

Introduction
The development of large language models (LLMs) is advancing rapidly, with each major update potentially bringing significant improvements in performance and extending application scenarios. In this context, the latest Qwen2.5 series models released by Alibaba have garnered widespread attention. This technical report provides a detailed overview of the development process, innovations, and performance of Qwen2.5, showcasing its latest advancements in the field of natural language processing.
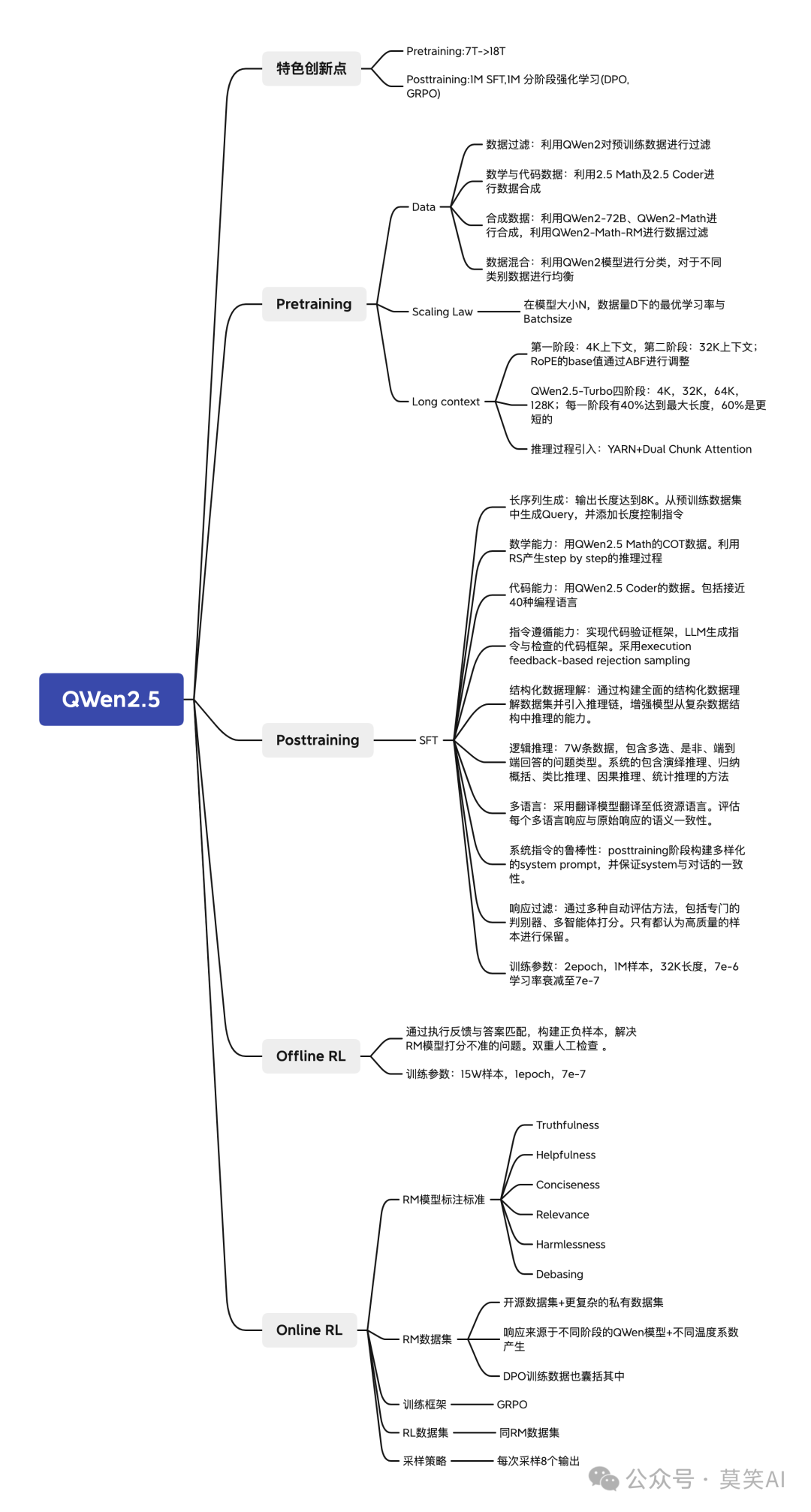
The core innovations of the Qwen2.5 series models mainly lie in two aspects: pre-training and post-training. During the pre-training phase, the research team expanded the training data scale from 7 trillion tokens to 18 trillion tokens, laying a solid foundation for the model’s knowledge acquisition and understanding capabilities. In the post-training phase, researchers employed complex techniques including supervised fine-tuning (SFT) with 1 million samples and staged reinforcement learning (including offline learning DPO and online learning GRPO), significantly enhancing the model’s alignment with human preferences and improving capabilities in long text generation and structured data analysis.
This article will delve into the development process of the Qwen2.5 model, including its innovative methods during the pre-training and post-training phases, as well as its performance across various benchmark tests. Through this report, we can glimpse the forefront of current large language model technology development and understand how Qwen2.5 stands out among numerous competitors, becoming an important force in advancing natural language processing technology.
The structure of the article is as follows:
Innovations in the Pre-training Phase
Breakthroughs in Data Processing
Qwen2.5 has several significant innovations in the processing of pre-training data, greatly enhancing the quality and diversity of the training data.
Intelligent Data Filtering
The research team cleverly utilized the Qwen2 model to intelligently filter pre-training data. This method not only improved data quality but also enhanced the model’s ability to handle multilingual data. Through this self-iterative approach, Qwen2.5 can better identify and retain high-quality training samples while effectively filtering out low-quality data.
Incorporation of Domain-Specific Data
Another highlight of Qwen2.5 is its incorporation of high-quality samples from Qwen2.5 Math and Qwen2.5 Coder. This data covers high-quality samples in mathematics and programming fields, greatly enhancing the model’s capabilities in these two critical areas. The introduction of this specialized data allows Qwen2.5 to excel at solving mathematical problems and programming tasks.
High-Quality Synthetic Data
The research team also generated high-quality synthetic data using the Qwen2-72B and Qwen2-Math models. Notably, they used the Qwen2-Math-RM model to further filter these synthetic data, ensuring the quality and relevance of the synthetic data. This method not only expanded the scale of the training data but also ensured high quality and diversity of the data.
Intelligent Data Mixing
To balance different types of data, researchers used the Qwen2 model to classify data and then balanced the processing of different categories of data. This method ensures that the model can learn from various types of data, avoiding bias caused by an overabundance of data in certain areas.
Breakthrough Scaling Laws
Another important innovation of Qwen2.5 lies in its application of scaling laws. The research team extensively studied the optimal learning rates and batch sizes (Batch Size) under different model sizes (N) and data volumes (D). This method allows researchers to find the best training parameters for models of various sizes, achieving a balance between training efficiency and model performance.
Innovations in Long Context Processing
Qwen2.5 also has significant breakthroughs in handling long contexts:
-
Multi-Stage Training: Model training is divided into two stages, first training at a 4K context length, then extending to 32K. This progressive approach allows the model to gradually adapt to longer contexts.
-
RoPE Base Value Adjustment: By adjusting the RoPE base value using ABF technology, the model’s ability to process long sequences is further enhanced.
-
Innovations in Qwen2.5-Turbo: This special version adopts a four-stage training strategy (4K, 32K, 64K, 128K), ensuring that 40% of the data reaches maximum length, while 60% consists of shorter sequences. This balanced approach allows the model to perform excellently on various input lengths.
-
Optimization in the Inference Phase: The introduction of YARN and Dual Chunk Attention technologies further enhances the model’s ability to handle long sequences in practical applications.
These innovations enable Qwen2.5 to excel in handling long texts and complex contexts, significantly expanding the model’s application scenarios.
Optimizations in the Post-Training Phase
The post-training phase is a key link in enhancing the performance of the Qwen2.5 model. The research team employed a series of innovative methods during this phase, including complex supervised fine-tuning (SFT) and multi-stage reinforcement learning.
Innovations in Supervised Fine-Tuning (SFT)
Enhancements in Long Sequence Generation
Qwen2.5 has breakthrough improvements in output length, increasing it to 8K tokens. The research team cleverly generates queries from the pre-training dataset and adds length control instructions, enabling the model to generate longer and more coherent texts. This improvement greatly enhances the model’s performance in long text generation tasks.
Enhancements in Mathematical Abilities
Researchers utilized Qwen2.5 Math’s chain of thought (CoT) data and generated a step-by-step reasoning process using rejection sampling. This method not only improves the model’s mathematical reasoning abilities but also allows it to clearly demonstrate problem-solving steps.
Enhancements in Programming Abilities
Qwen2.5 integrates data from Qwen2.5 Coder, covering nearly 40 programming languages. This extensive language coverage enables the model to excel in various programming tasks, significantly enhancing its application potential in software development.
Optimization of Instruction Following Ability
The research team implemented an innovative code verification framework, where the LLM not only generates instructions but also generates corresponding checking code frameworks. By executing feedback rejection sampling, it ensures that the model can accurately understand and execute various instructions.
Enhancements in Structured Data Understanding
By constructing a comprehensive structured data understanding dataset and introducing reasoning chains, Qwen2.5 significantly improves its ability to infer and extract information from complex data structures. This improvement makes the model more adept at handling structured data such as tables and JSON.
Enhancements in Logical Reasoning Abilities
Researchers constructed a diverse dataset containing 70,000 data points, covering multiple-choice, true/false, and open-ended questions. These questions systematically include various reasoning methods such as deductive reasoning, inductive generalization, analogical reasoning, causal reasoning, and statistical reasoning, comprehensively enhancing the model’s logical thinking abilities.
Enhancements in Multilingual Abilities
The research team employed translation models to translate instructions from high-resource languages to low-resource languages and assessed the semantic consistency of multilingual responses with original responses. This method not only expands the model’s language coverage but also ensures consistent performance across languages.
Improved Robustness of System Instructions
By constructing diverse system prompts and ensuring their consistency with conversational content, Qwen2.5 demonstrates more stability and reliability when handling different types of system instructions.
Strict Control of Response Quality
The researchers employed various automated evaluation methods, including specialized discriminators and multi-agent scoring systems, retaining only those samples deemed high-quality by all evaluation methods. This strict filtering ensures high quality in the training data.
Innovations in Offline Reinforcement Learning (Offline RL)
To address the inaccuracies of the reward model (RM) in scoring certain tasks, the research team innovatively used execution feedback and answer matching to construct positive and negative samples. This method is particularly suitable for objective tasks such as mathematics and programming. Additionally, researchers introduced a dual human-check mechanism to further ensure the reliability and accuracy of the training signals.
Breakthroughs in Online Reinforcement Learning (Online RL)
Optimization of the Reward Model
The research team established comprehensive evaluation criteria for the reward model, including authenticity, usefulness, conciseness, relevance, harmlessness, and debiasing. These criteria ensure the high quality and ethicality of the model’s outputs.
Diversity of Datasets
RM and RL training utilized a combination of open-source datasets and more complex private datasets. Responses originated from different training stages of the Qwen models and were generated using different temperature coefficients, ensuring data diversity.
Innovative Training Framework
The researchers adopted the GRPO (Group Relative Policy Optimization) framework for online RL training, a novel reinforcement learning algorithm that can more effectively optimize model strategies.
Intelligent Sampling Strategy
During training, for each query, eight outputs are sampled each time, balancing exploration and exploitation, helping the model learn more diverse responses.
Through these innovative post-training methods, Qwen2.5 not only performs excellently across various tasks but also demonstrates strong instruction-following capabilities and alignment with human preferences. These improvements make Qwen2.5 a more intelligent, reliable, and user-friendly large language model.
Performance Evaluation of Qwen2.5
The Qwen2.5 series models underwent comprehensive and rigorous evaluations, covering open benchmark tests and internal professional assessments. These evaluations not only showcase the model’s outstanding performance across various tasks but also highlight its exceptional capabilities in handling long contexts.
Open Benchmark Tests
The research team used a series of widely recognized benchmark tests to evaluate Qwen2.5’s performance:
-
General Capability Tests: Including MMLU-Pro, MMLU-redux, and LiveBench 0831, used to evaluate the model’s comprehensive understanding and reasoning abilities.
-
Scientific and Mathematical Abilities: Using GPQA, GSM8K, and MATH tests to assess the model’s performance in scientific reasoning and mathematical problem-solving.
-
Programming Abilities: Through HumanEval, MBPP, MultiPL-E, and LiveCodeBench tests to comprehensively evaluate the model’s code generation and understanding capabilities.
-
Instruction Following Abilities: Using IFEval tests to assess the model’s understanding and execution of instructions.
-
Human Preference Alignment: Using MT-Bench and Arena-Hard tests to evaluate the consistency of model outputs with human expectations.
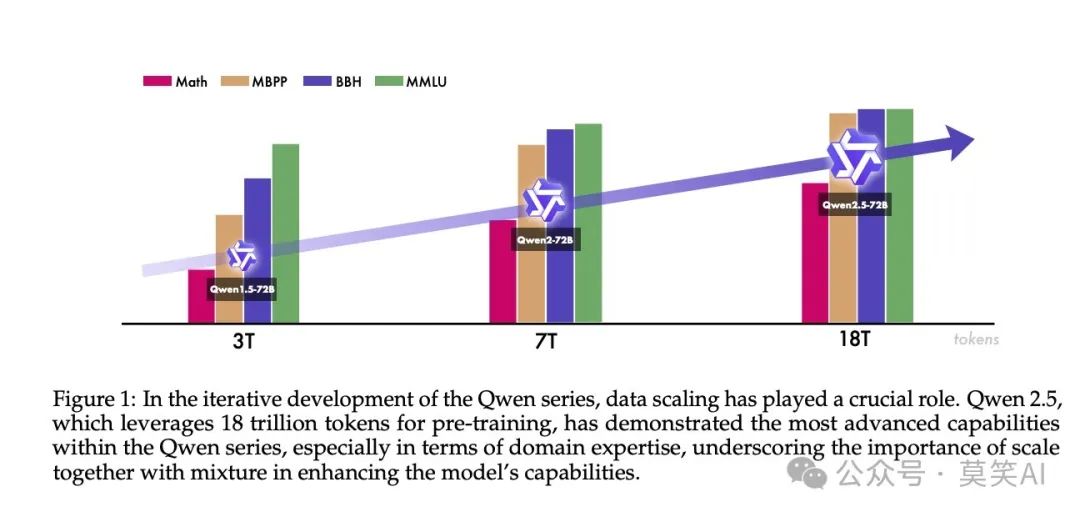
Results show that Qwen2.5-72B-Instruct performed excellently in multiple benchmark tests, even surpassing some models with larger parameter counts, such as Llama-3.1-405B-Instruct. Notably, in tests like MMLU-redux, MATH, and MBPP, Qwen2.5 demonstrated a leading advantage.
Internal Professional Assessments
In addition to open benchmark tests, the research team conducted a series of internal professional assessments:
-
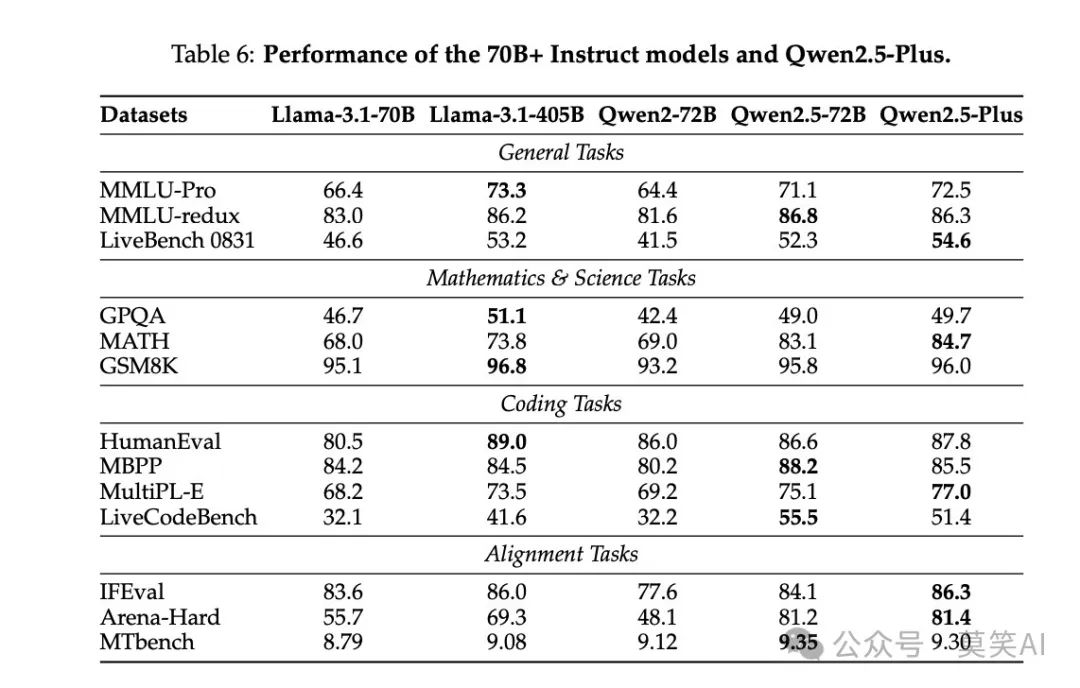
Multilingual Capability Assessment: Using AMMLU, JMMLU, and other multilingual tests to evaluate the model’s performance in different language environments.
-
Long Context Capability Assessment: Using RULER, LV-Eval, and Longbench-Chat tests to evaluate the model’s ability to handle long texts. Results show that Qwen2.5-72B-Instruct performed excellently across various context lengths, outperforming many open-source and proprietary models.
-
Reward Model Assessment: Using Reward Bench, RMB, and other tests to evaluate the performance of the reward model used for reinforcement learning.
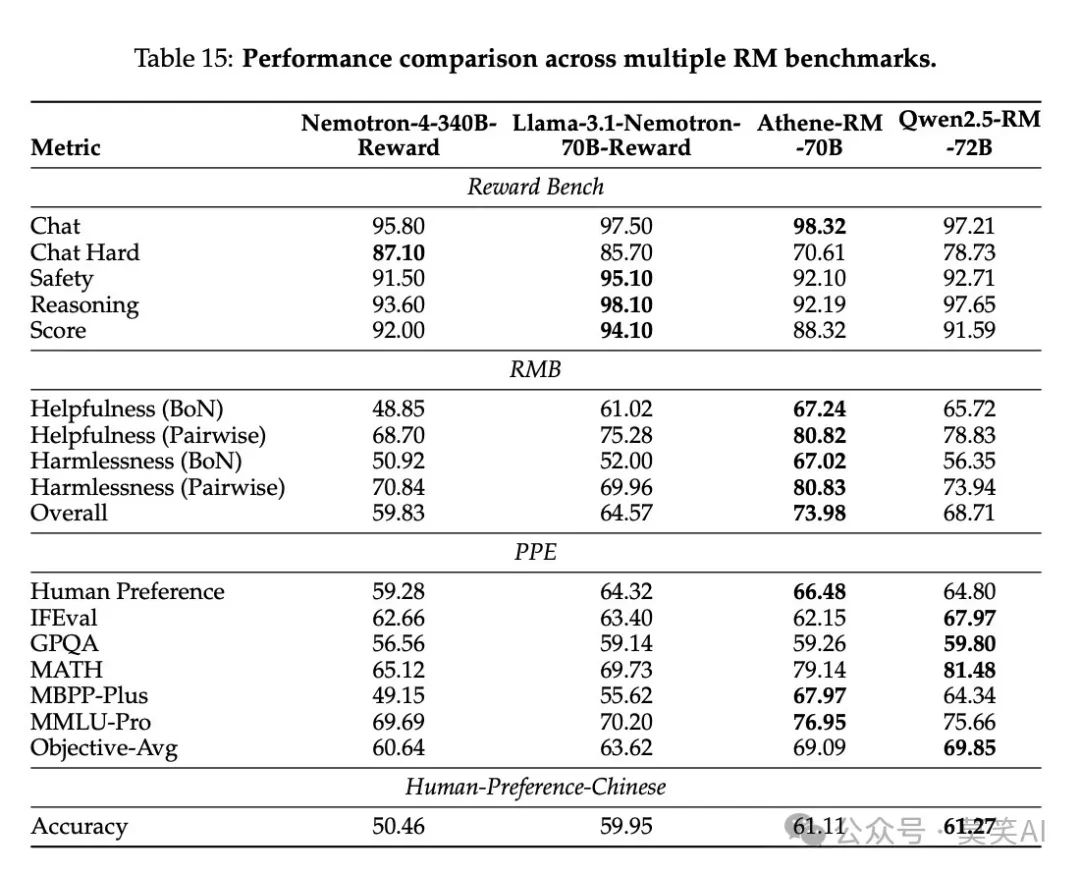
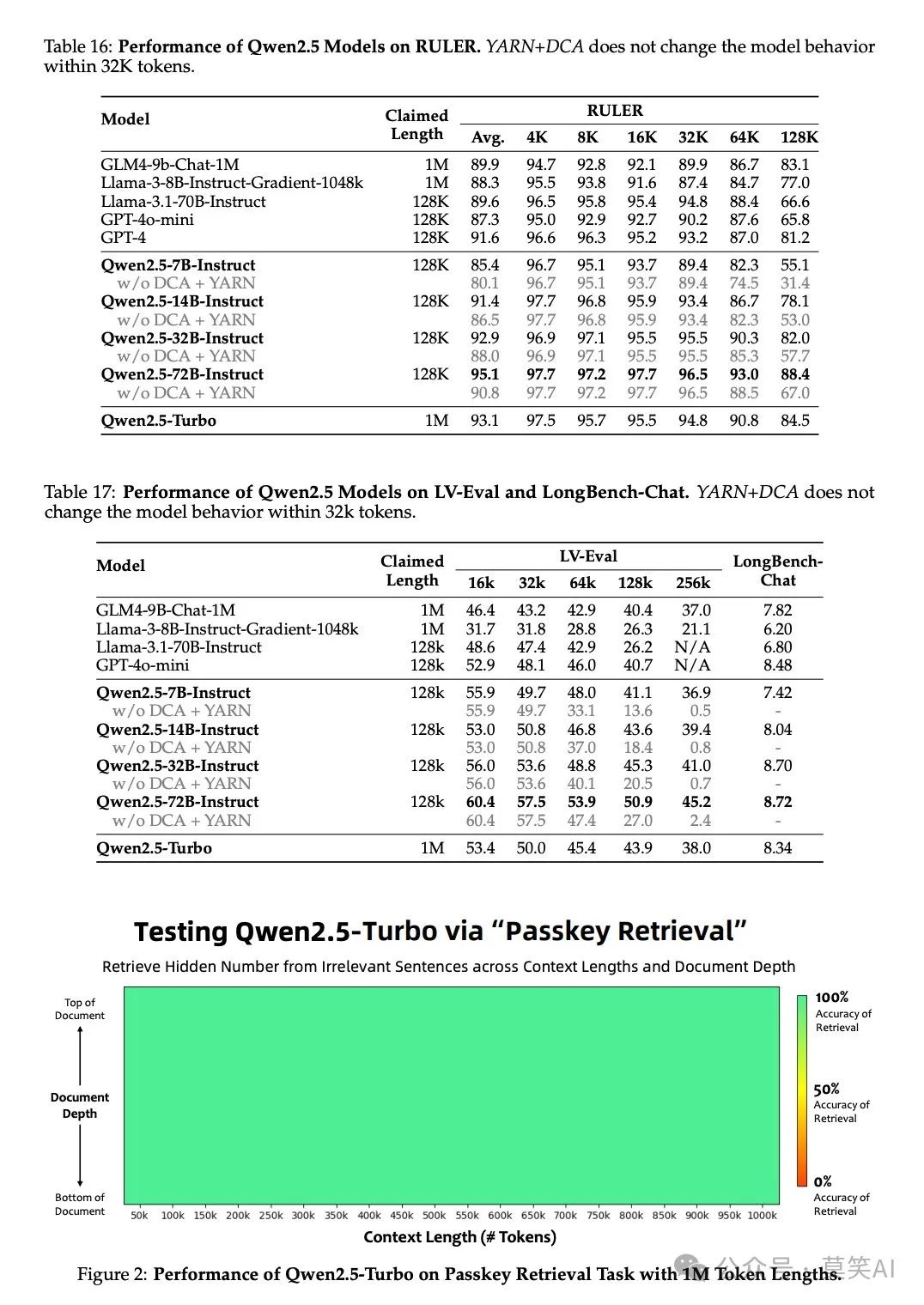
Breakthroughs in Long Context Processing
Qwen2.5 has achieved significant breakthroughs in long context handling:
-
Qwen2.5-Turbo: Achieved 100% accuracy in a 1 million token key retrieval task, demonstrating exceptional capability in handling ultra-long contexts.
-
Inference Speed Optimization: By introducing sparse attention mechanisms, the inference speed for long context processing has significantly improved. For sequences of 1 million tokens, the computational load was reduced by 12.5 times.
-
First Token Generation Time (TTFT): Under different hardware configurations, the TTFT of Qwen2.5-Turbo is 3.2 to 4.3 times faster than traditional methods.
These evaluation results fully demonstrate the outstanding performance of the Qwen2.5 series models across various tasks, especially their exceptional capabilities in handling long contexts. Qwen2.5 not only performs excellently in standard benchmark tests but also showcases strong capabilities in handling complex, long texts in practical applications, laying a solid foundation for its application in various real-world scenarios.
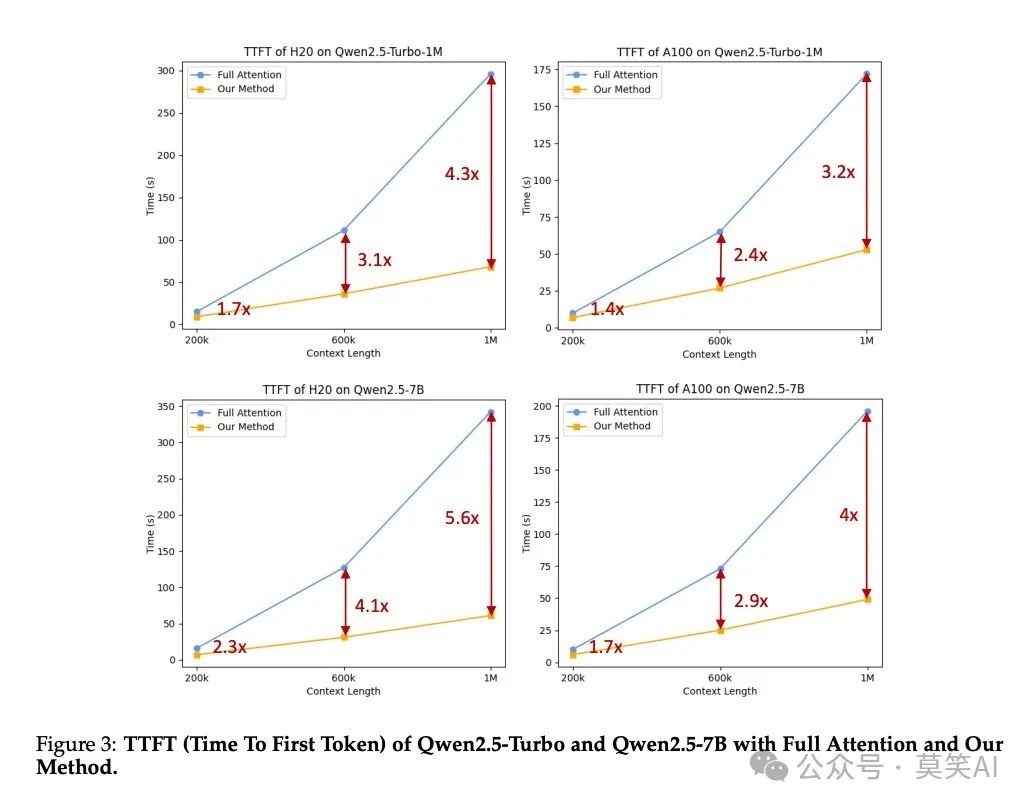
Conclusion
The release of the Qwen2.5 series models marks another significant advancement in large language model technology. Through comprehensive innovations in both the pre-training and post-training phases, Qwen2.5 has achieved significant breakthroughs in multiple areas:
-
Leap in Pre-training Data Scale: Expanding the training data from 7 trillion tokens to 18 trillion tokens provides a broader and deeper knowledge base for the model.
-
Innovations in Post-Training Technology: Employing supervised fine-tuning with 1 million samples and staged reinforcement learning has greatly enhanced the model’s instruction-following capabilities and alignment with human preferences.
-
Breakthroughs in Long Context Handling: Particularly, Qwen2.5-Turbo’s exceptional performance in handling million-token long texts opens up new possibilities for long document processing and complex task solutions.
-
Enhancements in Multilingual and Multidisciplinary Capabilities: Through diverse datasets and specialized training strategies, Qwen2.5 excels in multilingual understanding, scientific computation, programming, and more.
-
Diversity of Model Series: From 0.5B to 72B parameters in open-source models, as well as proprietary models like Qwen2.5-Turbo and Qwen2.5-Plus, flexible choices are provided for different application scenarios.
The success of Qwen2.5 is not only reflected in its powerful performance but also in its demonstration of a new direction for the development of large language model technology. Through innovative data processing methods, training strategies, and architectural designs, Qwen2.5 has achieved performance that meets or exceeds larger models even with relatively limited model size and computational resources. This efficient and powerful model design concept is of great significance for promoting the popularization and application of AI technology.
Looking ahead, the research team of Qwen2.5 plans to continue advancing in the following areas:
-
Continuously optimizing the foundational model and instruction fine-tuning model to improve the quality and diversity of data. -
Developing multimodal models that integrate text, visual, auditory, and other modal information. -
Enhancing the model’s reasoning capabilities and exploring more effective large-scale reasoning computation methods.
To join the technical exchange group, please add the AINLP assistant on WeChat (id: ainlp2)
Please specify the specific direction + related technical points used.
About AINLP
AINLP is an interesting AI natural language processing community focused on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, job experience sharing, etc. Welcome to follow! To join the technical exchange group, please add the AINLP assistant on WeChat (id: ainlp2), specifying your work/research direction + purpose of joining the group.