When constructing machine learning models, selecting the optimal model is an inevitable challenge. If you can correctly understand the meanings of training sets, validation sets, and test sets, as well as how to partition the dataset, you will have a macro understanding of how to build machine learning models and gain confidence in the optimal model you construct. This article clearly and understandably introduces the meanings of training sets, validation sets, and test sets, as well as how to partition the dataset.
1. Training Set
Training Set: The data samples used to build the model
The training set (Training data) is the dataset we use to build the model, such as the parameters w and b for univariate linear regression, and the weights w and biases b for neural networks.
2. Validation Set
The validation set provides an unbiased estimate of the machine learning model constructed from the training set. If the dataset only contains the training set without a validation set, the model constructed from the dataset will be biased, and the evaluation of the optimal model will be unreliable.
Unbiased meaning: The accuracy of the validation set (Validation data) is output multiple times and averaged; this average equals the true accuracy of the model.
The training set builds the model (obtaining the model parameters), while the validation set selects the optimal model (obtaining the optimal model parameters).
3. Test Set
The test set is used to test the model’s generalization ability. If the test accuracy is not high (the generalization ability is weak), then the optimal model constructed from the training and validation sets has failed.
The test set (Test data) is commonly used to compare the performance of different models. For example, in many Kaggle competitions, the initial phase only provides training and validation sets, and at the end of the competition, the test dataset is used to determine which model is better.
The test dataset is so important that in actual projects, we cannot randomly select the dataset; instead, we must first analyze the data and choose a test set that can represent all distributions of the data. Only then can the accuracy determine the gold standard for the model’s performance.
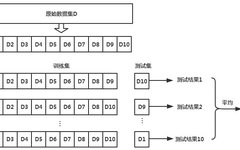
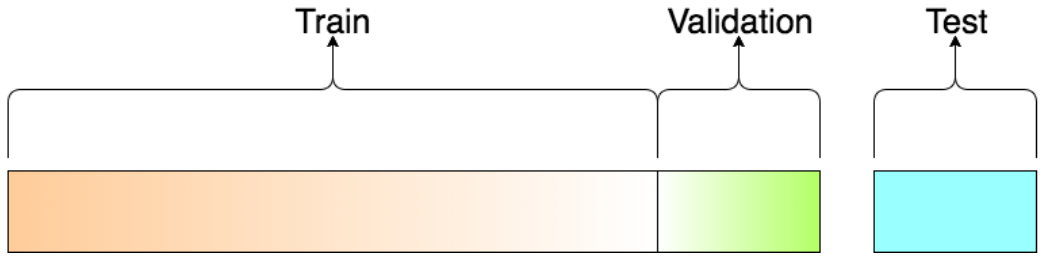
The dataset partitioning is shown in the figure below:
4. How to Partition the Dataset
The criteria for partitioning the dataset depend on two factors: (1) the sample size of the dataset, and (2) the machine learning model being trained.
Some models require a large dataset, so in this case, you need a larger training set to build the model.
If the model has fewer parameters, you can choose a smaller validation set sample because there are fewer model parameters to optimize; if the model has more parameters, you will need a larger validation set sample to optimize the model parameters.
Of course, if the chosen model has no parameters, then the validation set may also be unnecessary.
If the dataset is small and insufficient to partition into training, validation, and test sets, we adopt the cross-validation method to select the training and validation sets, because the model evaluated by the validation set is unbiased, and under the premise of a small dataset, the cross-validation method is also a practical approach.
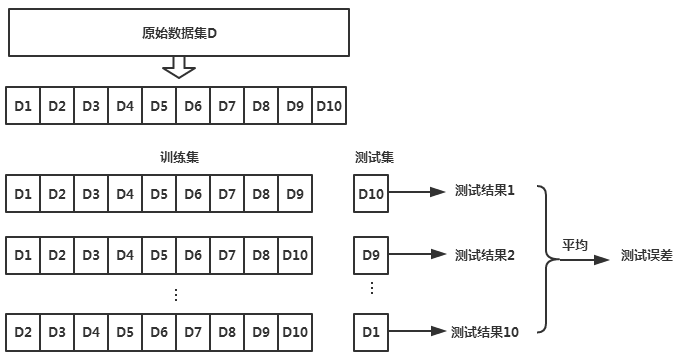
K-fold cross-validation method: The dataset is evenly divided into K datasets, with (K-1) datasets forming the training set, and the remaining dataset serving as the validation set. The accuracy of the validation set is output, and this process is repeated K times to obtain K validation set accuracies and average them. This average accuracy is used to select the optimal model parameters.
The principle diagram is shown below:
5. Summary
This article briefly introduces the meanings of training sets, validation sets, and test sets, as well as how to partition the dataset. The author also mentions the meaning of unbiased, as it explains why we need to partition the validation set and is the theoretical basis for the cross-validation method.
Feel free to scan the code to follow us:
