
V is the matrix from the input layer to the hidden layer, also known as the look-up table (because the input is a one-hot vector, multiplying a one-hot vector by a matrix is equivalent to selecting a column from that matrix. Each column is considered as a word vector).
U is the matrix from the hidden layer to the output layer, also known as the word representation matrix (where each row is considered as a word vector).
The final word vector matrix is obtained by adding the two word vector matrices: V + UT, and each column represents a word vector.
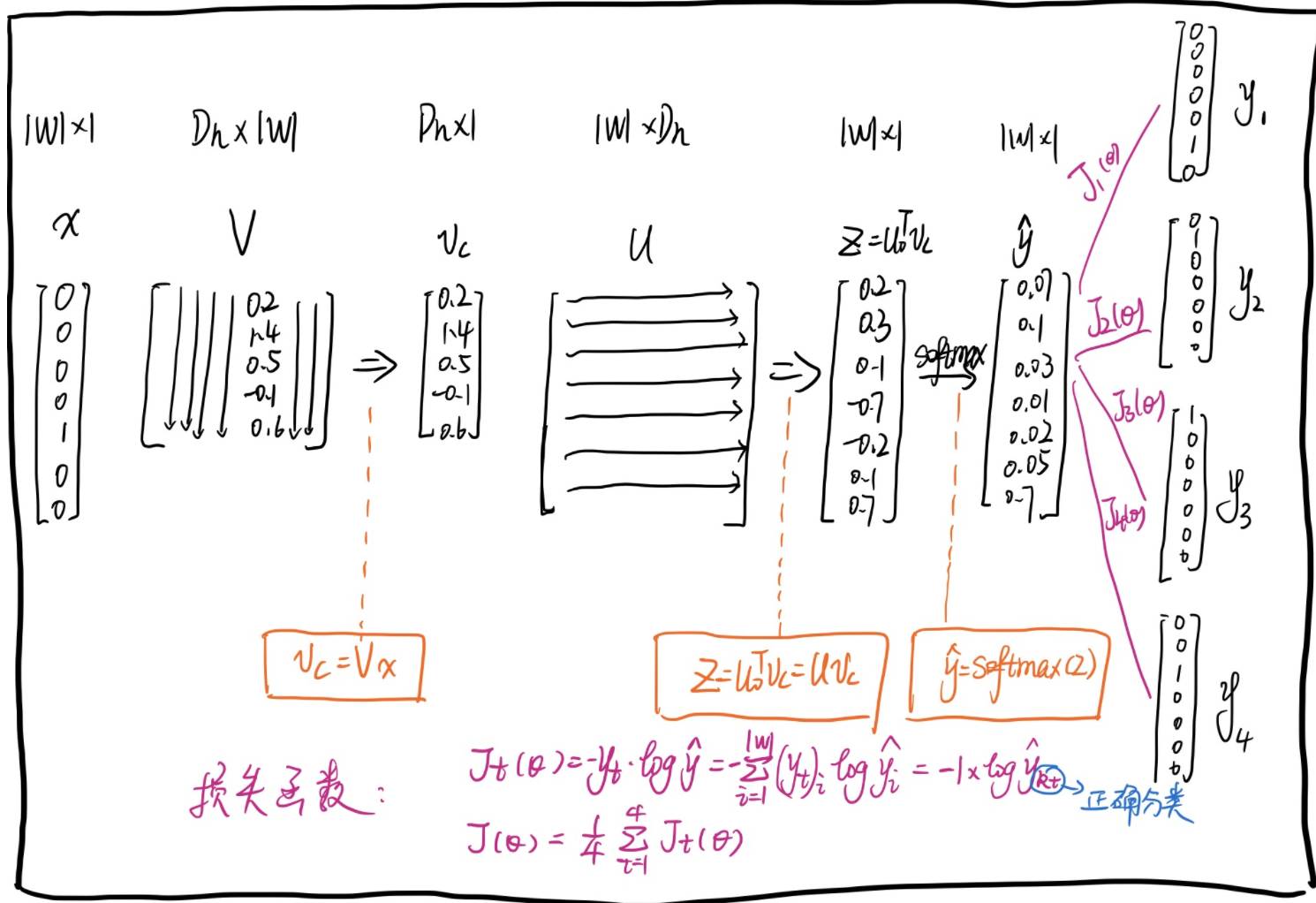
2.1. Skip-Gram
Training task: Predict context words based on the center word.
Input: A center word (center word, x∈R|W|*1)
Parameters: A look-up table V∈RDh*|W|, and a word representation matrix U∈R|W|*Dh

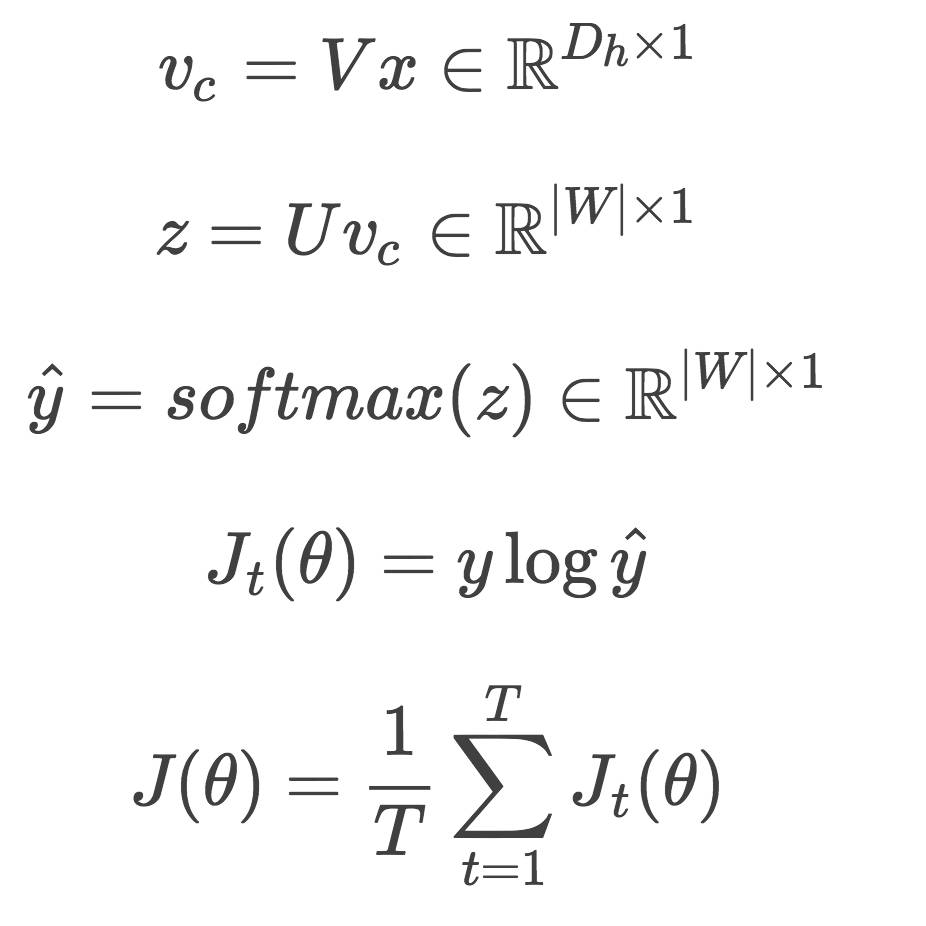
Skip-Gram Steps Diagram:
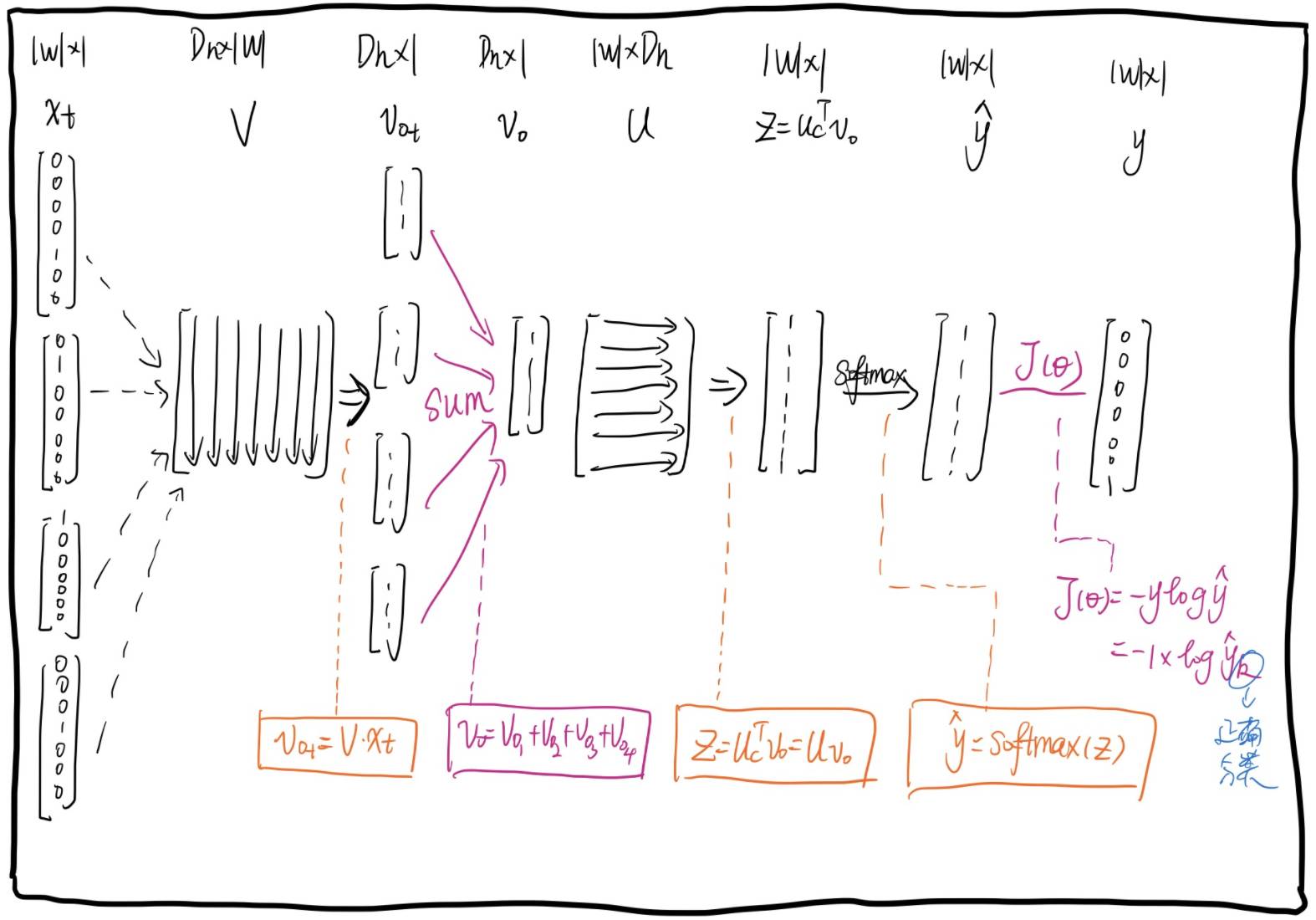
2.2. CBOW
Contrary to Skip-Gram, it trains word vectors by predicting the center word based on context words.

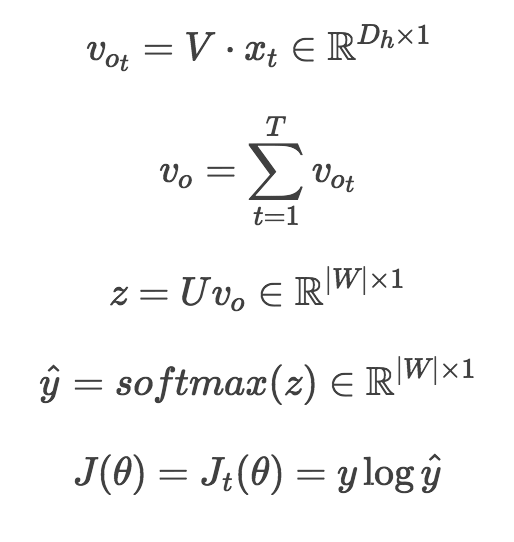
CBOW Steps Diagram:
Recommended Reading:
Selected Insights | Summary of Insights from the Last Six Months
Insights | Learning Notes from National Taiwan University’s Machine Learning Foundations Course 5 — Training versus Testing
Insights | Detailed Notes from MIT’s Linear Algebra Course [Lesson 1]
Welcome to follow our WeChat public account for learning and communication~

Welcome to join our group for discussions and learning
