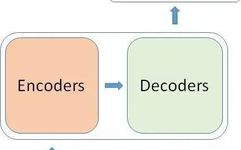
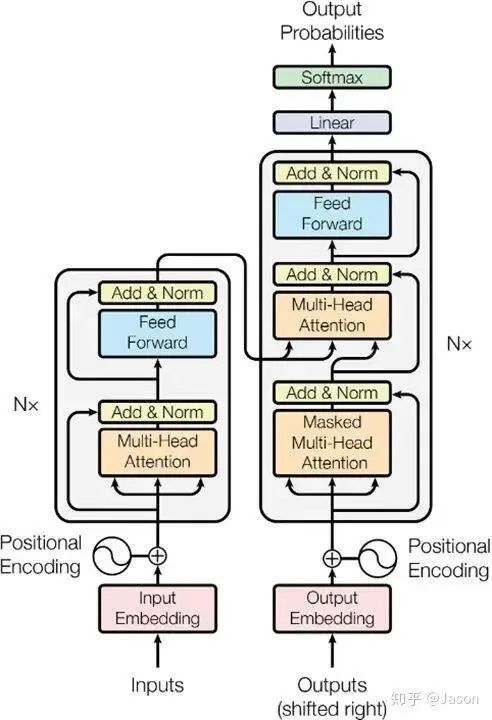
So what is a transformer?

So what is inside this black box?
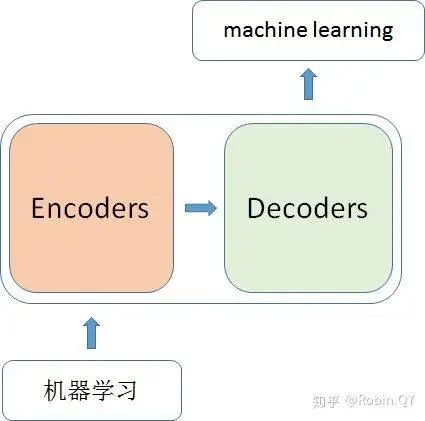
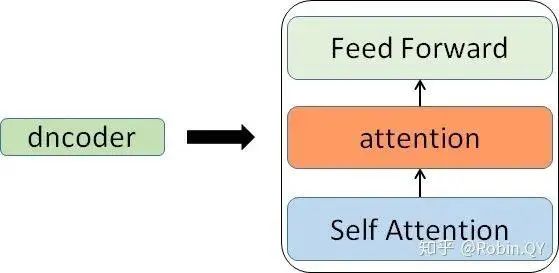
So what is inside the encoder and decoder?
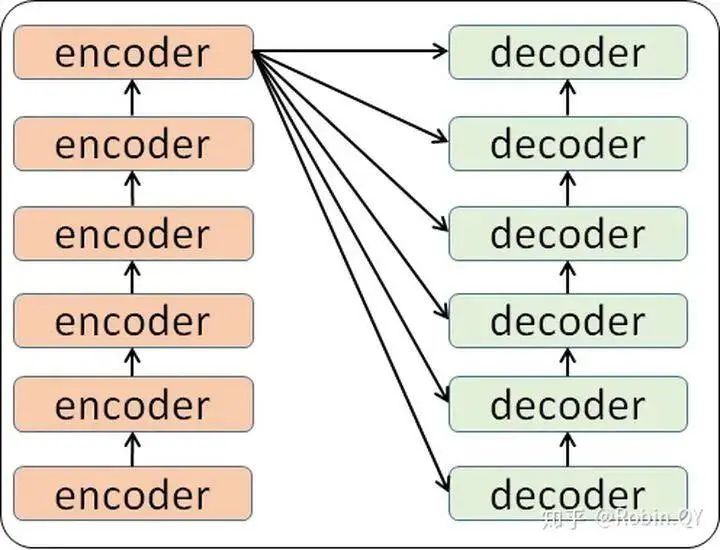
So you might ask, what is in each small encoder?
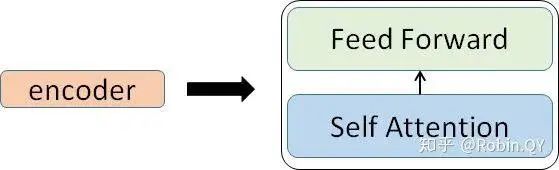
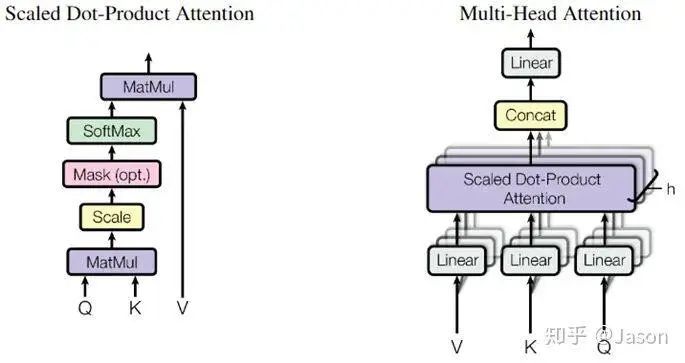
Let’s first take a look at what self-attention looks like.
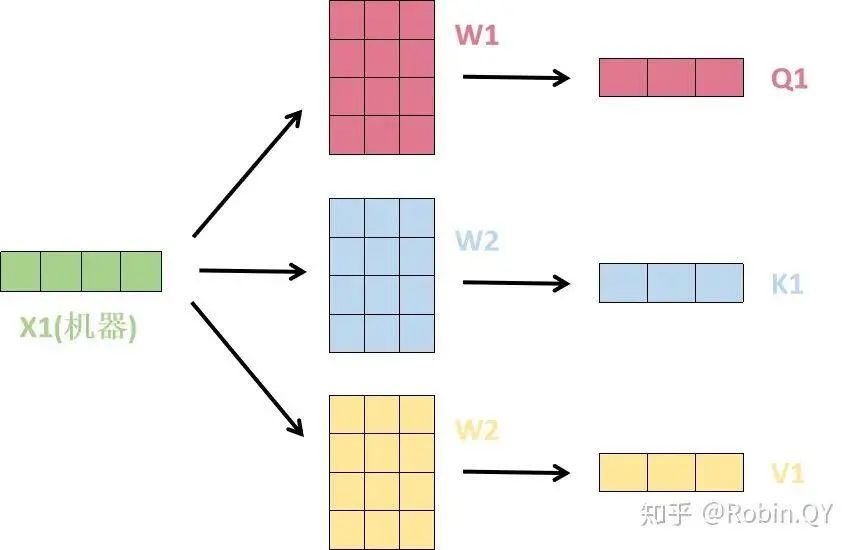
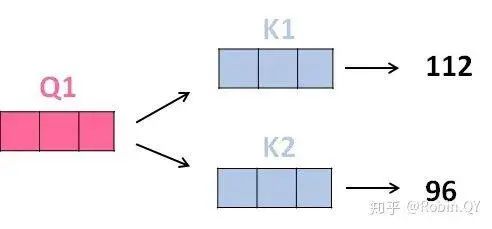
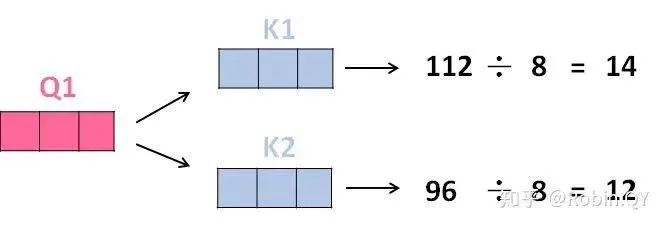
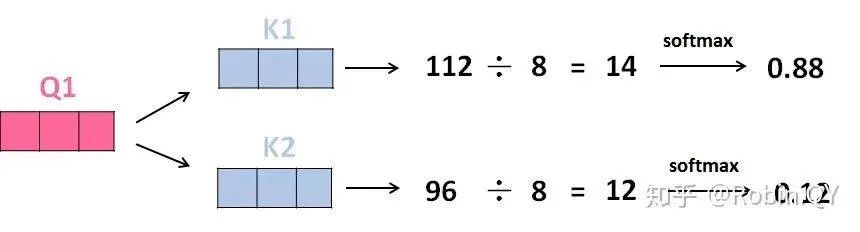
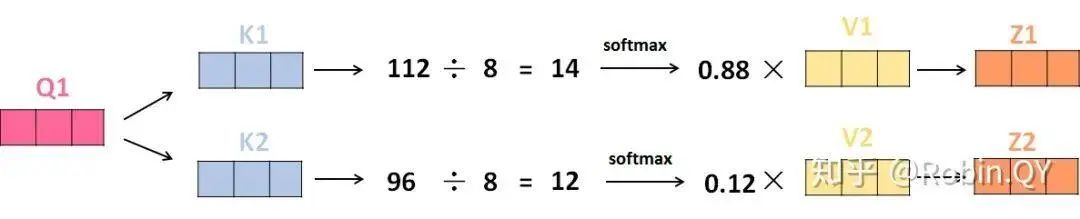

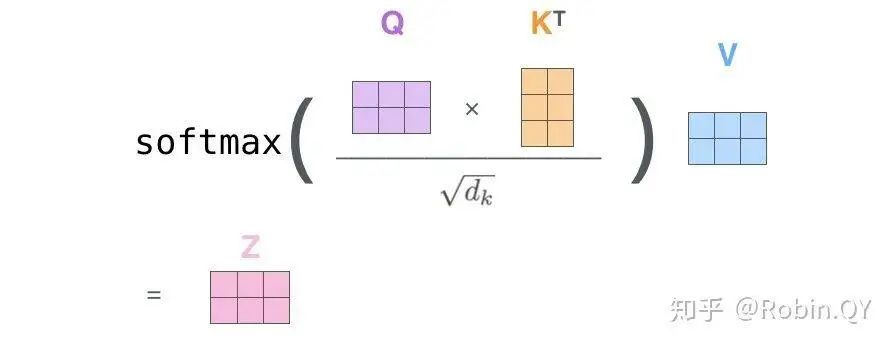
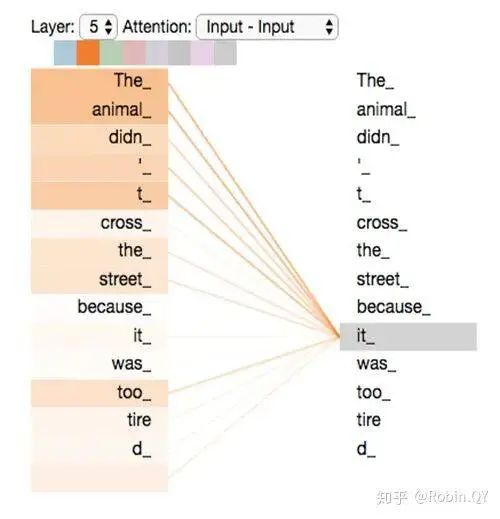
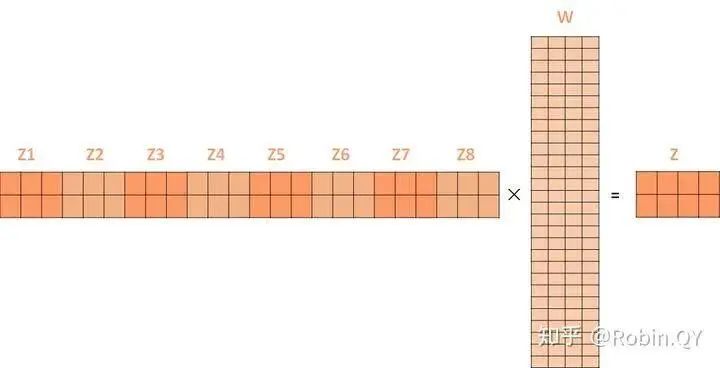
Does the self-attention layer end here?

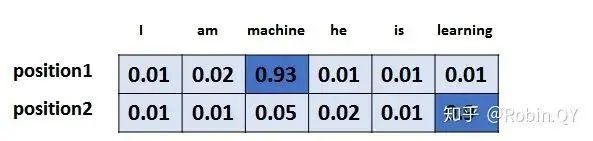
Assuming the vocabulary dimension is 6, the process for outputting the highest probability vocabulary is as follows:
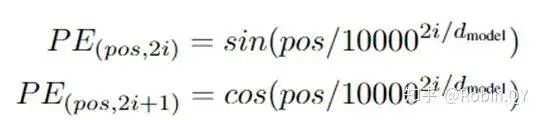
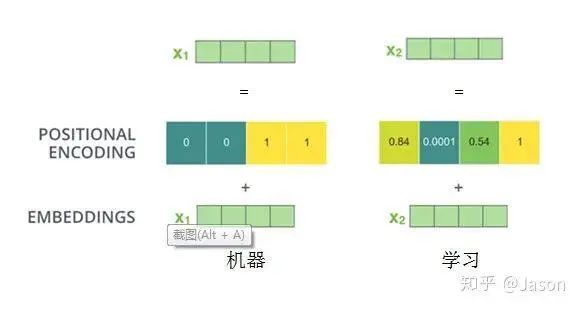
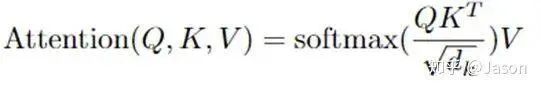
Editor / Zhang Zhihong
Reviewer / Fan Ruiqiang
Rechecker / Zhang Zhihong
Click below
Follow us
Read the original text