This article introduces one of the most basic and also the “laziest” algorithms in machine learning—KNN (k-nearest neighbor). Do you know why it is considered the laziest?
01|Algorithm Overview:
KNN is short for k-nearest neighbor, which refers to the K closest points. This algorithm is commonly used to solve classification problems. The specific principle of the algorithm is to first find the K values closest to the value A to be classified, and then determine which category the majority of these K values belong to, thus classifying value A into that category.
This is actually similar to how we evaluate people in real life. If you want to know what kind of person someone is, you just need to find the K people who are closest (or have the best relationships) to them, and then see what kind of people those K individuals are to make a judgment about them.
02|Three Key Elements of the Algorithm:
Based on the principle of this algorithm, we can break it down into three parts: the first part is to decide the value of K, which means determining how many surrounding values to find; the second part is the calculation of distance, i.e., finding the K closest values; and the third part is determining the classification rule, which is the standard by which we judge which category it belongs to.
1. Choosing the K value
The choice of K value will have a significant impact on the results of the KNN algorithm. Below is a simple example to illustrate this: In the figure below, which class should the green circle be assigned to, the red triangle or the blue square? If K=3, since the red triangle accounts for 2/3, the green circle will be assigned to the red triangle class. If K=5, since the blue square accounts for 3/5, the green circle will be assigned to the blue square class.
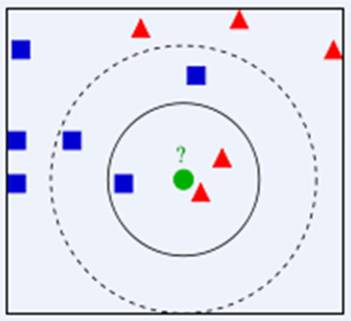
Figure 2.1—Source from the internet
As you can see, the choice of K value will directly affect the evaluation results. If the K value is chosen too large, it is equivalent to predicting using training instances from a larger domain. It might seem that more data could lead to more accuracy, but in reality, this is not the case. If you want to obtain a larger K value, you will need to expand the distance further, and the prediction accuracy will naturally decline.
Using the example of judging what kind of person someone is, if you choose a larger K value, such as the entire class, and then predict what someone in that class is like based on everyone in that class, it is obviously inaccurate.
If the K value is chosen too small, these could very well be exceptions, which will also affect the prediction results.
Too large is not good, and too small is also not good. So what should we do? The simplest and most effective method is to try. In our previous article, we mentioned that one method for model selection is cross-validation. We can also use cross-validation when selecting the K value.
2. Measuring Distance
When we evaluate the closeness of relationships between people, there is no quantifiable relationship; we can only use some words to describe the closeness of two people’s relationships, such as best friends, roommates, classmates.
However, in statistical learning, when we evaluate the closeness between two entities, there is a quantifiable measure, which we use as Euclidean distance.
Euclidean distance, also known as Euclidean distance, refers to the actual distance between two points in m-dimensional space.
-
The Euclidean distance between two points a(x1,y1) and b(x2,y2) in a two-dimensional plane:
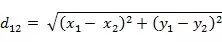
-
The Euclidean distance between two points a(x1,y1,z1) and b(x2,y2,z2) in three-dimensional space:
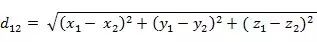
-
The Euclidean distance between two n-dimensional vectors a(x11,x12,…,x1n) and b(x21,x22,…,x2n):
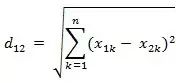
It can also be expressed in vector operation form:
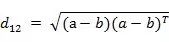
Of course, we can also use other distances to measure the closeness of two entities, such as Manhattan distance (doesn’t that sound impressive?). For more details, click: https://wenku.baidu.com/view/ebde5d0e763231126edb1113.html
3. Determining Classification Rules:
Currently, we use the majority voting classification rule, which means the category of the majority of the K closest values is the category of the value to be predicted.
04|Algorithm Steps:
-
Collect data: Find the text data to be trained.
-
Prepare data: Use Python to parse the text file.
-
Analyze data: Perform some statistical analysis on the data for a basic understanding.
-
Train algorithm: KNN does not have this step, which is why it is called the laziest algorithm.
-
Test algorithm: Use cross-validation to test the algorithm with the provided data.
-
Apply algorithm: Directly apply the algorithm with a high accuracy rate in practice.
05|Classifying Unknown Movies Using Python:
1. Background:
Assuming that the difference between romantic movies and action movies can be determined by the number of fight scenes and the number of kisses, below are some movie categories along with their corresponding kiss and fight counts (training dataset).
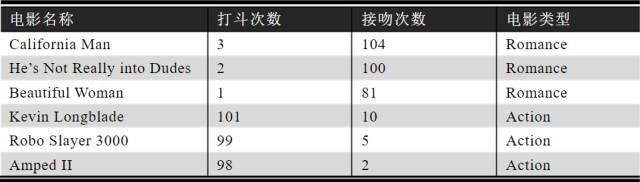
Table 6-1: Source from the internet
Now there is a movie A, with 18 fight scenes and 90 kisses, and we need to use the KNN algorithm to predict which category this movie belongs to.
2. Prepare data
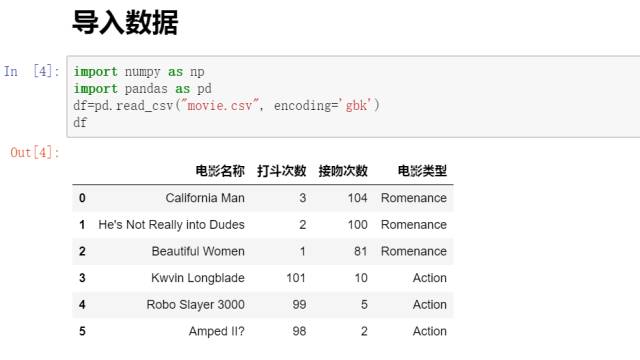
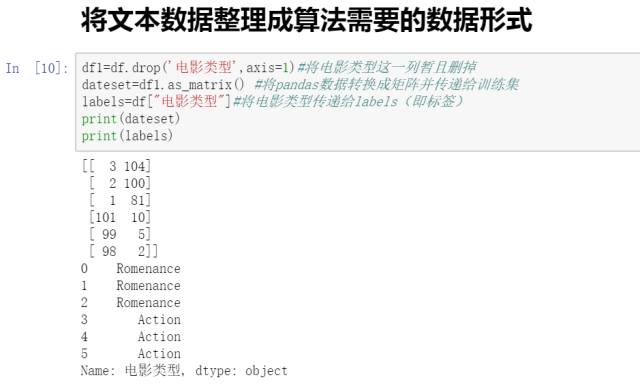
3. Analyze data
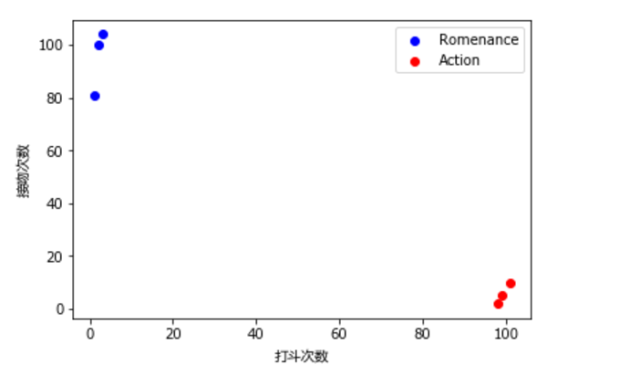
4. Test algorithm
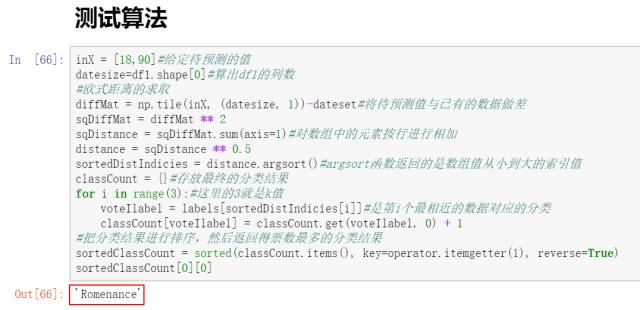
Through testing, we conclude that if a movie has 18 fight scenes and 90 kisses, it can be classified as a romantic movie.
5. Apply algorithm:
By modifying the inX value, we can directly determine the type of the movie.
06|Conclusion:
Some knowledge points involved in the Python implementation process above:
-
Converting pandas data to numpy, df.matrix()
-
Matplotlib Chinese display garbled problem
-
List comprehensions
-
np.tile() function
-
np.sum() function
-
np.argsort() function
-
dict.get() method
-
dict.items() method
-
operator.itemgetter() function