
This article will cover the essence of ViT and the principles of ViT, as well as the applications of ViT to help you understand Vision Transformer |ViT.
Vision Transformer (ViT)
1. ViTessence
In the field of computer vision, Convolutional Neural Networks (CNNs) have long dominated due to their powerful local feature extraction capabilities. However, in recent years, the Vision Transformer (ViT) as an emerging model architecture has begun to demonstrate performance comparable to or even better than CNNs across multiple visual tasks.

CNN vs ViT
Development history of Transformers
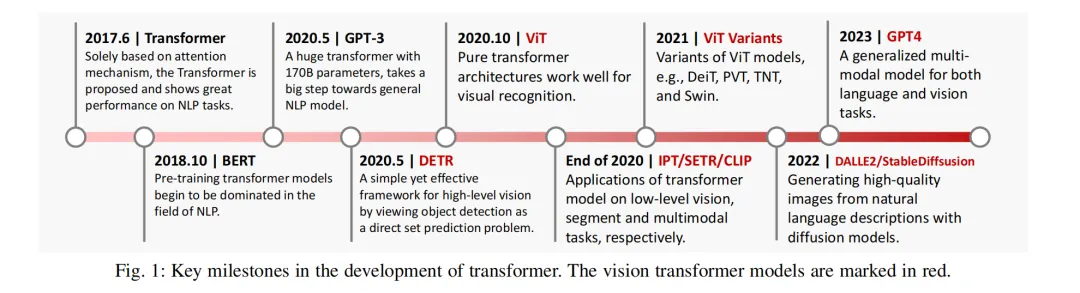
Origin of Transformers:
-
In 2017, Google proposed the Transformer model, a language model based on the Seq2Seq structure, which first introduced the Self-Attention mechanism, replacing RNN-based model structures.
-
The architecture of the Transformer includes an Encoder and Decoder, utilizing the Self-Attention mechanism to model global information, thereby addressing the long-distance dependency problem in RNNs.
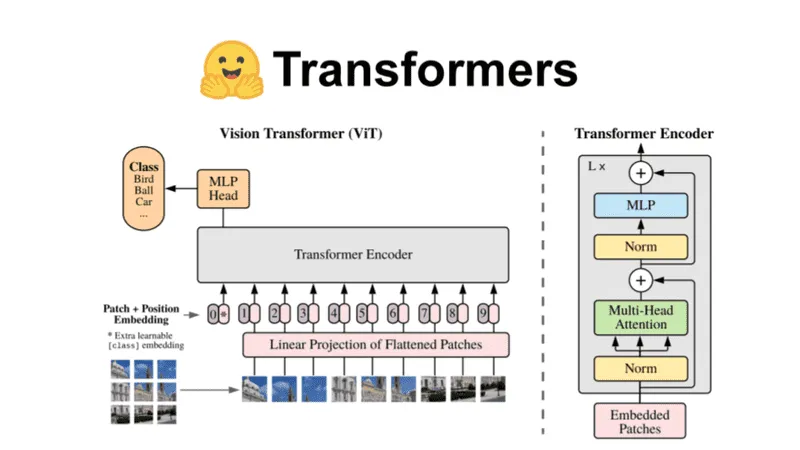
Emergence of ViT:
-
ViT employs the self-attention mechanism from the Transformer model to model image features, differing from CNNs that extract local features through convolutional and pooling layers.
-
The main Block structure of the ViT model is based on the Encoder structure of the Transformer, containing a Multi-head Attention structure.
Further Development of ViT:
-
With ongoing research, the architecture and training strategies of ViT have been further optimized and improved, achieving performance comparable to or even better than CNNs across various computer vision tasks.
-
Currently, ViT has become an important research direction in the field of computer vision and is expected to further replace CNNs as a mainstream method in the future.
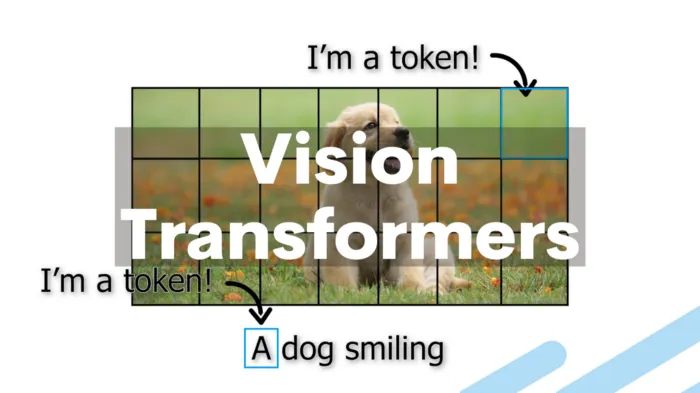
Image Patches:
-
ViT first splits the input image into multiple fixed-size image patches. -
These image patches are linearly embedded into fixed-size vectors, similar to word embeddings in NLP. -
Each image patch is treated as an independent “visual word” or “token” and is used for processing in subsequent Transformer layers.
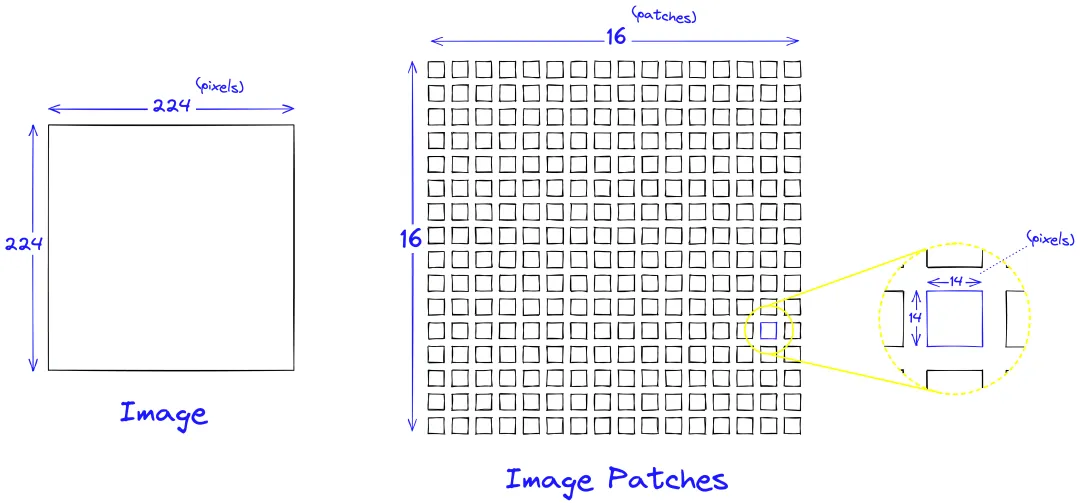
Image Patches
2. ViT Principles
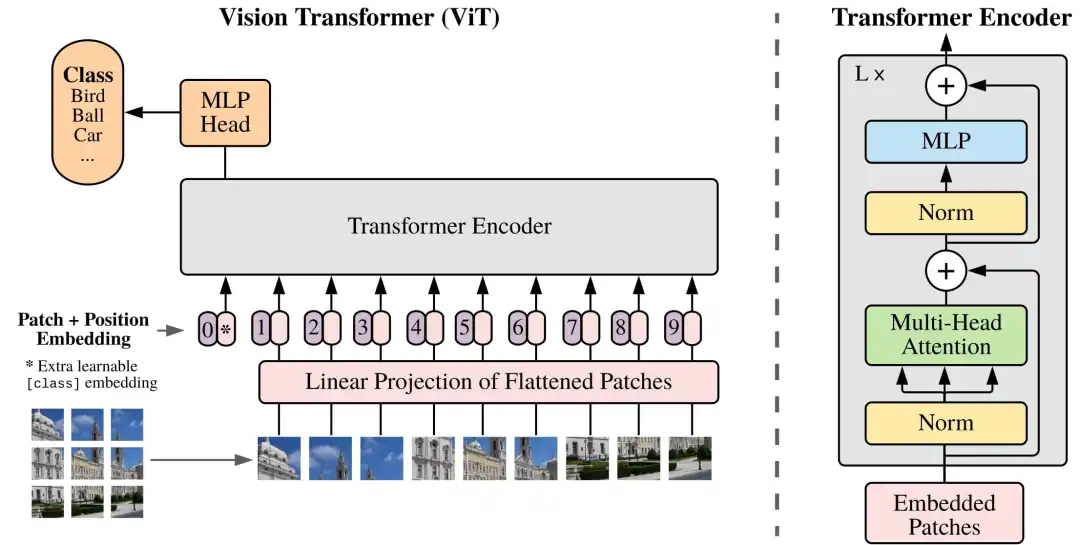
Architecture of ViT
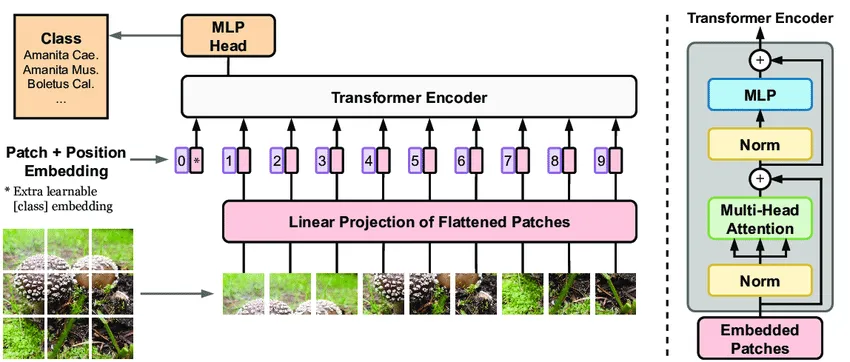
Core components of ViT:Patch Embeddings, Position Embeddings, Classification Token, Linear Projection of Flattened Patches, and Transformer Encoder.
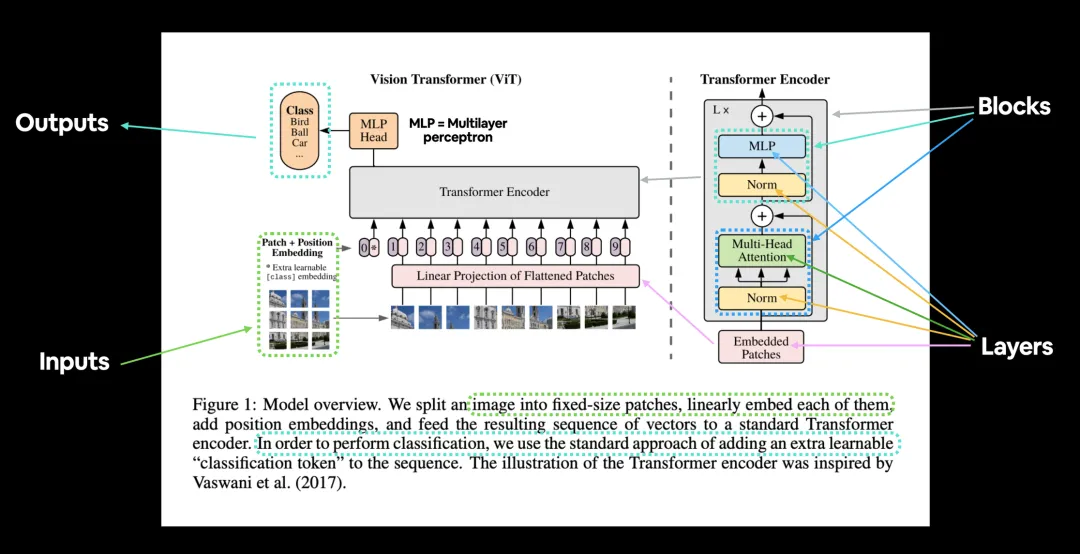
Core components of ViT
-
Patch Embeddings:As shown in the left half of the dashed line in the above image, we divide the image into fixed-size image patches (for example, a 9×9 image), and linearly expand them. -
Position Embeddings:Position embeddings are added to image patches to retain positional information. -
Classification Token:To complete the classification task, in addition to the nine image patches, we also add an additional learned block 0 in the sequence, called the Classification Token. -
Linear Projection of Flattened Patches:After segmenting the image into fixed-size patches, each patch is flattened into a one-dimensional vector and transformed into a fixed-dimensional embedding vector (patch embeddings) through a linear transformation (i.e., linear projection layer or embedding layer). -
Transformer Encoder:Composed of multiple stacked layers, each layer includes a Multi-head Self-Attention mechanism (MSA) and a fully connected feed-forward neural network (MLP block).
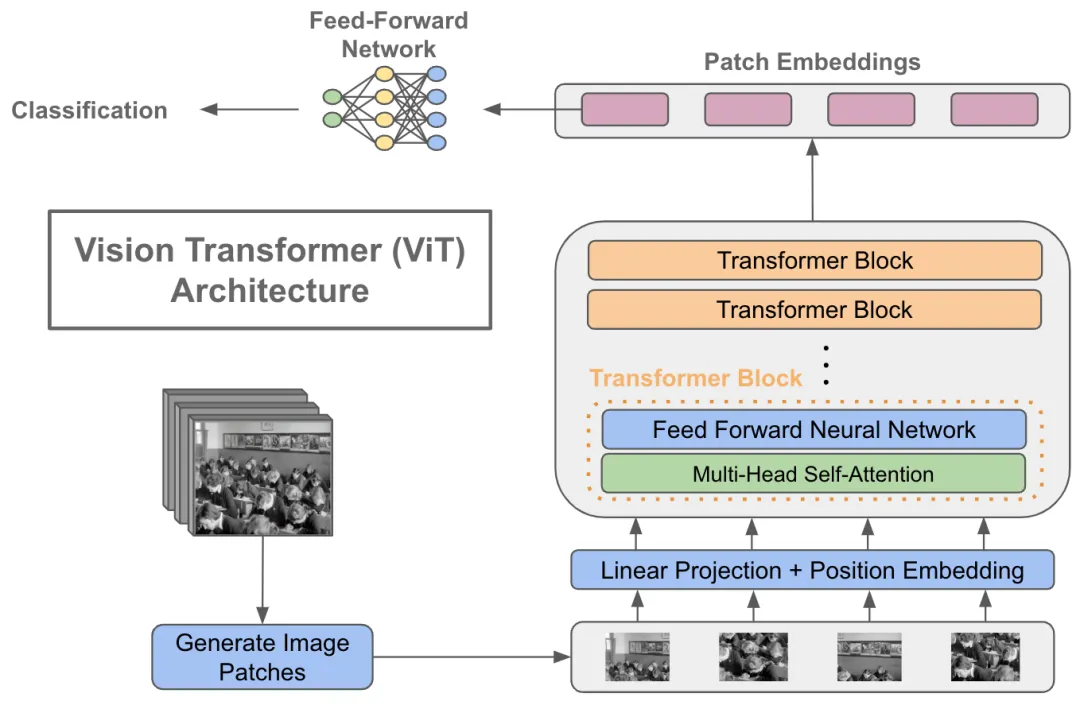
Transformer Encoder of ViT
Workflow of ViT:It segments the image into fixed-size patches, converts them into Patch Embeddings, adds positional encoding information, processes these embeddings through a Transformer encoder that includes multi-head self-attention and feed-forward neural networks, and finally uses the classification token for tasks such as image classification.

Workflow of ViT
3. Applications of ViT
Four types of Segmentation
-
Panoptic Segmentation Transformer: Considers the relationship between target objects and the global image context, directly outputting the final prediction set in parallel. This architecture efficiently handles multiple object instances and backgrounds, achieving effective completion of panoptic segmentation tasks.
-
Instance Segmentation Transformer: Treats the video instance segmentation task as a direct end-to-end parallel sequence decoding/prediction problem. It achieves efficient instance segmentation by predicting the mask sequence for each instance in the video. This method’s advantage is its ability to handle dynamically changing video content and output segmentation results for each instance in real time.
-
Semantic Segmentation Transformer: Utilizes the self-attention mechanism of Transformers to capture global contextual information, thereby improving the performance of semantic segmentation. By considering global information in the image, it can more accurately identify the categories of different areas and generate finer segmentation results.
-
Medical Image Segmentation Transformer: By predicting individual object instances, the Transformer improves the experimental information yield of data processing, making online monitoring experiments and closed-loop optimal experimental designs feasible. This is significant for medical diagnosis, treatment, and research.
Related Papers
-
“AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE”