
Recently, researchers from Nanyang Technological University published a paper that describes the mathematical principles of convolutional networks. This paper explains the operations and propagation processes of convolutional networks from a mathematical perspective. It is very helpful for understanding the mathematical essence of convolutional networks and aids readers in implementing convolutional networks “from scratch” (without using pre-built libraries).
Paper link: https://arxiv.org/pdf/1711.03278.pdf
In this paper, we will explore the mathematical essence of convolutional networks from aspects such as convolution architecture, component modules, and propagation processes. Readers may already have a good understanding of the specific operations of convolutional networks. Beginners can first refer to the first part of the Capsule paper interpretation to understand the detailed convolution process. However, we generally do not focus on how convolutional networks are implemented mathematically. Since major deep learning frameworks provide concise APIs for convolutional layers, we can build various convolutional layers without needing mathematical expressions. We only need to focus on the tensor dimensions of the input and output of the convolution operation. Although this allows us to perfectly implement the network, our understanding of the mathematical essence and processes of convolutional networks remains unclear, which is the purpose of this paper.
Next, we will briefly introduce the main content of the paper and attempt to understand the mathematical processes of convolutional networks. Readers with a background can refer to the original paper for a deeper understanding. Additionally, we may be able to use the computations from this paper to implement a simple convolutional network without using hierarchical APIs.

Convolutional Neural Networks (CNNs), also known as ConvNets, are widely used in many tasks such as visual image processing and speech recognition. After the deep convolutional network was first applied by Krizhevsky et al. in the 2012 ImageNet Challenge, the architecture design of deep convolutional neural networks has attracted many researchers to contribute. This has also had a significant impact on the construction of deep learning architectures, such as TensorFlow, Caffe, Keras, and MXNet. Although the implementation of deep learning can be easily done through frameworks, the mathematical theories and concepts are very difficult to understand for beginners and practitioners. This paper will attempt to outline the architecture of convolutional networks and explain the mathematical derivations involving activation functions, loss functions, forward propagation, and backward propagation. In this paper, we use grayscale images as input information, with ReLU and Sigmoid activation functions to construct the non-linear properties of the convolutional network, and cross-entropy loss function to calculate the distance between predicted values and actual values. The architecture of this convolutional network includes one convolutional layer, pooling layer, and multiple fully connected layers.
2 Architecture
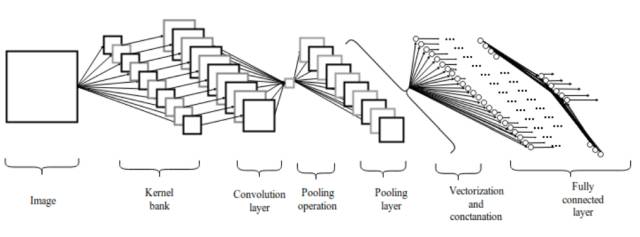
Figure 2.1: Convolutional Neural Network Architecture
2.1 Convolutional Layer
The convolutional layer consists of a set of parallel feature maps, which are formed by sliding different convolutional kernels over the input image and performing certain operations. Furthermore, at each sliding position, an element-wise multiplication and summation operation is performed between the convolutional kernel and the input image to project the information within the receptive field onto an element in the feature map. This sliding process can be referred to as stride Z_s, which is a factor that controls the size of the output feature map. The size of the convolutional kernel is much smaller than that of the input image and overlaps or acts in parallel on the input image. All elements in a feature map are computed using a single convolutional kernel, meaning that a feature map shares the same weights and biases.
However, using smaller convolutional kernels can lead to imperfect coverage and limit the learning algorithm’s capability. Therefore, we generally use zero-padding around the image, known as the Z_p process, to control the size of the input image. Using zero-padding around the image also controls the size of the feature map. During the training process of the algorithm, the dimensions of a set of convolutional kernels are generally (k_1, k_2, c), and these kernels will slide over a fixed-size input image (H, W, C). Stride and padding are important means of controlling the dimensions of the convolutional layer, thus producing feature maps that are stacked together to form the convolutional layer. The size of the convolutional layer (feature map) can be calculated using the following formula 2.1.
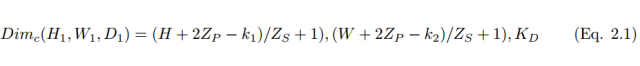
Where H_1, W_1, and D_1 are the height, width, and depth of a feature map, respectively; Z_p is the padding, and Z_s is the stride size.
2.2 Activation Function
The activation function defines the output of a neuron given a set of inputs. We pass the weighted sum of the linear network input values to the activation function for non-linear transformation. Typical activation functions are based on conditional probabilities, returning either 1 or 0 as output values, i.e., op {P(op = 1|ip) or P(op = 0|ip)}. When the network input information ip exceeds a threshold, the activation function returns a value of 1 and passes the information to the next layer; if the network input ip is below the threshold, it returns a value of 0 and does not pass the information. The activation function determines whether the neuron should be activated based on the separation of relevant and irrelevant information. The higher the network input value, the greater the activation. Different types of activation functions are applied differently, and some commonly used activation functions are shown in Table 1.
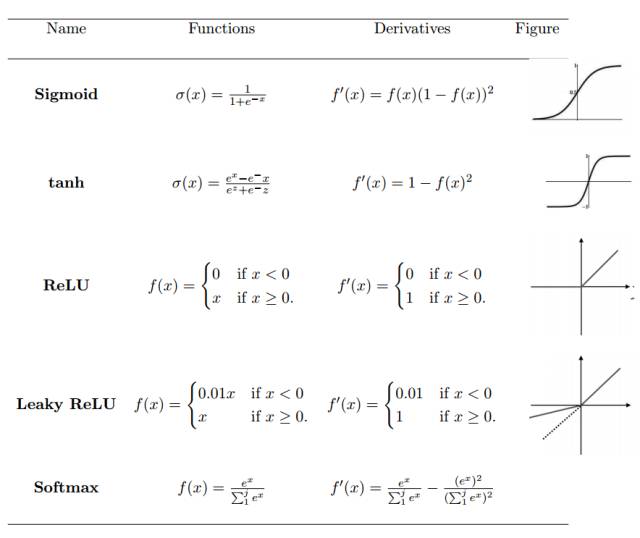
Table 1: Non-linear Activation Functions
2.3 Pooling Layer
The pooling layer is a down-sampling layer that combines the output of a cluster of neurons from the previous layer with a single neuron from the next layer. Pooling operations are performed after non-linear activation, where the pooling layer helps reduce the number of parameters and avoid overfitting. It can also serve as a smoothing technique to eliminate unwanted noise. The most commonly used pooling method is simple max pooling, while in some cases, we also use average pooling and L2 norm pooling operations.
When using the number of convolutional kernels D_n and stride size Z_s to perform pooling operations, its dimensions can be calculated using the following formula:
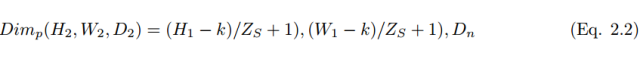
2.4 Fully Connected Layer
After the pooling layer, the three-dimensional pixel tensor needs to be converted into a single vector. These vectorized and concatenated data points are then fed into a fully connected layer for classification. The function of the fully connected layer is the weighted sum of features plus a bias term, fed into the activation function. The architecture of the convolutional network is shown in Figure 2. This type of local connection architecture surpasses traditional machine learning algorithms in image classification problems.
2.5 Loss or Cost Function
The loss function maps the events of one or more variables to a real number associated with some cost. The loss function is used to measure the model performance and the inconsistency between actual values y_i and predicted values y hat. Model performance increases as the loss function value decreases.
If the output vector of all possible outputs is y_i = {0, 1} and the event x has a set of input variables x = (xi , x2 . . . xt), then the mapping from x to y_i is as follows:
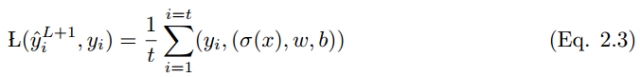
Where L(y_i hat , y_i) is the loss function. Many types of loss functions are applied differently, and some of them are listed below.
2.5.1 Mean Squared Error
Mean squared error, or squared loss function, is commonly used in linear regression models to evaluate performance. If y_i hat is the output value of t training samples and y_i is the corresponding label value, the mean squared error (MSE) is:
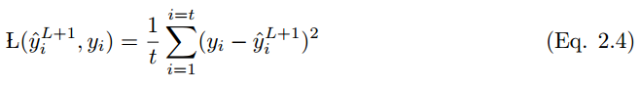
The downside of MSE is that when it occurs alongside the Sigmoid activation function, it may lead to slow learning speed (slower convergence).
Other loss functions described in this section include Mean Squared Logarithmic Error, L_2 Loss, L_1 Loss, Mean Absolute Error, and Mean Absolute Percentage Error.
2.5.7 Cross-Entropy
The most commonly used loss function is the cross-entropy loss function, as shown below. If the output y_i has a probability of p in the training set label y,
 and the probability of y_i not being in the training set label y is
and the probability of y_i not being in the training set label y is  . The expected label is y, thus:
. The expected label is y, thus:
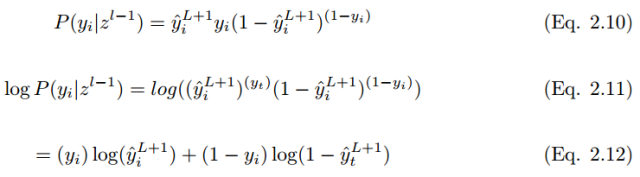
To minimize the cost function,
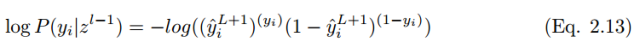
In the case of i training samples, the cost function is:
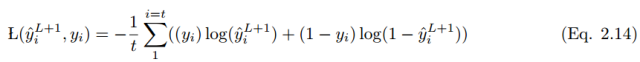
3 Learning of Convolutional Networks
3.1 Feedforward Inference Process
The feedforward propagation process of a convolutional network can be mathematically explained as multiplying the input values by randomly initialized weights, then adding an initial bias term to each neuron, and finally summing all products of all neurons to feed into the activation function, which performs a non-linear transformation on the input values and outputs the activation results.
In a discrete color space, images and convolutional kernels can be represented as three-dimensional tensors of (H, W, C) and (k_1, k_2, c), where m, n, and c represent the pixel at row m and column n of the c-th image channel. The first two parameters represent spatial coordinates, while the third parameter represents color channels.
If a convolutional kernel slides over a color image, the multi-dimensional tensor convolution operation can be expressed as:
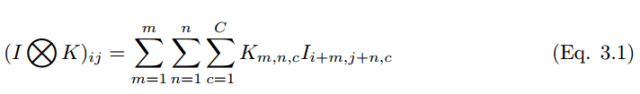
The convolution process can be denoted by the symbol ⓧ. For grayscale scalar images, the convolution process can be represented as,
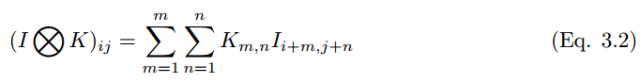
A convolutional kernel k (denoted as k_p,q|u,v hereafter) slides to the position of image I_m,n with a stride of 1 and with padding. The feature map C_p,q|m,n of the convolution layer can be calculated as
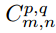
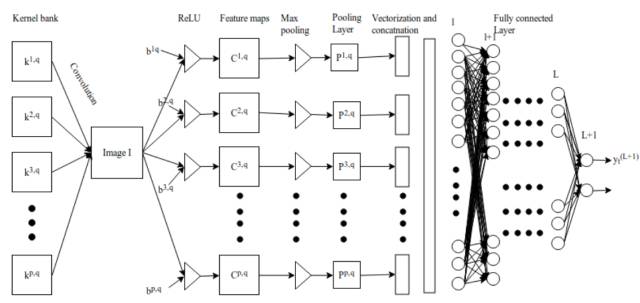
Figure 3.1: Convolutional Neural Network
After performing the convolution, we need to use a non-linear activation function to obtain the feature map:
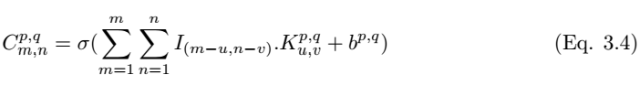
Where σ is the ReLU activation function. The pooling layer P_p,q|m,n can be constructed by selecting the maximum value in the convolution layer at m,n, and the construction of the pooling layer can be expressed as,

The output of the pooling layer P^p,q can be concatenated into a vector of length p*q, and then we can feed this vector into the fully connected network for classification. Subsequently, the vectorized data points from layer l-1 can be calculated using the following equation:

Long vectors are fed from layer l to the fully connected network at layer L+1. If there are L fully connected layers and n neurons, then l can represent the first fully connected layer, L represents the last fully connected layer, and L+1 is the classification layer shown in Figure 3.2. The forward propagation process in the fully connected layer can be expressed as:
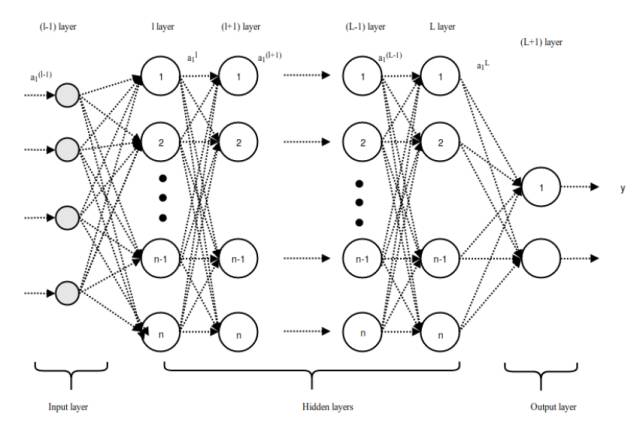
Figure 3.2: Forward Propagation Process in Fully Connected Layer
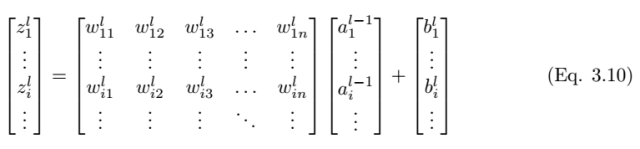
As shown in Figure 3.3, we consider a single neuron (j) in the fully connected layer l. The input value a_l-1,i is weighted by the weights w_ij and summed with the bias term b_l,j. Then we feed the input value z_l,i of the last layer into the non-linear activation function σ. The input value of the last layer can be calculated using the following equation,
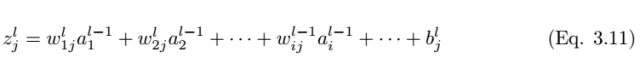
Where z_l,i is the input value of the activation function of neuron j in layer l.

Thus, the output of layer l is

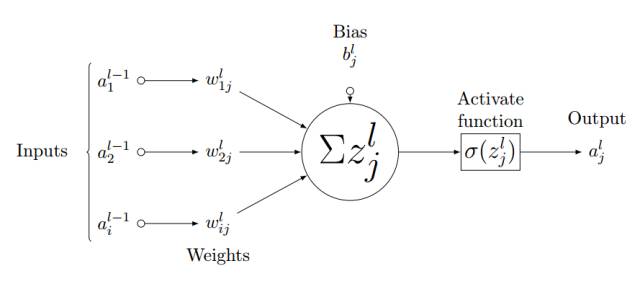
Figure 3.3: Forward Propagation Process of Neuron j in Layer l

Where a^l is

And W^l is

Similarly, the output value of the last layer L is

Where
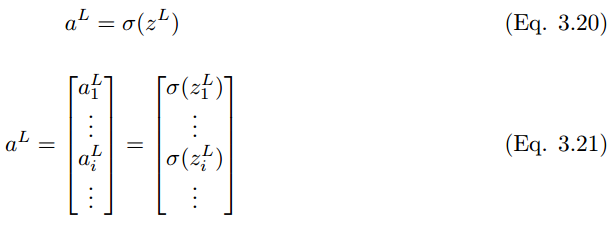
Expanding these to the classification layer, the final output prediction value y_i hat of neuron unit (i) in layer L + 1 can be expressed as:
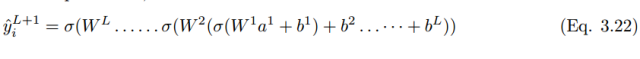
If the prediction value is y_i hat and the actual label value is y_i, the performance of the model can be calculated using the following loss function equation. According to Eqn.2.14, the cross-entropy loss function is:
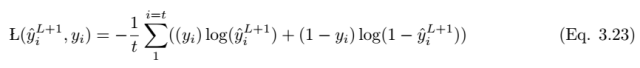
This is a brief overview of the mathematical process of forward propagation. This paper also emphasizes the mathematical process of backward propagation; however, due to space limitations, we will not present it in this article. Interested readers can refer to the original paper.
4 Conclusion
This article provides an overview of the architecture of convolutional neural networks, including different activation functions and loss functions, while detailing the steps of feedforward and backward propagation. For mathematical clarity, we use grayscale images as input information. The stride value of the convolutional kernel is set to 1, with padding applied. The non-linear transformations of the intermediate and final layers are completed using ReLU and sigmoid activation functions. The cross-entropy loss function is used to measure model performance. However, a significant amount of optimization and regularization steps are required to minimize the loss function, increase the learning rate, and avoid overfitting of the model. This paper attempts to consider only the typical convolutional neural network architecture devised with gradient descent optimization.
Paper link: https://arxiv.org/pdf/1711.03278.pdf